
GIF 출처 : https://logpresso.store/ko/apps/mysql
🖥 Contents
1 ) SELECT
2 ) WHERE
3 ) ORDER BY
4 ) 와일드카드
5 ) REGEXP
6 ) GROUP BY
7 ) 외래키 조작
8 ) MySQL 데이터 유형
1 ) SELECT
-
SELECT
: SELECT 문은 데이터베이스에서 데이터를 조회하는 구문이다. SELECT문의 경우 다양한 옵션을 함께 사용할 수 있다.
SELECT [ 열 ] FROM [ 테이블 ] ex )
SELECT * FROM USER;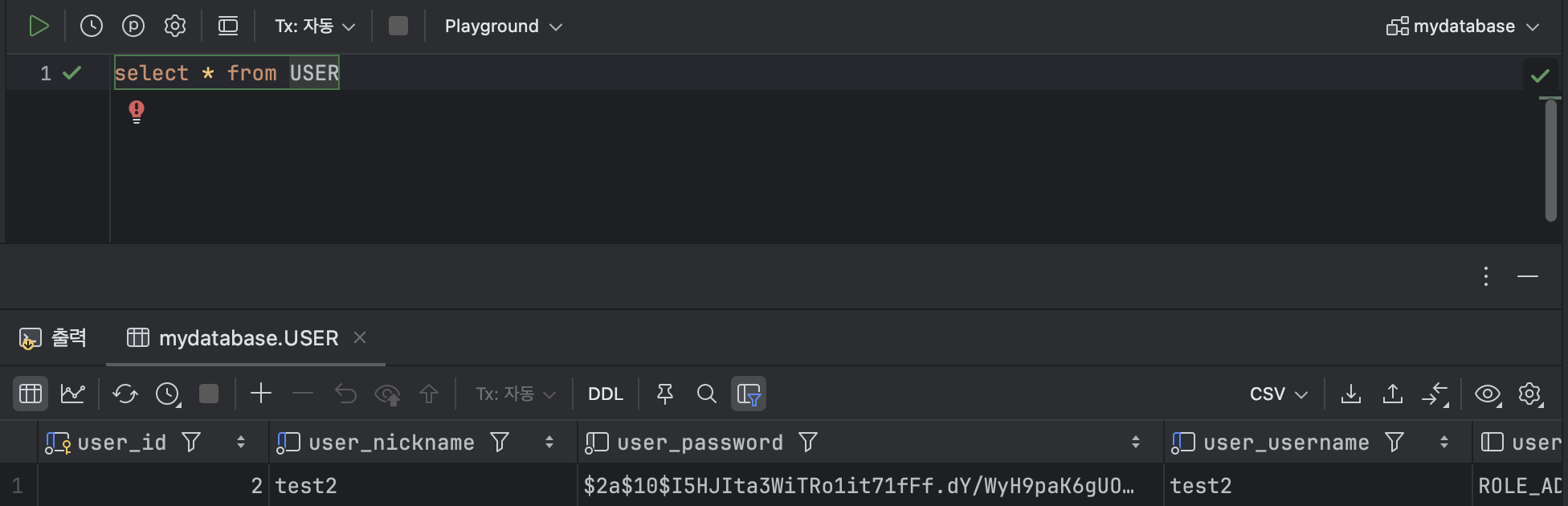 : 모든 열을 조회할 경우에는 ' * ' 키워드를 열 부분에 삽입하여 쿼리를 날려주면 된다.
: 모든 열을 조회할 경우에는 ' * ' 키워드를 열 부분에 삽입하여 쿼리를 날려주면 된다.
‼️ 이때 , 항상 열을 조회하기 위해 * 를 사용하는 방식은 데이터 세트의 크기가 커질 수록 지양해야한다.
< 모든 열 조회를 지양해야 하는 이유 >
전체 데이터의 크기가 증가하면서 필요한 열 외에 불필요한 열의 데이터까지 모두 조회하게 되면서 CPU나 디스크에 많은 부담을 주기 때문이다. 또한 조회한 데이터는 네트워크를 통해 전송하는 것이 일반적이므로 네트워크에도 부담을 준다.
예를 들어보자. 백엔드에서 위 예시 화면처럼 User 도메인의 데이터를 조회하는 쿼리를 날린다고 가정해보자.
해당 쿼리를 전달하는 과정에서 Http 통신을 통해 전달되기 때문에 네트워크의 부하 문제가 발생한다. 필요 없는 필드가 증가하면서 응답 바이트 수가 증가하게 되고 이로인해 클라이언트 - 서버간의 트래픽 비용이 증가하기 때문이다. 또한 User 데이터를 객체에 담아 사용하기 때문에 GC ( Garbage Collection ) 의 문제가 발생할 여지도 존재한다.
따라서 가급적 데이터를 조회할 때 전체 열 조회는 가급적 자주 사용하지 않는 것이 중요하다.
⭐️ 테이블의 열 정보 조회하기
: 테이블에 존재하는 열의 데이터 타입에 대해서 궁금할때는 다음과 같은 쿼리를 통해 타입을 조회할 수 있다.
SHOW COLUMNS FROM [ 데이터베이스.테이블 명 ] ex )
SHOW COLUMNS FROM mydatabase.USER;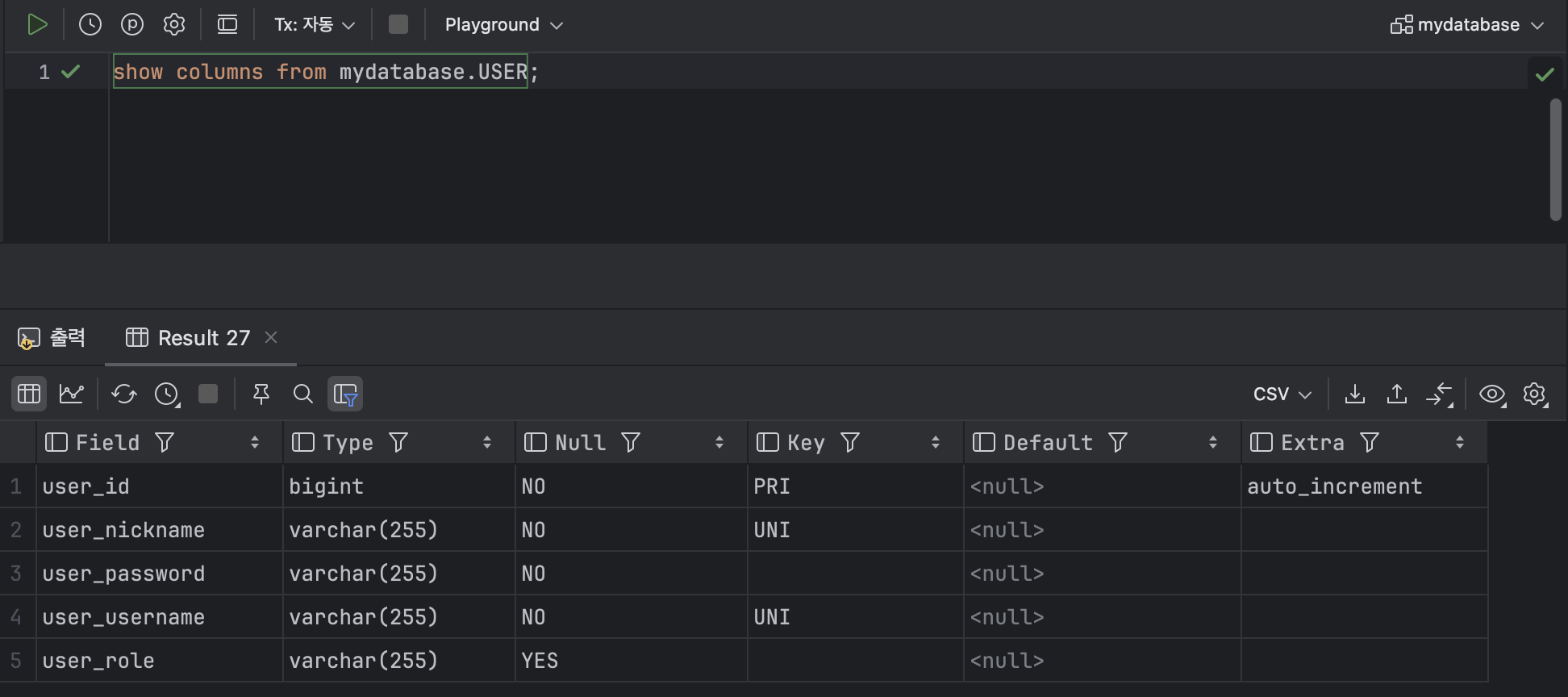
2 ) WHERE
- WHERE
: WHERE 문은 조건에 맞는 행을 조회하기 위해 사용된다.
SELECT [ 열 ] FROM [ 테이블 ] WHERE [ 열 ] = [ 조건값 ] ex )
SELECT user_nickname FROM USER WHERE user_nickname = 'test2';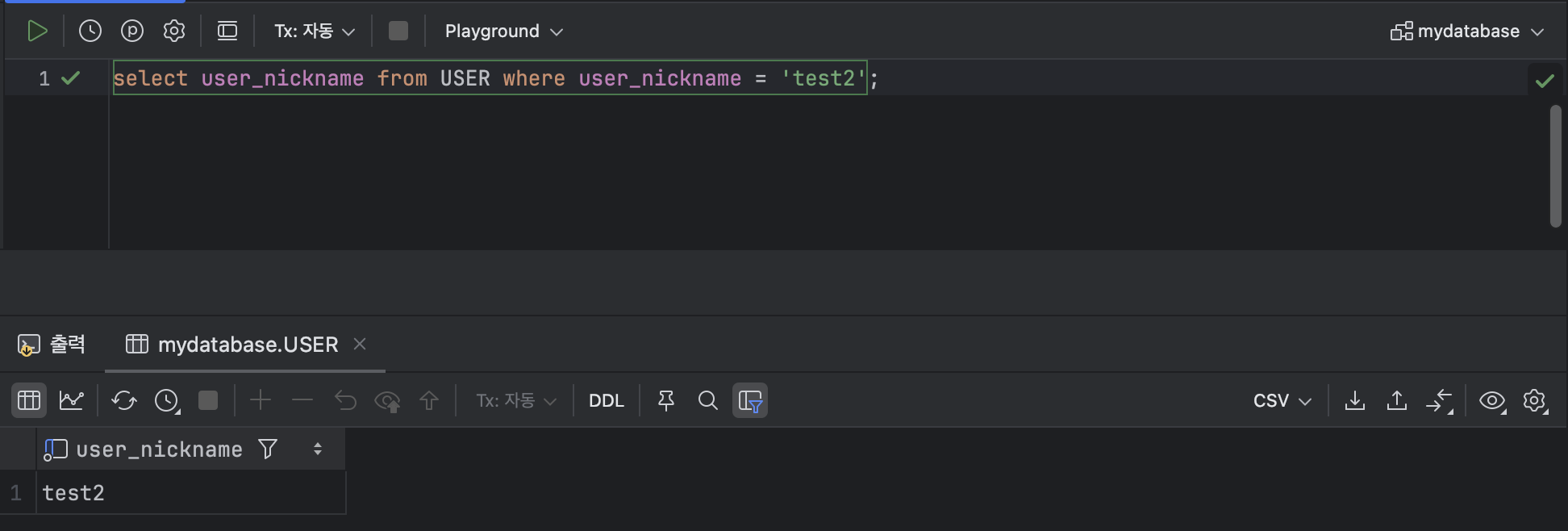
⭐️ 비교 연산자 사용
: WHERE 문의 경우 비교 연산자를 통해서 데이터 조회의 조건을 부여할 수 있다.
| 연산자 | 설명 |
|---|---|
| ' < ' | 조건 값보다 작은 값을 조회한다. |
| ' <= ' | 조건값보다 같거나 작은 값을 조회한다. |
| ' = ' | 조건값과 동일한 값을 조회한다. |
| ' > ' | 조건값보다 큰 값을 조회한다. |
| ' >= ' | 조건값보다 같거나 큰 값을 조회한다. |
| ' <> ' , ' != ' | 조건값과 동일하지 않는 값을 조회한다. |
| ' !< ' | 조건값보다 작지 않은 값을 조회한다. |
| ' !> ' | 조건값보다 크지 않은 값을 조회한다. |
⭐️ 논리 연산자 사용
: 참 , 거짓을 판단하여 복잡한 조건식을 구성해야할 필요가 있는 경우에 비교 연산자와 더불어 많이 사용한다.
| 연산자 | 설명 |
|---|---|
| ALL | 모든 비교 집합이 참일 경우에 대한 데이터를 조회한다. |
| AND | 양쪽의 부울 표현식이 모두 참이면 해당 데이터를 조회한다. |
| ANY | 비교 집합 중 하나라도 참이면 해당 데이터를 조회한다. |
| BETWEEN | 피연산자가 범위 내에 있으면 데이터를 조회한다. |
| EXISTS | 하위 쿼리에 행이 포함되면 데이터를 조회한다. |
| IN | 피연산자가 리스트 중 하나라도 포함되어 있으면 데이터를 조회한다. |
| LIKE | 피연산자가 패턴과 일치하는 경우 데이터를 조회한다. |
| NOT | 부울 연산자를 반대로 실행해 데이터를 조회한다. |
| OR | OR를 기준으로 한 쪽의 부울 표현식이 참이면 해당 데이터를 조회한다. |
| SOME | 비교 집합 중 일부가 참인 경우 데이터를 조회한다. |
3 ) ORDER BY
- ORDER BY
: ORDER BY 문의 경우 데이터를 정렬하기 위해 사용된다.
SELECT [ 열 ] FROM [ 테이블 명 ] WHERE [ 열 ] = [ 조건 값 ] ORDER BY [ 열 ] [ ASC 또는 DSC ] ex )
SELECT * FROM Refresh ORDER BY id;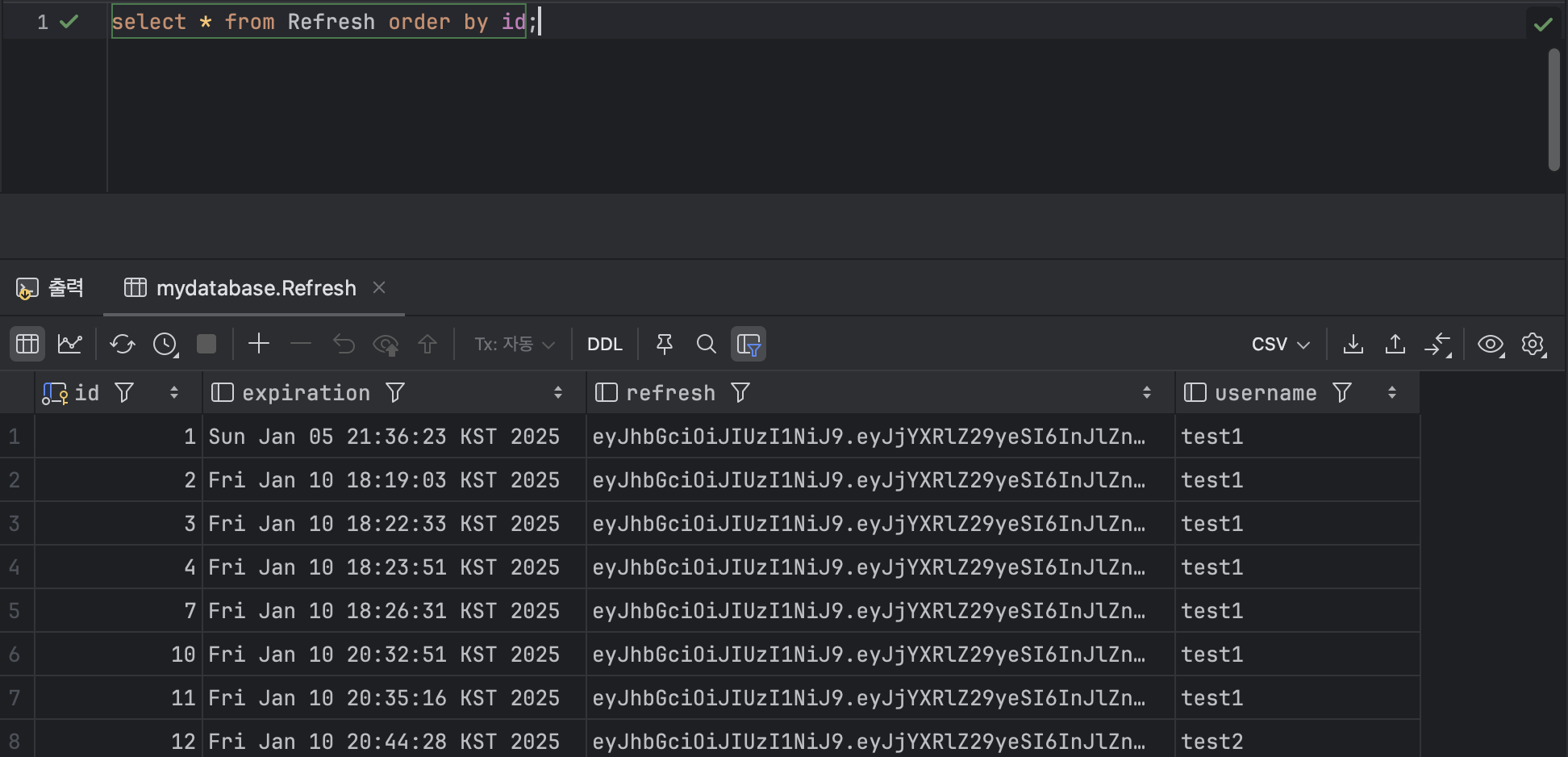 해당 쿼리의 결과를 보면 id를 오름차순으로 정렬하여 데이터를 조회하였다. 기본적으로 ORDER BY는 오름차순을 디폴트로 한다.
해당 쿼리의 결과를 보면 id를 오름차순으로 정렬하여 데이터를 조회하였다. 기본적으로 ORDER BY는 오름차순을 디폴트로 한다.
⭐️ LIMIT 문
: LIMIT문은 특정 조건에 해당하는 데이터 중에서 상위 N개의 데이터만을 보고 싶은 경우에 사용한다.
SELECT [ 열 ] FROM [ 테이블 명 ] ORDER BY [ 열 ][ASC 또는 DESC] LIMIT [ 갯수 ];ex )
SELECT * FROM Refresh ORDER BY id ASC LIMIT 3;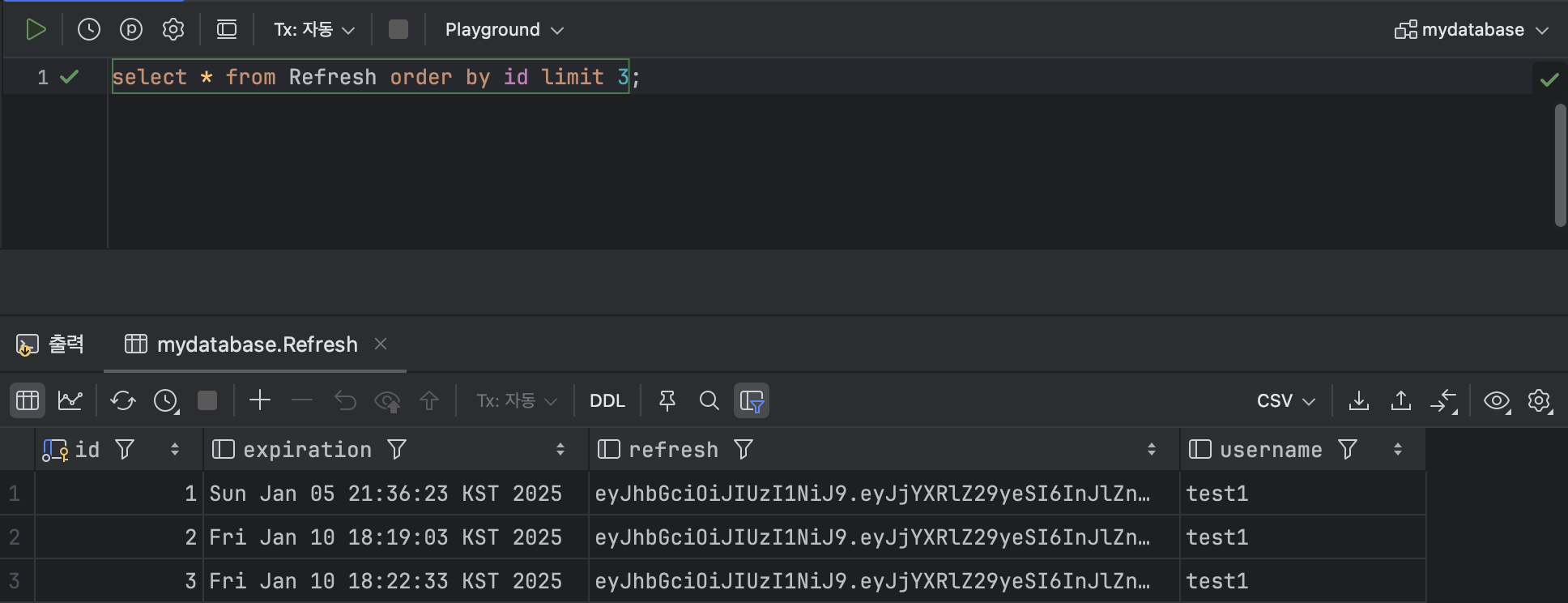 : 오름차순으로 상위 3개의 데이터만 조회하는 쿼리를 날리는 경우 다음과 같은 결과를 얻을 수 있다.
: 오름차순으로 상위 3개의 데이터만 조회하는 쿼리를 날리는 경우 다음과 같은 결과를 얻을 수 있다.
상위 데이터의 개수를 지정할 수 있는것 뿐만 아니라 데이터의 범위를 지정하여 데이터를 조회할 수 있다.
ex )
SELECT * FROM Refresh ORDER BY id ASC LIMIT 3,3;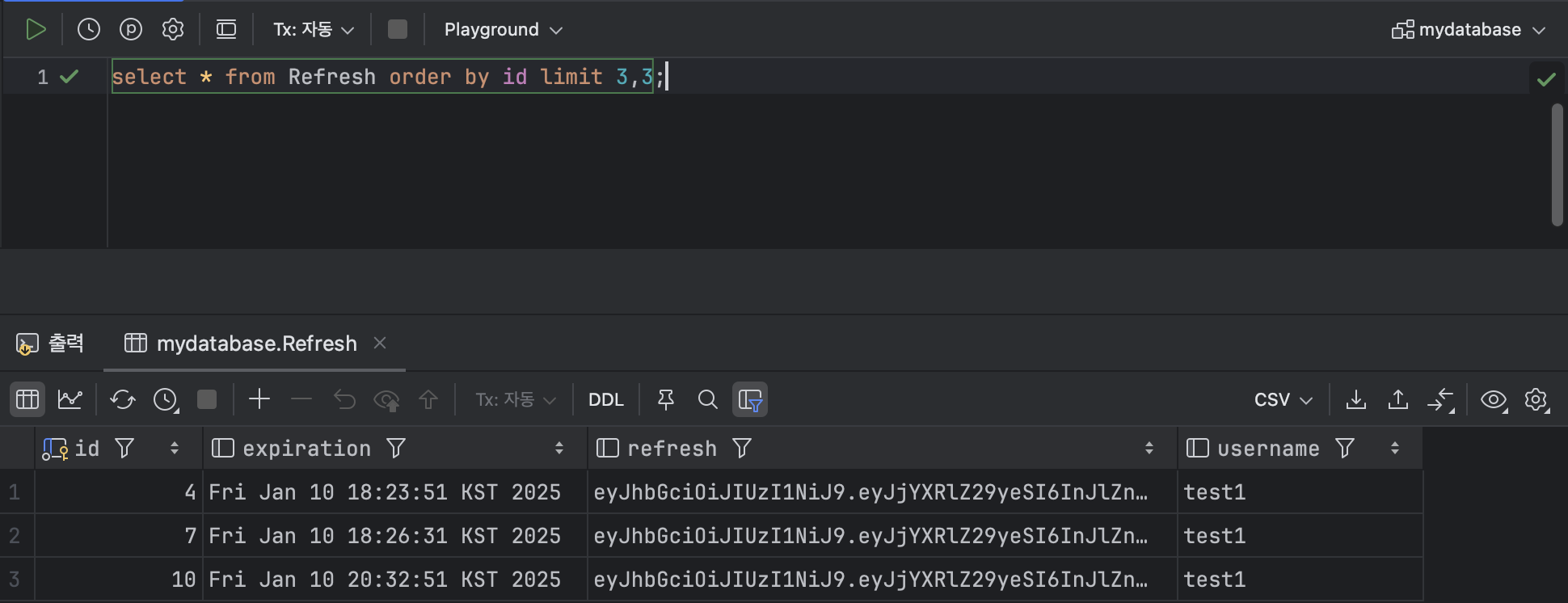 특정 데이터 구간의 데이터 조회의 경우
특정 데이터 구간의 데이터 조회의 경우 OFFSET 키워드를 통해서 같은 결과의 쿼리를 날릴 수 있다.
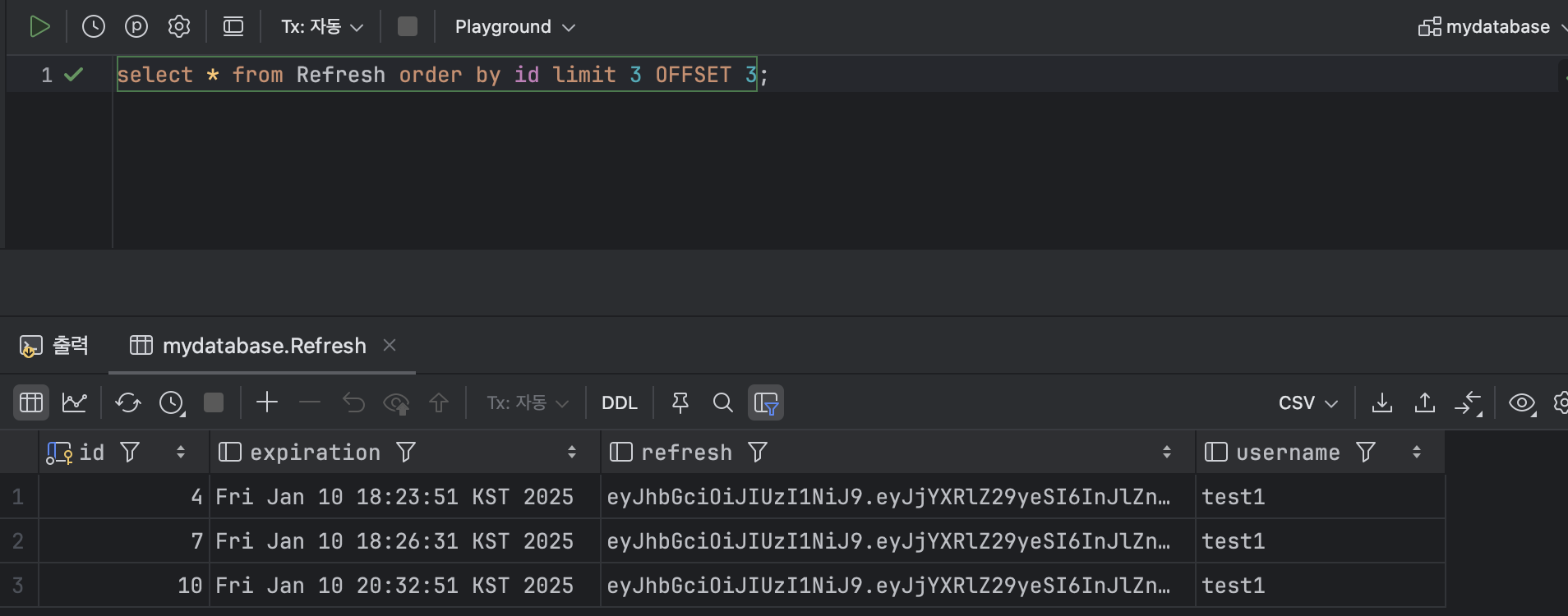
4 ) 와일드 카드
-
와일드 카드
: SQL에서의 와일드 카드는 다른 문자열의 문자를 대체하는데 사용된다. 와일드 카드로 지정한 패턴과 일치하는 문자열 , 날짜 , 시간 등을
LIKE키워드를 통해 조회한다.
SELECT [ 열 ] FROM [ 테이블 ] WHERE [ 열 ] LIKE [ 조건 값 ]
- % 와 LIKE로 특정 문자열을 포함하는 데이터 조회하기
| 기호 위치 | 설명 |
|---|---|
| A% | A로 시작하는 모든 문자열 |
| %A | A로 끝나는 모든 문자열 |
| %A% | A가 포함된 모든 문자열 |
ex ) 문자열 앞에 %가 붙은 경우
SELECT * FROM Refresh WHERE refresh LIKE '%e';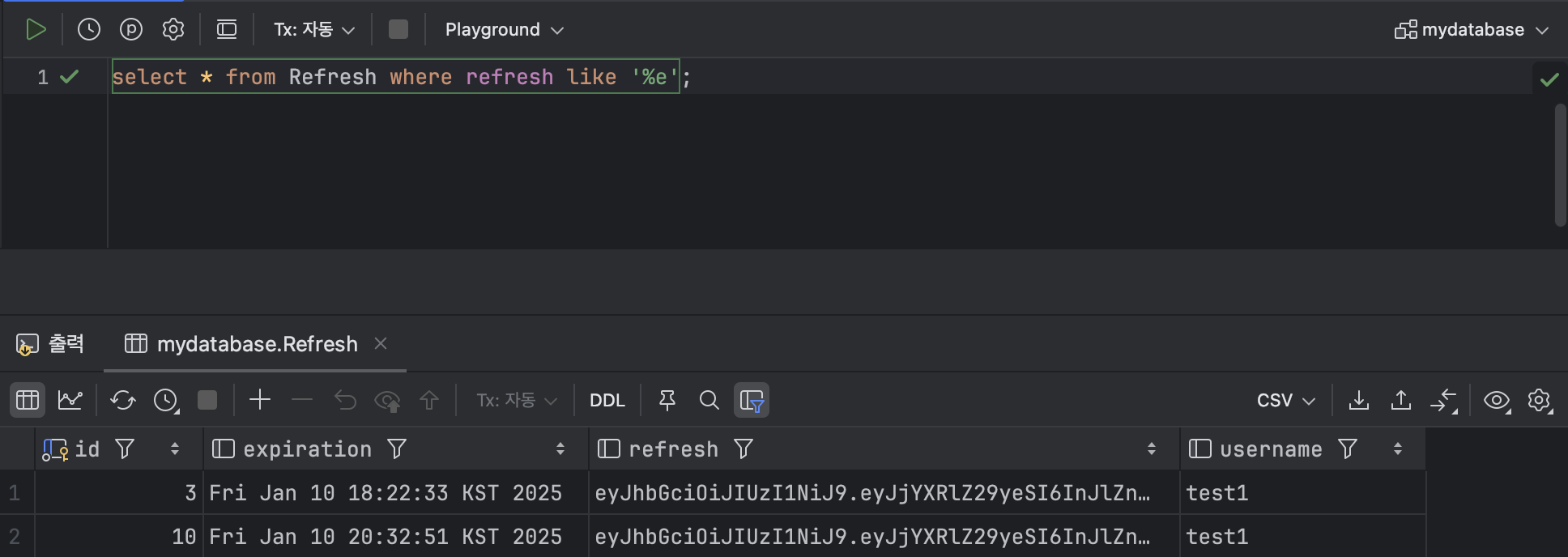
ex ) 문자열 뒤에 %가 붙은 경우
SELECT * FROM Refresh WHERE refresh LIKE '1%';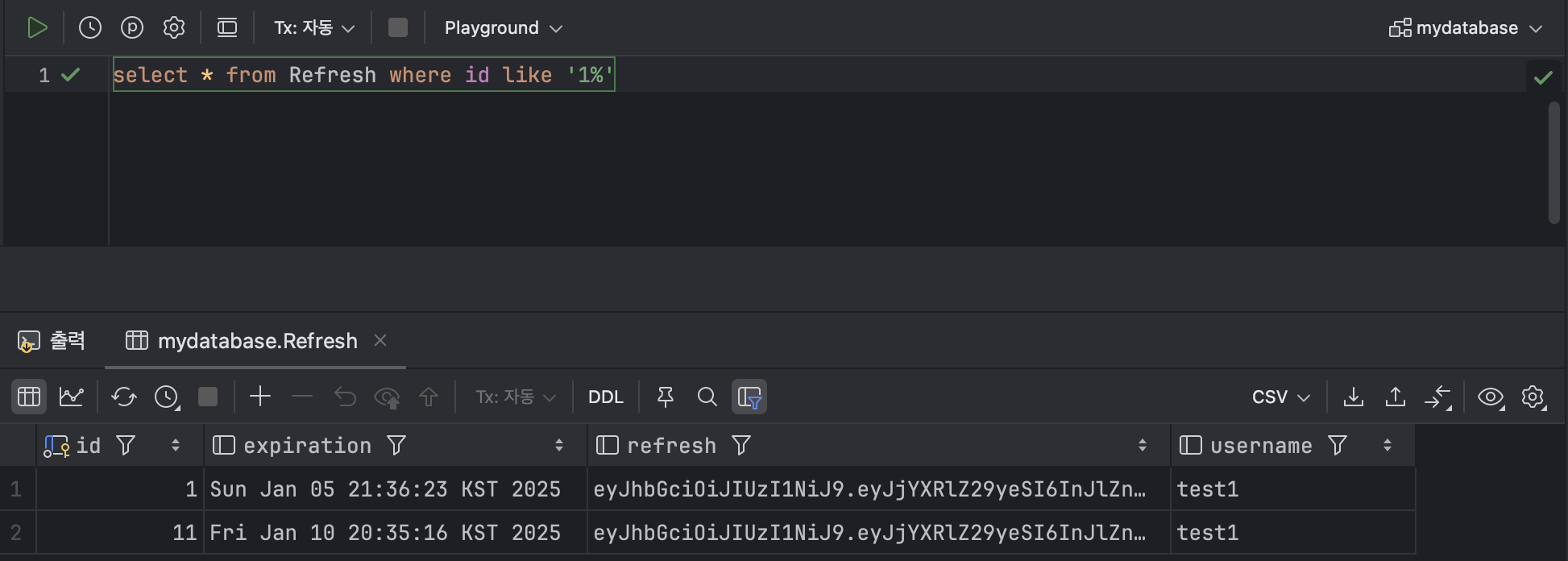
ex ) 문자열 양 옆에 %가 붙은 경우
SELECT * FROM Refresh WHERE username LIKE '%2%';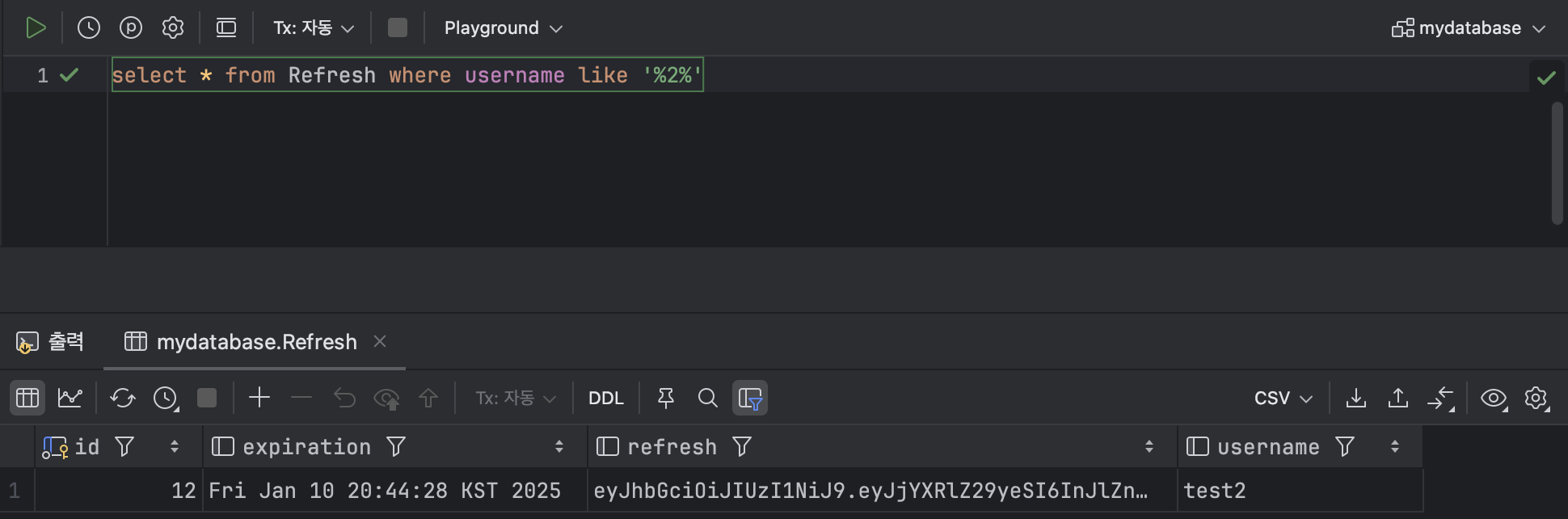
- ESCAPE로 특수 문자를 포함한 데이터 조회하기
: ESCAPE 문을 통해 특수 문자를 포함한 데이터를 조회할때는 메타 문자를 삽입한 뒤 ESCAPE를 통해 해당 문자를 제거하면 된다.
ex )
SELECT * FROM [ 테이블 명 ] WHERE [ 열 ] LIKE '%[ 문자 ]%%' ESCAPE '[ 문자 ]';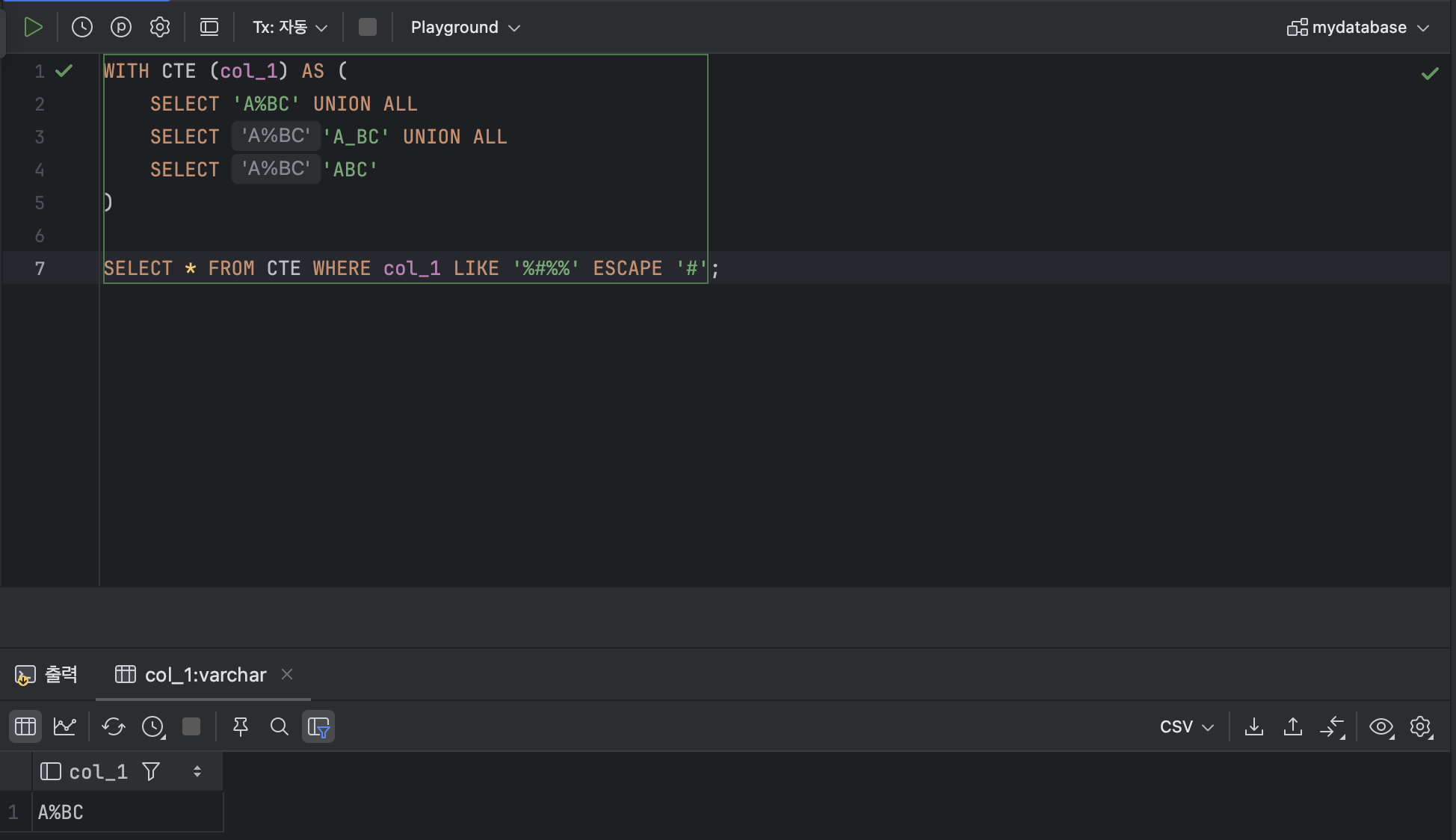
WITH CTE (col_1) AS (
SELECT 'A%BC' UNION ALL
SELECT 'A_BC' UNION ALL
SELECT 'ABC'
)
SELECT * FROM CTE WHERE col_1 LIKE '%#%%' ESCAPE '#';
- LIKE 와 _ 로 길이가 정해진 데이터 조회하기
: ' _ ' 키워드의 경우 특정 문자열의 길이를 나타낸다. LIKE와의 사용은 다음과 같다.
| 위치 | 설명 |
|---|---|
| A_ | A로 시작하면서 전체 글자 수가 2개인 문자열 |
| _A | A로 끝나면서 전체 글자수는 2개인 문자열 |
| _A | 세 글자로 된 문자열 중 가운데 글자만 A인 문자열 |
SELECT [ 열 ] FROM [ 테이블 명 ] WHERE [ 열 ] LIKE '[ 문자열 ]_'SELECT [ 열 ] FROM [ 테이블 명 ] WHERE [ 열 ] LIKE '_[ 문자열 ]'SELECT [ 열 ] FROM [ 테이블 명 ] WHERE [ 열 ] LIKE '_[ 문자열 ]_'5 ) REGEXP
-
REGEXP
: MySQL에서는 정규 표현식 ( Regular Expression ) 을 의미하는 REGEXP를 통해 다양한 방법으로 문자열을 검색할 수 있다. 정규 표현식의 경우 특정한 패턴의 문자열을 표현하기 위해 사용된다.표현식 설명 . 줄 바꿈 문자 ( \n ) 을 제외한 임의의 한 문자를 의미한다. * 해당 문자 패턴이 0번 이상 반복한다. + 해당 문자 패턴이 1번 이상 반복한다. ^ 문자열의 처음을 의미한다. $ 문자열의 끝을 의미한다. | OR를 의미한다. [...] 대괄호([]) 안에 있는 어떠한 문자를 의미한다. [^..] 대괄호([]) 안에 있지 않은 어떠한 문자를 의미한다. {n} 반복되는 횟수를 지정한다. {m,n} 반복되는 횟수의 최솟값과 최댓값을 지정한다.
ex ) first_name 열에서 K로 시작하거나 N으로 끝나는 데이터
SELECT * FROM Customer WHERE first_name REGEXP '^K|N$';ex ) first_name 열에서 K와 함께 L과 N사이의 글자를 포함한 데이터
SELECT * FROM Customer WHERE first_name REGEXP 'K[L-N]';ex ) first_name 열에서 K와 함께 L과 N사이의 글자를 포함하지 않는 데이터
SELECT * FROM Customer WHERE first_name REGEXP 'K[^L-N]';6 ) GROUP BY
-
그룹화
: 조회한 데이터들을 그룹으로 묶어 정보를 확인해야 할 때가 있다. 또한 데이터 그룹에 특정 조건을 필터링해서 필요한 데이터를 조회해야 하는 경우도 존재한다.예를들어 여러 Column으로 구성된 데이터 셋이 존재한다고 가정해보자. 해당 데이터 셋에서 특정 Column을 기준으로 어떤 데이터가 존재하는지를 조회하고자 할 때 , 해당 Column을 기준으로 ' 그룹화 ' 하여 데이터를 분석할 필요가 있다.
< GROUP BY 문과 HAVING 문의 기본 형식 >
SELECT [ 열 ] FROM [ 테이블 명 ] WHERE [ 열 ] = [ 조건값 ] GROUP BY [ 열 ] HAVING [ 열 ] = [ 조건값 ] ex ) special_features 열의 데이터를 그룹화
SELECT special_features FROM film GROUP BY special_features;
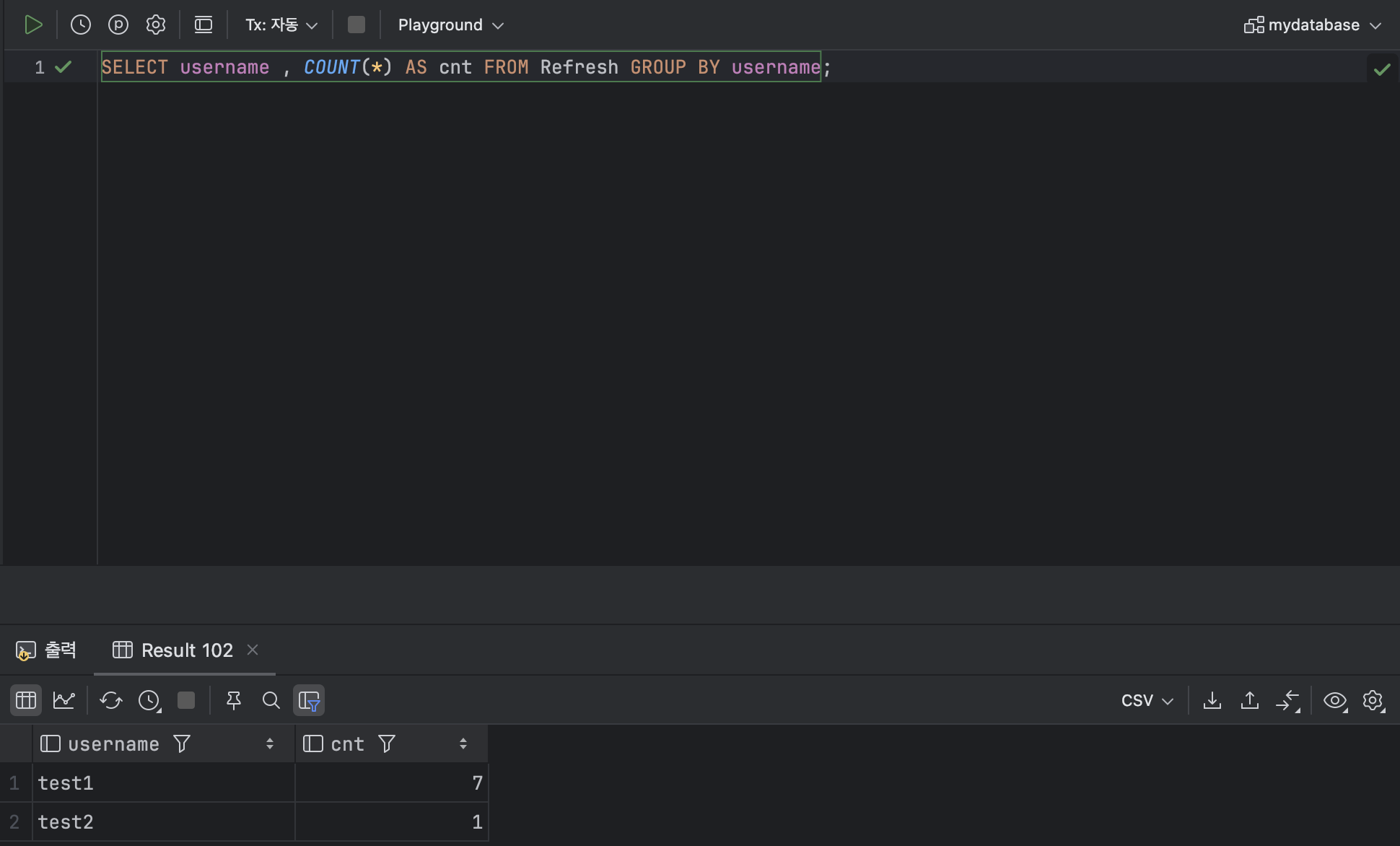
- COUNT로 그룹화한 열의 데이터 개수 세기
ex )
SELECT username , COUNT(*) AS cnt FROM Refresh GROUP BY username;
- HAVING 문으로 그룹화한 데이터 필터링 하기
ex )
SELECT username , COUNT(*) AS cnt FROM Refresh GROUP BY username HAVING cnt > 1; 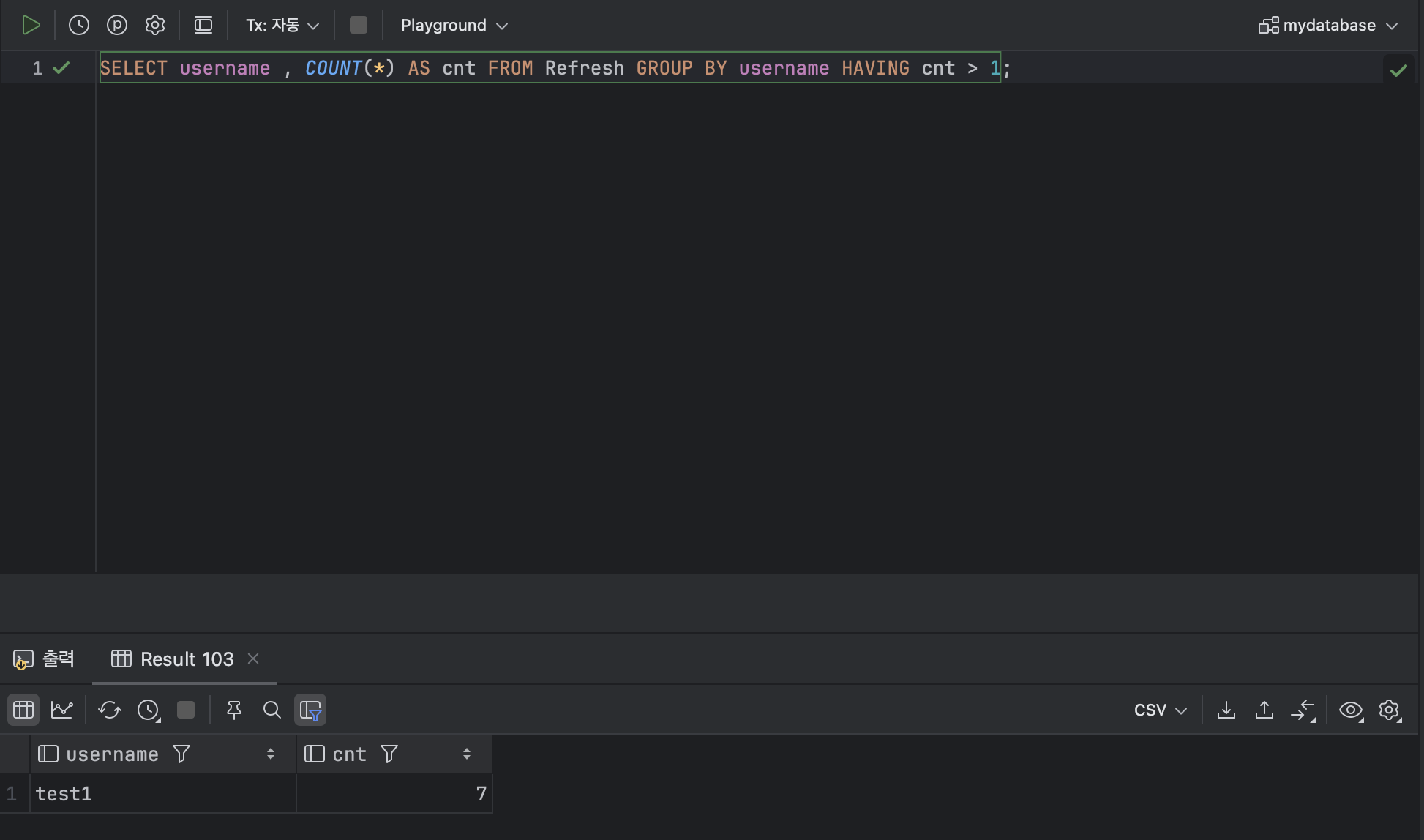 : HAVING 문의 경우 GROUP BY를 사용하지 않는 경우에는 사용할 수 없다.
: HAVING 문의 경우 GROUP BY를 사용하지 않는 경우에는 사용할 수 없다.
- DISTINCT 문으로 중복된 데이터 제거하기
< DISTINCT 문의 기본 형식 >
SELECT DISTINCT [ 열 ] FROM [ 테이블 ];ex )
SELECT DISTINCT username FROM Refresh;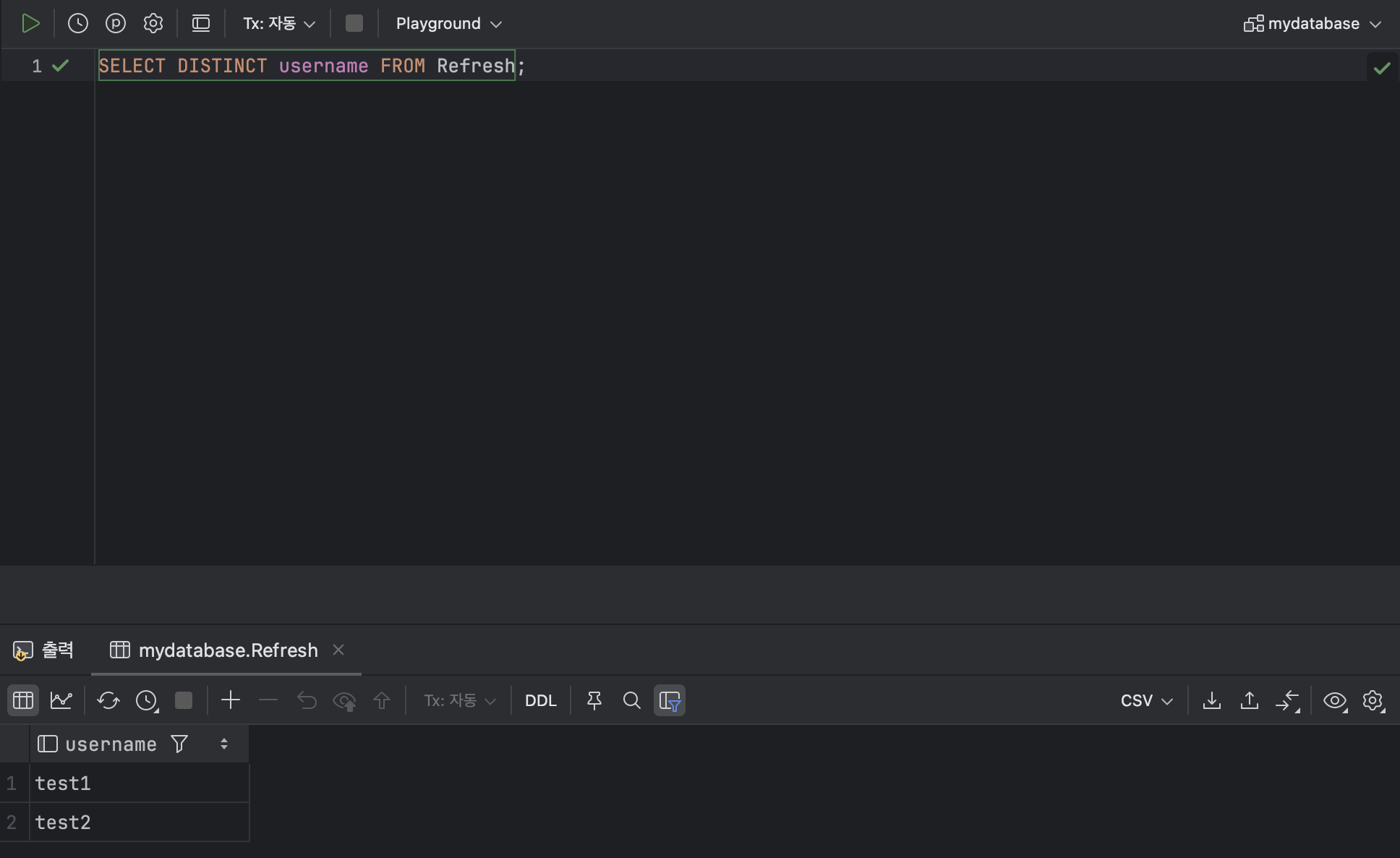
7 ) 외래키 조작
-
외래키 ( Foreign Key )
: 한 테이블의 컬럼 ( Column ) 이 다른 테이블의 기본키 ( Primary Key ) 를 참조하는 키를 의미한다.
관계형 데이터베이스는 데이터의 무결성을 유지하기 위해 부모 테이블에 없는 데이터가 자식 테이블에 있으면 안 되는 것이 원칙이다. 해당 원칙을 유지함으로써 데이터가 잘못 입력되거나 삭제되는 것을 방지한다.
- 외래키로 연결되어 있는 테이블에 데이터 입력 및 삭제
먼저 테이블 2개를 생성해서 부모-자식 관계를 형성한다.
CREATE TABLE kangwooju_parent (col_1 INT PRIMARY KEY);
CREATE TABLE kangwooju_child (col_1 INT);
ALTER TABLE kangwooju_child;
ADD FOREIGN KEY (col_1) REFERENCES kangwooju_parent;이때 , REFERENCE KEY를 등록하는 테이블이 **자식 테이블**이며 REFERENCES를 받는 테이블이 **부모 테이블**이다. 외래키로 연결된 경우 부모 테이블에 값이 먼저 등록되어야 한다. 만일 자식 테이블에 데이터를 먼저 입력하는 경우 다음과 같은 오류가 발생한다.
mysql> insert into kangwooju_child values (1);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`woojuice_ex`.`kangwooju_child`, CONSTRAINT `kangwooju_child_ibfk_1` FOREIGN KEY (`col_1`) REFERENCES `kangwooju_parent` (`col_1`))따라서 부모 테이블에 데이터를 입력한 후에 자식 테이블에 데이터를 입력해야 한다.
INSERT INTO kangwooju_parent VALUES (1);
INSERT INTO kangwooju_child VALUES (1);
SELECT * FROM kangwooju_parent (1);
SELECT * FROM kangwooju_child (1);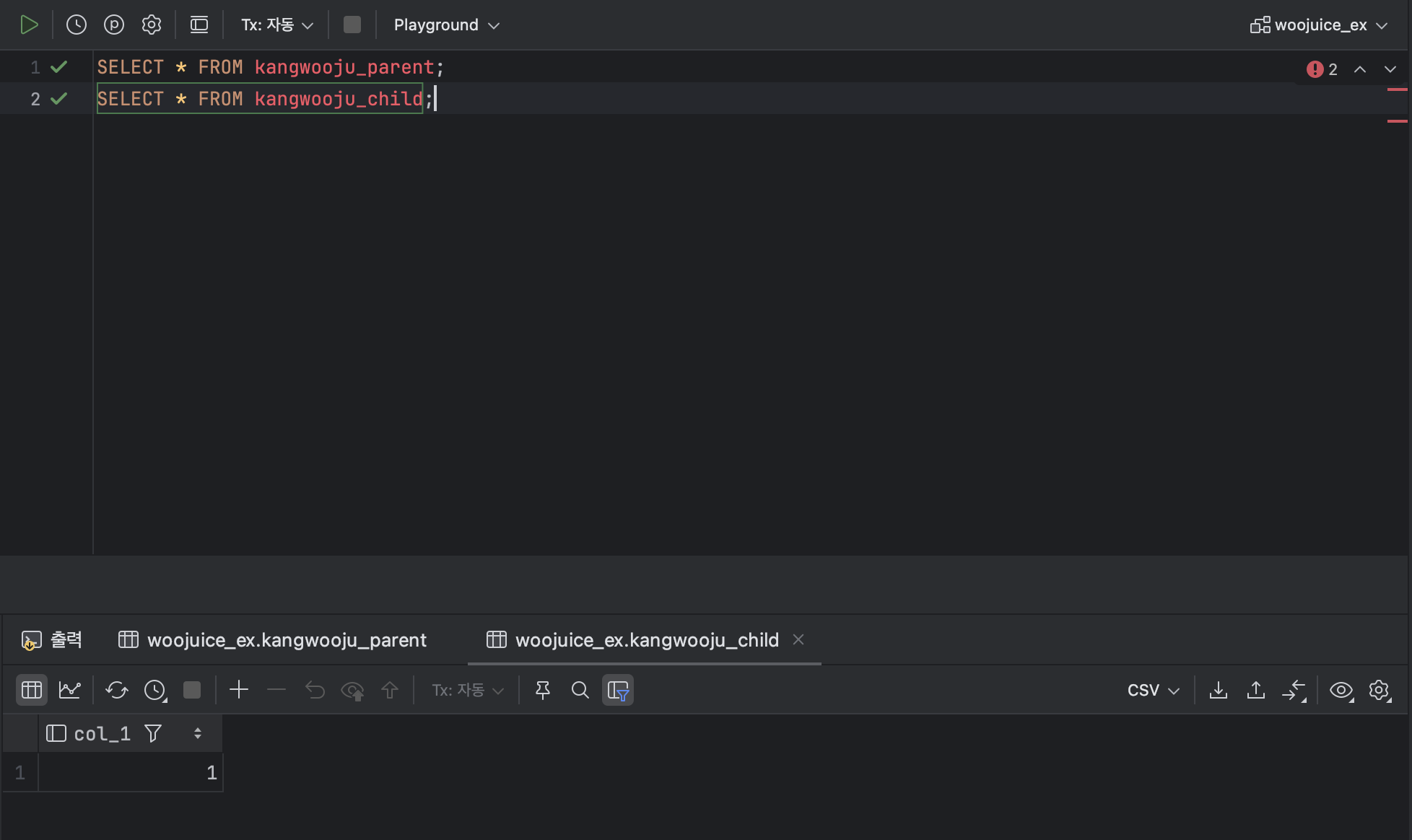
다음으로 데이터의 삭제의 경우 자식 -> 부모 순서대로 데이터 삭제를 실행해야 한다. 이는 마치 자료구조의 스택 ( Stack ) 구조와 유사하다.
부모 -> 자식 순으로 쌓인 스택에서 스택을 push 할때는 부모 -> 자식 순서로 실행해야 하며 pop을 실행할때는 자식 -> 부모 순서로 실행되기 때문이다.
테이블 삭제도 마찬가지로 하위 테이블 -> 상위 테이블 순서로 이루어져야 한다.
- 1 : 1 관계
: 데이터베이스는 릴레이션 ( Relation ) 을 통해 테이블간의 관계를 나타낸다. 이때 , Primary Key 와 Foreign Key의 조합을 통해 참조 관계를 형성한다.
MySQL에서는 각 Primary키 와 참조하는 key에 Unique 옵션을 부여함으로써 1 : 1 매핑 관계를 형성할 수 있다.
8 ) MySQL 데이터 유형
-
정수형
: 기본적으로 부호를 갖는 SIGNED 형식으로 저장되어 음수와 양수를 동시에 저장할 수 있다. 부호를 갖지 않는 UNSIGNED 형식도 존재하며 해당 형식은 0보다 큰 양의 정수를 더 많이 저장할 수 있어 최대값이 SIGNED 형식보다 2배 커진다.
데이터유형 데이터 크기(byte) 숫자 범위(SIGNED) 숫자 범위(UNSIGEND) TINYINT 1 -128 ~ 127 0 ~ 255 SMALLINT 2 -32,768 ~ 32,767 0 ~ 65535 MEDINUMINT 3 -8388608 ~ 8388607 0 ~ 16777215 INT 4 -2^31 ~ 2^31 -1 0 ~ 2^32-1 BIGINT 8 -2^63 ~ 2^63-1 0 ~ 2^64-1
-
실수형
: 실수형에는 고정 소수점 형식 과 부동 소수점 형식이 존재한다.
① 고정 소수점
: 고정 소수점의 경우 숫자 값의 길이가 변화해도 소수점의 자리가 변하지 않는다.
데이터 유형 데이터 크기(byte) 숫자 범위 FLOAT(n) 4 ~ 8 -3.40E+30 ~ 1.17E-38 DOUBLE 8 -1.22E-308 ~ 1.79E+308
② 부동 소수점
: 부동 소수점의 경우 숫자 값의 길이가 변화하면 유효 범위의 소수점 자리가 바뀐다. 이러한 이유로 부동 소수점을 사용하면 정확한 유효 소수점의 값을 식별하기 어렵고 , 부동 소수점으로 된 값끼리의 비교가 어렵다.
데이터 유형 데이터 크기(byte) 숫자 범위 DECIMAL(p,s) 5 ~ 17 -10^38+1 ~ 10^38+1 NUMERIC(p,s) 5 ~ 17 -10^38+1 ~ 10^38+1 이때 , p는 전체 자릿수를 s는 소수 자릿수를 의미한다.
-
숫자형 변환
: 숫자형 변환은 숫자 타입끼리 변환하거나,문자열을 숫자로 변환하거나,
숫자 타입으로 변환하는 작업을 의미한다. 숫자형 변환에는 2가지가 존재한다.① 암시적 형 변환
: 암시적 형 변환은 자료형을 직접 변경하지 않아도 실행 환경에서 자동으로 자료형을 변경하는 것을 의미한다.
② 명시적 형 변환
: 명시적 형 변환은 자료형을 직접 사용자가 CAST , CONVERT 등의 함수를 사용하여 변경하는 것을 의미한다.
-
문자형
: 문자형은 다양한 문자를 저장할 수 있는 데이터 유형이다. 문자형은 고정 길이와 가변 길이로 구분이 가능하다.① 고정 길이 문자열
데이터 유형 데이터 크기(byte) 설명 CHAR(n) 1 ~ 255 고정 길이 문자열로, 0 ~ 255 크기의 문자열까지 저장 가능 BINARY(n) 1 ~ 255 고정 길이 문자열로, 0 ~ 255 크기의 문자열까지 저장 가능 ② 가변 길이 문자열
데이터 유형 데이터 크기(byte) 설명 VARCHAR(N) 1 ~ 65535 가변 길이 문자열로 , n만큼의 크기를 지정하며 0 ~ 16383 크기의 문자열까지 저장 가능 ( 한 문자당 최대 4바이트 사용 ) VARBINARY(n) 1 ~ 65335 가변 길이 문자열로, 0 ~ 16383 크기의 문자열까지 저장 가능
-
콜레이션 ( Collation )
: 콜레이션은 문자열 데이터가 담긴 열의 비교나 정렬 순서를 위한 규칙을 의미한다. 이를 통해 문자열의 우선순위 결정한다.
-
날짜형 및 시간형
: 날짜 및 시간을 저장하는 데이터 유형이다.데이터 유형 데이터 크기(byte) 설명 TIME 3 HH:MM:SS (시:분:초) 형태의 데이터를 사용한다. 범위는 -838:59:59 ~ 838:59:59이다. DATE 3 날짜만 있는 데이터에 사용하고 , YYYY-MM-DD ( 연-월-일 ) 형태이다. 범위는 1000-01-01 ~ 9999-12-31이다. DATETIME 8 날짜와 시간을 모두 포함하는 데이터에 사용하고 , YYYY-MM-DD hh:mm:ss[.fraction] 형식이다. TIMESTAMP 4 날짜와 시간 부분을 모두 포함하는 데이터에 사용하고 , 범위는 1970-01-01 00:00:01 UTC ~ 2038-01-19 03:14:07 UTC이다. 이때 , DATETIME 데이터 유형은 문자형이며 TIMESTAMP 데이터 유형은 숫자형이다. 또한 UTC 날짜 데이터 유형의 경우 데이터를 저장할 때 자동으로 입력된다.
