1) OpenAPI 등 공개된 API 를 사용
공공데이터포털, NaverDevelopers, Mydata 허브 등2) HTTP Get Method
- 정보가 게시되어 있는 대상 웹사이트를 HTTP GET을 사용하여 HTML 코드를 얻고 Text Parsing해서 사용
- 거의 대부분의 언어로 구현 가능
- 동적으로 변하는 웹페이지에는 활용이 어려움3) Selenium Web Driver
- 본디 테스트를 위해 개발되었으나 데이터 수집용으로 활용 중
- 웹 브라우저 인스턴스를 생성해 실행시킨 후 해당 인스턴스를 컨트롤
- 웹사이트 테스트 자동화 목적으로 개발
- 가상의 브라우저를 실행시키는 Headless Mode 등이 있음
- HTTP GET 방식에 비해 느리고 불안정적이나 보다 많은 웹사이트를 스크래핑 가능
- 사람이 하는 것과 유사한 자동화 방법4) 사람이 수작업으로 데이터를 수집하는 방법
웹 크롤러 vs 웹 스크래퍼
웹 크롤러(Web Crawler)
조직적, 자동화된 방법으로 웹을 탐색/수집하는 프로그램
ex) 구글, 네이버 등의 검색엔진 결과 데이터를 수집하기 위한 봇(Bot)웹 스크래퍼(Web Scrapper)
웹사이트에서 정보를 추출하는 프로그램
ex) 상품별 가격을 알기 위해 해당 상품을 파는 페이지들의 가격을 추출- 크롤러보다는 대부분 단순 스크래퍼 개발 수요가 많음.
- 우리나라에서는 많은 기업들이 같은 의미로 혼용.
크롤링은 불법인가?
불법에 노출되기 쉬운 기술 중 하나라 주의
웹사이트의 홈디렉토리에 위치한 robots.txt 파일을 열어보고 해당 사이트의 정책을 준수하지 않는다면 불법
크롤링할 웹사이트의 URL의 /robots.txt로 접속하면 크롤링해도 되는 파일, 안 되는 파일을
Disallow와 Allow로 구분해서 명시해 놓음.크롤링한 자료를 상업적인 용도로 사용하면 불법
국내에서는 불법, 해외(미국)에서는 합법 판결이 난 전례가 있음 원작자의 수익을 해치지 않았다면 합법
비상업적인 용도라 하더라도 원작자에게 불이익을 주면 불법
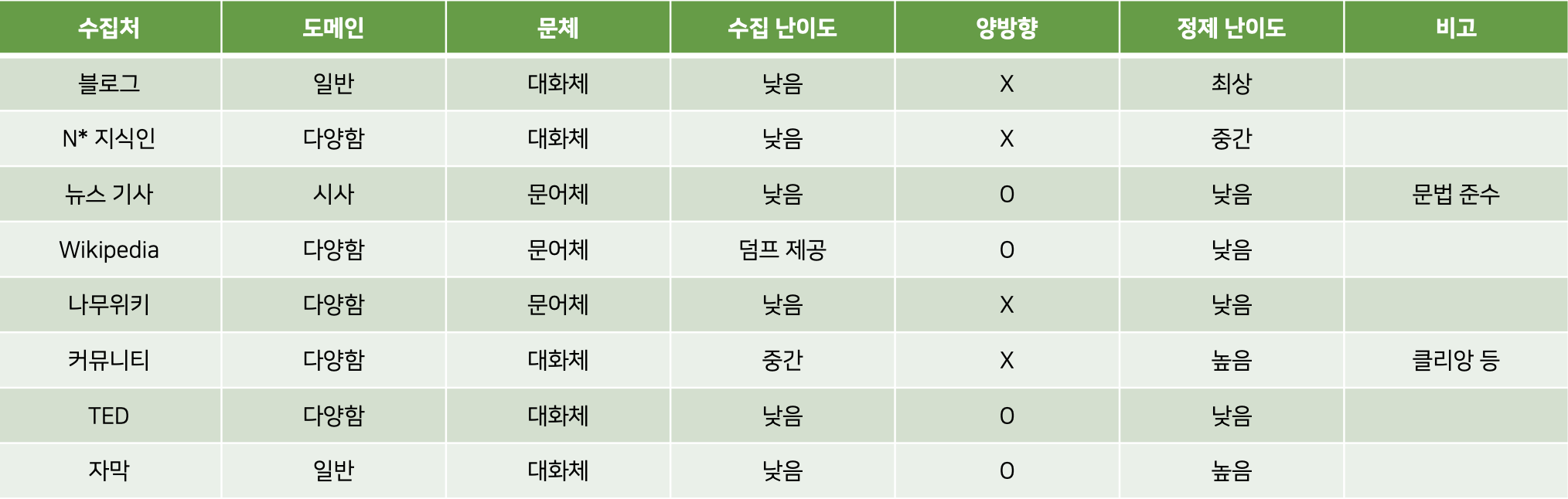
수집처

Frontend & Artificial Intelligence