GIF 출처 : https://logpresso.store/ko/apps/mysql
🖥 Contents
1 ) 문자열 함수
2 ) 날짜 함수
3 ) 집계 함수
4 ) 수학 함수
5 ) 순위 함수
6 ) 분석 함수
1 ) 문자열 함수
- 문자열과 문자열을 연결하는 함수 : CONCAT
< CONCAT 기본 형식 >
CONCAT(' 문자열 1 ' , ' 문자열 2 ' , ... )ex )
SELECT CONCAT(first_name, ' , ', last_name) AS customer_name FROM customer;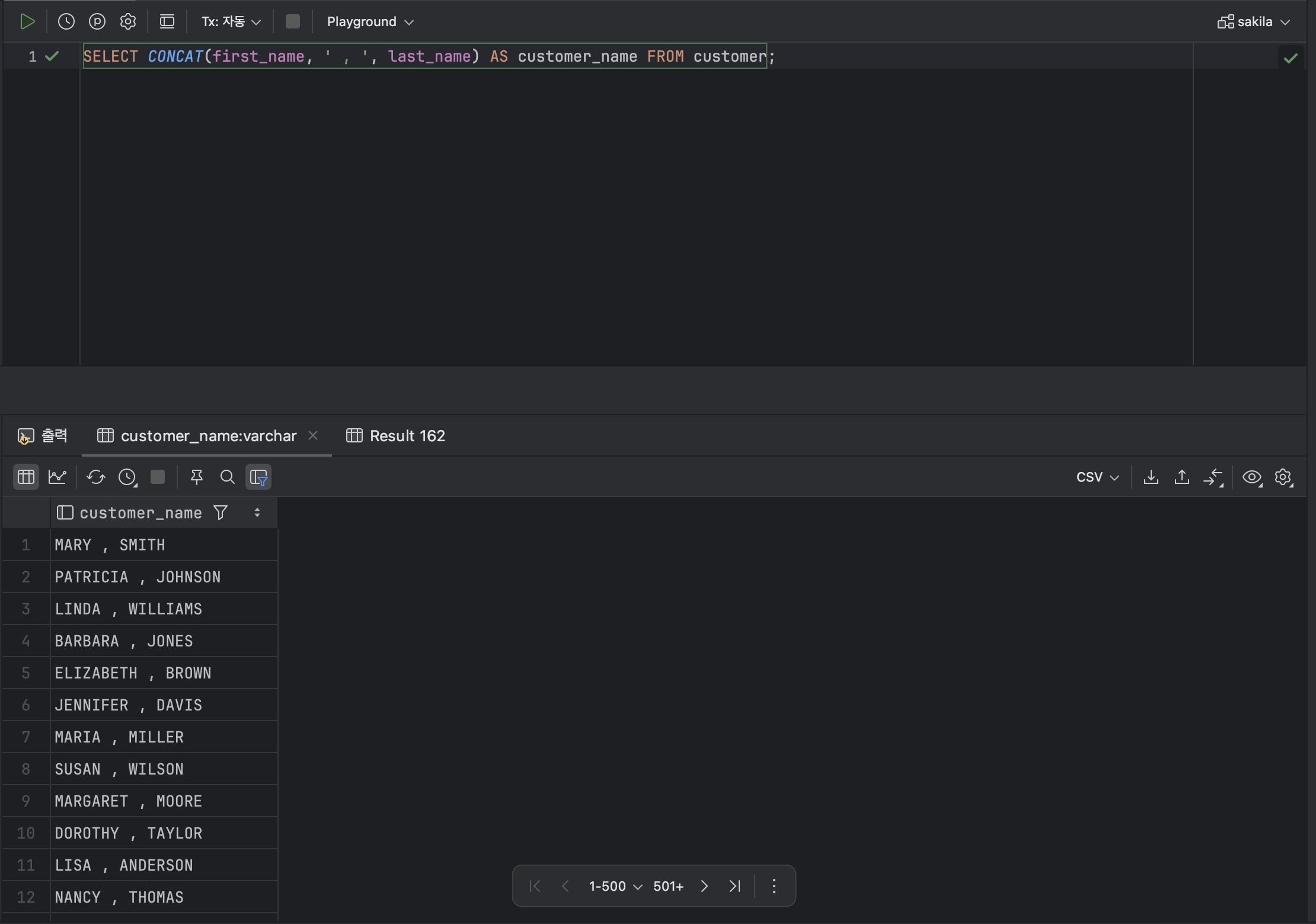
⭐️ CONCAT_WS 함수로 구분자 추가하기
: CONCAT_WS 함수는 CONCAT과 달리 연결하는 문자열들에 대해서 각 문자열 사이에 구분자를 추가할 수 있게 한다 .
ex )
SELECT CONCAT_WS(', ' , first_name, last_name , email) AS customer_name FROM customer;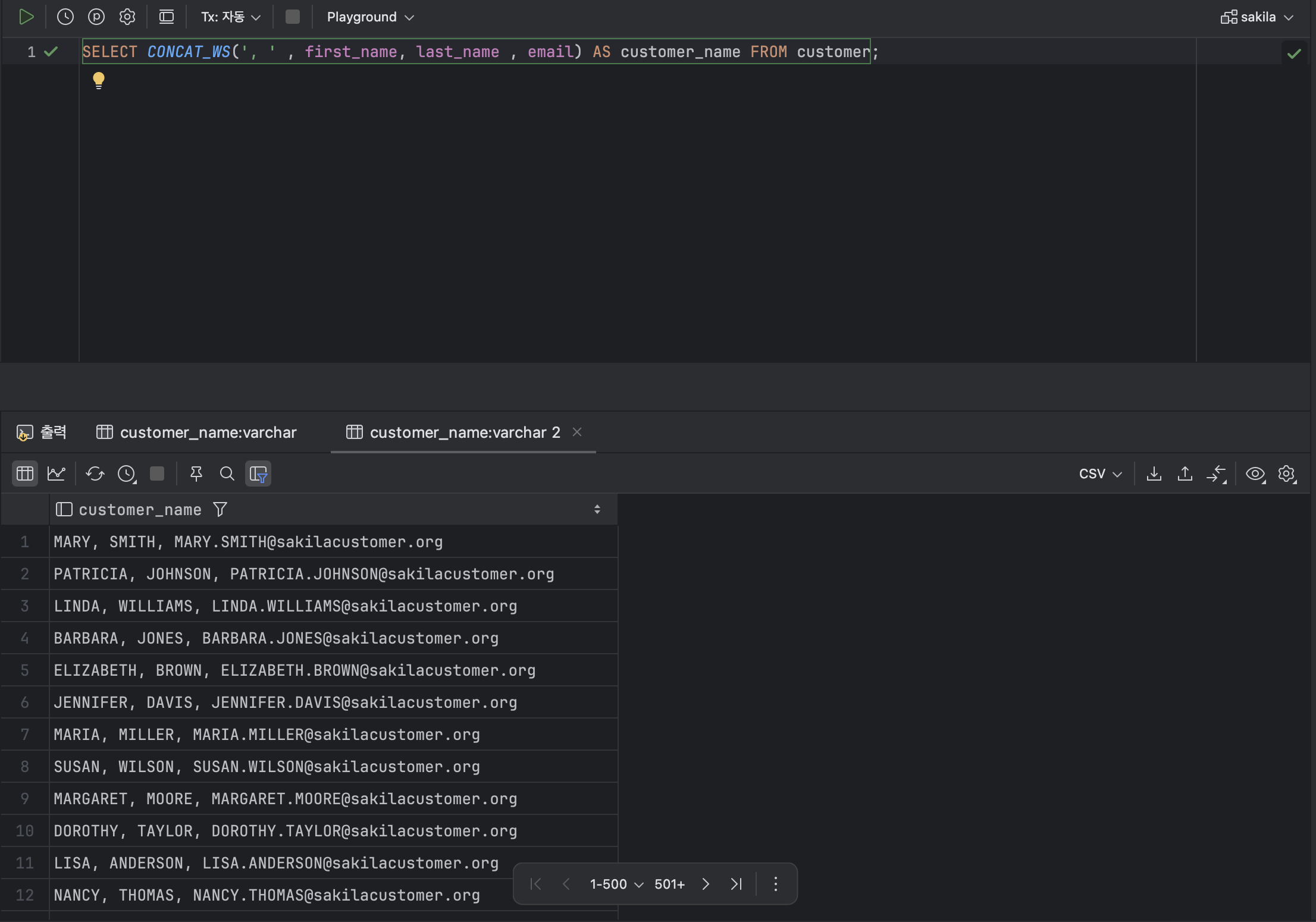
- 데이터 형 변환 함수 : CAST , CONVERT
: 숫자를 날짜로 또는 날짜를 숫자로 변환하는 등 데이터를 다양한 형태로 변환해야하는 경우 사용자가 임의로 형을 변경할 수 있다. 이를 명시적 형 변환 이라고 한다. 명시적 형 변환을 위해 사용하는 함수로는 CAST 와 CONVERT가 있다.
💫 ① CAST
< CAST 기본 형식 >
SELECT CAST ( [ 열 ] AS [ 데이터 유형 ] ) FROM [ 테이블 명 ];ex )
SELECT CAST(20250430 AS CHAR);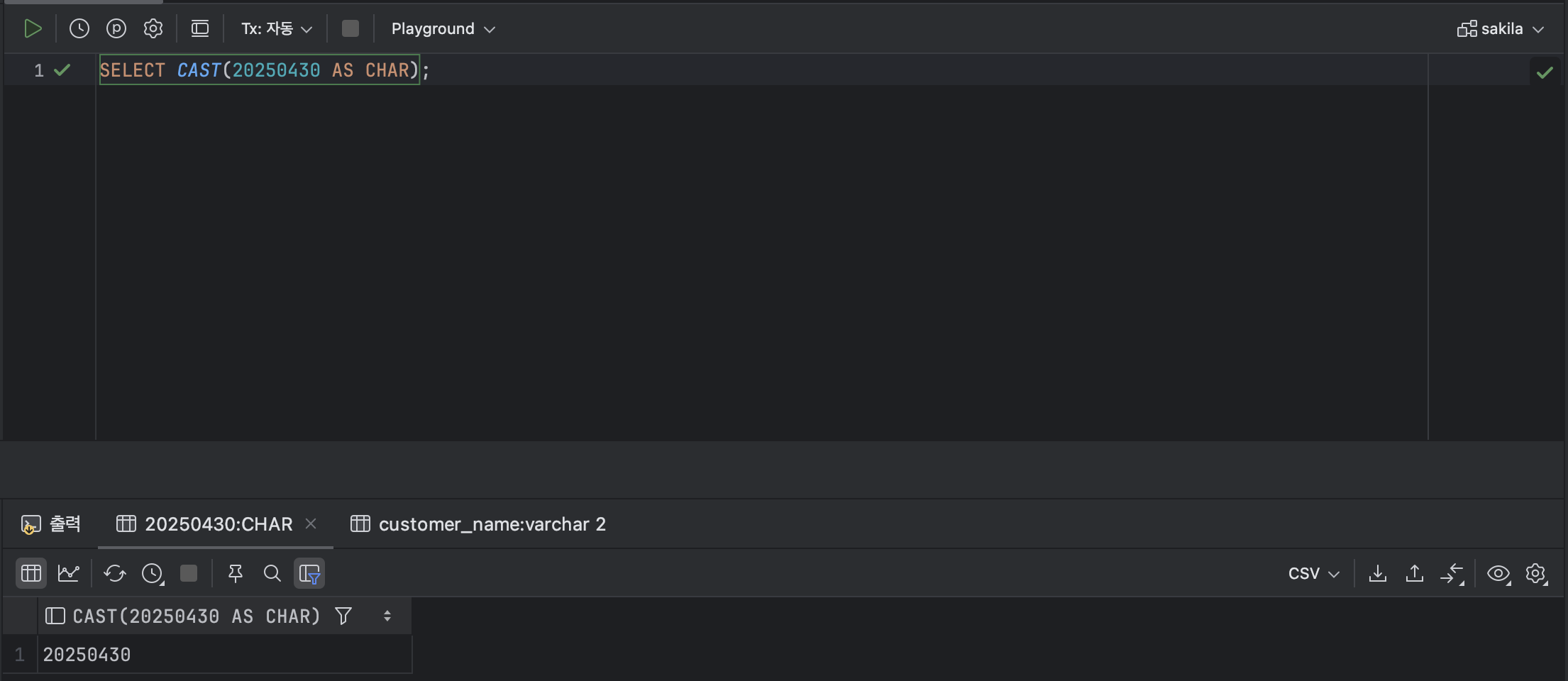 : 숫자형 데이터를 CHAR 형 데이터로 명시적 형 변환을 실시한 결과이다.
: 숫자형 데이터를 CHAR 형 데이터로 명시적 형 변환을 실시한 결과이다.
💫 ② CONVERT
< CONVERT 기본 형식 >
SELECT CONVERT ( [ 열 ] , [ 데이터 유형 ] ) FROM 테이블 ex )
SELECT CONVERT(20250430,DATE);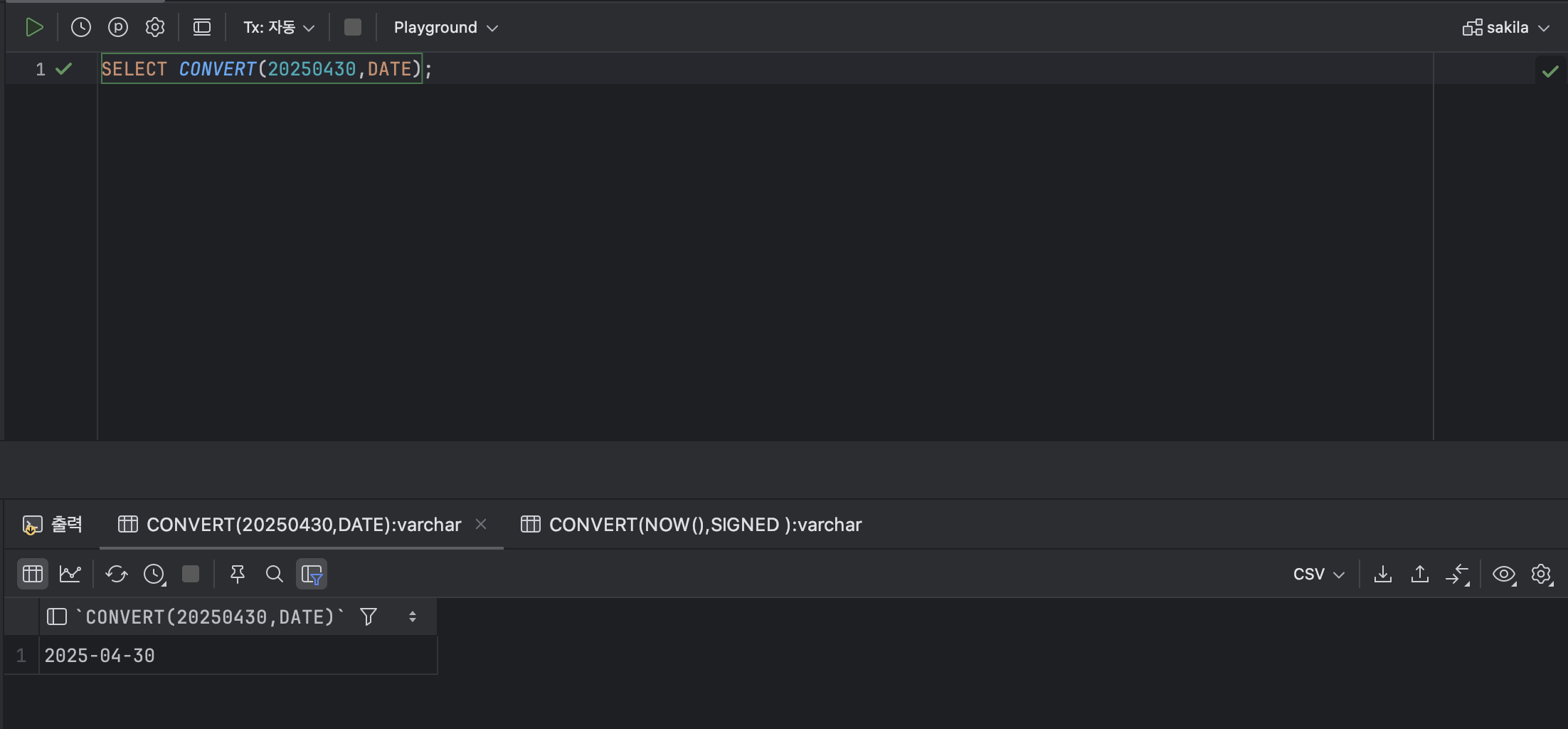 : 숫자형 데이터를 날짜형 데이터로 변경하였다. CAST 와 달리 CONVERT에서는 CAST에서 지원하지 않는 스타일을 정의할 수 있다.
: 숫자형 데이터를 날짜형 데이터로 변경하였다. CAST 와 달리 CONVERT에서는 CAST에서 지원하지 않는 스타일을 정의할 수 있다.
- NULL을 대체하는 함수 : IFNULL , COALESCE
: NULL은 어떠한 연산 작업을 진행하여도 반환되므로 해당 함수를 통해 문자열 혹은 숫자 데이터로 변환이 필요하다.  다음과 같은 테이블의 구조를 예시로 NULL 대체 함수를 사용해보면 다음과 같다.
다음과 같은 테이블의 구조를 예시로 NULL 대체 함수를 사용해보면 다음과 같다.
💫 ① IFNULL
< IFNULL 기본형식 >
IFNULL( [ 열 ] , [ 대체할 값 ] ) ex )
SELECT col_1 , IFNULL(col_2, '') AS col_2 , col_3 , col_4 , col_5
FROM woojuice_null WHERE col_1 = 1;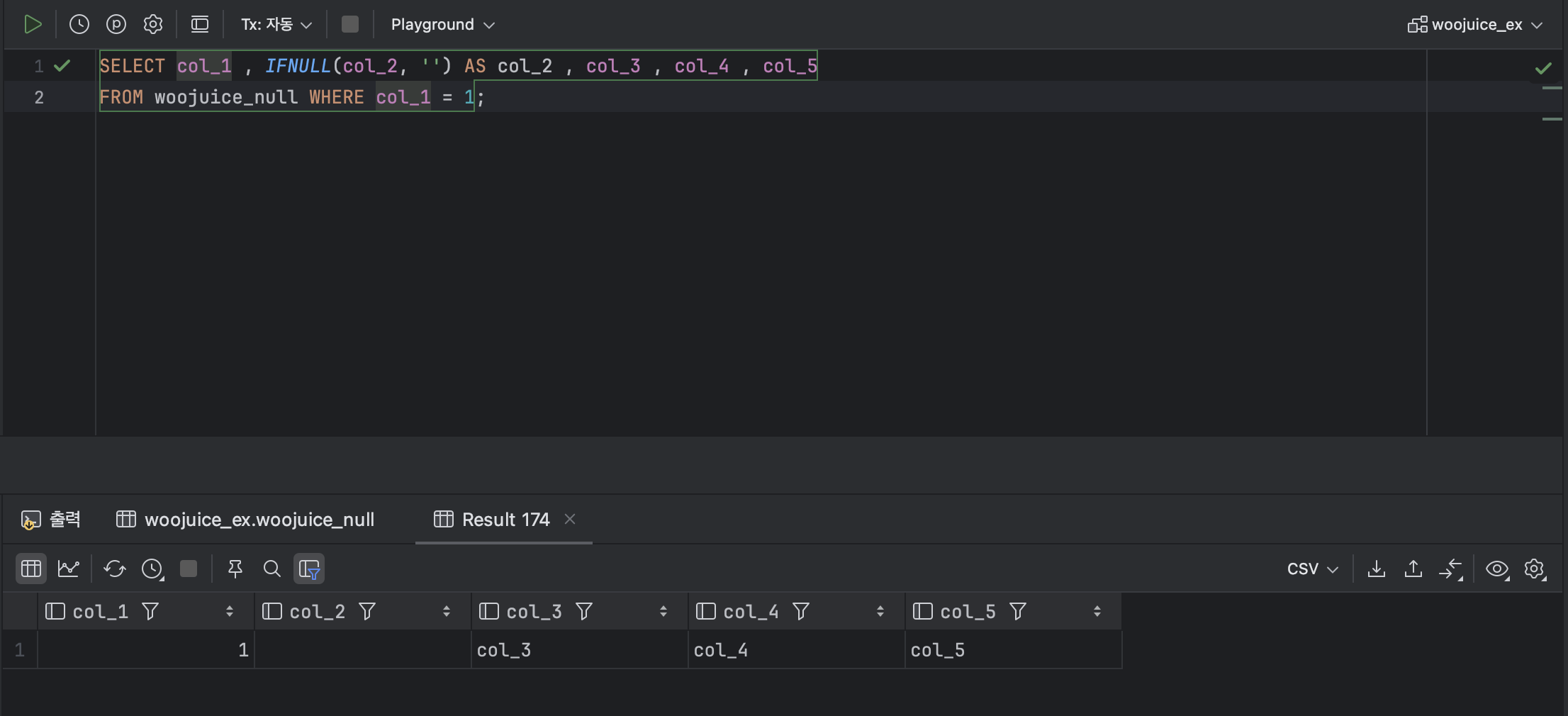 : col_2가 null 에서 ''공백 문자로 변경되었음을 확인할 수 있다.
: col_2가 null 에서 ''공백 문자로 변경되었음을 확인할 수 있다.
💫 ② COALESCE
< COALESCE 기본형식 >
COALESCE ( 열 1 , 열 2 , ... ) ex )
SELECT col_1 , COALESCE(col_2,col_3,col_4,col_5)
FROM woojuice_null WHERE col_1 = 2;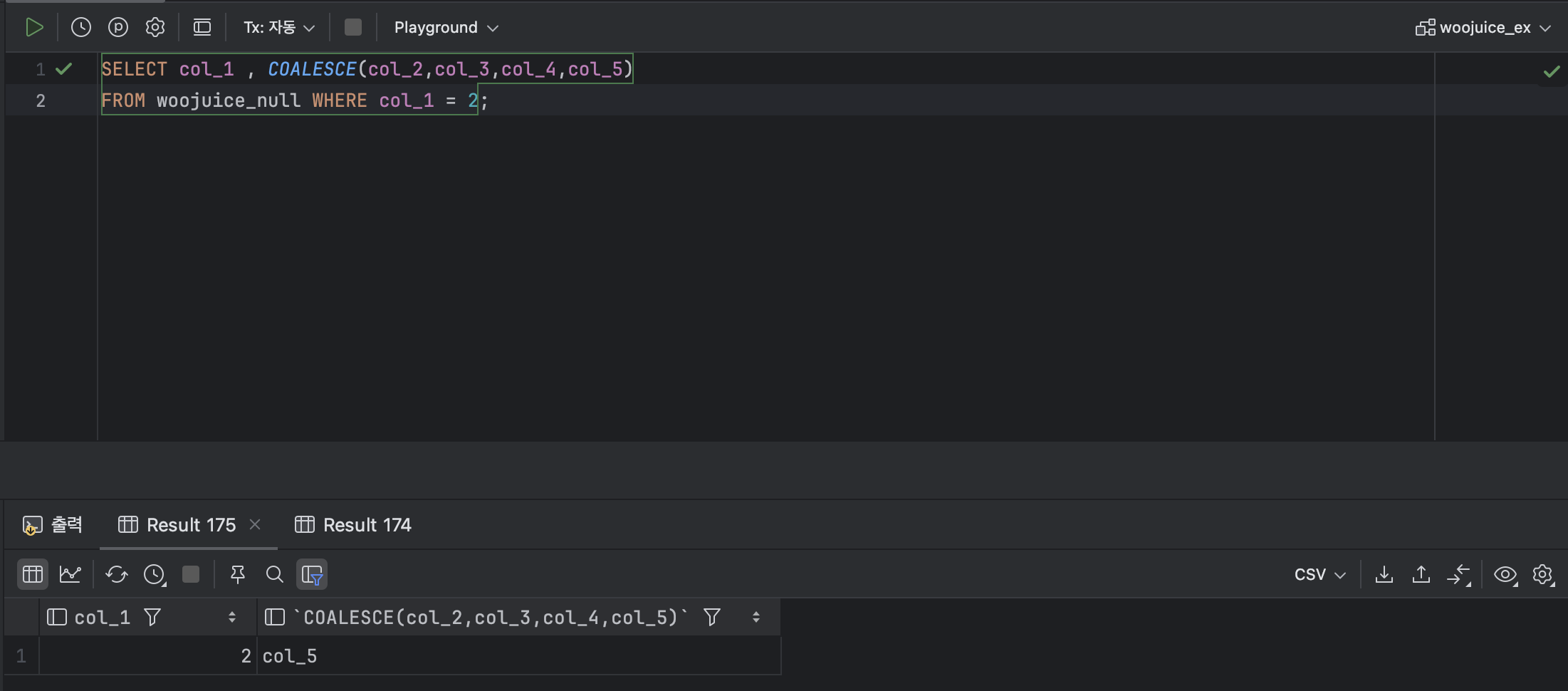 : COALESCE 함수는 첫 번째 인자로 전달한 열에 NULL이 있을 때 , 그 다음 인자로 작성한 열의 데이터로 대체한다.
: COALESCE 함수는 첫 번째 인자로 전달한 열에 NULL이 있을 때 , 그 다음 인자로 작성한 열의 데이터로 대체한다.
- 소문자 or 대문자로 변경하는 함수 : LOWER , UPPER
: 해당 함수들은 대문자 <-> 소문자로의 명시적 형 변환 함수이다.
💫 ① LOWER
< LOWER 기본형식 >
LOWER ( [ 열 ] ) ex )
SELECT 'WOOJUICE_VELOG' , LOWER ('WOOJUICE_VELOG');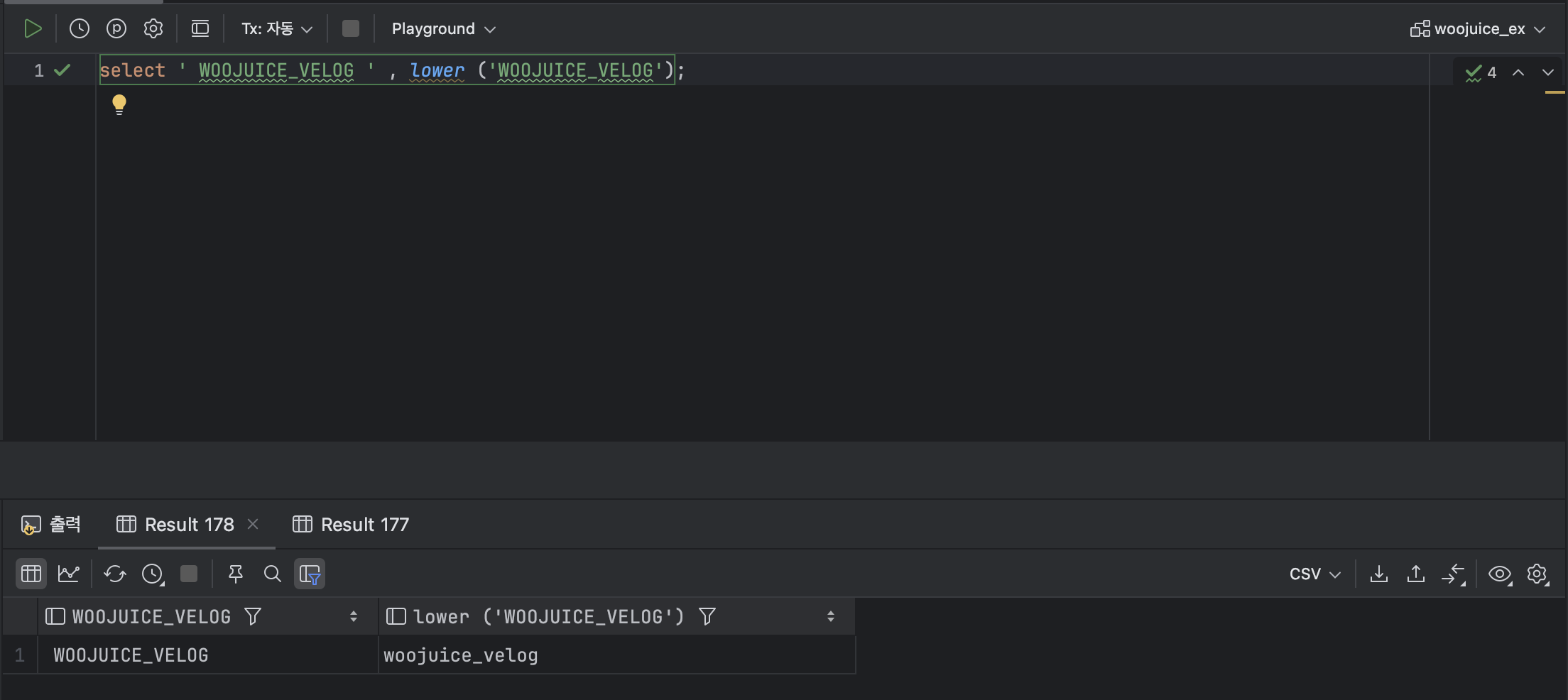
💫 ② UPPER
< UPPER 기본형식 >
UPPER ( [ 열 ] ) ex )
SELECT 'woojuice_velog' , UPPER ('woojuice_velog');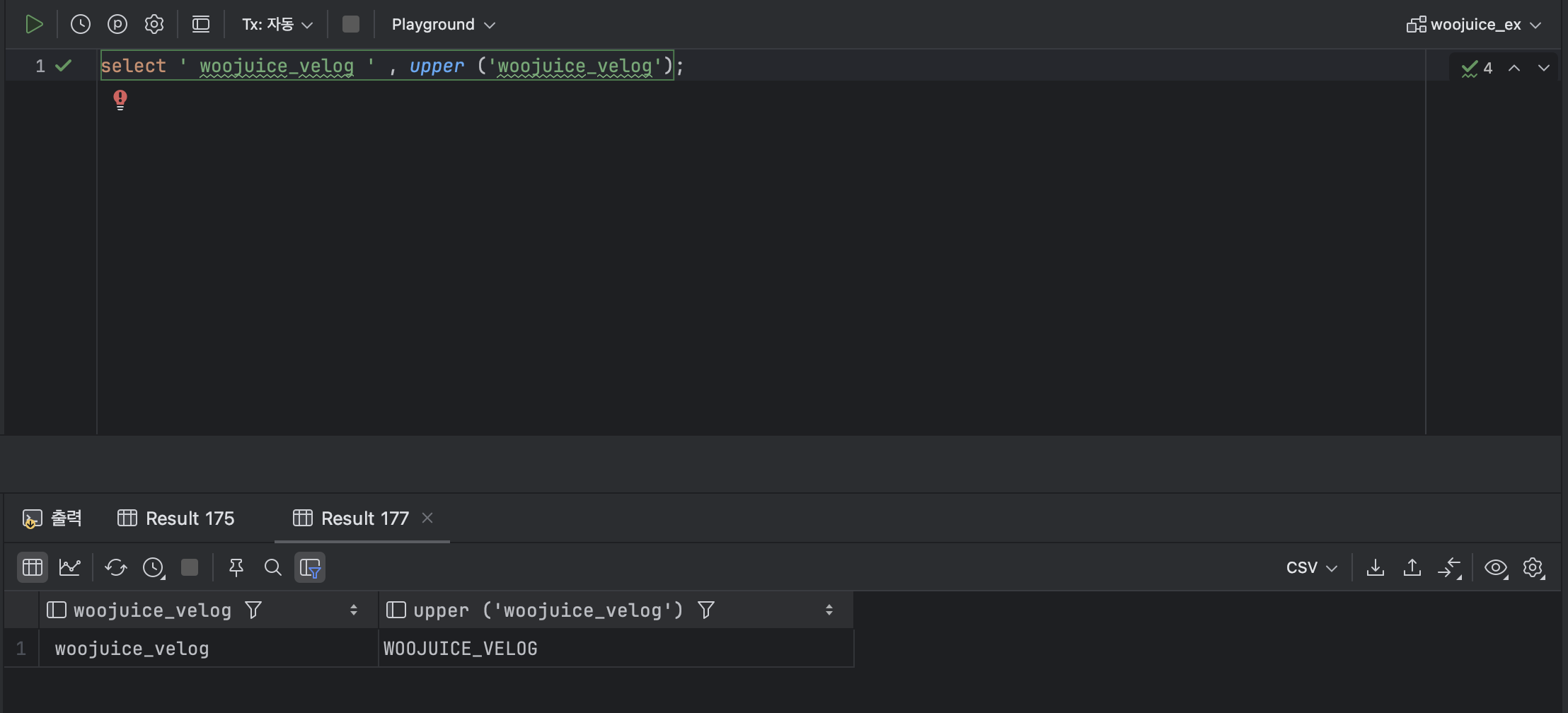
- 공백 제거 함수 : TRIM , RTRIM , LTRIM
💫 ① TRIM
: 기준점으로부터 양쪽에 존재하는 공백을 제거한다.
< TRIM 기본형식 >
SELECT '[ 문자열 ]' , TRIM('[ 문자열]');💫 ② RTRIM
: 기준점으로부터 오른쪽에 존재하는 공백을 제거한다.
< RTRIM 기본형식 >
SELECT '[ 문자열 ]' , RTRIM('[ 문자열]');💫 ③ LTRIM
: 기준점으로부터 왼쪽에 존재하는 공백을 제거한다.
< LTRIM 기본형식 >
SELECT '[ 문자열 ]' , LTRIM('[ 문자열]');
- 문자열 크기 or 개수를 반환하는 함수 : LENGTH , CHAR_LENGTH
💫 ① LENGTH
: LENGTH 함수는 문자열의 크기를 ' 바이트 ' 단위의 길이로 표현한다. 공백은 1바이트 , 한글과 한자는 3바이트 , 특수문자는 3바이트를 차지한다.
< LENGTH 기본형식 >
SELECT LENGTH('[문자열]');💫 ② CHAR_LENGTH
: CHAR_LENGTH는 LENGTH와 달리 문자열의 개수를 반환하는 함수이다.
< CHAR_LENGTH 기본형식 >
SELECT CHAR_LENGTH('[문자열]');
- 지정 문자까지의 문자열 길이 반환 : POSITION
: POSTION함수는 지정한 특정 문자까지의 문자열 길이를 반환한다.
< POSITION 기본형식 >
POSITION('[문자]' IN '[문자열]');
- 지정 길이만큼 문자열을 반환하는 함수 : LEFT , RIGHT
: 왼쪽 혹은 오른쪽을 기준으로 정의한 위치만큼의 문자열을 반환한다.
💫 ① LEFT
: 기준에서 왼쪽으로의 문자열을 반환한다.
< LEFT 기본형식 >
LEFT('[문자열]',갯수);💫 ② RIGHT
: 기준에서 오른쪽으로의 문자열을 반환한다.
< RIGHT 기본형식 >
RIGHT('[문자열]',갯수);
- 지정 범위의 문자열을 반환하는 함수 : SUBSTRING
< SUBSTRING 기본형식 >
SUBSTRING('[문자열]' , 시작 인덱스 , 개수);
- 특정 문자로 대체하는 함수 : REPLACE
< REPLACE 기본형식 >
REPLACE('[문자열]', 대체 문자 , 특정 문자 );
- 문자를 반복하는 함수 : REPEAT
< REPEAT 기본형식 >
REPEAT('[문자열]' , 반복 횟수);
- 공백 문자 생성함수 : SPACE
< SPACE 기본형식 >
SPACE(공백 갯수);: SPACE의 경우 CONCAT과 함께 사용하여 문자열 내에 공백을 생성할 수 있다.
- 문자열 역순 출력함수 : REVERSE
< REVERSE 기본형식 >
REVERSE('[문자열]');
- 문자열 비교함수 : STRCMP
: STRCMP 함수는 두 문자열을 비교하여 동일한지 여부를 판단한다. 문자열이 동일한 경우 0 , 다를 경우 -1 을 반환한다.
< STRCMP 기본형식 >
STRCMP('[문자열 1]','[문자열 2]');2) 날짜 함수
- 현재 날짜나 시간을 반환하는 함수 : CURRENT_DATE , CURRENT_TIME , CURRENT_TIMESTAMP
💫 ① CURRENT_DATE
: 접속 중인 데이터베이스 서버의 현재 날짜를 반환한다.
< CURRENT_DATE 기본형식 >
SELECT CURRENT_DATE();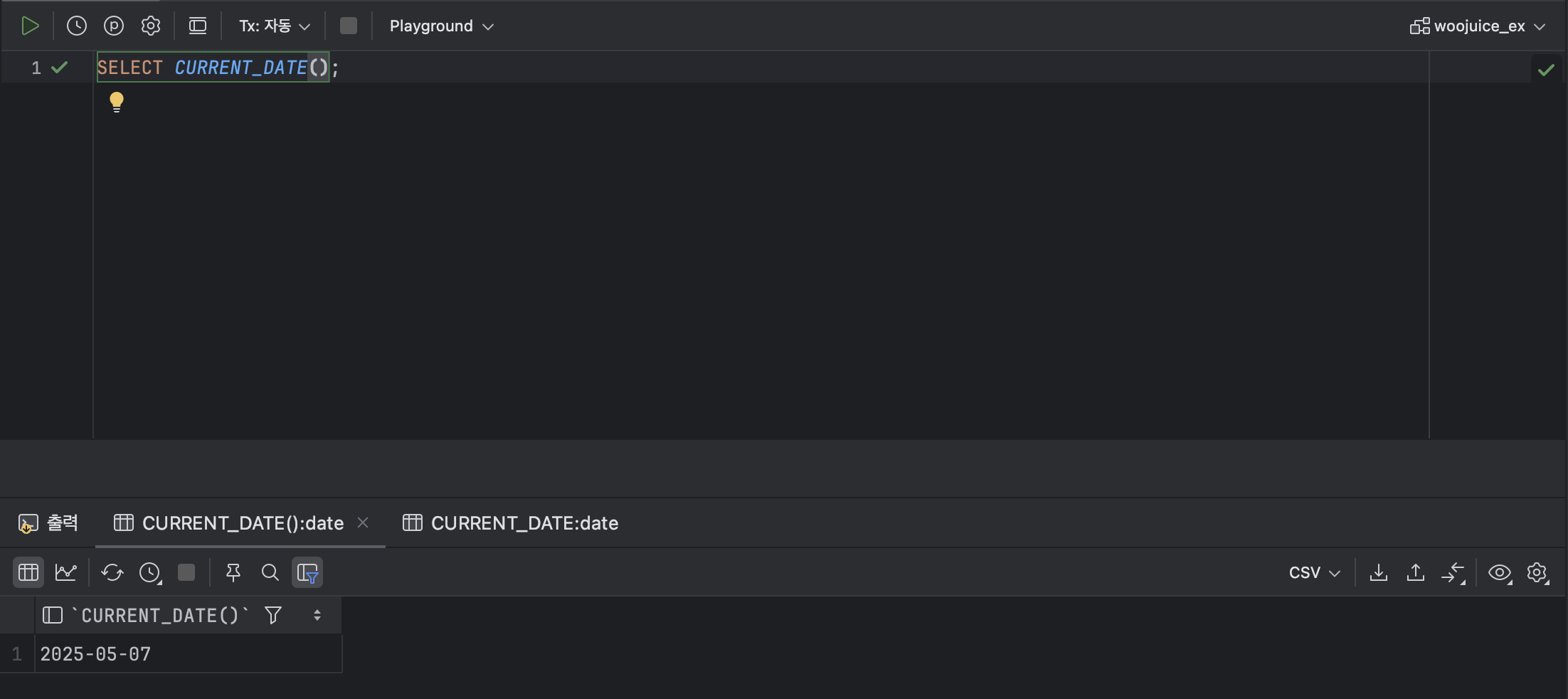
💫 ② CURRENT_TIME
: 접속 중인 데이터베이스 서버의 현재 시간을 반환한다.
< CURRENT_TIME 기본형식 >
SELECT CURRENT_TIME();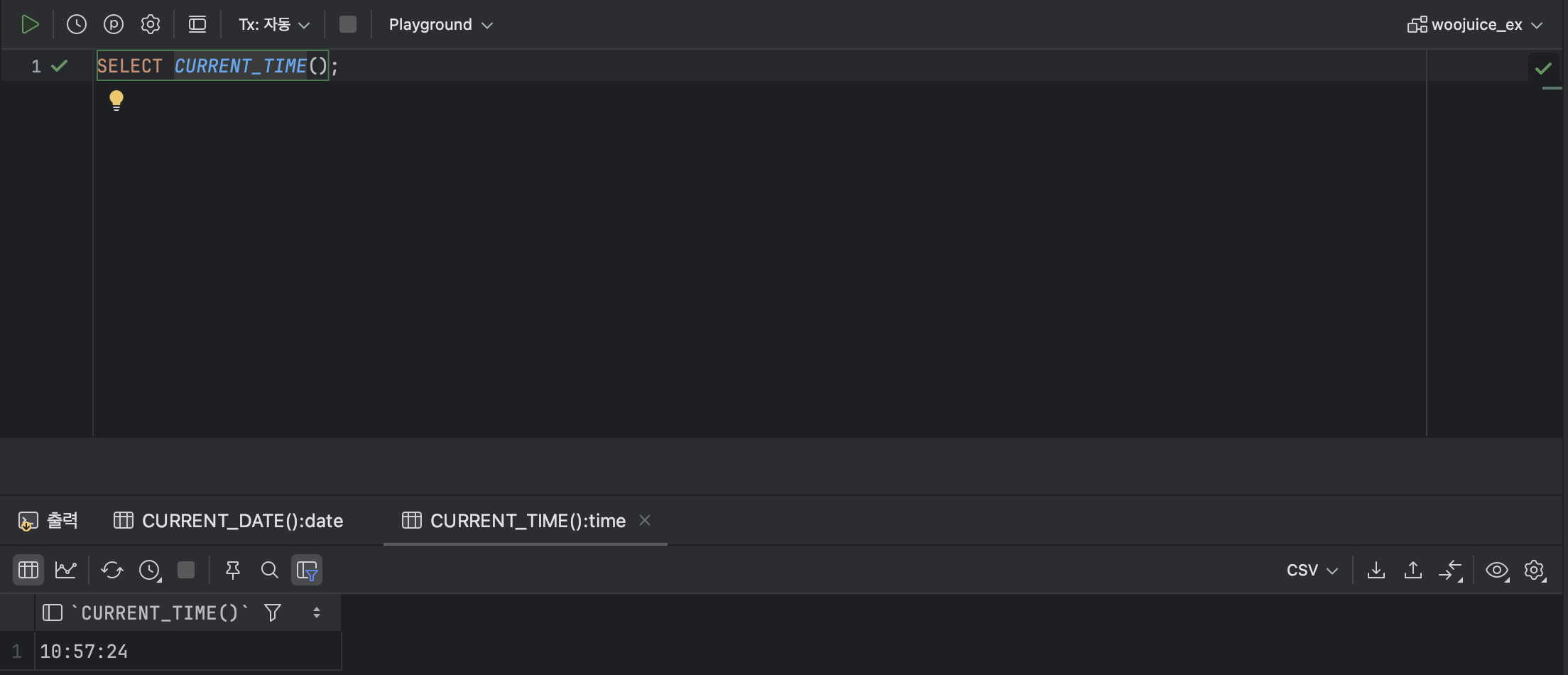
💫 ③ CURRENT_TIMESTAMP
: 접속 중인 데이터베이스 서버의 날짜와 시간을 합쳐 반환한다.
< CURRENT_TIMESTAMP 기본형식 >
SELECT CURRENT_TIMESTAMP();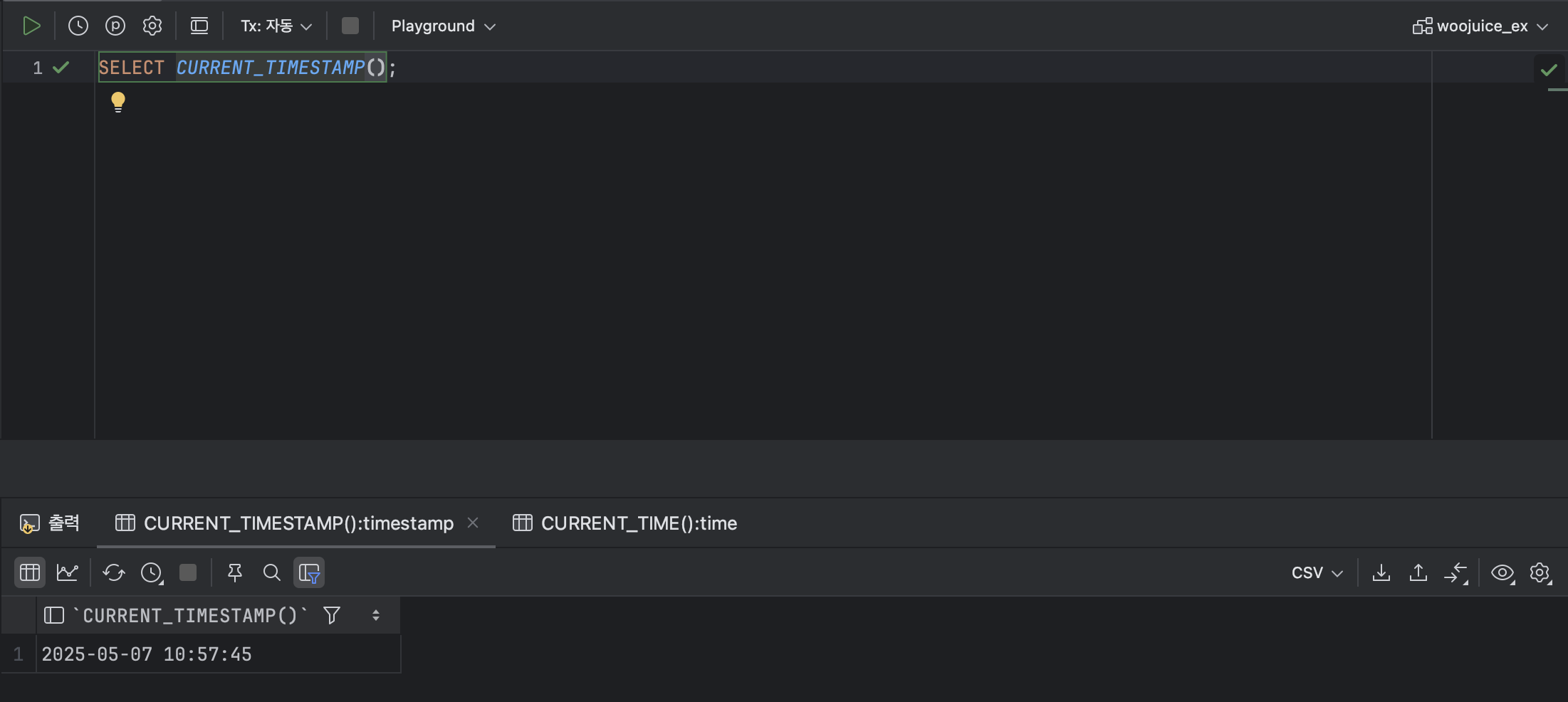
- 날짜를 더하거나 빼는 함수 : DATE_ADD , DATE_SUB
💫 ① DATE_ADD
< DATE_ADD 기본형식 >
SELECT NOW() , DATE_ADD(NOW(),INTERVAL 1 YEAR);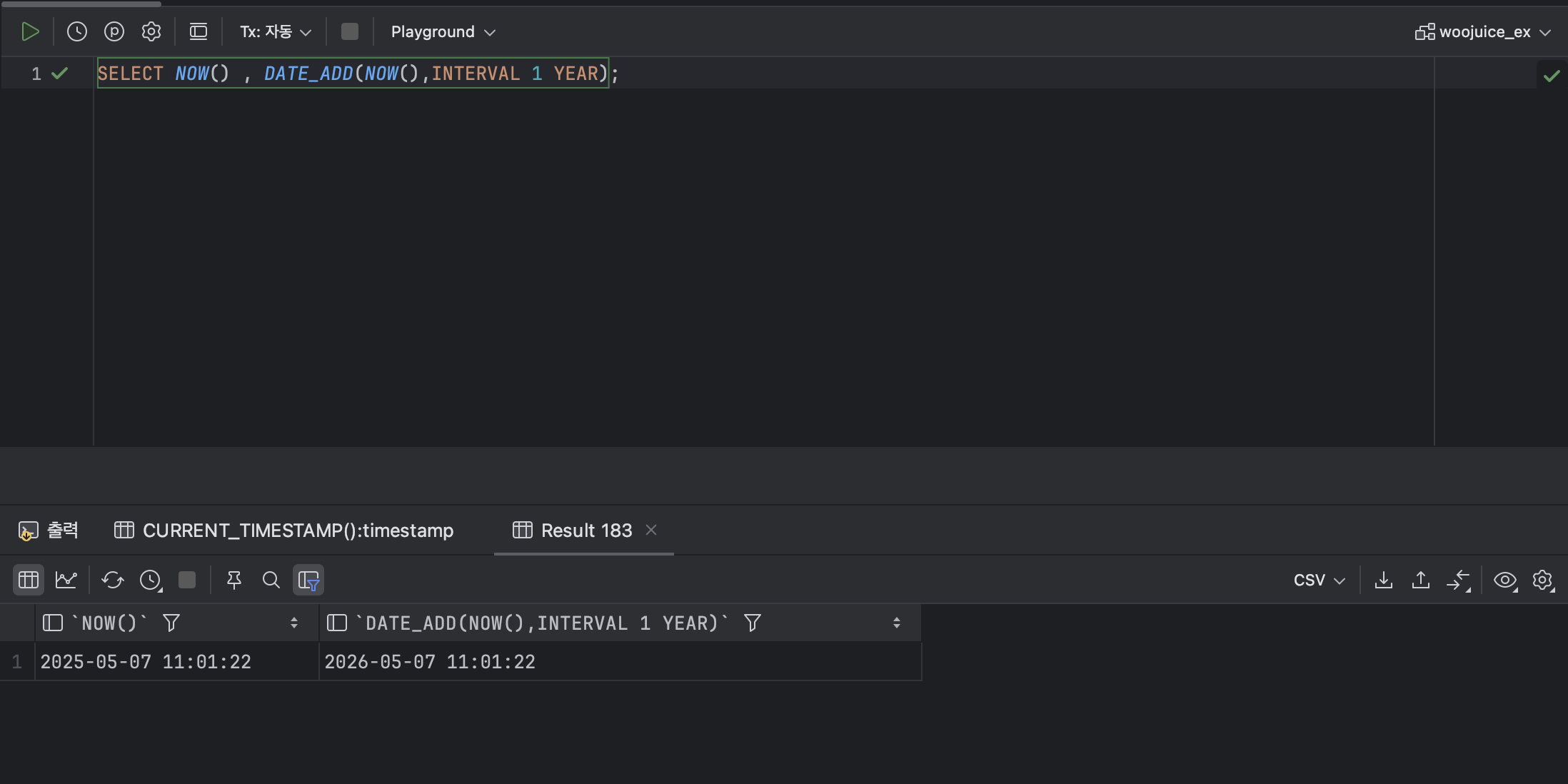
💫 ② DATE_SUB
< DATE_SUB 기본형식 >
SELECT NOW() , DATE_SUB(NOW() , INTERVAL 1 YEAR);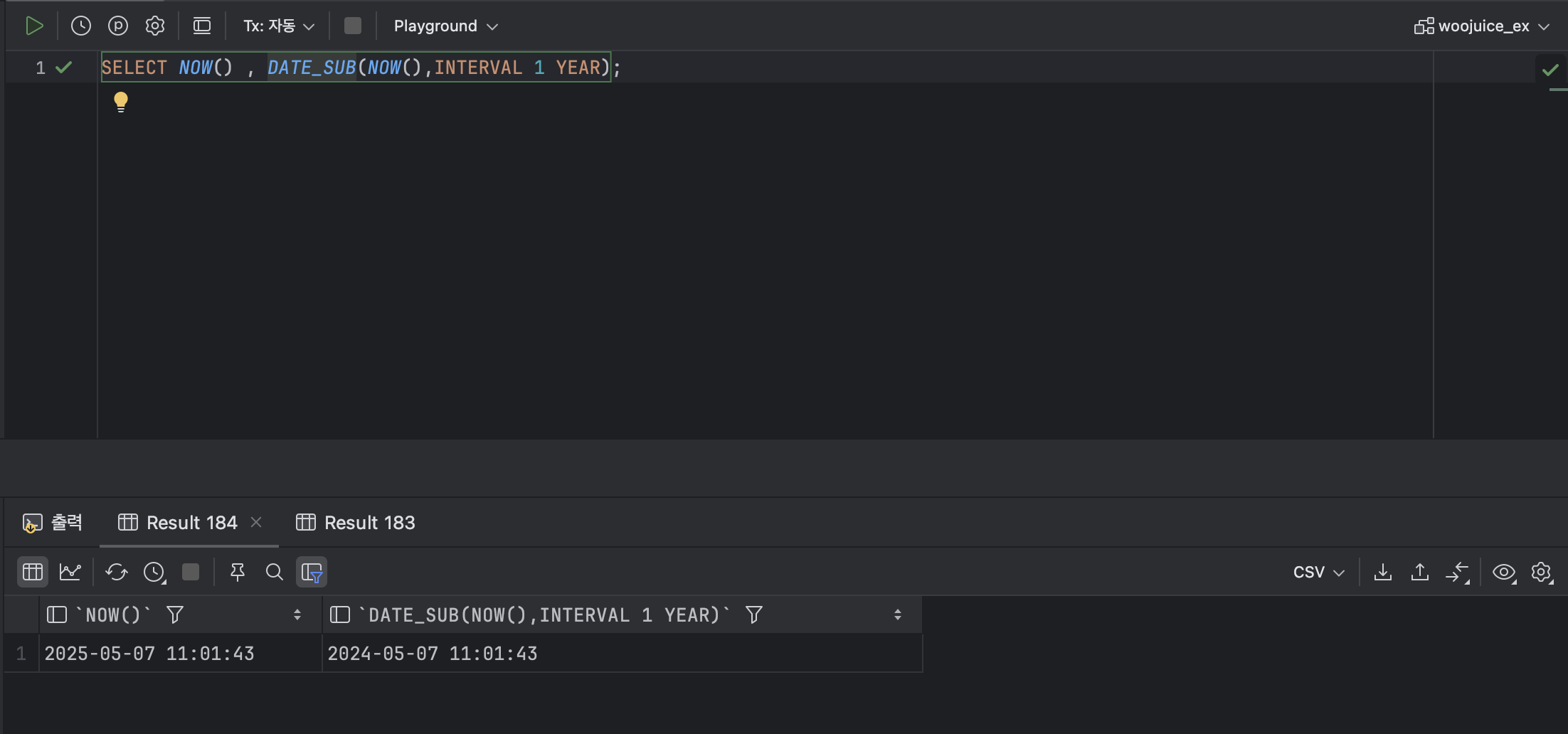 : 이때 , DATE_ADD에 음수를 입력하여 사용하면 DATE_SUB와 마찬가지로 날짜를 뺄 수 있다.
: 이때 , DATE_ADD에 음수를 입력하여 사용하면 DATE_SUB와 마찬가지로 날짜를 뺄 수 있다.
- 날짜 간 차이를 구하는 함수 : DATEDIFF , TIMESTAMPDIFF
: 날짜 간의 시간 차이를 반환하는 함수로 시작 날짜 , 종료 날짜를 인자로 받는다.
💫 ① DATEDIFF
< DATEDIFF 기본형식 >
SELECT DATEDIFF('[ DATE 1 ]' , '[ DATE 2]' );ex )
SELECT DATEDIFF(NOW(),DATE_SUB(NOW(), INTERVAL 1 YEAR));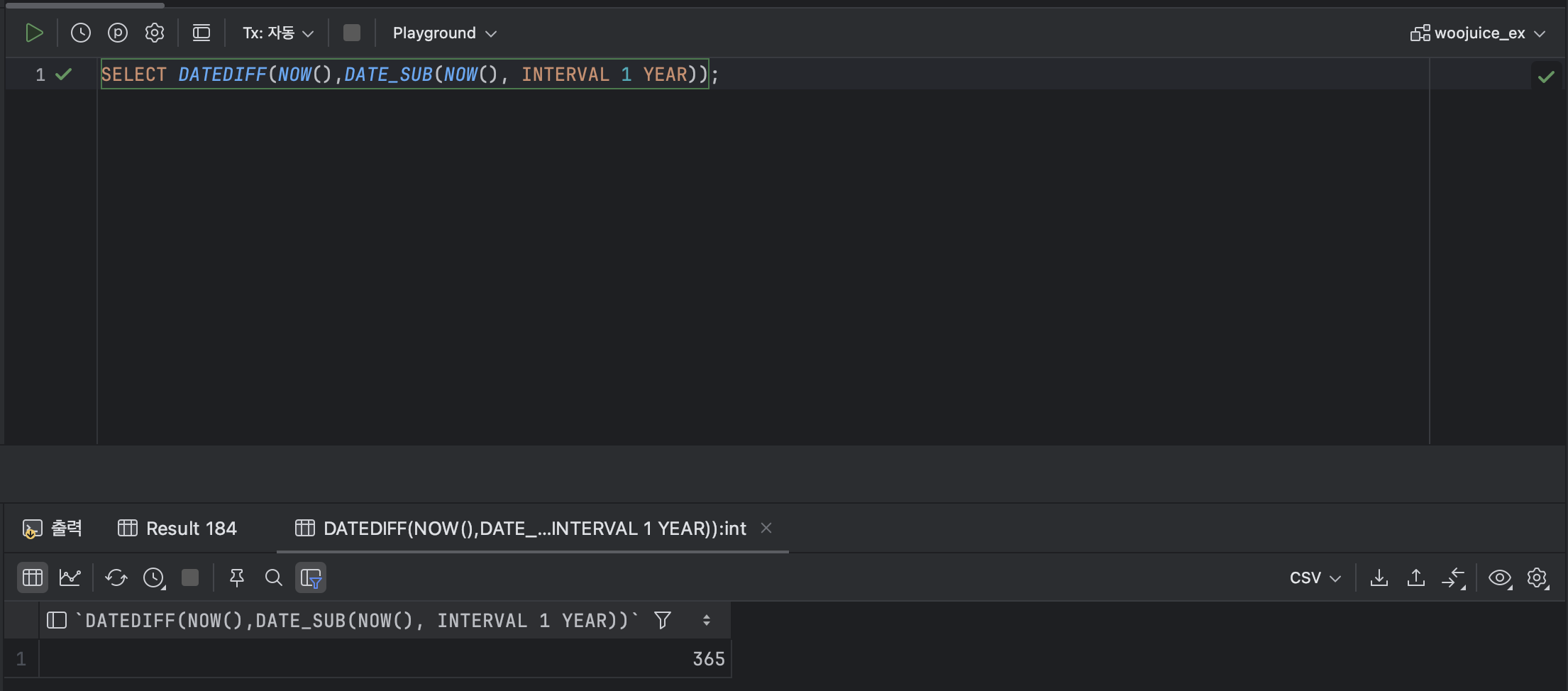
💫 ② TIMESTAMPDIFF
: TIMESTAMPDIFF의 경우 DATEDIFF와 달리 연 , 시간 등 다양한 단위의 차이로 변환할 수 있다.
< TIMESTAMPDIFF 기본형식 >
SELECT TIMESTAMPDIFF('[ TIMESTAMP 1 ]' , '[ TIMESTAMP 2 ]');ex )
SELECT TIMESTAMPDIFF(MONTH,NOW(),DATE_SUB(NOW(),INTERVAL 1 YEAR));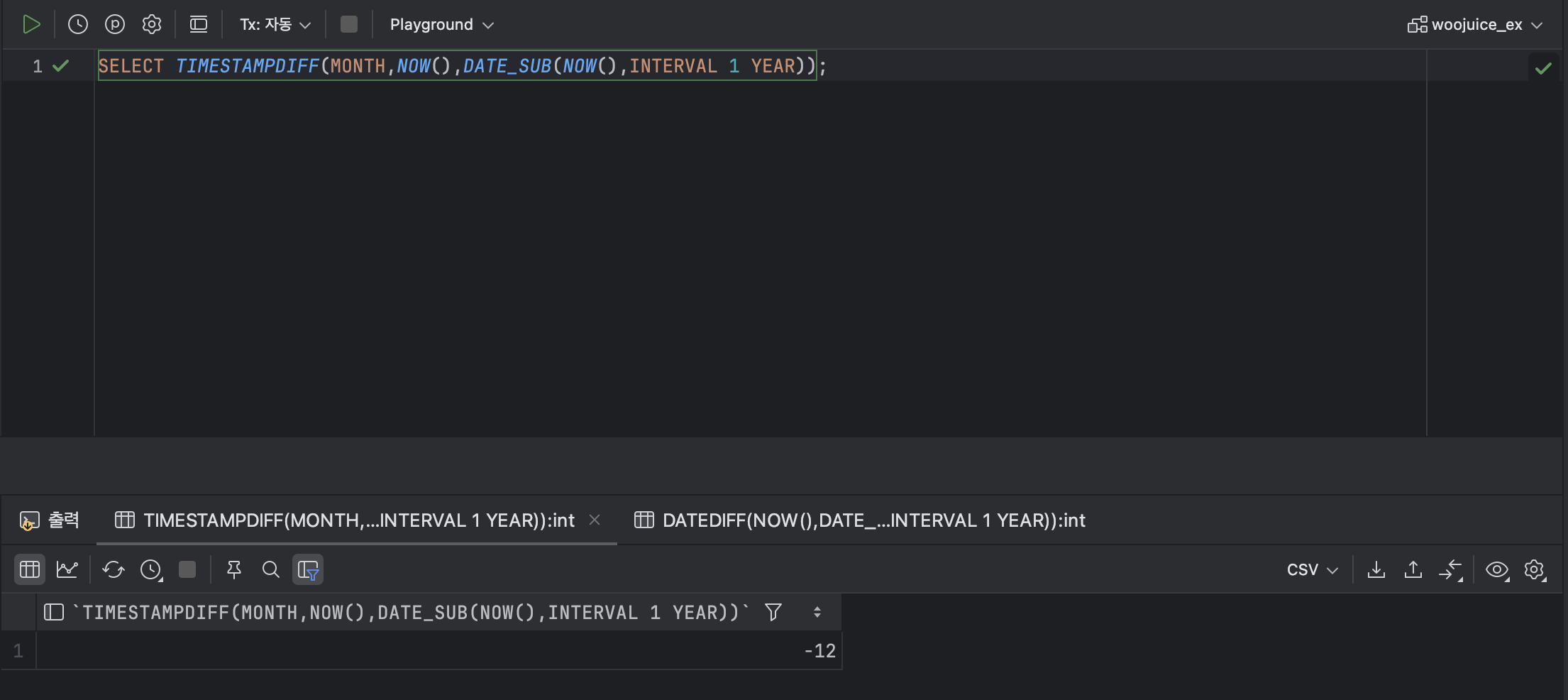
- 지정한 날짜의 요일을 반환하는 함수 : DAYNAME
: 해당하는 날짜가 어떤 요일인지를 반환하는 함수이다.
< DAYNAME 기본형식 >
SELECT DAYNAME('[날짜]');ex )
SELECT DAYNAME(NOW());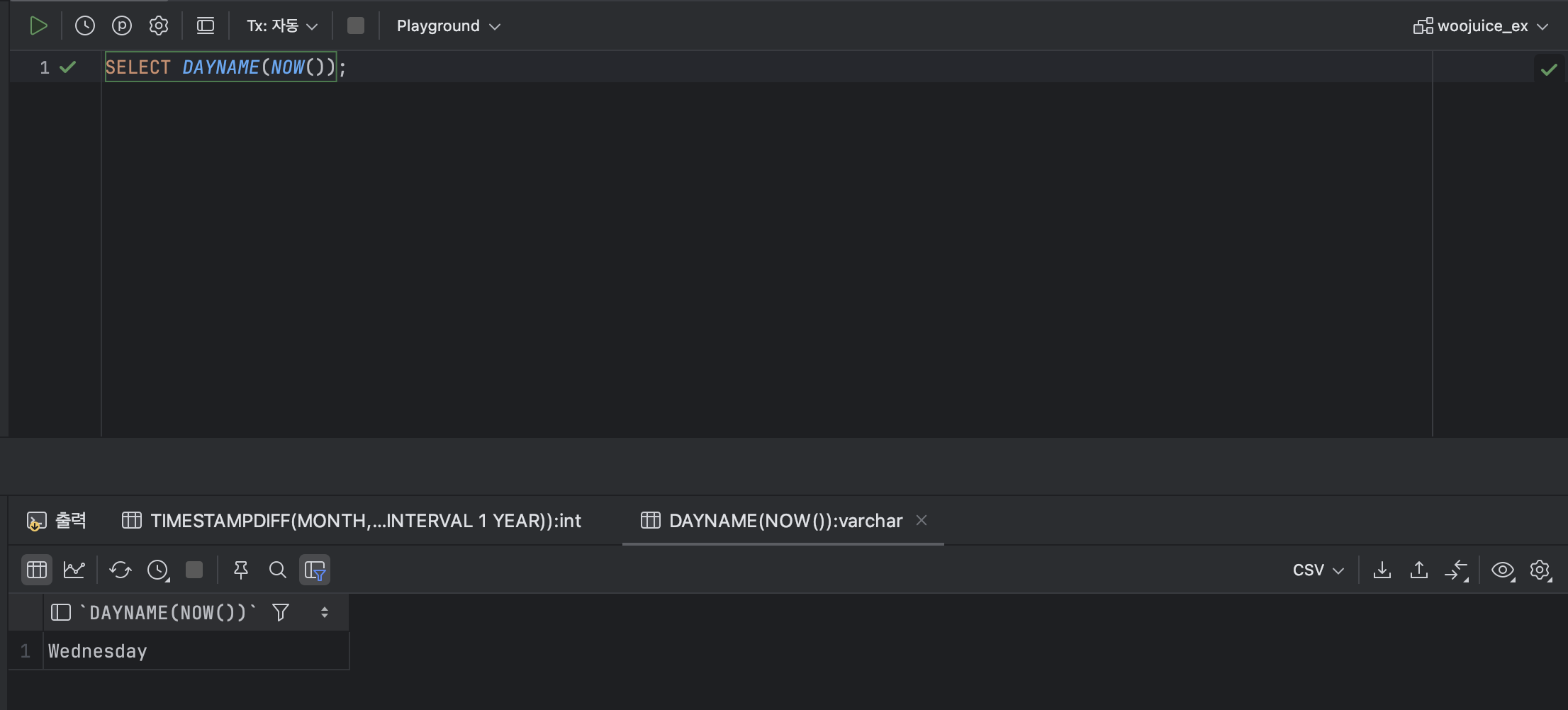
- 날짜에서 연 , 월 , 주 , 일을 값으로 가져오는 함수 : YEAR , MONTH , WEEK , DAY
< 기본 형식 >
YEAR('[ 연도 ]');
MONTH('[ 월 ]');
WEEK('[ 주 ]');
DAY('[ 일 ]');ex )
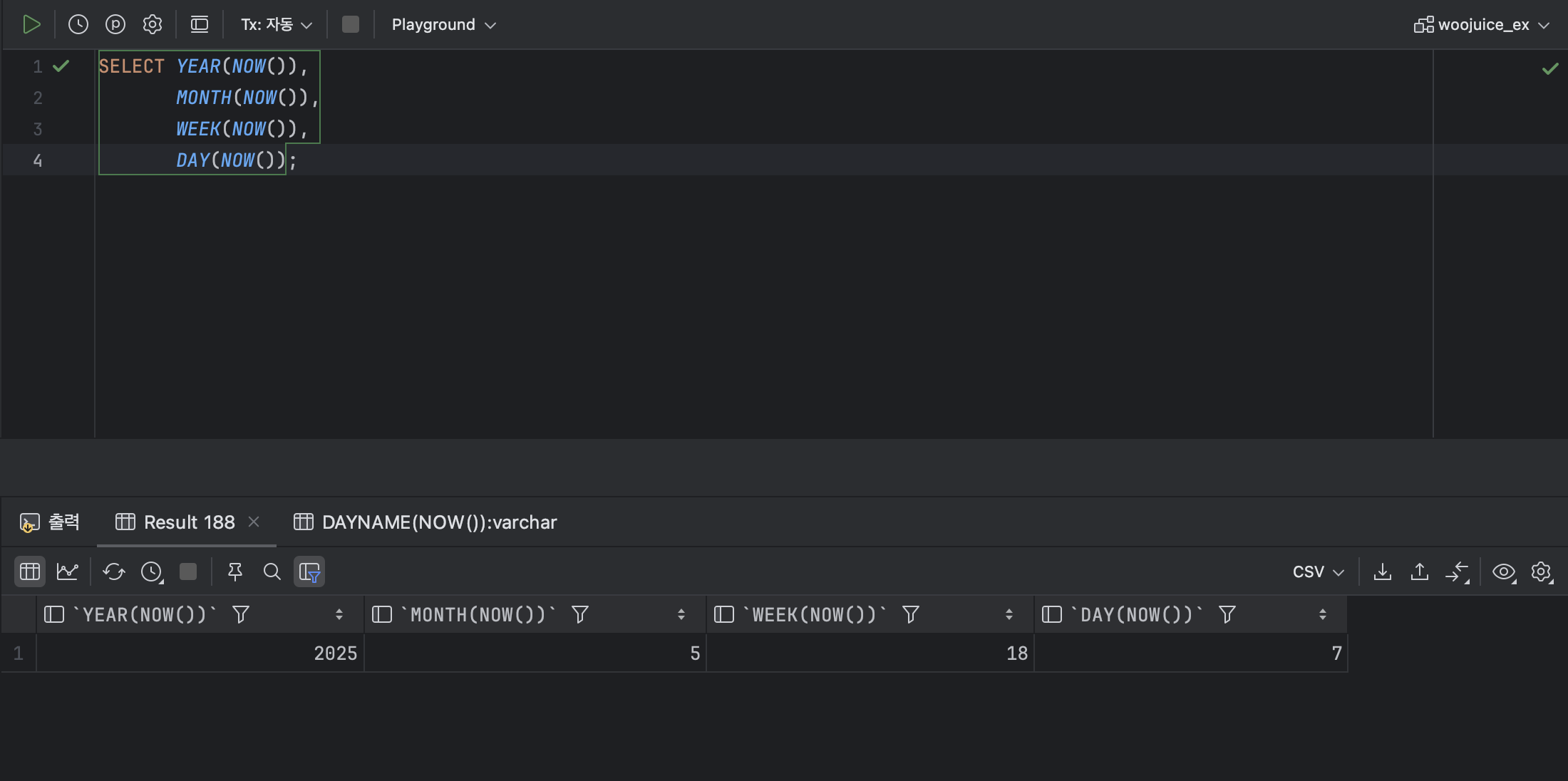
- 날짜 형식을 변환하는 함수 : DATE_FORMAT , GET_FORMAT
💫 ① DATE_FORMAT
: DATE_FORMAT 함수는 날짜를 다양한 형식으로 표현할 때 사용한다.
ex )
SELECT DATE_FORMAT(NOW(),'%m/%d/%Y');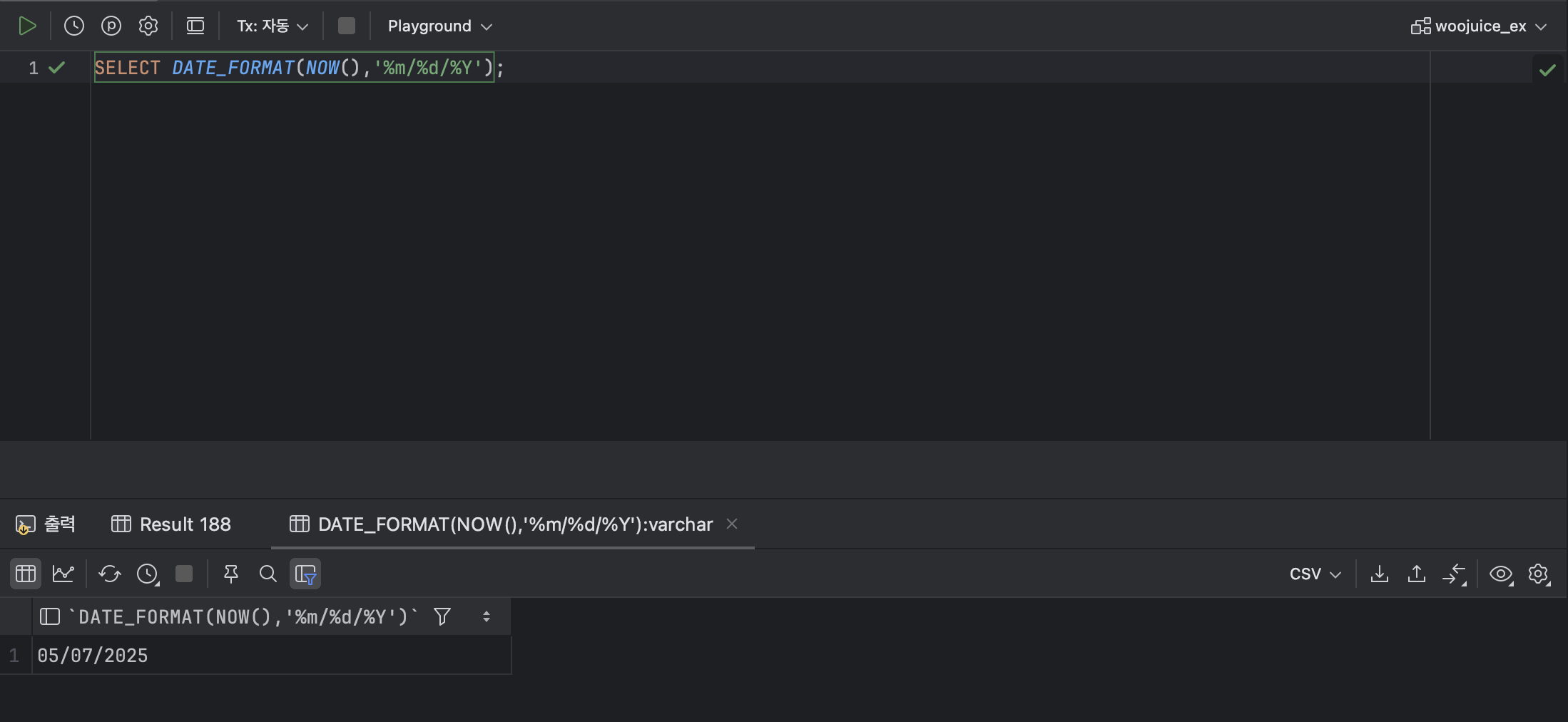
💫 ② GET_FORMAT
: GET_FORMAT은 국가나 지역별 날짜 형식을 반환하기 위해 사용하는 함수이다.
ex )
SELECT GET_FORMAT(DATE,'USA') AS USA;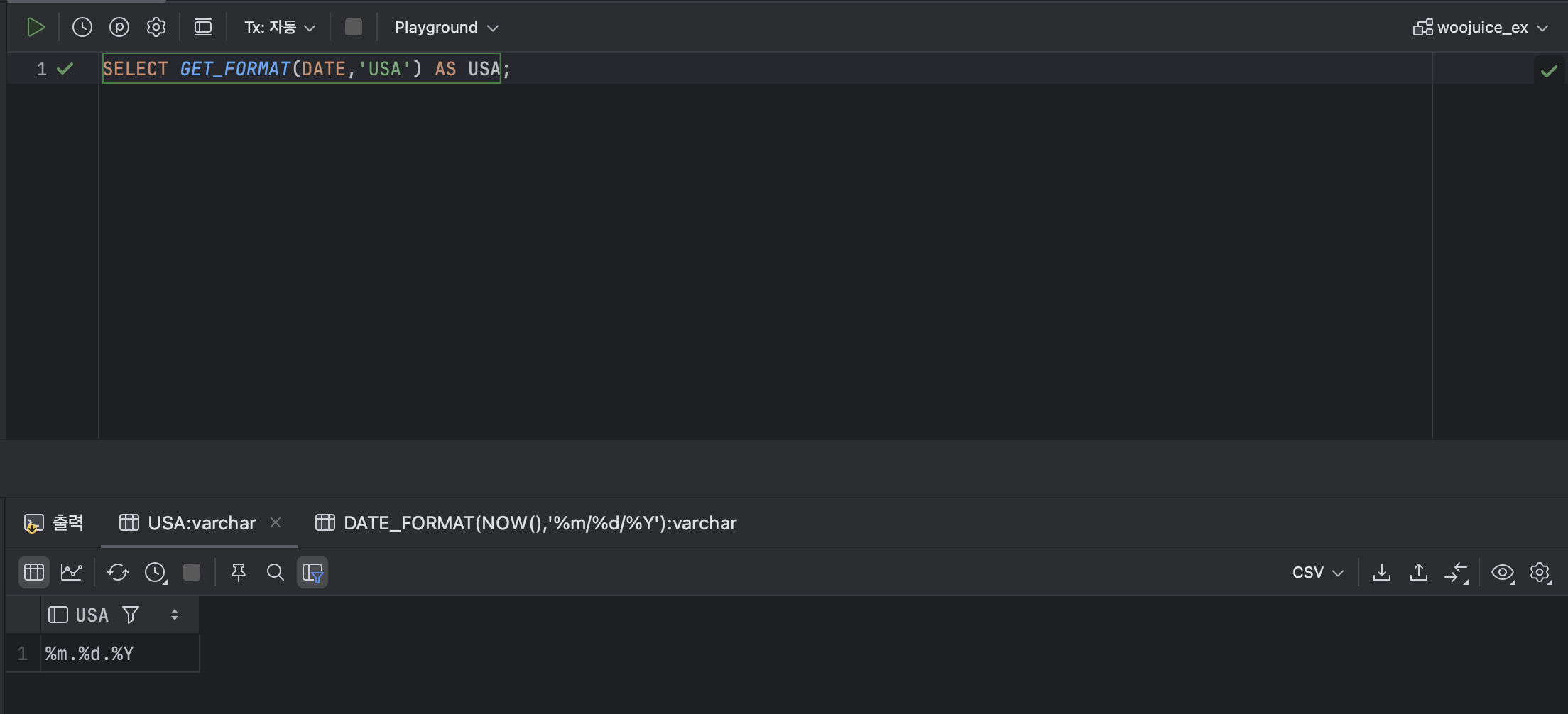
3) 집계 함수
- 조건에 맞는 데이터 개수를 세는 함수 : COUNT
: 조건에 맞는 데이터의 개수를 반환하는 함수이다. 이때 , COUNT 가 변환하는 데이터의 범위는 BIGINT 이다.
ex )
SELECT COUNT(*) FROM customer;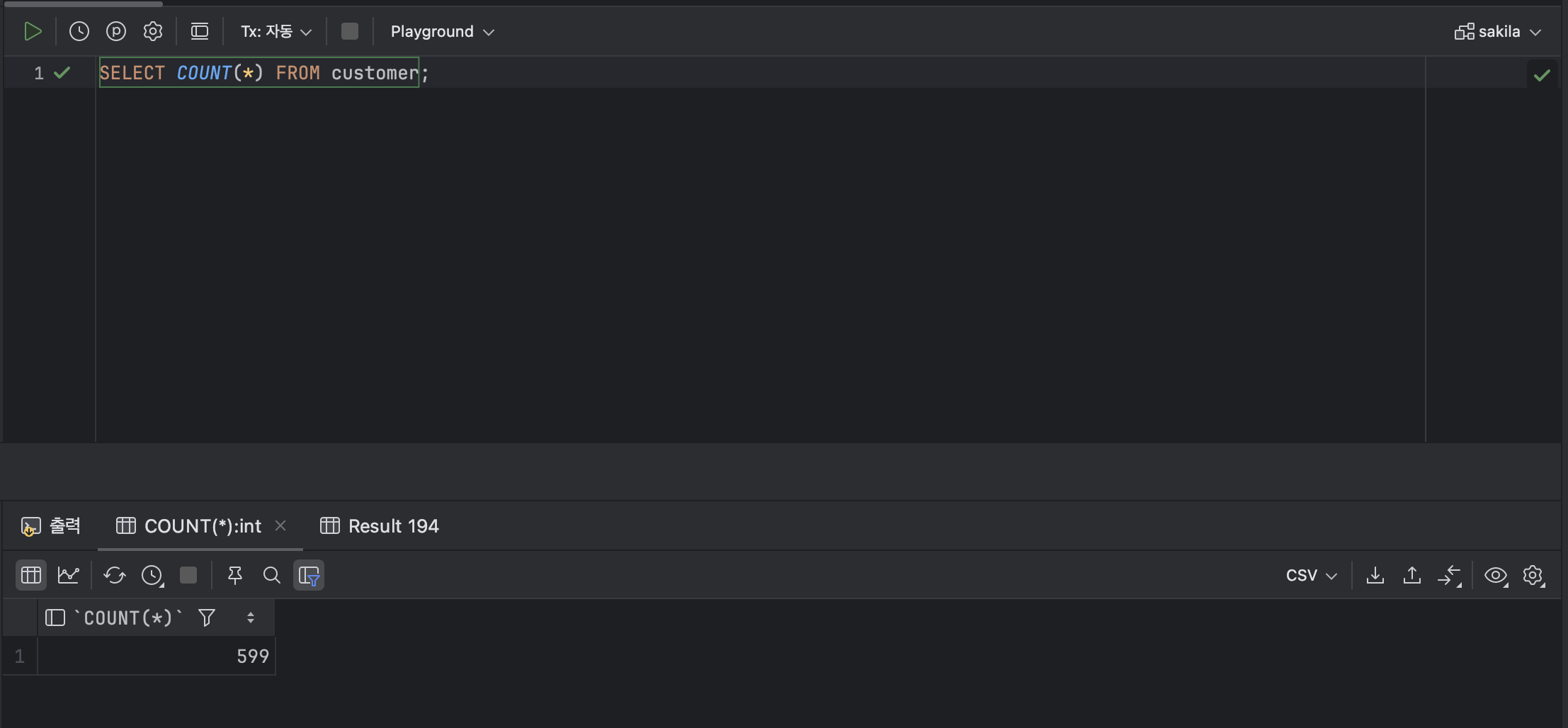
- 데이터의 합을 구하는 함수 : SUM
< SUM 기본형식 >
SUM([ 열 ]);ex )
SELECT SUM(amount) FROM payment;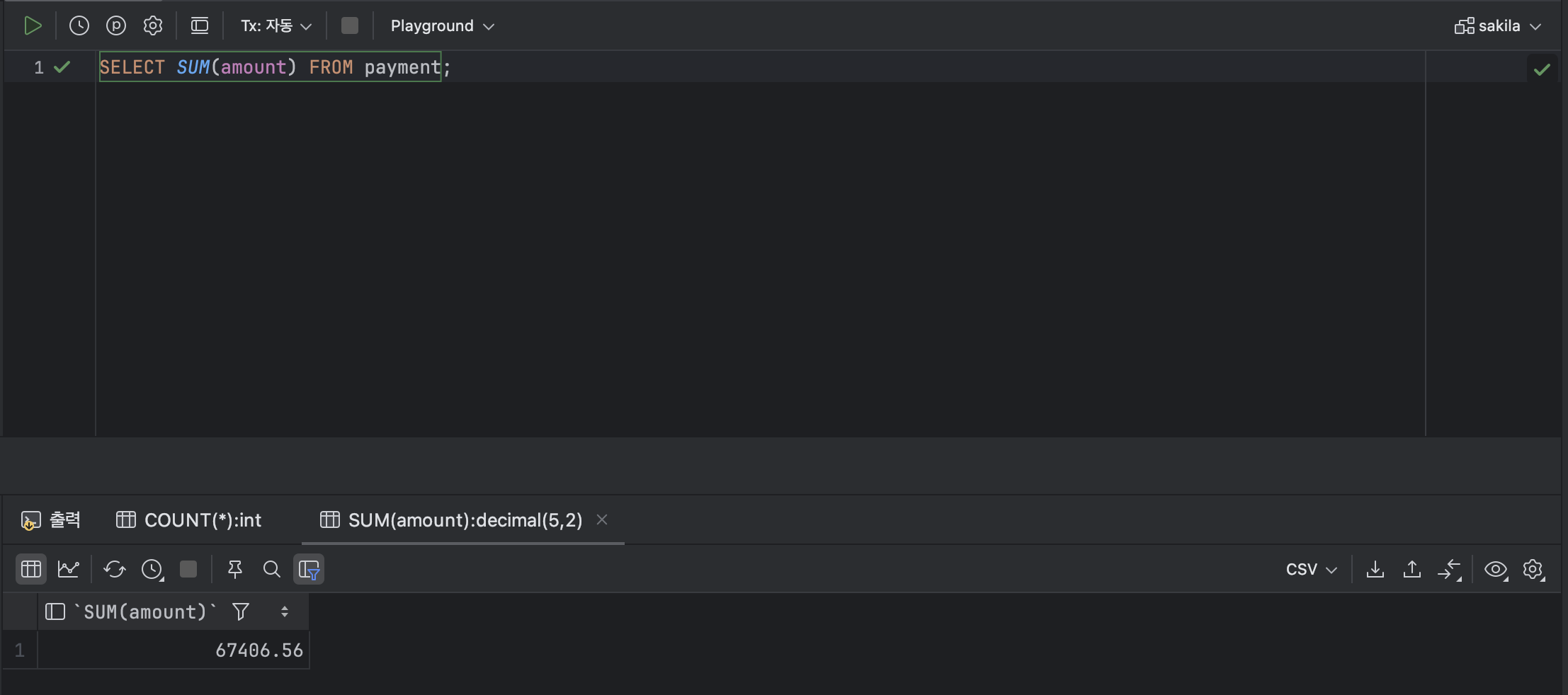
- 평균을 반환하는 함수 : AVG
< AVG 기본형식 >
AVG( [ 열 ] );ex )
SELECT AVG(amount) FROM payment;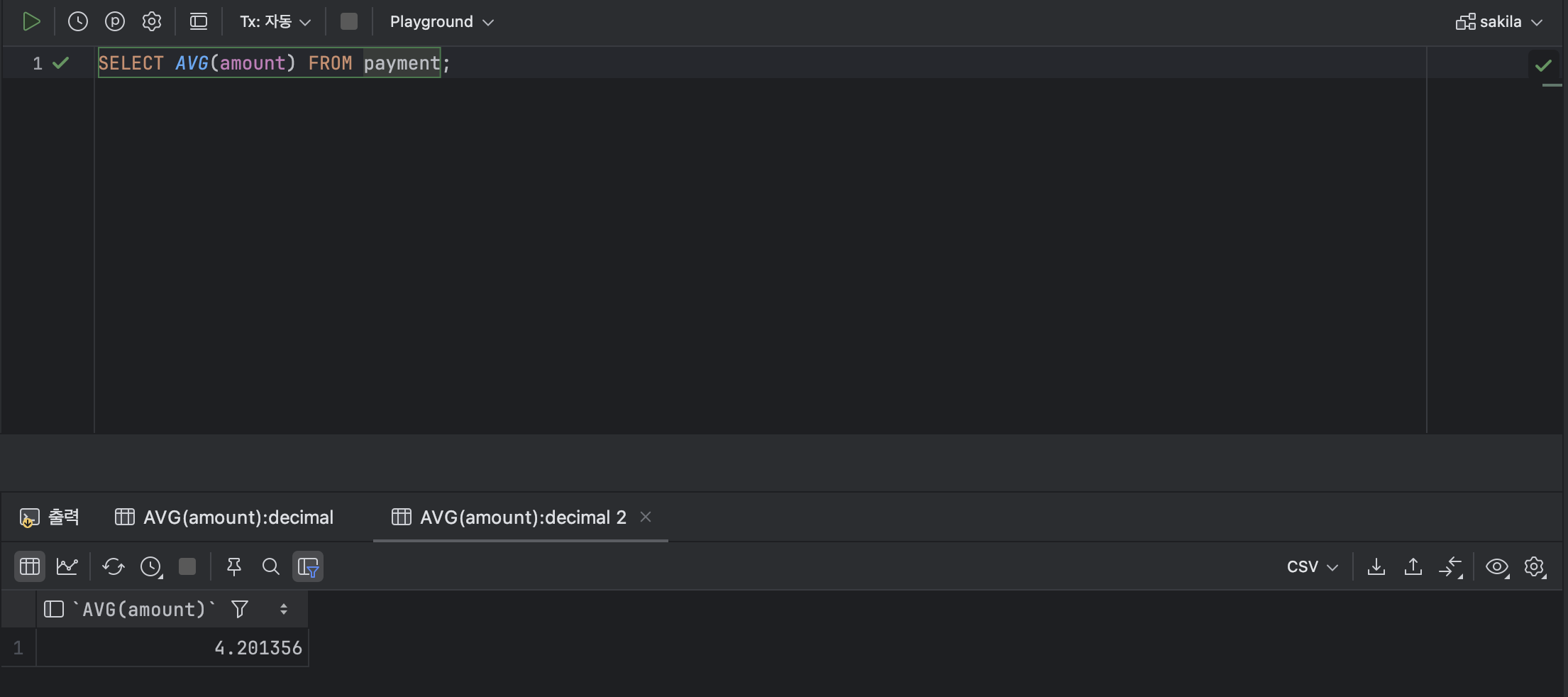
- 최솟값 or 최댓값을 구하는 함수 : MIN , MAX
< 기본형식 >
MIN ( [ 열 ] );
MAX ( [ 열 ] );ex )
SELECT MIN(amount) , MAX(amount) FROM payment;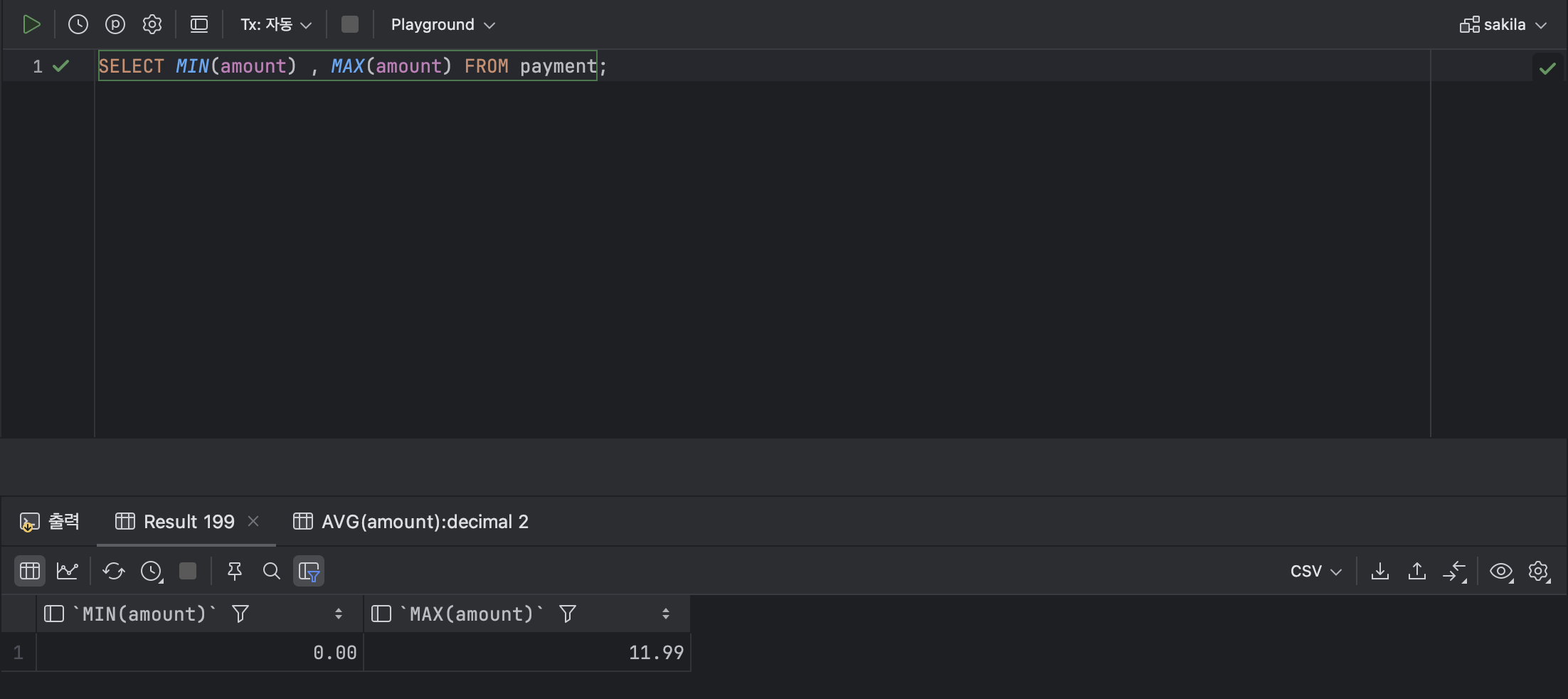
- 부분합과 총합을 구하는 함수 : ROLLUP
< ROLLUP 기본형식 >
SELECT [ 열 ] FROM [ 테이블 명 ] GROUP BY [ 열 ] .. WITH ROLLUP;ex )
SELECT customer_id , staff_id , SUM(amount)
FROM payment
GROUP BY customer_id, staff_id WITH ROLLUP;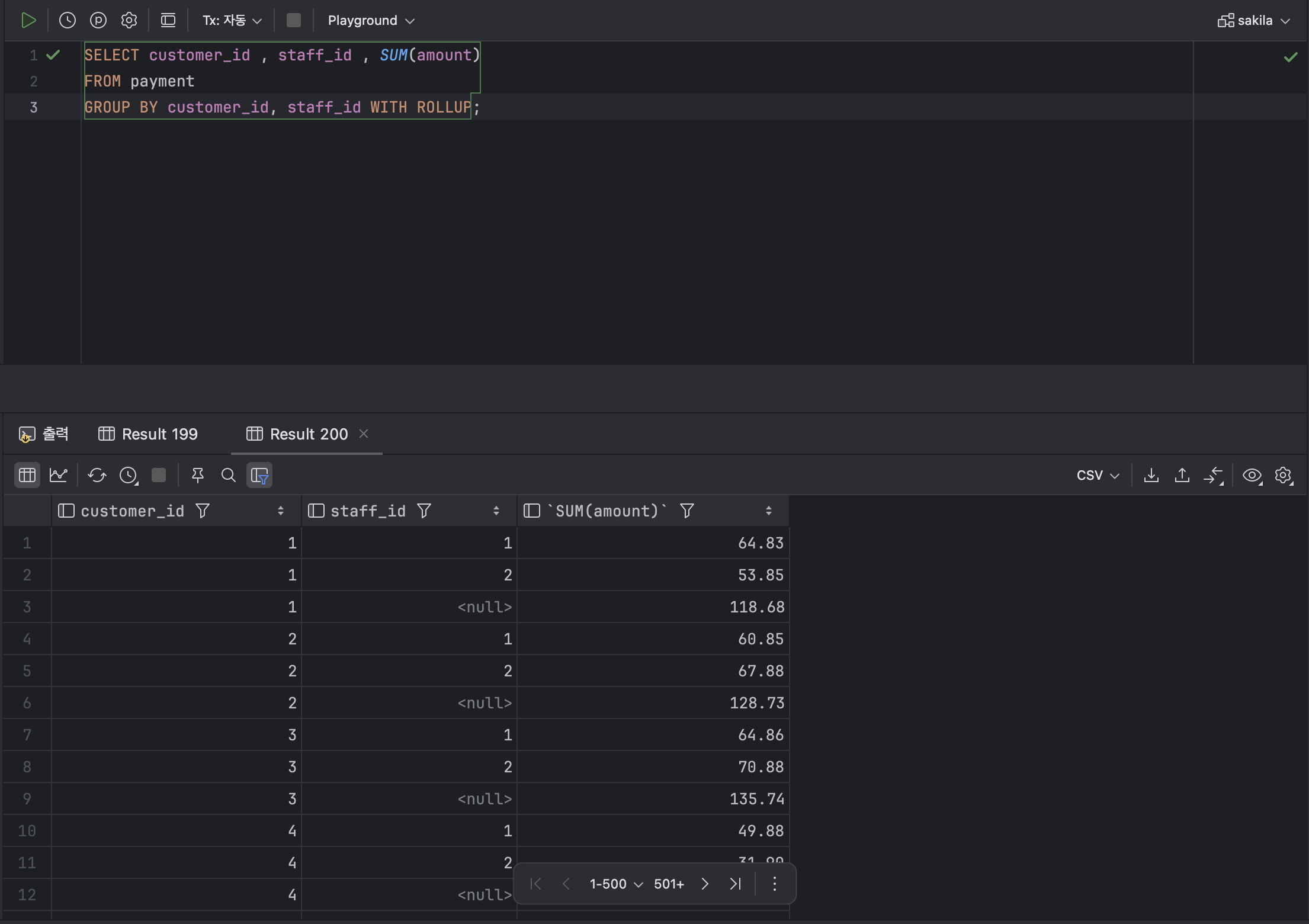
- 데이터의 표준편차를 구하는 함수 : STDDEV , STDDEV_SAMP
💫 ① STDDEV
: STDDEV 함수는 해당하는 값들의 표준편차를 반환한다.
< STDDEV 기본형식 >
STDDEV( [ 모집단 ] );ex )
SELECT STDDEV(amount) FROM payment;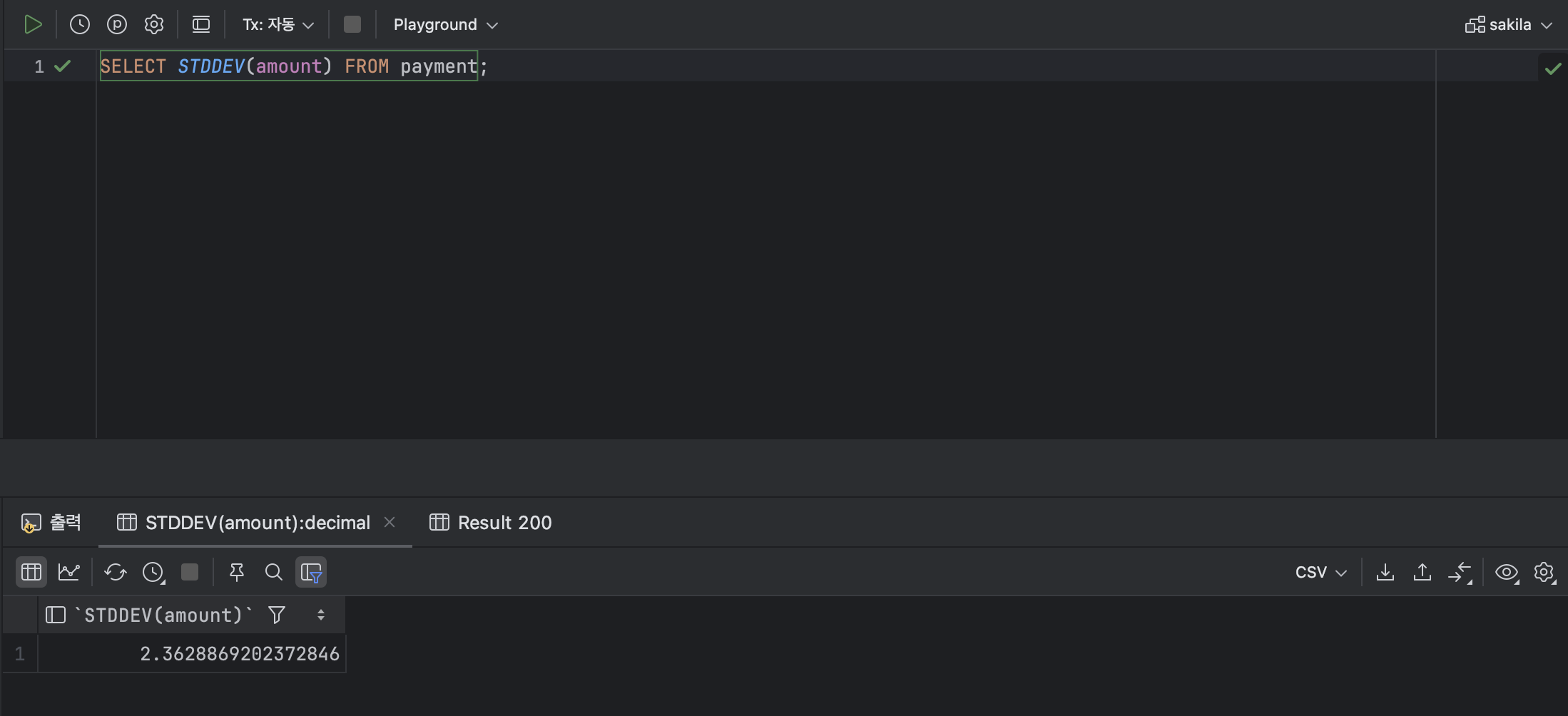
💫 ② STDDEV_SAMP
: STDDEV_SAMP 함수는 표본에 대한 표준편차를 반환한다.
< STDDEV_SAMP 기본형식 >
STDDEV_SAMP( [ 표본 집단 ] );ex )
SELECT STDDEV_SAMP(amount) FROM payment;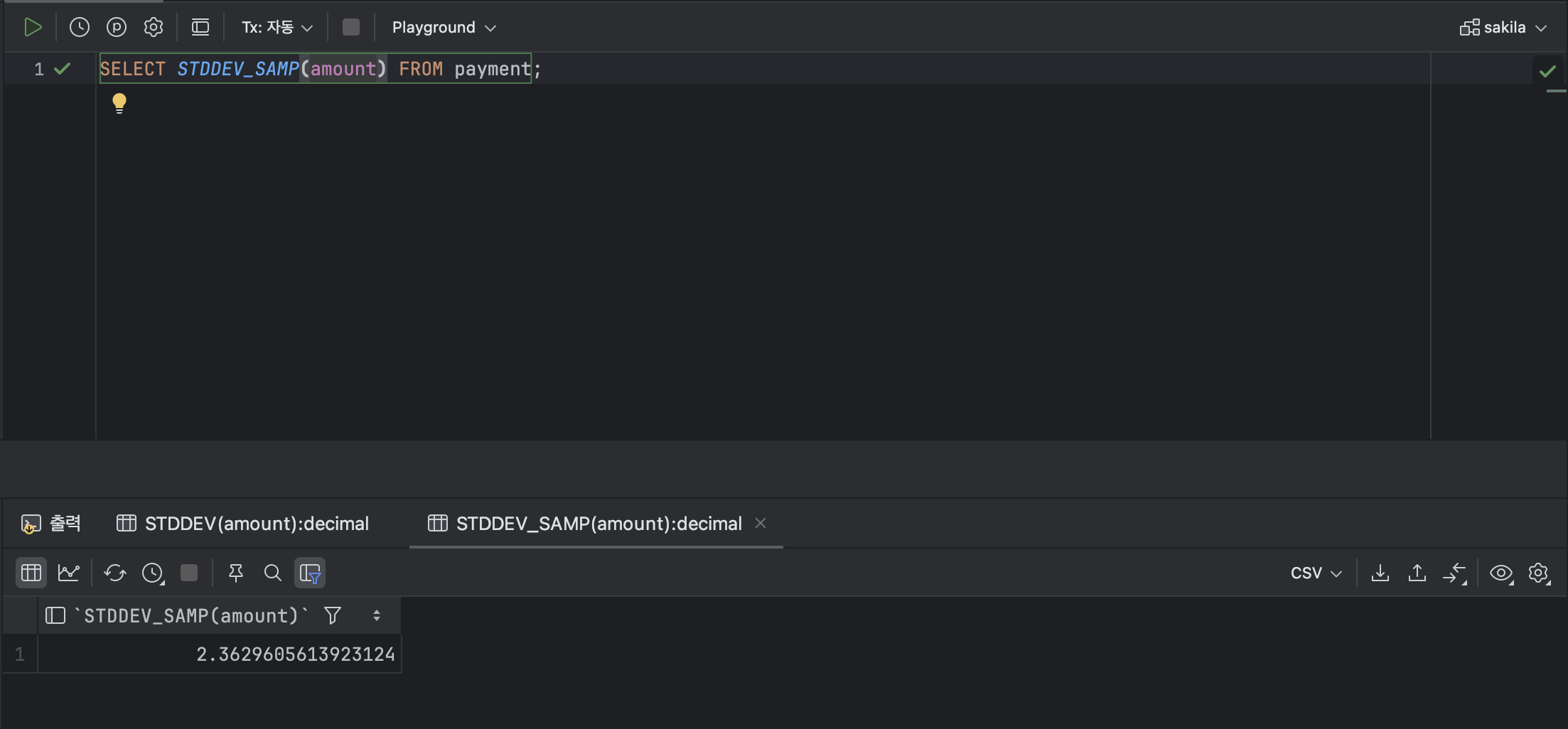
4) 수학 함수
- 절댓값을 구하는 함수 : ABS
< ABS 기본형식 >
SELECT ABS( [ 값 ] );ex )
SELECT ABS(-1);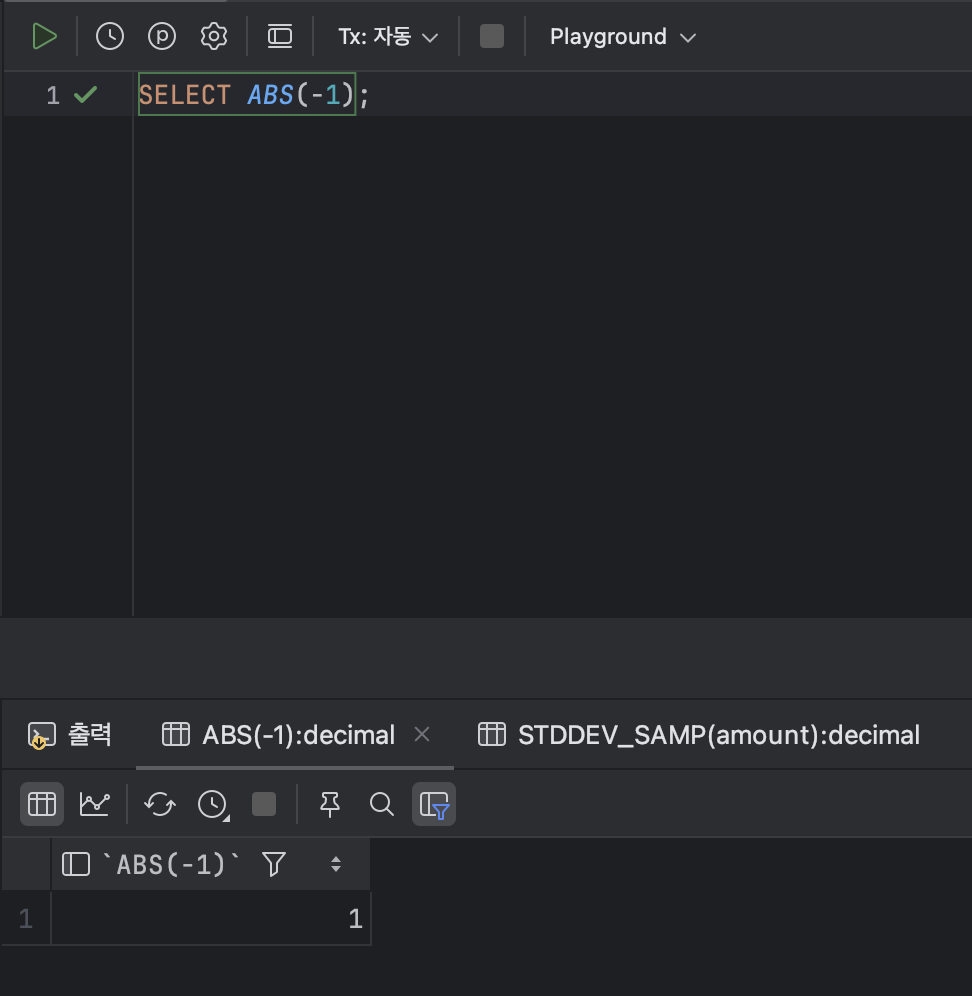
- 양수 or 음수 여부를 판단하는 함수 : SIGN
: SIGN 함수의 경우 양수일 때 1을 , 음수일 때 -1을 반환한다.
< SIGN 기본형식 >
SELECT SIGN( [ 값 ] );ex )
SELECT SIGN(-1);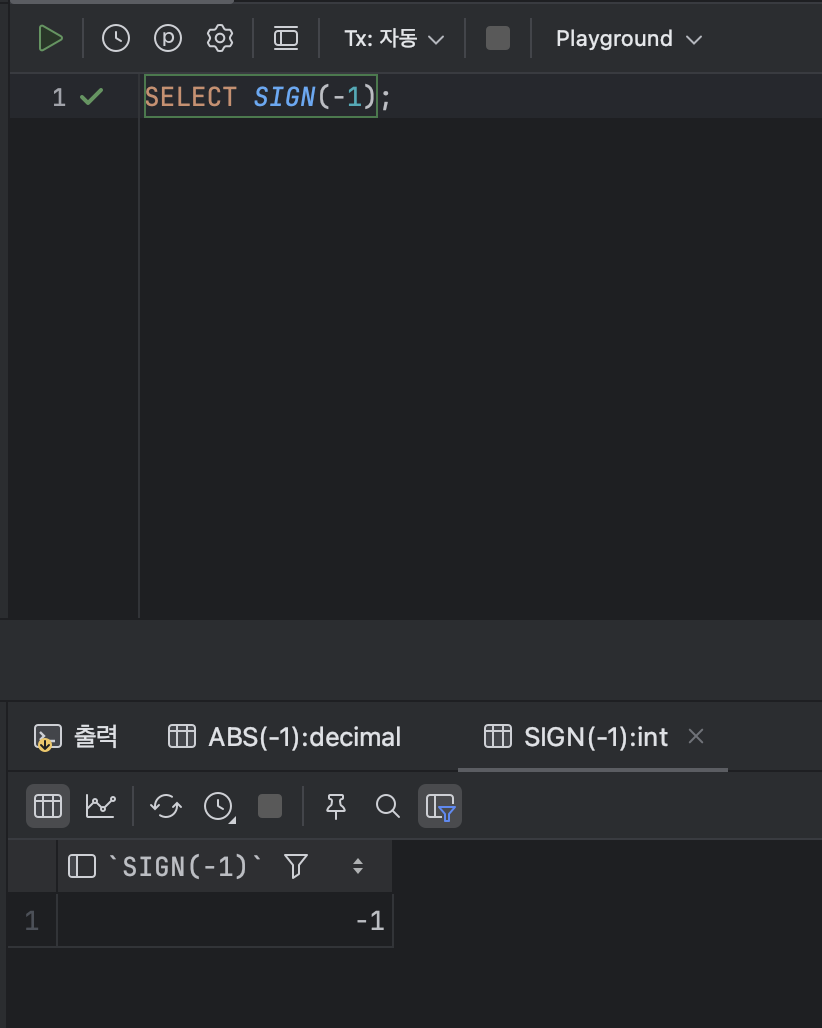
- 천장값과 바닥값을 구하는 함수 : CEILING , FLOOR
💫 ① CEILING
: CEILING 함수는 천장 값을 구한다. 천장값이란 입력한 숫자보다 크거나 같은 최소 정수를 의미한다.
< CEILING 기본형식 >
SELECT CEILING( [ 값 ] );ex )
SELECT CEILING(2.4);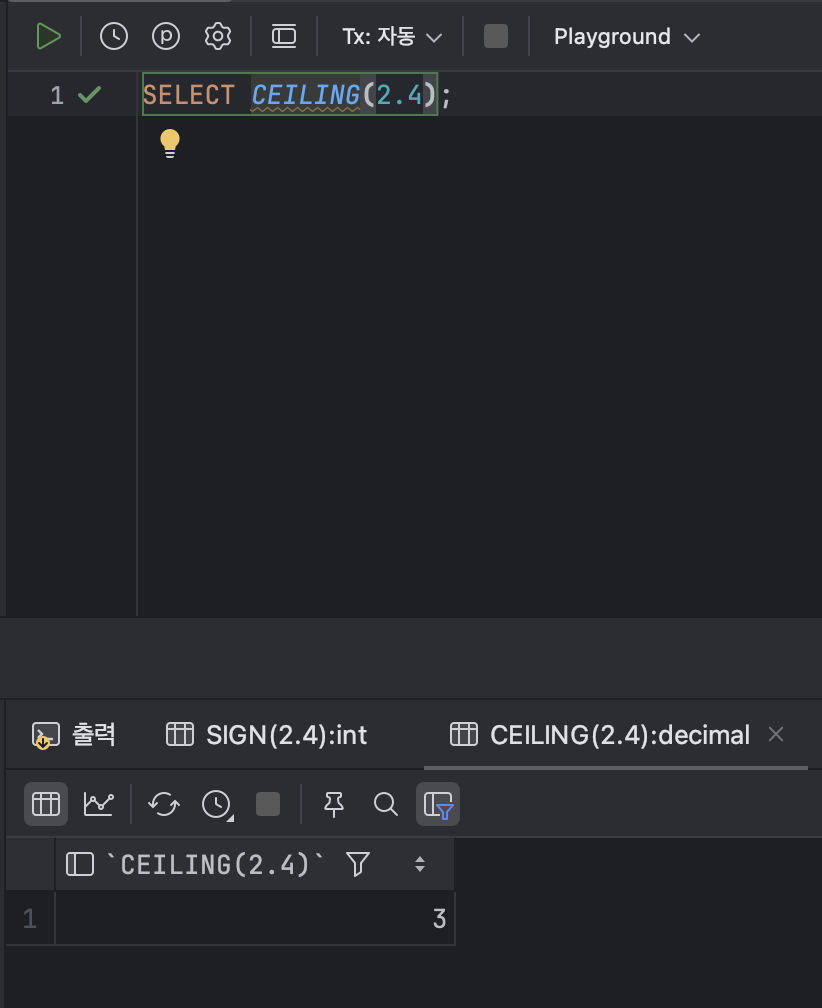
💫 ② FLOOR
: FLOOR 함수는 바닥값을 반환한다. 바닥값이란 지정한 숫자보다 작거나 같은 최대 정수를 의미한다.
< FLOOR 기본형식 >
SELECT FLOOR( [ 값 ] );ex )
SELECT FLOOR(2.4);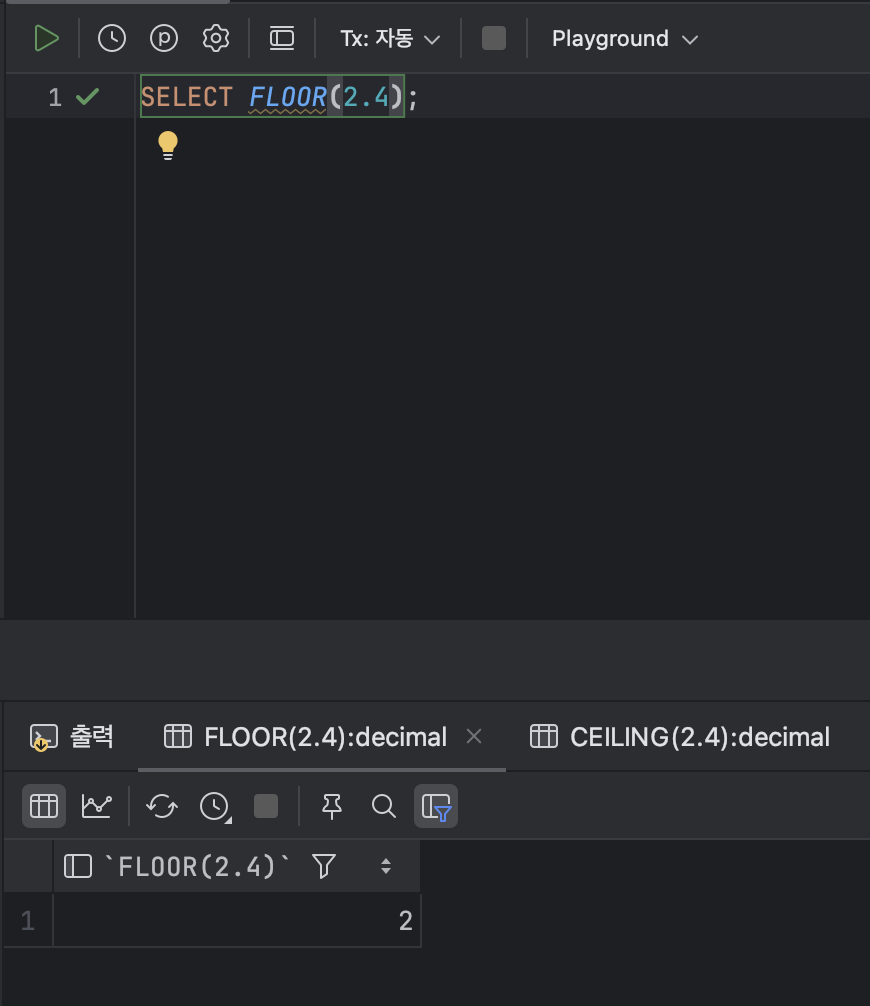
- 반올림을 반환하는 함수 : ROUND
< ROUND 기본형식 >
ROUND( [ 숫자 ] , [ 자릿수 ] );ex )
SELECT ROUND(99.9994 , 3);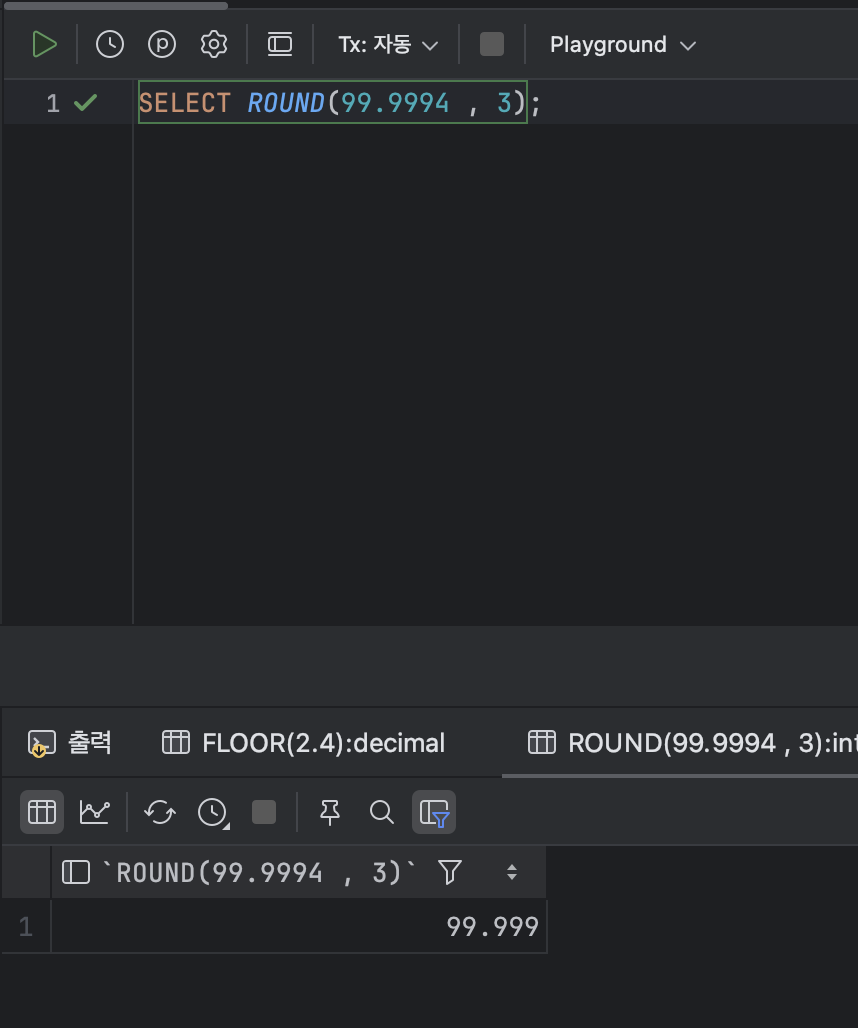
- 로그를 구하는 함수 : LOG
< LOG 기본형식 >
LOG( [ 로그 계산할 숫자 or 식 ] , [ 밑 ] );ex )
SELECT LOG(10); // 상용로그 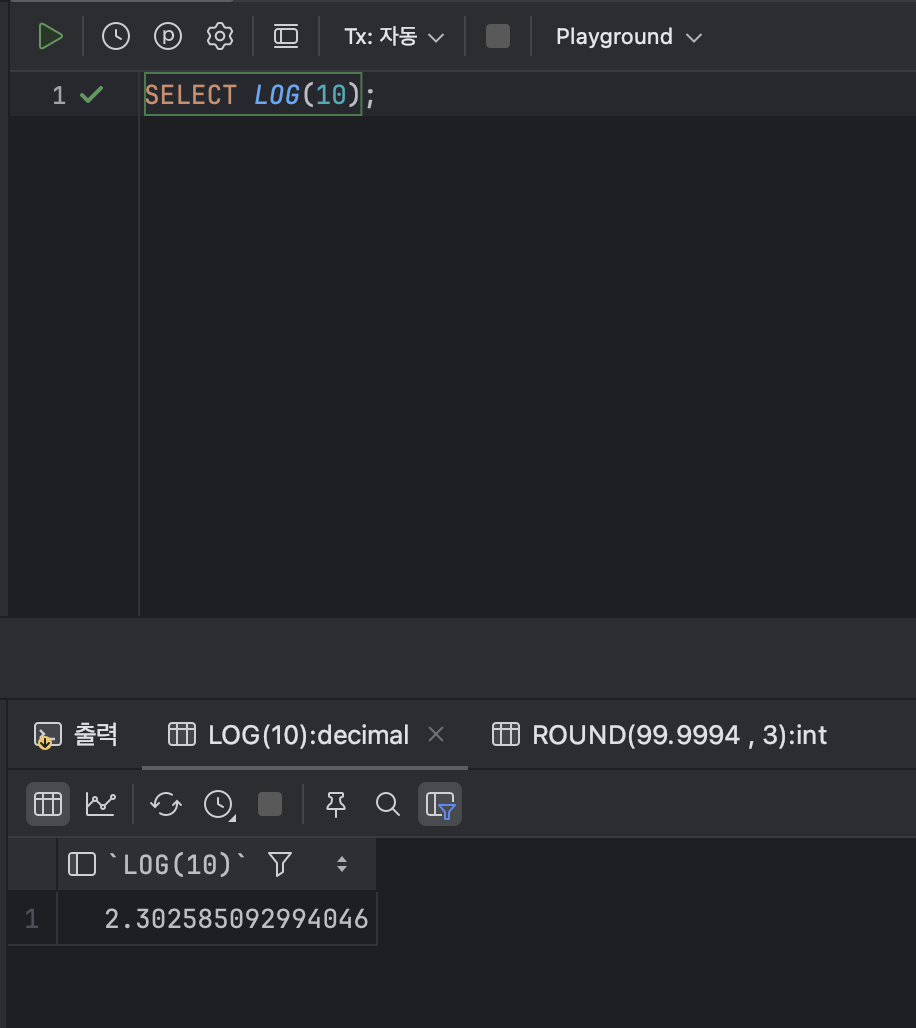
- e의 n 제곱을 구하는 함수 : EXP
< EXP 기본형식 >
EXP( [ 지수 계산할 숫자 or 식 ] );ex )
SELECT EXP(1.0);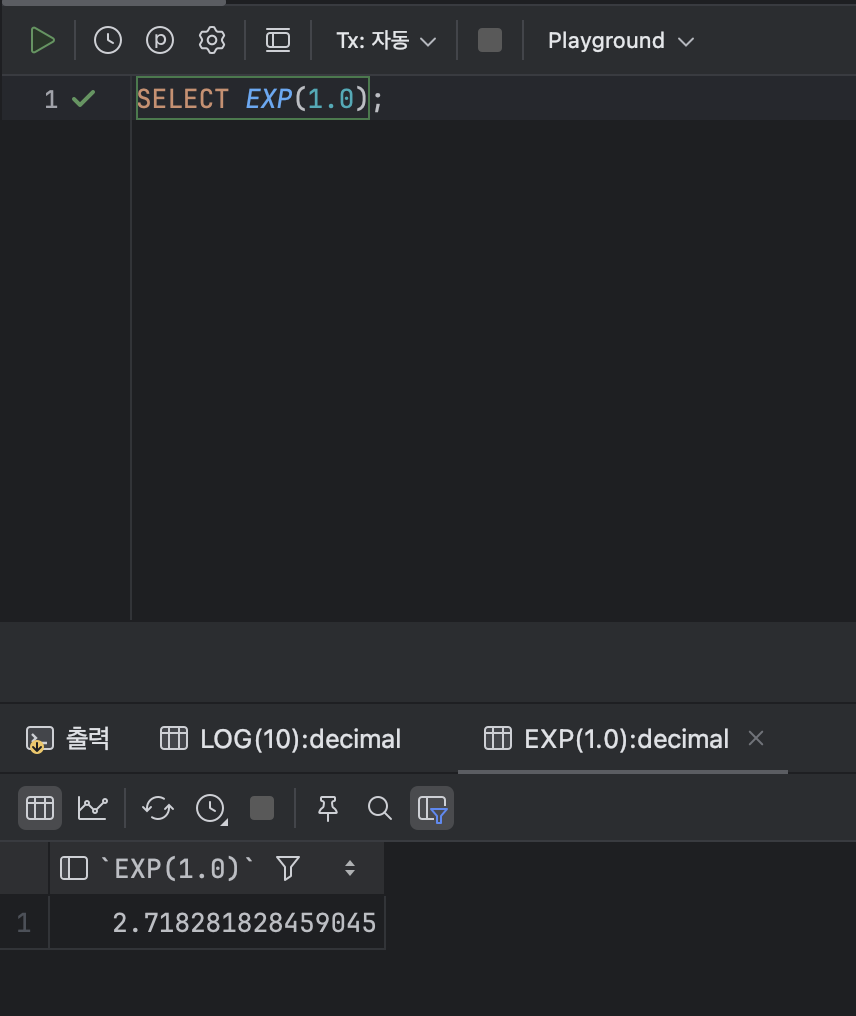
- 거듭제곱값을 구하는 함수 : POWER
< POWER 기본형식 >
POWER( [ 숫자 or 수식 ] , [ 지수 ] );ex )
SELECT POWER(2,3);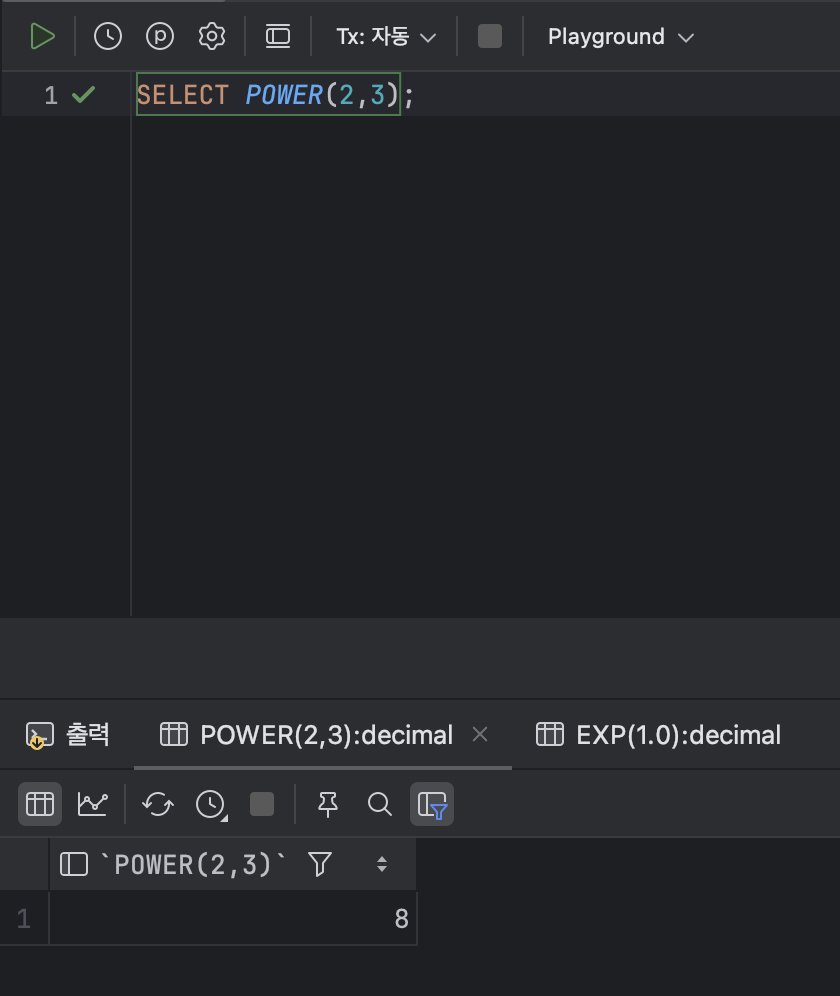
- 제곱근을 구하는 함수 : SQRT
< SQRT 기본형식 >
SQRT( [ 숫자 or 수식 ] );ex )
SELECT SQRT(10);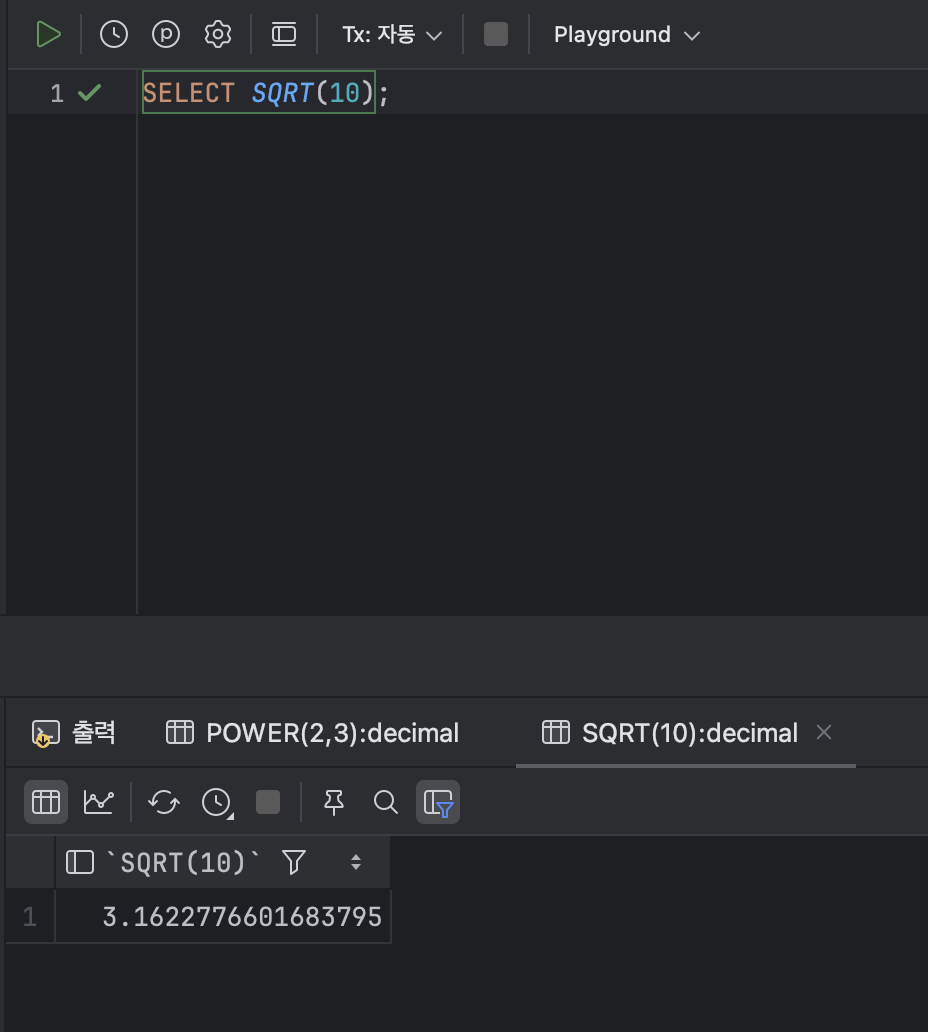
- 난수를 구하는 함수 : RAND
: RAND 함수는 0 부터 1사이의 실수형 난수를 반환한다.
< RAND 기본형식 >
RAND( [ 인자 ] );ex )
SELECT RAND(100);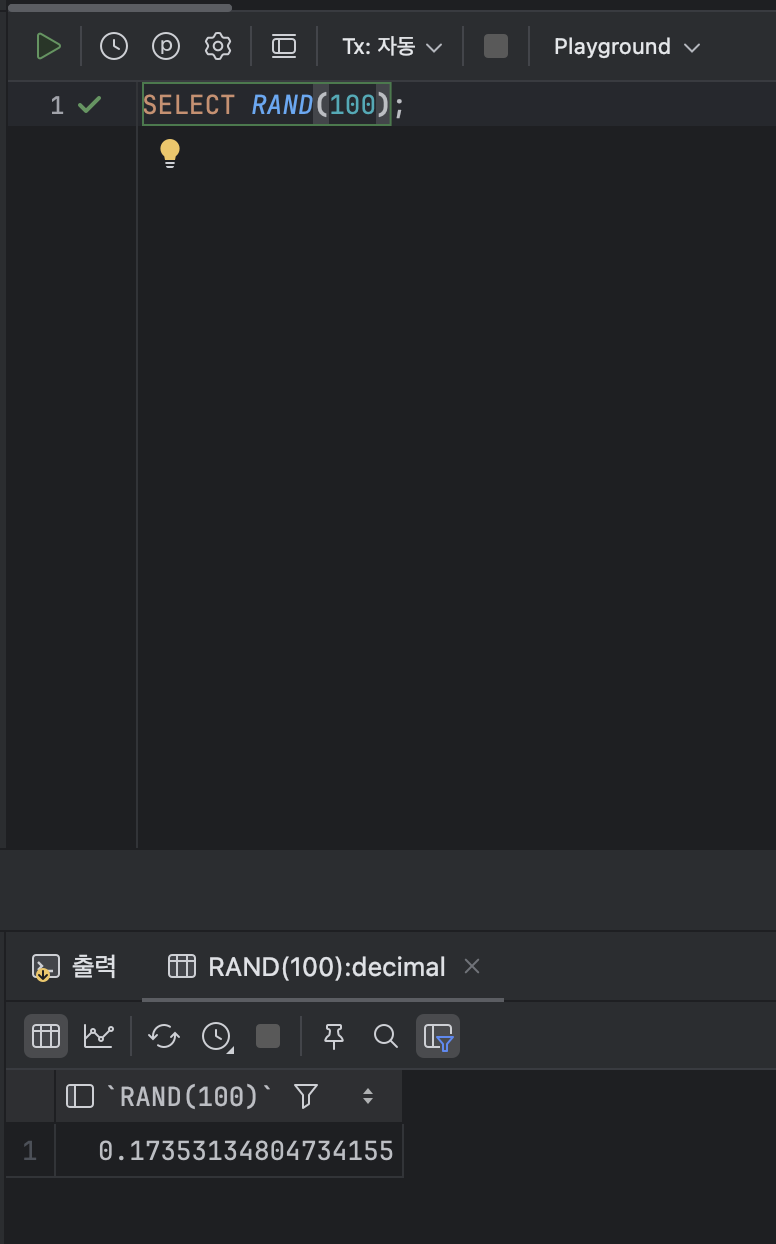
- 삼각함수 : COS , SIN , TAN , ATAN
< 기본형식 >
COS ( [ 숫자 or 식 ] );
SIN ( [ 숫자 or 식 ] );
TAN ( [ 숫자 or 식 ] );
ATAN ( [ 숫자 or 식 ] );ex )
SELECT COS(14.78)
, SIN(45.1)
, TAN(PI()/2)
, ATAN(197.1099392) AS atanCalc5;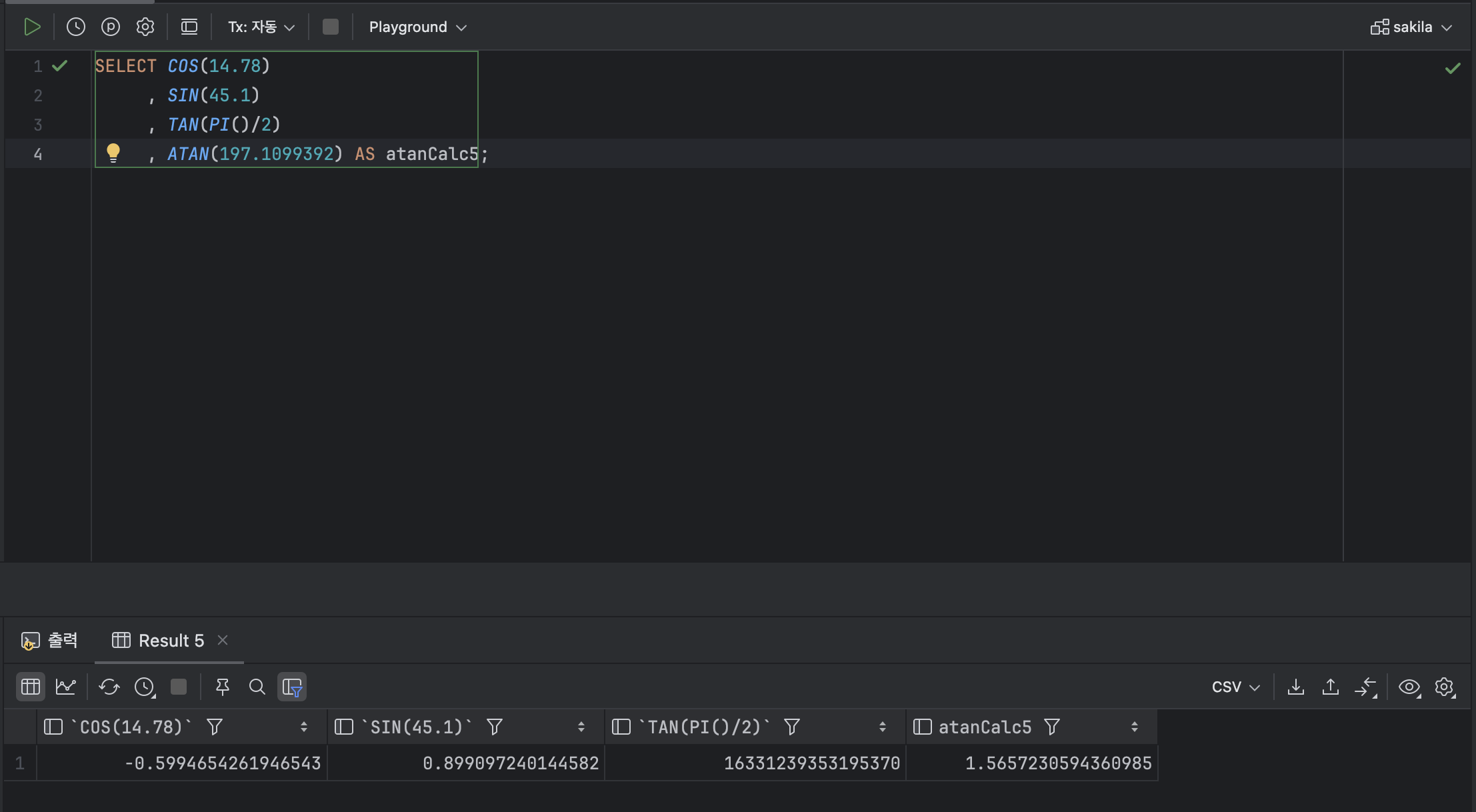
5) 순위 함수
- 유일한 값으로 순위를 부여하는 함수 : ROW_NUMBER
: 모든 행에 유일한 값으로 순위를 부여한다. 즉 , 함수 실행 결과에 대해서 같은 순위를 가지는 행이 없다.
< ROW_NUMBER 기본형식 >
ROW_NUMBER() OVER( [ PARTITION BY 열 ] ORDER BY 열 );ex )
SELECT ROW_NUMBER() OVER(ORDER BY amount DESC) AS num , customer_id , amount
FROM(
SELECT customer_id,SUM(amount) AS amount
FROM payment GROUP BY customer_id)
AS x;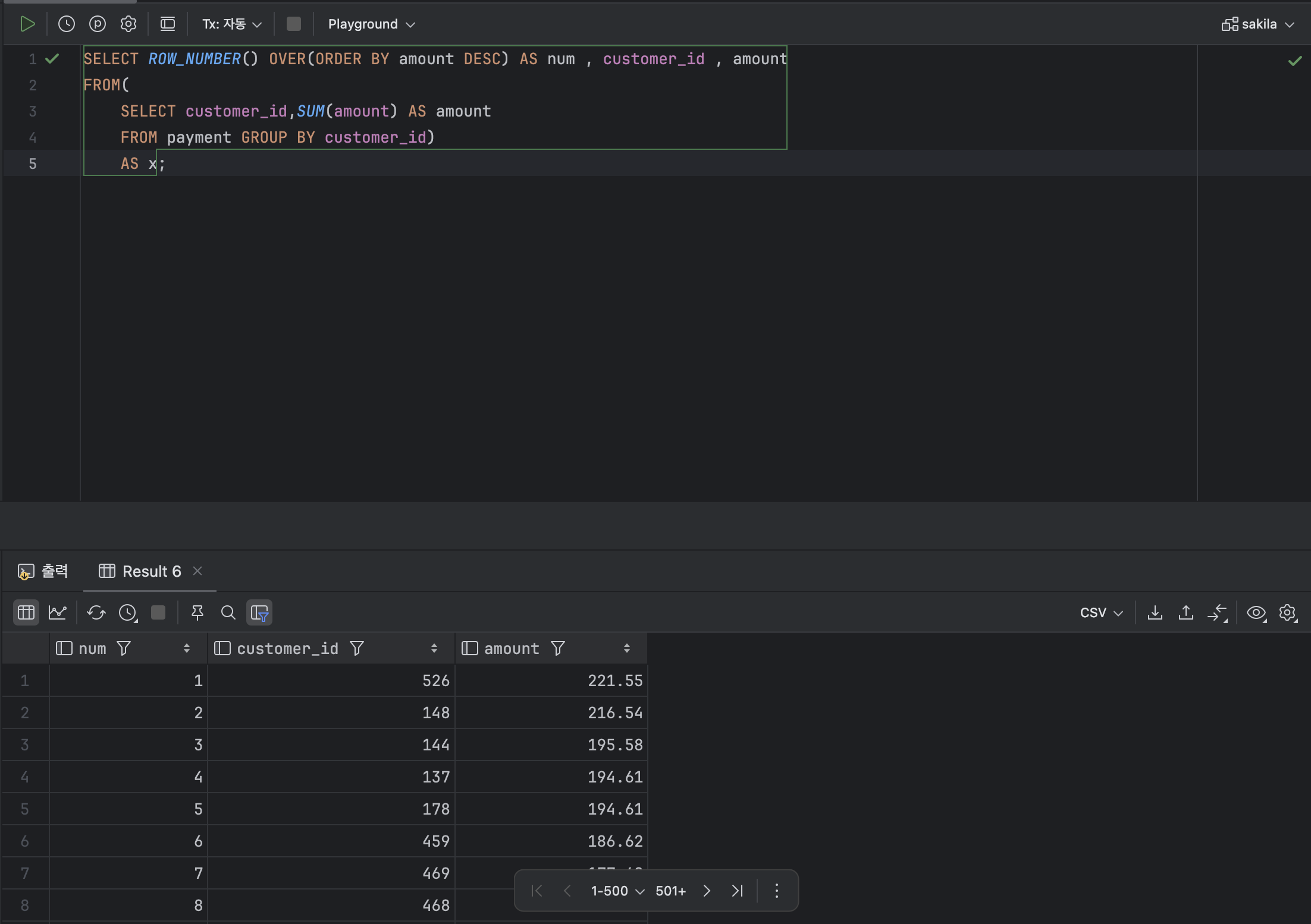
- 우선순위를 고려하지 않고 순위를 부여하는 함수 : RANK
: RANK 함수의 경우 우선순위를 따지지 않고 같은 순위를 부여한다.
< RANK 기본형식 >
RANK() OVER( [ PARTITION BY 열 ] ORDER BY 열 )ex )
SELECT RANK() OVER(ORDER BY amount DESC) AS num , customer_id , amount
FROM(
SELECT customer_id,SUM(amount) AS amount
FROM payment GROUP BY customer_id)
AS x;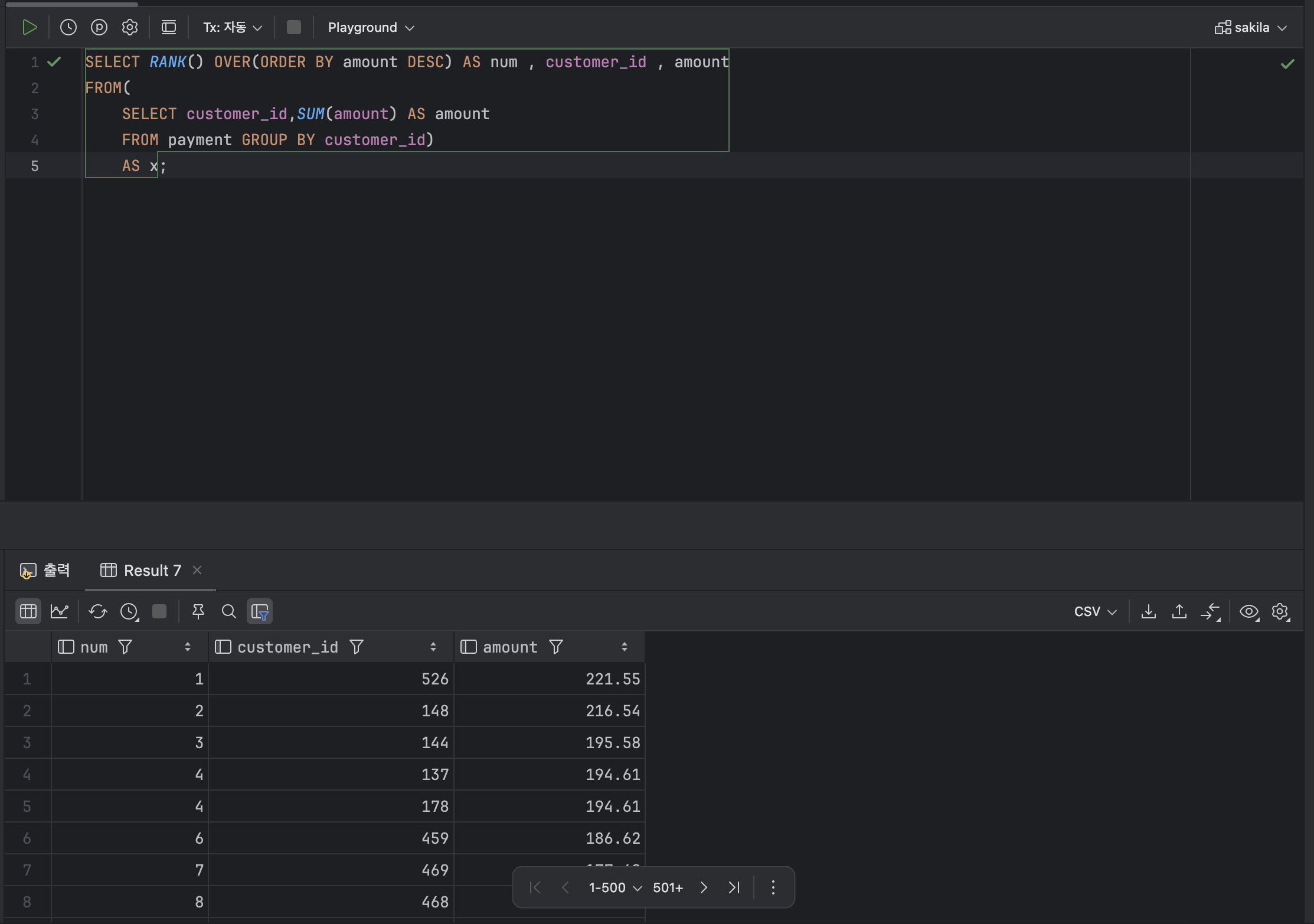
- 건너뛰지 않고 순위를 부여하는 함수 : DENSE_RANK
: RANK와 유사하나 중복 그룹에 대한 순위를 구분하지 않는다. 예를 들어 1등이 3개라면 다음 데이터는 4등이 아닌 2등이 된다.
< DENSE_RANK 기본형식 >
DENSE_RANK() OVER( [ PARTITION BY 열 ] ORDER BY 열 )ex )
SELECT DENSE_RANK() OVER(ORDER BY amount DESC) AS num , customer_id , amount
FROM(
SELECT customer_id,SUM(amount) AS amount
FROM payment GROUP BY customer_id)
AS x;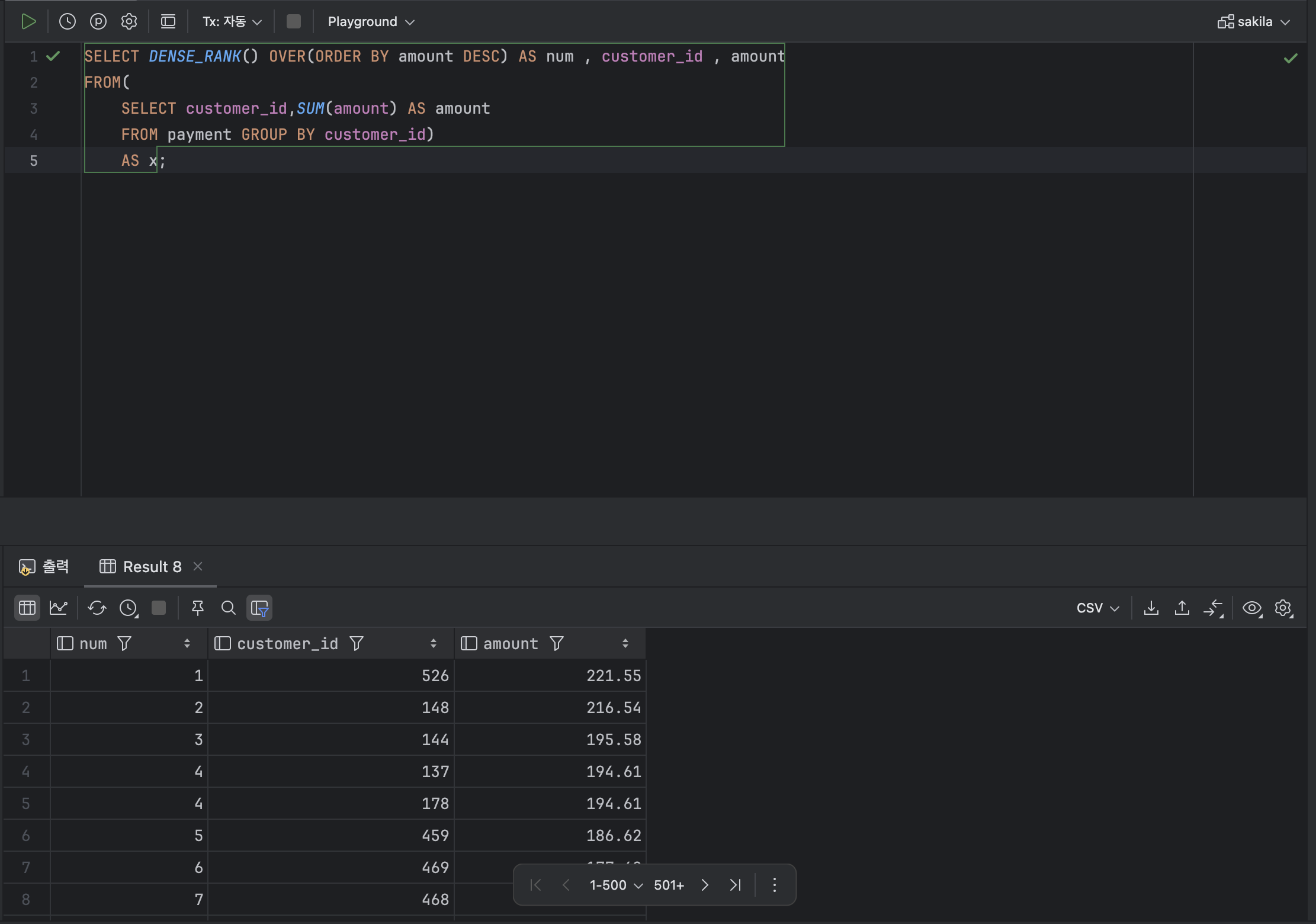
- 그룹 순위를 부여하는 함수 : NTILE
: NTILE 함수는 인자로 지정한 개수만큼 데이터 행을 그룹화 한 후. 각 그룹에 순위를 부여한다. 이는 앞선 함수들과 달리 개인이 아닌 ' 그룹 ' 에 대해서 순위를 부여하는 것이다.
< NTILE 기본형식 >
NTILE( [ 정수 ] ) OVER( [ PARTITION BY 열 ] ORDER BY 열 )ex )
SELECT NTILE(100) OVER(ORDER BY amount DESC) AS num , customer_id , amount
FROM(
SELECT customer_id,SUM(amount) AS amount
FROM payment GROUP BY customer_id)
AS x;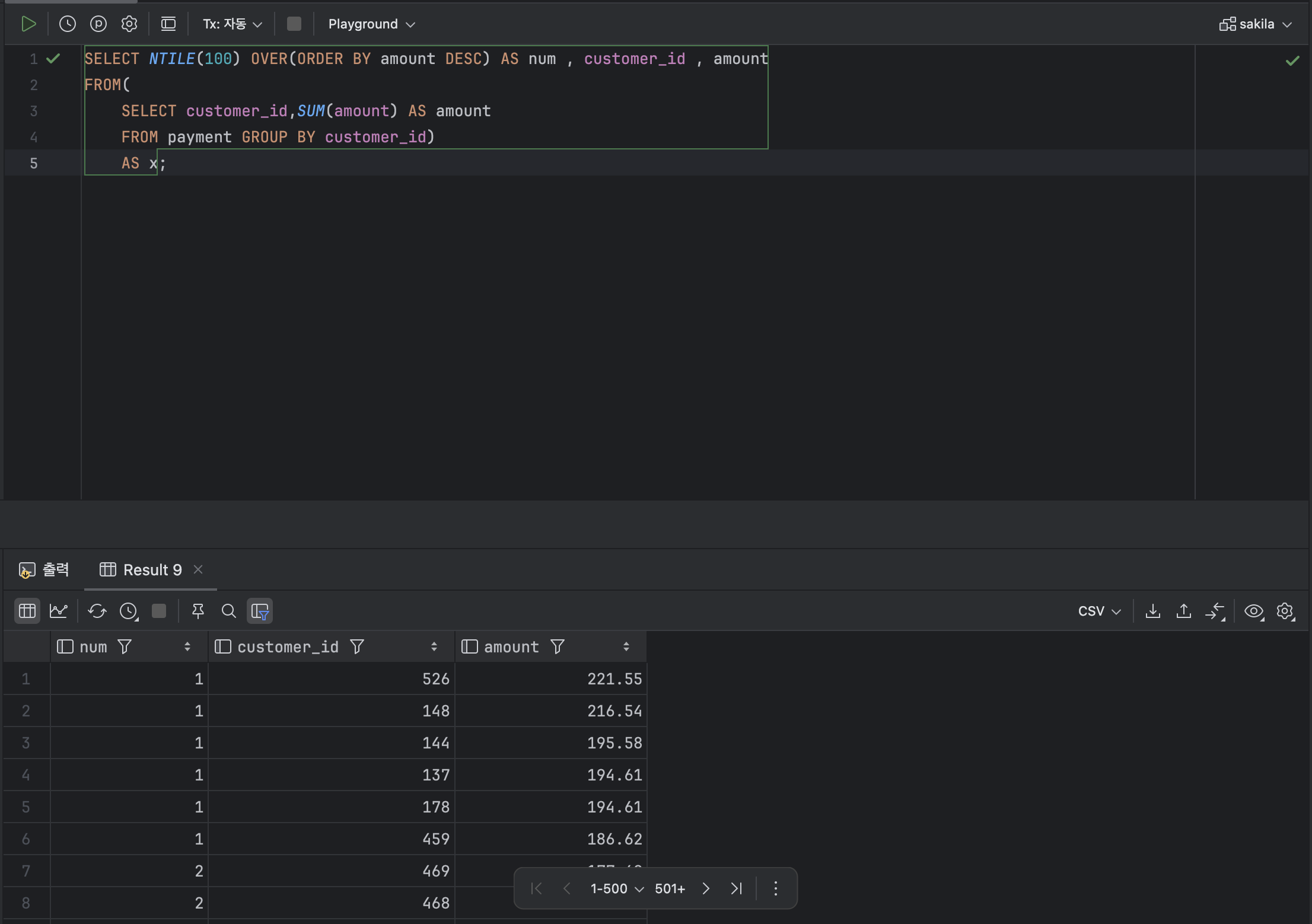
6) 분석 함수
- 앞 or 뒤 행을 참조하는 함수 : LAG , LEAD
💫 ① LAG
: LAG 함수는 현재 행에서 바로 앞의 행을 조회하여 데이터를 처리한다.
< LAG 기본형식 >
LAG( [ 열 이름 ] , [ 참조 위치 ] ) OVER( [ PARTITION BY 열 ] ORDER BY 열 )ex )
SELECT x.payment_date,
LAG(x.amount) OVER(ORDER BY x.payment_date ASC) AS lag_amount , amount
FROM (
SELECT DATE_FORMAT(payment_date, '%y-%m-%d') AS payment_date,
SUM(amount) AS amount
FROM payment GROUP BY DATE_FORMAT(payment_date, '%y-%m-%d')
) AS x
ORDER BY x.payment_date;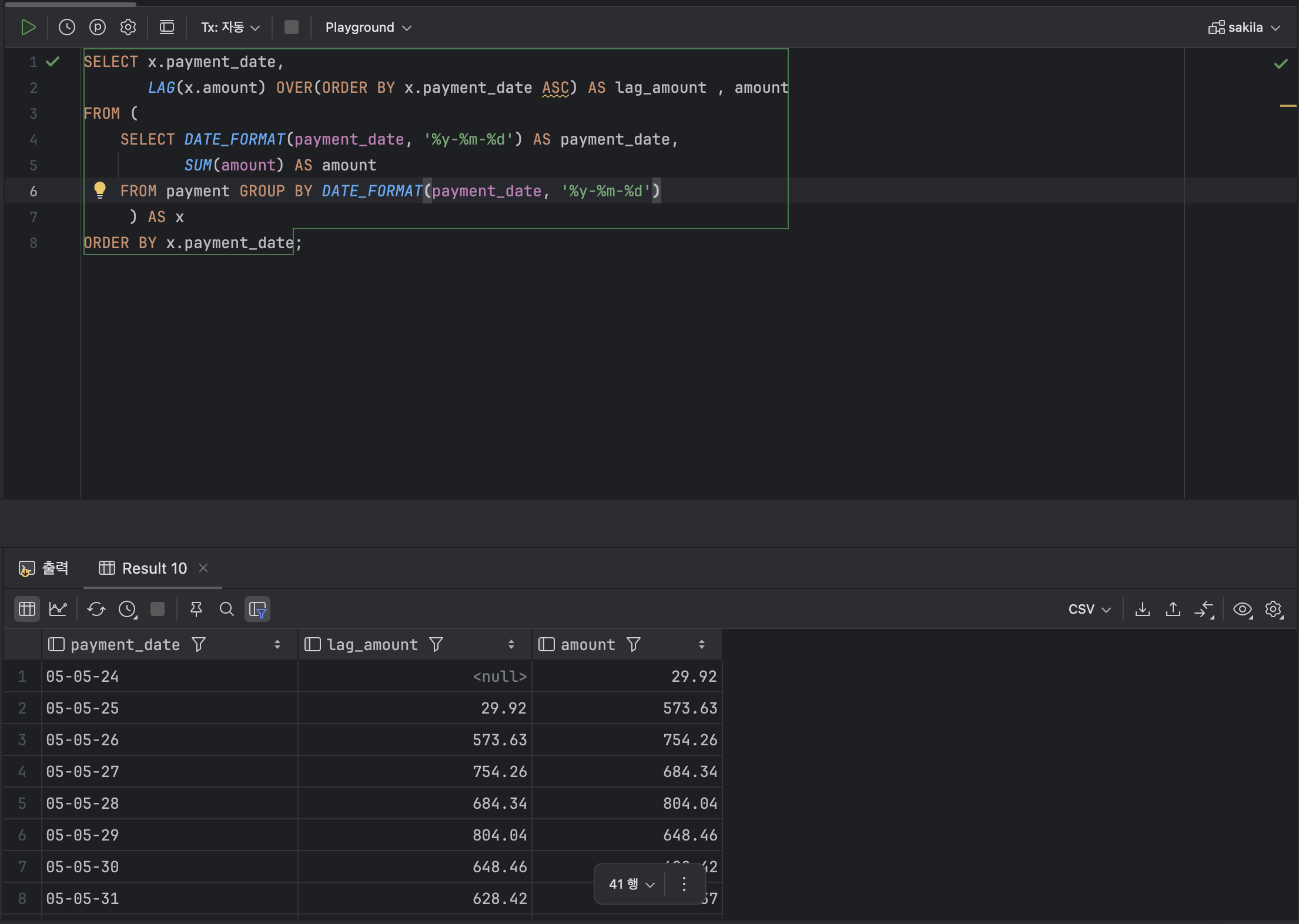
💫 ② LEAD
: LEAD 함수는 현재 행에서 바로 뒤의 행을 조회하여 데이터를 처리한다.
< LEAD 기본형식 >
LEAD( [ 열 이름 ] , [ 참조 위치 ] )
OVER( [ PARTITION BY 열 ] ORDER BY 열 )ex )
SELECT x.payment_date,
LEAD(x.amount) OVER(ORDER BY x.payment_date ASC) AS lead_amount , amount
FROM (
SELECT DATE_FORMAT(payment_date, '%y-%m-%d') AS payment_date,
SUM(amount) AS amount
FROM payment GROUP BY DATE_FORMAT(payment_date, '%y-%m-%d')
) AS x
ORDER BY x.payment_date;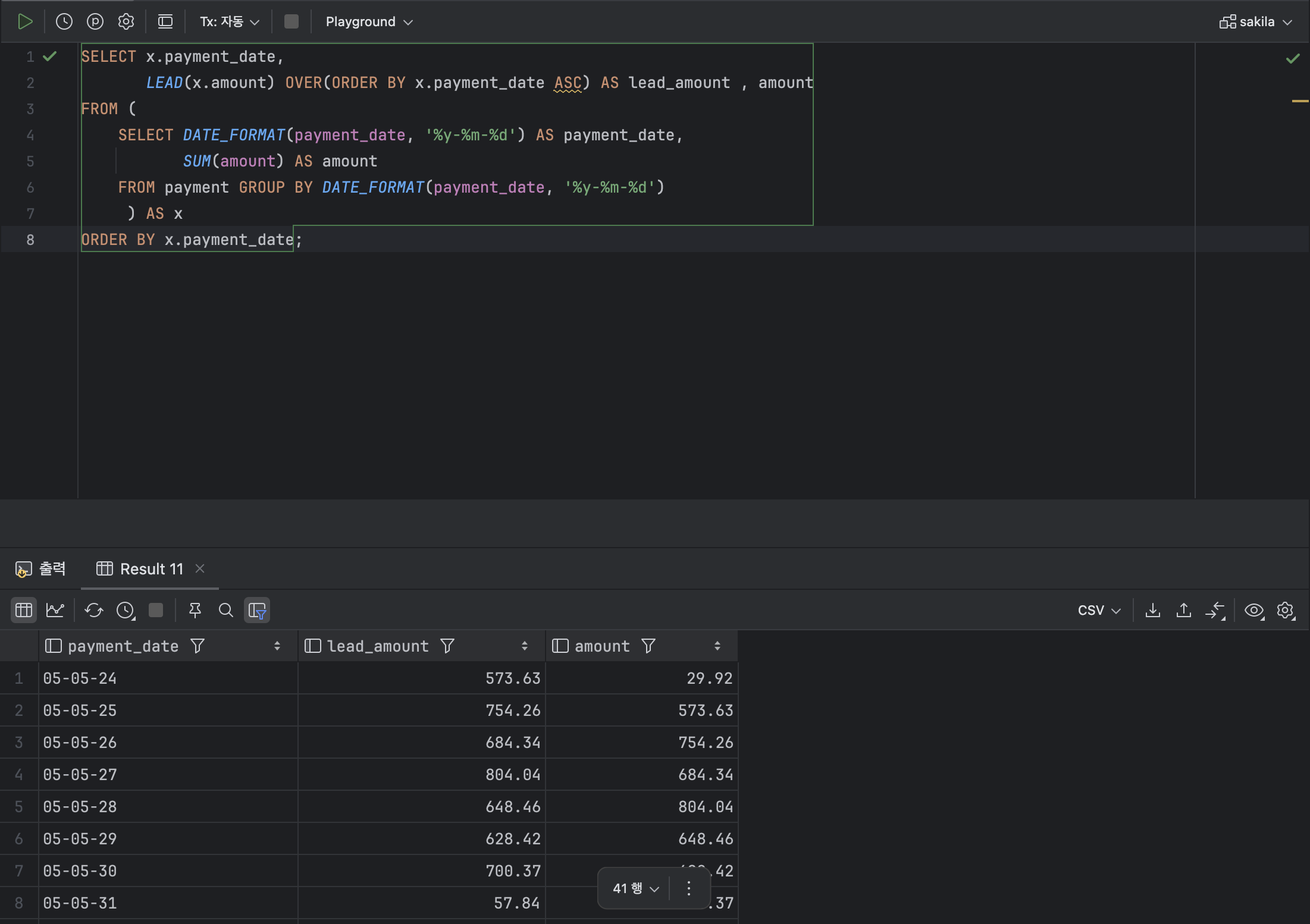
- 누적 분포를 계산하는 함수 : CUME_DIST
: CUME_DIST 함수는 그룹 내에서의 누적 분포를 계산한다.
< CUME_DIST 기본형식 >
CUME_DIST() OVER( [ PARTITION BY 열 ] ORDER BY 열 )ex )
SELECT x.customer_id , x.amount , CUME_DIST() OVER(ORDER BY x.amount DESC)
FROM (
SELECT customer_id , SUM(amount) AS amount
FROM payment GROUP BY customer_id
) AS x
ORDER BY x.amount DESC;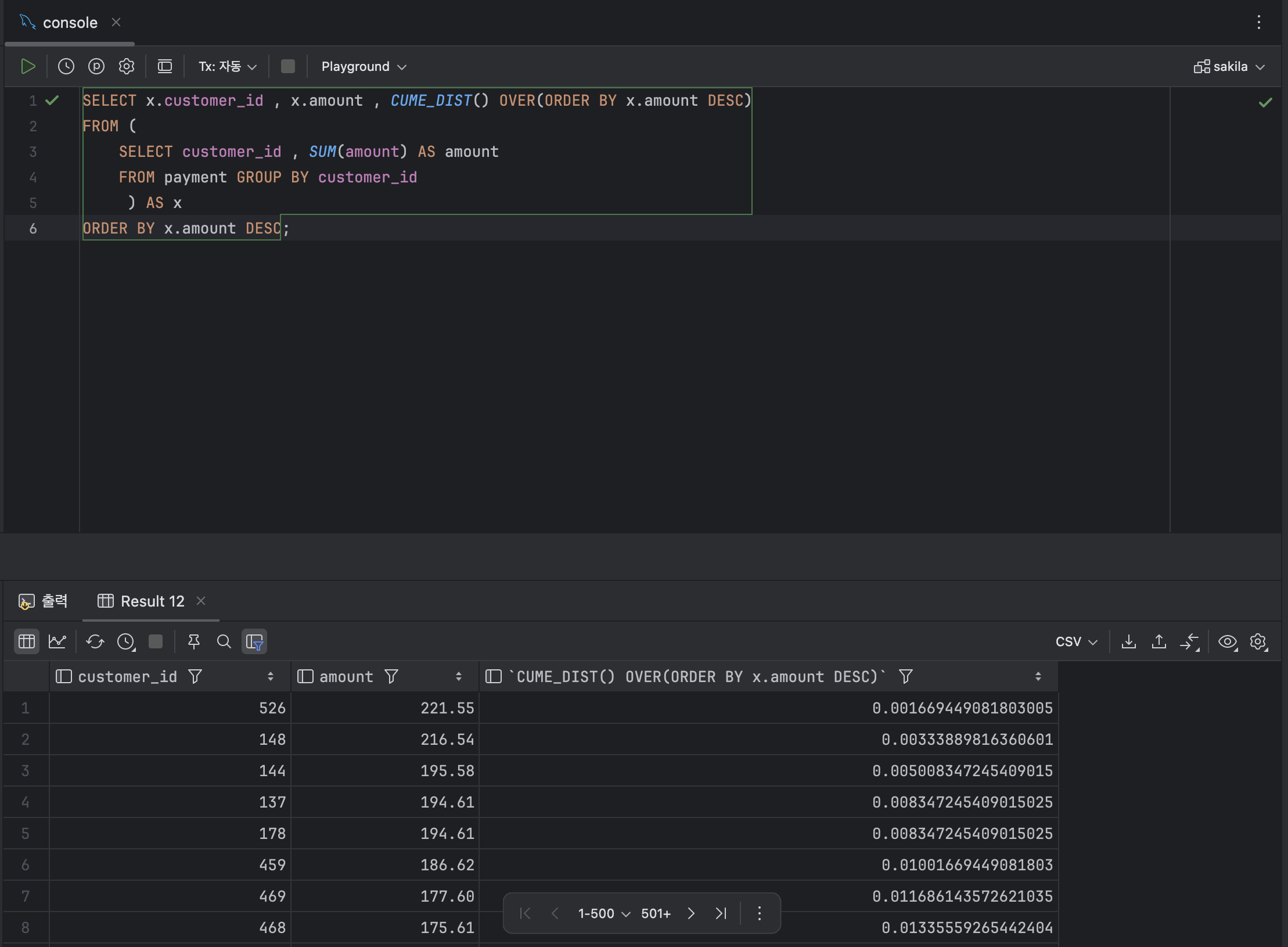
- 상대 순위를 계산하는 함수 : PERCENT_RANK
: PERCENT_RANK 함수는 지정한 그룹 또는 쿼리 결과로 이루어진 그룹 내의 상대 순위를 계산하여 반환한다.
< PERCENT_RANK 기본형식 >
PERCENT_RANK() OVER( [ PARTITION BY 열 ] ORDER BY 열 ) ex )
SELECT x.customer_id , x.amount , PERCENT_RANK() OVER (ORDER BY x.amount DESC)
FROM (
SELECT customer_id , SUM(amount) AS amount
FROM payment GROUP BY customer_id
) AS x
ORDER BY x.amount DESC;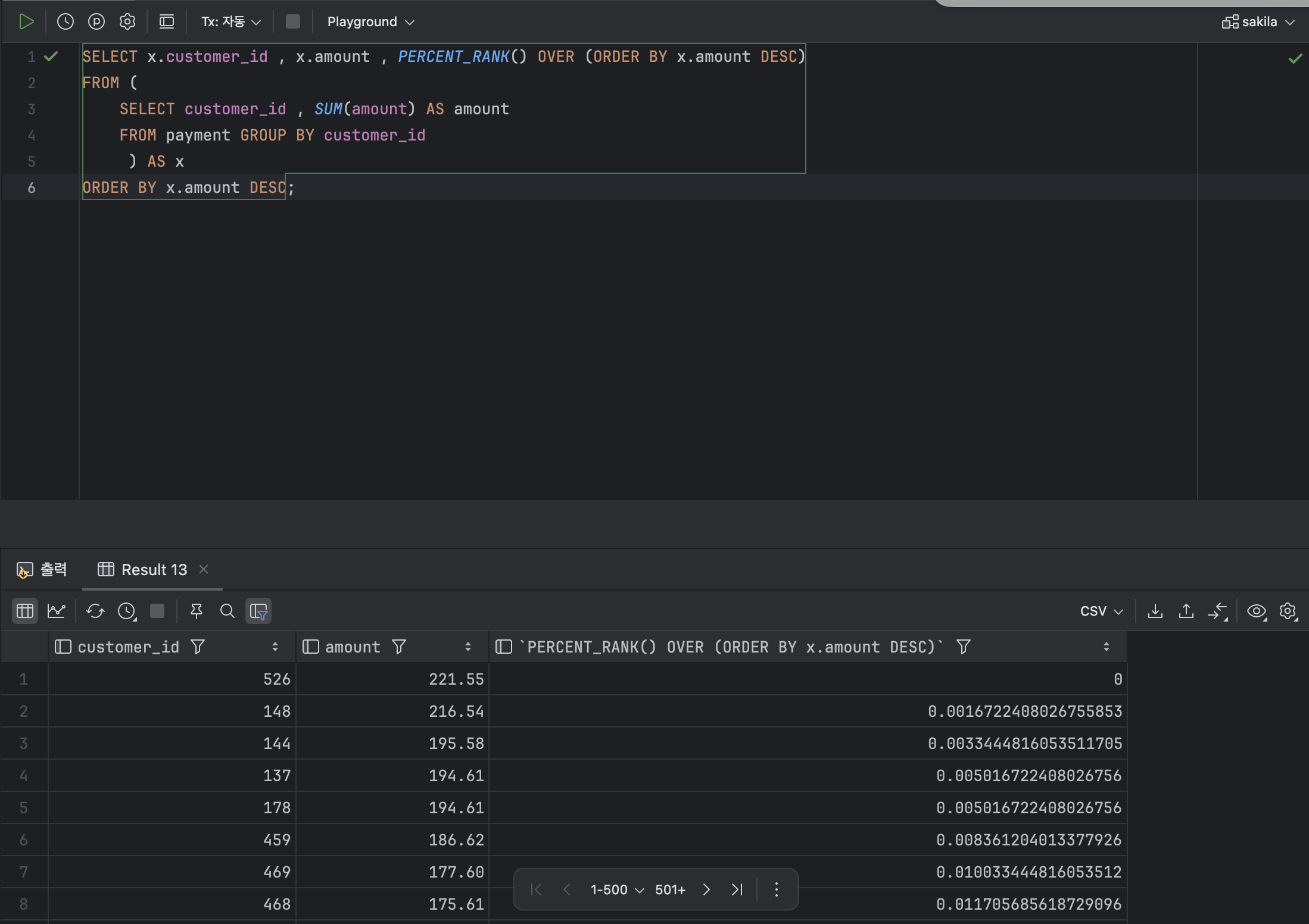
- 첫 행 or 마지막 행 값을 구하는 함수 : FIRST_VALUE , LAST_VALUE
💫 ① FIRST_VALUE
< FIRST_VALUE 기본형식 >
FIRST_VALUE( [ 열 ] ) OVER ( [ PARTITION BY ] ORDER BY 열 ) ex )
SELECT x.payment_date , x.amount , FIRST_VALUE(x.amount) OVER(ORDER BY x.payment_date) AS f_value
FROM(
SELECT DATE_FORMAT(payment_date,'%y-%m-%d') AS payment_date,
SUM(amount) AS amount
FROM payment GROUP BY DATE_FORMAT(payment_date,'%y-%m-%d')
) AS x
ORDER BY x.payment_date;
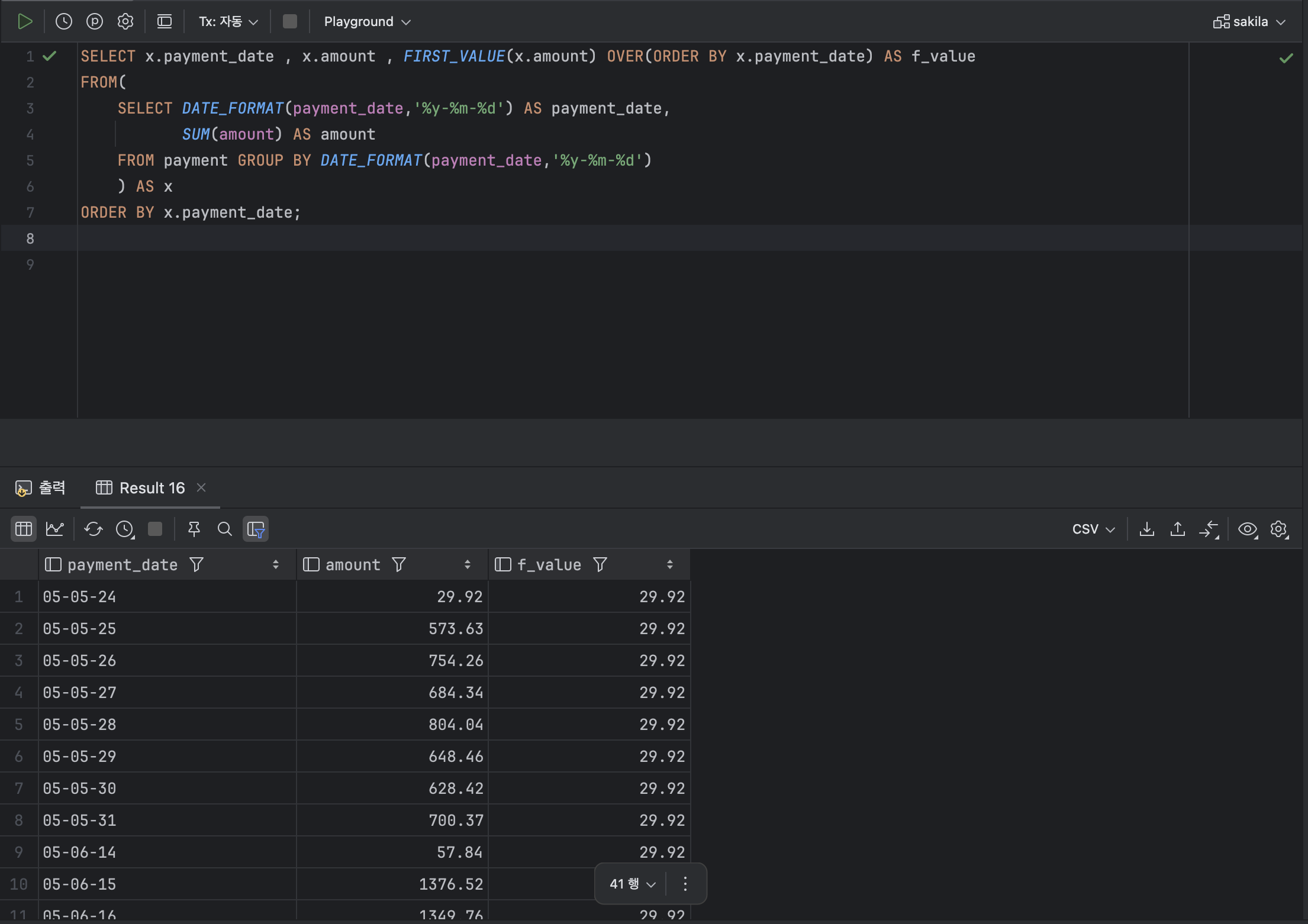
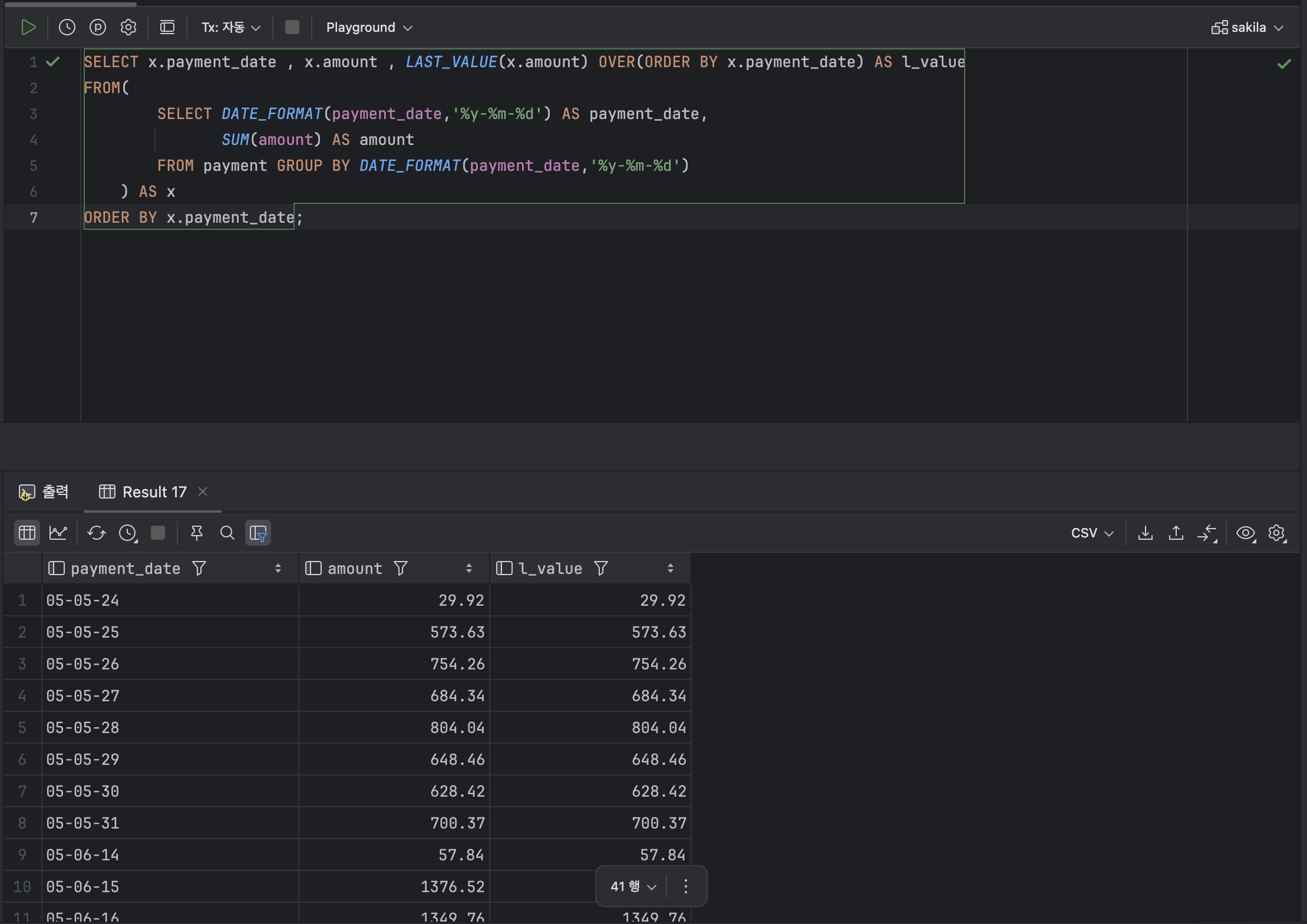
💫 ② LAST_VALUE
< LAST_VALUE 기본형식 >
LAST_VALUE( [ 열 ] ) OVER ( [ PARTITION BY ] ORDER BY 열 ) ex )
SELECT x.payment_date , x.amount , LAST_VALUE(x.amount) OVER(ORDER BY x.payment_date) AS l_value
FROM(
SELECT DATE_FORMAT(payment_date,'%y-%m-%d') AS payment_date,
SUM(amount) AS amount
FROM payment GROUP BY DATE_FORMAT(payment_date,'%y-%m-%d')
) AS x
ORDER BY x.payment_date;