Tools
- Google colab
- RhinoMorph
주요 코드 분석
치안뉴스 분류 단계에서 설명했듯이 학습용 데이터셋은 '아시아경제'와 '경남신문'에서 크롤링하였고,
완성된 모델을 팀원이 전달해준 '창원'을 검색어로 하여 크롤링한 뉴스 csv 파일에 적용해 치안뉴스인 것과 일반뉴스인 것을 구분하여 치안뉴스 데이터들만 수집하였다.
경로설정, 형태소 분석기 및 토크나이저 설치, Jpype 설치 등과 같은 코드는 생략한다.
# 필요한 라이브러리 import
import pandas as pd
import numpy as np
import os
import csv
import ast
from rhinoMorphExtension import findKeywordSentences#치안뉴스 데이터 엑셀 불러오기
news = pd.read_csv('치안뉴스.csv')
news = news.rename(columns={'0':'기사제목','1':'기사내용','2':'기사URL'})
news

#뉴스내용들 가져와서 리스트로 만듬
data2 = news['기사내용'].tolist()
#뉴스 기사에 들어있는 지 확인할 지역 단어 모음
regions=['의창구','성산구','마산합포구','마산회원구','진해구','진주시','진주','통영시','통영',
'사천시','사천','김해시','김해','밀양시','밀양','거제시','거제','양산시','양산','거창군','거창',
'의령군','의령','함안군','함안','창녕군','창녕','고성군','고성','남해군','남해','하동군','하동',
'산청군','산청','함양군','함양','합천군','합천']
#기사에서 지역 이름 추출
found_sentences = findKeywordSentences.findKeySentence(data=data2, keywords=regions) rhinoMorphExtension의 findKeywordSentences 메서드를 활용하여,
기사 내용들만 들어있는 리스트를 순회하며,
region 리스트에 들어있는 지역별로 분류한다.
# 나중의 활용을 위해 지역도출결과 csv 파일 생성
w = csv.writer(open("지역도출결과.csv", "w", newline=''))
for sen, key in found_sentences.items():
w.writerow([sen, list(set(key))])# csv 확인
df1 = pd.read_csv('지역도출결과.csv',encoding='utf-8',header=None)
df1.rename(columns = {0 : '기사내용',1:'지역분류'}, inplace = True)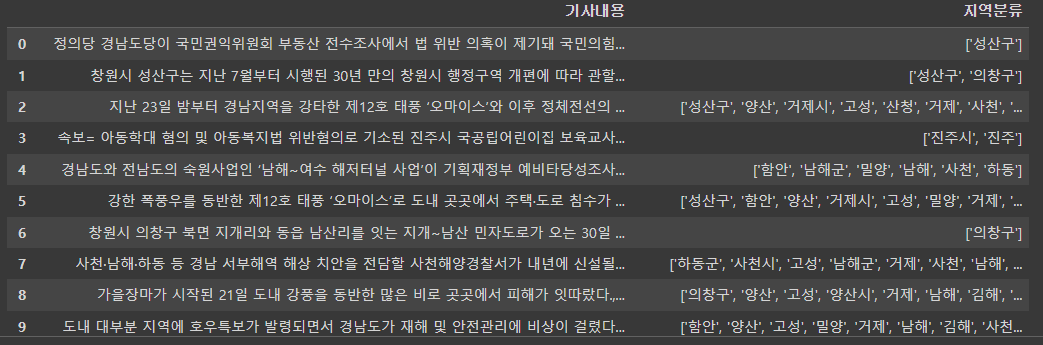
현재 지역분류에 담겨있는 내용들은 리스트로서 동작하는 것이 아니라 '문자열'이다.
이것이 리스트, 즉 지역들의 묶음으로서 동작할 수 있도록 처리해준다.
#[str] -> list
for i in range(0,len(df1)):
df1['지역분류'][i] = ast.literal_eval(df1['지역분류'][i])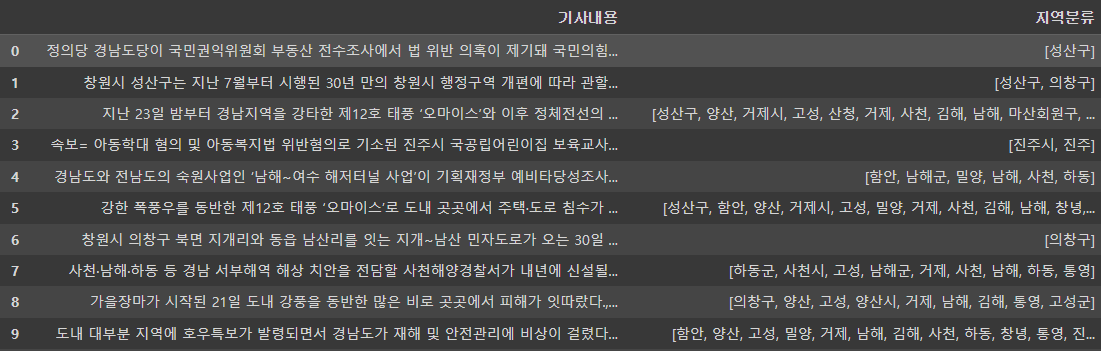
이제 지역분류 칼럼의 내용들은 리스트가 되었고, 리스트 내 지역 이름은 하나의 원소로서 동작한다.
그리고 지역분류를 위해 만약 기사 내에 '사천', '사천시'가 들어가 있으면 모두 '사천시'와 관련된 기사로 처리하도록 하는 것이 본래의 의도였기 때문에 관련 작업을 수행한다.
#두글자짜리 지역중에서 시/군 분류 작업
def region(X):
output = []
for x in X:
if len(x) <= 2:
if x in ['진주','김해','밀양','통영','사천','거제','양산']:
y = x+'시'
elif x in ['함안','창녕','남해','의령','거창','고성','하동','산청','함양','합천']:
y = x+'군'
else:
y = x
output.append(y)
return output
df1['지역분류'] = df1['지역분류'].apply(region)
#리스트 속 중복 제거
for i in range(0,len(df1)):
df1['지역분류'][i] = list(set(df1['지역분류'][i]))
두 글자, 세 글자 지역분류가 하나로 묶여 보다 깔끔하게 정리된 것을 확인할 수 있다.
이제 이 데이터프레임을 기사 내용을 기준으로 원래 뉴스 크롤링 테이블과 합쳐주면 작업 끝.
df1 = pd.merge(news, df1, left_on='기사내용', right_on='기사내용', how='inner')

Frontend & Artificial Intelligence