TF
단어 w가 문서 d에 등장한 빈도수
문서 i에서의 단어 j의 중요도
흔하게 등장하는 단어는 중요하지 않은 단어
각 단어에 가중치를 부여해서 키워드 추출 등에 활용
문서에서 특정 단어가 등장하는 것으로 문서끼리 관련있음을 표현할 수 있음
IDF
해당 단어가 얼마나 다른 문서에 비해 해당 문서에서 특별한지 체크
movie lens 실습
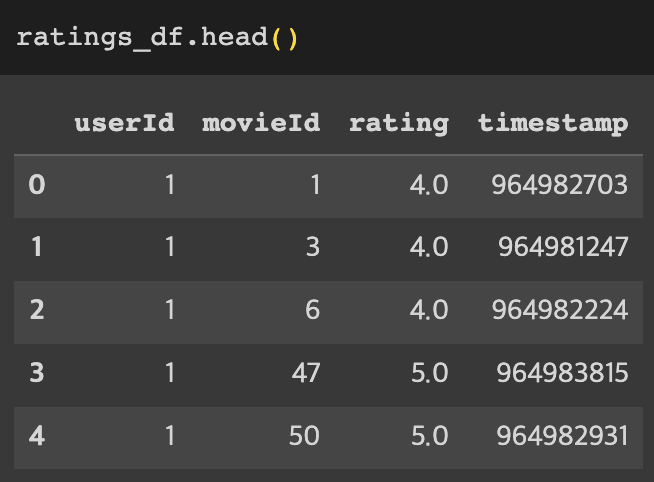
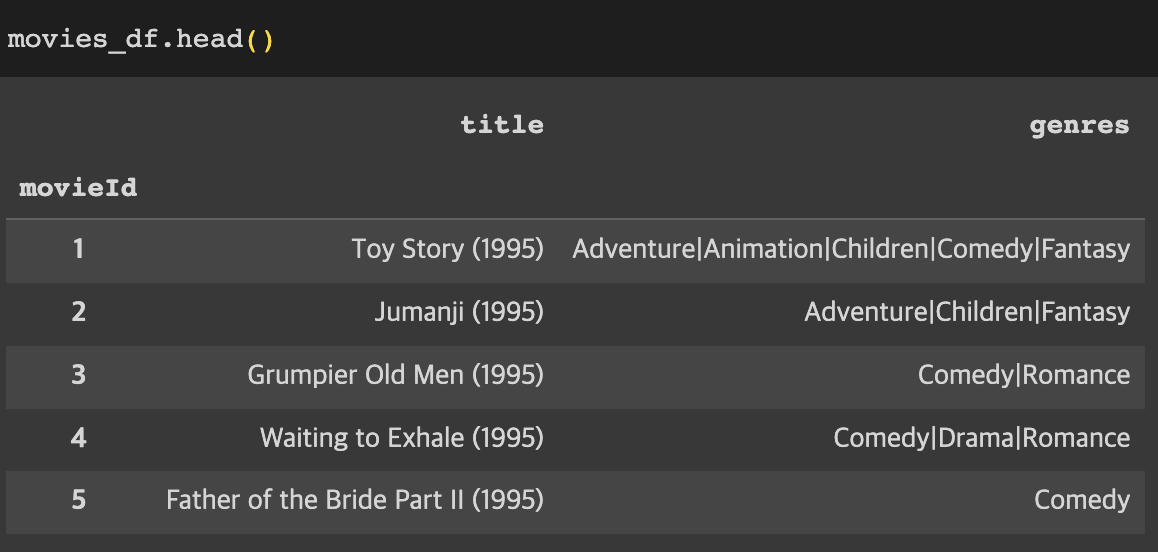
genre를 이용한 movie representation
total_count = len(movies_df.index)
total_genres = list(set([genre for sublist in list(map(lambda x: x.split('|'), movies_df['genres'])) for genre in sublist]))print(f"전체 영화 수: {total_count}")
print(f"장르: {total_genres}")
>>>전체 영화 수: 9742
>>>장르: ['Romance', 'Fantasy', 'Mystery', 'Comedy', 'War', 'Thriller', 'Sci-Fi', 'Adventure', 'Documentary', 'Crime', 'IMAX', 'Western', 'Children', 'Animation', 'Horror', '(no genres listed)', 'Film-Noir', 'Action', 'Drama', 'Musical']genre_count = dict.fromkeys(total_genres)
for each_genre_list in movies_df['genres']:
for genre in each_genre_list.split('|'):
if genre_count[genre] == None:
genre_count[genre] = 1
else:
genre_count[genre] = genre_count[genre]+1genre_count
>>>{'(no genres listed)': 34,
'Action': 1828,
'Adventure': 1263,
'Animation': 611,
'Children': 664,
'Comedy': 3756,
'Crime': 1199,
'Documentary': 440,
'Drama': 4361,
'Fantasy': 779,
'Film-Noir': 87,
'Horror': 978,
'IMAX': 158,
'Musical': 334,
'Mystery': 573,
'Romance': 1596,
'Sci-Fi': 980,
'Thriller': 1894,
'War': 382,
'Western': 167}for each_genre in genre_count:
genre_count[each_genre] = np.log10(total_count/genre_count[each_genre])
genre_count
>>>{'(no genres listed)': 2.457169208193496,
'Action': 0.7266719338379385,
'Adventure': 0.8872447746804204,
'Animation': 1.2026069149931968,
'Children': 1.1664800458677336,
'Comedy': 0.41392254164167785,
'Crime': 0.9098289421369025,
'Documentary': 1.3451954487495636,
'Drama': 0.3490620385623247,
'Fantasy': 1.0971106675631868,
'Film-Noir': 2.0491288726171324,
'Horror': 0.9983092704481497,
'IMAX': 1.7899910382813284,
'Musical': 1.4649016584241867,
'Mystery': 1.2304935032683613,
'Romance': 0.7856152382210405,
'Sci-Fi': 0.9974220495432562,
'Thriller': 0.7112681505684965,
'War': 1.4065847623240424,
'Western': 1.7659316540881678}많이 나온 장르일 수록 영화를 잘 설명하는 요인이 되지 못한다.
적게 나온 장르일 수록 영화를 잘 설명하는 요인이 된다.
# create genre representations
genre_representation = pd.DataFrame(columns=sorted(total_genres), index=movies_df.index)
for index, each_row in tqdm(movies_df.iterrows()):
dict_temp = {i: genre_count[i] for i in each_row['genres'].split('|')}
row_to_add = pd.DataFrame(dict_temp, index=[index])
genre_representation.update(row_to_add)
genre_representation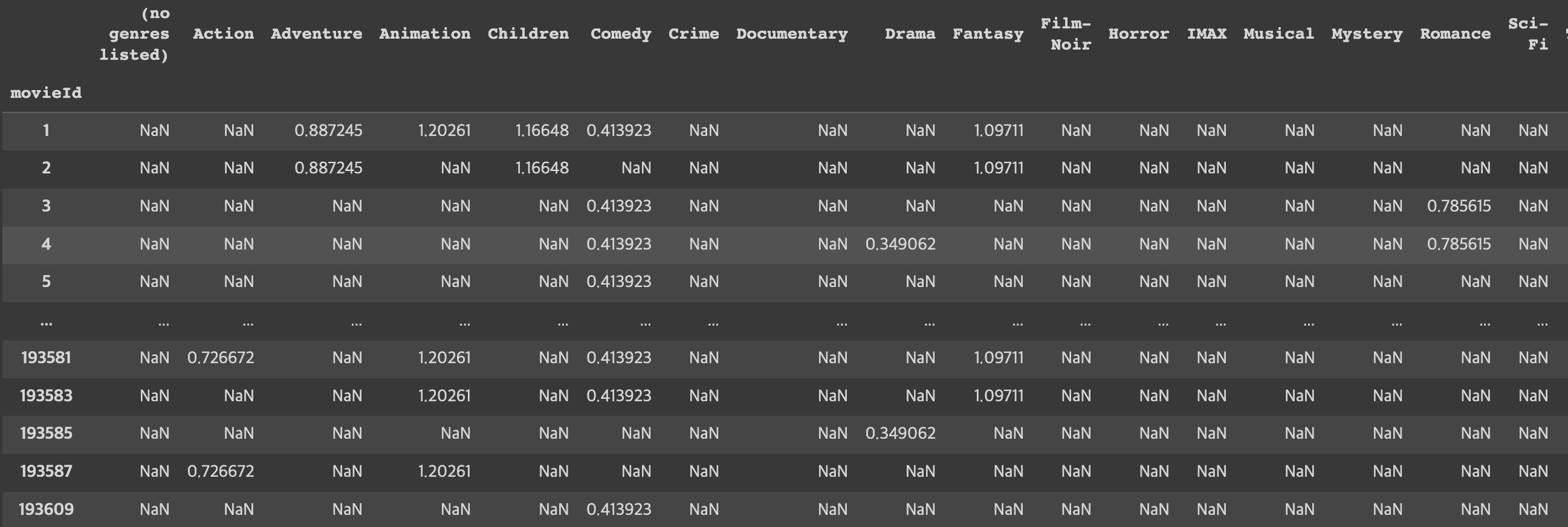
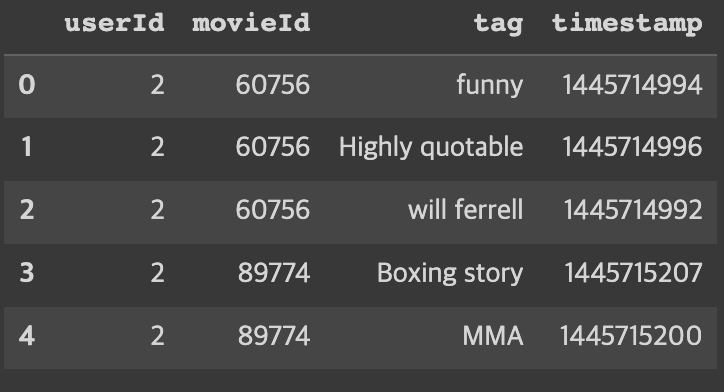
tag를 이용한 movie representation
# get unique tag
tag_column = list(map(lambda x: x.split(','), tags_df['tag']))
unique_tags = list(set(list(map(lambda x: x.strip(), list([tag for sublist in tag_column for tag in sublist])))))# Compute IDF for tag
total_movie_count = len(set(tags_df['movieId']))
# key: tag, value: number of movies with such tag
tag_count_dict = dict.fromkeys(unique_tags)
for each_movie_tag_list in tags_df['tag']:
for tag in each_movie_tag_list.split(","):
if tag_count_dict[tag.strip()] == None:
tag_count_dict[tag.strip()] = 1
else:
tag_count_dict[tag.strip()] += 1
tag_idf = dict()
for each_tag in tag_count_dict:
tag_idf[each_tag] = np.log10(total_movie_count / tag_count_dict[each_tag])
tag_idf# Create movie representations
tag_representation = pd.DataFrame(columns=sorted(unique_tags), index=list(set(tags_df['movieId'])))
for name, group in tqdm(tags_df.groupby(by='movieId')):
temp_list = list(map(lambda x: x.split(','), list(group['tag'])))
temp_tag_list = list(set(list(map(lambda x: x.strip(), list([tag for sublist in temp_list for tag in sublist])))))
dict_temp = {i: tag_idf[i.strip()] for i in temp_tag_list}
row_to_add = pd.DataFrame(dict_temp, index=[group['movieId'].values[0]])
tag_representation.update(row_to_add)
tag_representation = tag_representation.sort_index(0)
final movie representation
genre와 tag로 만들어진 representation을 합쳐서 각 movie의 vector로 만든다
movie_representation = pd.concat([genre_representation, tag_representation], axis=1).fillna(0)
print(movie_representation.shape)
print(movie_representation.describe())Contents 유사도 평가
Cosine similarity를 사용
from sklearn.metrics.pairwise import cosine_similarity
def cos_sim_matrix(a, b):
cos_sim = cosine_similarity(a, b)
result_df = pd.DataFrame(data=cos_sim, index=[a.index])
return result_dfcs_df = cos_sim_matrix(movie_representation, movie_representation)
cs_df.head()한 영화와 나머지 영화들 간의 코사인 유사도 측정

print(cs_df.shape)
print(cs_df[1].sort_values(ascending=False))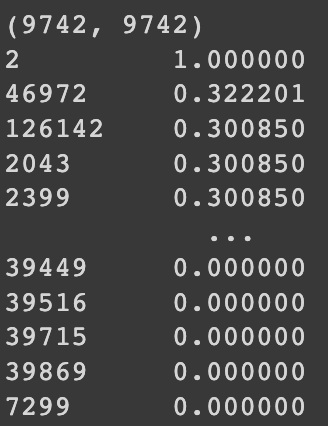
추천시스템의 성능 평가
train_df, test_df = train_test_split(ratings_df, test_size=0.2, random_state=1234)test_userids = list(set(test_df.userId.values))result_df = pd.DataFrame()
for user_id in tqdm(test_userids):
user_record_df = train_df.loc[train_df.userId == int(user_id), :]
user_sim_df = cs_df.loc[user_record_df['movieId']] # (n, 9742); n은 userId가 평점을 매긴 영화 수
user_rating_df = user_record_df[['rating']] # (n, 1)
sim_sum = np.sum(user_sim_df.T.to_numpy(), -1) # (9742, 1)
# print("user_id=", i, user_record_df.shape, user_sim_df.T.shape, user_rating_df.shape, sim_sum.shape)
prediction = np.matmul(user_sim_df.T.to_numpy(), user_rating_df.to_numpy()).flatten() / (sim_sum+1) # (9742, 1)
prediction_df = pd.DataFrame(prediction, index=cs_df.index).reset_index()
prediction_df.columns = ['movieId', 'pred_rating']
prediction_df = prediction_df[['movieId', 'pred_rating']][prediction_df.movieId.isin(test_df[test_df.userId == user_id]['movieId'].values)]
temp_df = prediction_df.merge(test_df[test_df.userId == user_id], on='movieId')
result_df = pd.concat([result_df, temp_df], axis=0)
result_df.head(10)
mse = mean_squared_error(y_true=result_df['rating'].values, y_pred=result_df['pred_rating'].values)
rmse = np.sqrt(mse)
print(mse, rmse)
>>> 1.40606646706041 1.1857767357561078
Frontend & Artificial Intelligence