
📝 07 시계열 제어 - 데이터 셋에서 시계열 데이터 처리(to_datetime, parse_dates=) ✏️
pd.to_datetime()
- 정의: 문자열, 숫자, 리스트, 또는 Series 객체를 datetime으로 변환하는 함수이다.
- 파라미터:
arg: 변환할 데이터.errors: 에러 처리 방법 ('raise', 'coerce', 'ignore').format: 날짜 형식 문자열.unit: 시간 단위 (예: 's', 'ms').
- 사용 예:
import pandas as pd
# 문자열 리스트를 datetime으로 변환
date_strings = ['2023-01-01', '2023-01-02', '2023-01-03']
dates = pd.to_datetime(date_strings)
dates
# 결과: DatetimeIndex(['2023-01-01', '2023-01-02', '2023-01-03'], dtype='datetime64[ns]', freq=None)parse_dates
- 정의: 데이터를 불러올 때 특정 열을 datetime 형식으로 변환하는 옵션.
- 사용 예:
# 예제 CSV 파일 로드
df = pd.read_csv('example.csv', parse_dates=['date_column'])
df['date_column']
# 결과: datetime 형식으로 변환된 열을 포함한 데이터프레임- 예제: 복잡한 날짜 형식을 가진 데이터를 처리하는 방법
# 다양한 날짜 형식을 가진 데이터프레임 생성
data = {'date': ['2023-01-01', '01/02/2023', '2023.03.01', 'April 4, 2023'],
'value': [10, 20, 30, 40]}
df = pd.DataFrame(data)
# to_datetime을 사용하여 날짜 형식 변환
df['date'] = pd.to_datetime(df['date'], errors='coerce')
df
# 결과:
# date value
# 0 2023-01-01 10
# 1 2023-01-02 20
# 2 2023-03-01 30
# 3 2023-04-04 40📝 08 시계열 제어 - 날짜 포맷 정리 ✏️
날짜 포맷 정리
- 설명: 다양한 형식의 날짜 데이터를 정리하고 변환하는 방법.
- 예제:
# 여러 형식의 날짜 문자열 변환
date_strings = ['01-01-2023', '2023.01.01', 'January 1, 2023']
dates = pd.to_datetime(date_strings, format='%d-%m-%Y', errors='coerce')
dates
# 결과: DatetimeIndex(['2023-01-01', '2023-01-01', '2023-01-01'], dtype='datetime64[ns]', freq=None)- 예제: 복잡한 날짜 형식 정리
# 다양한 날짜 형식을 가진 데이터프레임 생성
data = {'date': ['01-01-2023', '2023/02/01', 'March 3, 2023', '04.04.2023'],
'value': [10, 20, 30, 40]}
df = pd.DataFrame(data)
# to_datetime을 사용하여 날짜 형식 변환
df['date'] = pd.to_datetime(df['date'], errors='coerce')
df
# 결과:
# date value
# 0 2023-01-01 10
# 1 2023-02-01 20
# 2 2023-03-03 30
# 3 2023-04-04 40📝 09 시계열 제어 - 잘못된 날짜 포맷 정리 ✏️
잘못된 날짜 포맷 정리
- 설명: 잘못된 형식의 날짜 데이터를 처리하고 변환하는 방법.
- 예제:
# 잘못된 날짜 형식의 문자열 변환
date_strings = ['2023/01/01', '01-2023-01', '20230101']
dates = pd.to_datetime(date_strings, errors='coerce')
dates
# 결과: DatetimeIndex(['2023-01-01', 'NaT', '2023-01-01'], dtype='datetime64[ns]', freq=None)- 예제: 잘못된 날짜 형식을 가진 데이터를 처리하는 방법
# 잘못된 날짜 형식을 가진 데이터프레임 생성
data = {'date': ['2023/01/01', '01-2023-01', '20230101', '2023.04.05'],
'value': [10, 20, 30, 40]}
df = pd.DataFrame(data)
# to_datetime을 사용하여 날짜 형식 변환
df['date'] = pd.to_datetime(df['date'], errors='coerce')
df
# 결과:
# date value
# 0 2023-01-01 10
# 1 NaT 20
# 2 2023-01-01 30
# 3 2023-04-05 40📝 10 시계열 제어 - 시계열의 조회(.loc) ✏️
시계열 데이터의 조회
- 설명:
.loc를 사용하여 시계열 데이터를 조회하는 방법. - 예제:
# 예제 데이터프레임 생성
date_range = pd.date_range(start='2023-01-01', end='2023-01-10')
df = pd.DataFrame({'value': range(10)}, index=date_range)
# 특정 날짜 조회
specific_date = df.loc['2023-01-05']
specific_date
# 결과: value 4
# Name: 2023-01-05 00:00:00, dtype: int64
# 날짜 범위 조회
date_range_data = df.loc['2023-01-03':'2023-01-06']
date_range_data
# 결과:
# value
# 2023-01-03 2
# 2023-01-04 3
# 2023-01-05 4
# 2023-01-06 5- 예제: 복잡한 시계열 데이터 조회
# 시계열 데이터프레임 생성
date_range = pd.date_range(start='2023-01-01', end='2023-01-15')
data = {'value': range(15)}
df = pd.DataFrame(data, index=date_range)
# 특정 날짜와 조건 조회
filtered_data = df.loc['2023-01-05':'2023-01-10'][df['value'] > 5]
filtered_data
# 결과:
# value
# 2023-01-06 6
# 2023-01-07 7
# 2023-01-08 8
# 2023-01-09 9
# 2023-01-10 10📝 11 시계열 제어 - 재색인(reindex)와 결측치 처리 ✏️
재색인(reindex)
- 설명: 시계열 데이터의 인덱스를 새로 설정하거나 변경하는 방법.
- 예제:
import pandas as pd
# 예제 데이터프레임 생성
date_range = pd.date_range(start='2023-01-01', periods=5, freq='D')
df = pd.DataFrame({'value': range(5)}, index=date_range)
# 재색인
new_date_range = pd.date_range(start='2023-01-01', periods=7, freq='D')
df_reindexed = df.reindex(new_date_range)
df_reindexed
# 결과:
# value
# 2023-01-01 0.0
# 2023-01-02 1.0
# 2023-01-03 2.0
# 2023-01-04 3.0
# 2023-01-05 4.0
# 2023-01-06 NaN
# 2023-01-07 NaN결측치 처리
- 설명: 결측치(NaN)를 처리하는 방법.
- 예제:
# 결측치 채우기
df_filled = df_reindexed.fillna(0)
df_filled
# 결과:
# value
# 2023-01-01 0.0
# 2023-01-02 1.0
# 2023-01-03 2.0
# 2023-01-04 3.0
# 2023-01-05 4.0
# 2023-01-06 0.0
# 2023-01-07 0.0심화 예제
- 예제: 복잡한 재색인과 결측치 처리
# 예제 데이터프레임 생성
date_range = pd.date_range(start='2023-01-01', periods=5, freq='D')
data = {'value': [1, None, 3, None, 5]}
df = pd.DataFrame(data, index=date_range)
# 재색인 및 결측치 채우기
new_date_range = pd.date_range(start='2023-01-01', periods=7, freq='D')
df_reindexed = df.reindex(new_date_range)
df_filled = df_reindexed.fillna(method='ffill') # 결측치를 앞의 값으로 채우기
df_filled
# 결과:
# value
# 2023-01-01 1.0
# 2023-01-02 1.0
# 2023-01-03 3.0
# 2023-01-04 3.0
# 2023-01-05 5.0
# 2023-01-06 5.0
# 2023-01-07 5.0📝 12 시계열 제어 - 리샘플링(resample, asfreq, interpolate, method=, kind=) ✏️
리샘플링(resample)
- 설명: 시계열 데이터를 새로운 주기로 변환하는 방법.
- 예제:
import pandas as pd
# 예제 데이터프레임 생성
date_range = pd.date_range(start='2023-01-01', periods=10, freq='D')
df = pd.DataFrame({'value': range(10)}, index=date_range)
# 일간 데이터를 주간 데이터로 리샘플링
df_resampled = df.resample('W').sum()
df_resampled
# 결과:
# value
# 2023-01-01 0
# 2023-01-08 28
# 2023-01-15 17asfreq
- 설명: 시계열 데이터를 새로운 빈도로 변환하여 빈 값을 유지하는 방법.
- 예제:
# 일간 데이터를 주간 빈도로 변환
df_asfreq = df.asfreq('W')
df_asfreq
# 결과:
# value
# 2023-01-01 0.0
# 2023-01-08 7.0
# 2023-01-15 NaNinterpolate
-
설명: 결측치를 보간하여 채우는 방법.
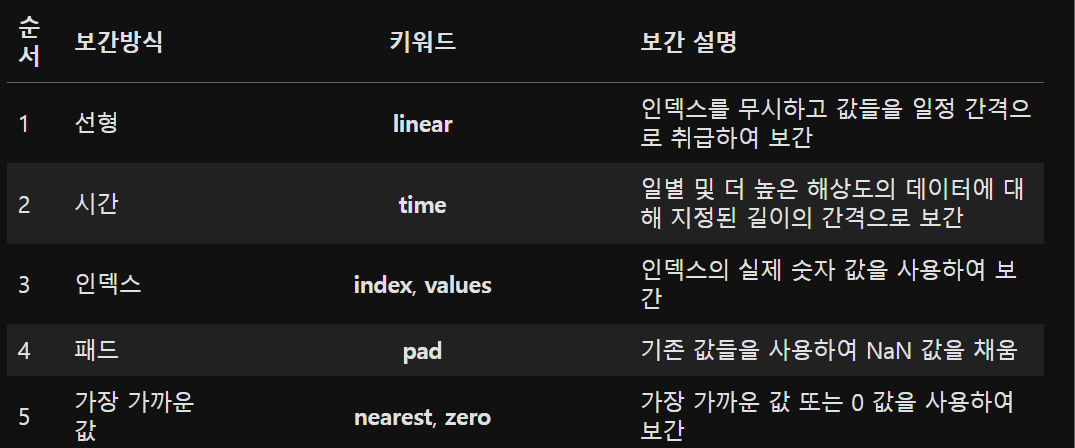
-
예제:
# 결측치를 선형 보간으로 채우기
df_interpolated = df_asfreq.interpolate(method='linear')
df_interpolated
# 결과:
# value
# 2023-01-01 0.0
# 2023-01-08 7.0
# 2023-01-15 14.0- 예제: 복잡한 리샘플링과 보간
# 예제 데이터프레임 생성
date_range = pd.date_range(start='2023-01-01', periods=30, freq='D')
data = {'value': [i if i % 2 == 0 else None for i in range(30)]}
df = pd.DataFrame(data, index=date_range)
# 리샘플링 및 보간
df_resampled = df.resample('W').mean()
df_interpolated = df_resampled.interpolate(method='polynomial', order=2) # 다항식 보간
df_interpolated
# 결과:
# value
# 2023-01-01 0.000000
# 2023-01-08 3.500000
# 2023-01-15 9.000000
# 2023-01-22 14.500000
# 2023-01-29 20.000000
# 2023-02-05 25.500000format에 대하여
strftime으로 변환된 데이터는 일정한 형식을 가지므로, pd.to_datetime을 사용할 때 format 인자를 사용하지 않아도 작동한다. 그러나 성능 향상과 명확성을 위해 format 인자를 사용하는 것이 좋다.
예를 들어, strftime으로 변환된 데이터가 2015.03.04 형식인 경우, pd.to_datetime을 사용할 때 format 인자를 생략할 수 있다. 그러나 명시적으로 형식을 지정하는 것이 더 좋은 방법이다.
format 인자를 사용하지 않는 경우
import pandas as pd
# 예시 데이터프레임 생성
data = {
'value': [10, 20, 30]
}
index = pd.to_datetime(['2015-03-04', '2015-03-05', '2015-03-06'])
df = pd.DataFrame(data, index=index)
# 날짜형 데이터를 문자열로 변환
df.index = df.index.strftime('%Y.%m.%d')
# 문자열을 날짜형 데이터로 다시 변환 (format 인자 없이)
df.index = pd.to_datetime(df.index)
# 결과 확인
print(df)format 인자를 사용하는 경우
import pandas as pd
# 예시 데이터프레임 생성
data = {
'value': [10, 20, 30]
}
index = pd.to_datetime(['2015-03-04', '2015-03-05', '2015-03-06'])
df = pd.DataFrame(data, index=index)
# 날짜형 데이터를 문자열로 변환
df.index = df.index.strftime('%Y.%m.%d')
# 문자열을 날짜형 데이터로 다시 변환 (format 인자 사용)
df.index = pd.to_datetime(df.index, format='%Y.%m.%d')
# 결과 확인
print(df)요약
-
format인자를 사용하지 않는 경우:pd.to_datetime은 형식을 자동으로 인식하려고 시도한다.- 성능이 떨어질 수 있으며, 데이터가 일정한 형식을 따르지 않는 경우 오류가 발생할 수 있다.
-
format인자를 사용하는 경우:- 변환할 문자열의 형식을 명시적으로 지정하여 변환한다.
- 성능이 향상되고, 변환 과정에서의 명확성이 높아진다.
따라서, strftime으로 변환된 일정한 형식의 문자열 데이터를 다시 날짜형 데이터로 변환할 때는 format 인자를 사용하는 것이 권장된다.

Data Analyst Challenge