K-Nearest Neighbor
데이터로부터 거리가 가까운 k개의 다른 데이터를 선택하는 알고리즘
데이터와 다른 데이터 사이의 거리를 측정할 때, 유클리드 거리 등 거리계산 metric을 활용
model based learning이 아닌 lazy model
k값과 거리 측정 방법이 가장 중요한 hyperparameter
- k값 : k값에 따라 overfitting과 underfitting 발생
k는 홀수로 하는 것이 일반적 (과반수 선택) - 거리측정 metric : 유클리드 거리, 마할라노비스 거리, 맨하탄 거리...
장점
훈련이 없기 때문에, 빠르게 학습 가능한 알고리즘
수치 기반 데이터에서 우수한 성능을 나타내는 알고리즘 (거리 기반 알고리즘이기 때문)
단순하고 효율적
단점
명목 또는 더미 데이터를 처리하기 어렵다
변수가 많은 데이터는 처리 속도가 느리고 정확도가 많이 떨어진다
적절한 k를 선택하는 것이 어렵다
변수를 이해하는 알고리즘이 아니며, label과의 관계 파악 등 설명력이 떨어진다
각 변수마다 스케일이 다른 경우 동일한 거리 척도를 사용하기 어렵다
고려해야할 부분
- 변수 간의 분포가 다르기 때문에 데이터 정규화를 꼭 해야한다.
- 데이터 간의 거리 측정 효율화
- 공간 상에서 데이터의 representation 상태를 확인해야 한다.
- 다른 모델에 비해 outlier에 강건한 편이지만, 전체적으로 데이터가 주어진 공간에 데이터 특성에 따라 위치와 거리가 적절히 분포되어 있어야 한다
분류에서의 knn
- 소속된 항목(label)을 출력하며 k개의 nearest neighbor중 과반수로 분류
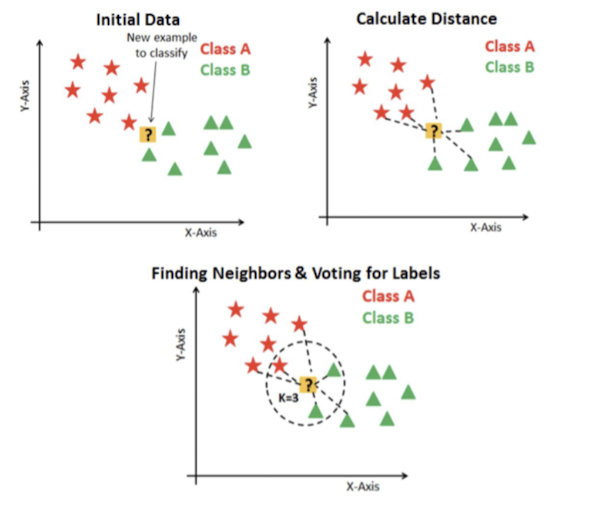
Logistic Regression과의 비교
Logistic Regression은 종속변수와 독립변수가 선형상관관계가 있을 것이라는 것을 가정한 상태에서 진행 (Parametric)
Knn은 그런 가정이 없기 때문에 조금 더 다이나믹.
knn은 속도가 더 느림. 결과만 제시.
Logistic regression은 주는 정보가 많고, 속도가 빠름.
회귀에서의 knn
- 객체의 특성값이며, 이 값은 nearest neighbor 값들의 평균
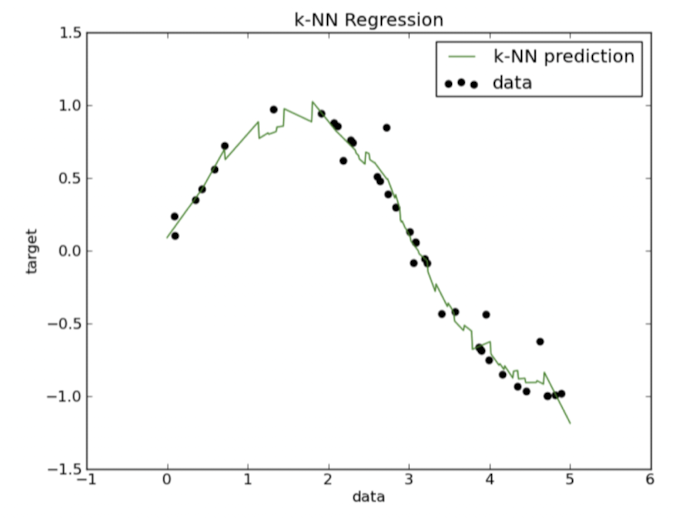

Frontend & Artificial Intelligence