Tools
- jupyter notebook
주요 코드 분석
게임에 사용 된 '예/아니오 음성 분류 모델', '새 이름 분류 모델', '의성어/의태어 분류 모델'의 로직은 거의 동일하다. 학습에 유독 난항을 겪었던 '새 이름 분류 모델' 학습 코드를 가져와 보았다. 총 3660개의 데이터셋에서 3300개는 train에, 300개는 test에 사용했고, 60개는 모델 성능 확인용 샘플로 빼두었다.
%matplotlib inline
import matplotlib.pyplot as plt
import os
from scipy.io import wavfile
from collections import defaultdict, Counter
from scipy import signal
import numpy as np
import librosa
import sklearn
import random
from unicodedata import normalize
from keras.layers import Dense, Activation, BatchNormalization
from keras import Input
import librosa.display
from keras_preprocessing.sequence import pad_sequences
import tensorflow as tf
from keras.callbacks import EarlyStopping, ModelCheckpoint, LearningRateScheduler
import warnings
warnings.filterwarnings(action='ignore')모델 학습에 사용한 라이브러리들이다.
# 오디오 데이터
# 평균길이 : 1.10
DATA_DIR_TRAIN = './특화_음성/real_bird/train/'
DATA_DIR_TEST = './특화_음성/real_bird/test/'
# Data set list, include (raw data, mfcc data, y data)
trainset = []
testset = []
# split each set into raw data, mfcc data, and y data
train_X = []
train_mfccs = []
train_y = []
test_X = []
test_mfccs = []
test_y = []
# 모든 음성파일의 길이가 같도록 후위에 padding 처리
pad1d = lambda a, i: a[0: i] if a.shape[0] > i else np.hstack((a, np.zeros(i-a.shape[0])))
pad2d = lambda a, i: a[:, 0:i] if a.shape[1] > i else np.hstack((a, np.zeros((a.shape[0], i-a.shape[1]))))음성 데이터 특징 추출 & CNN 모델 학습
# train data를 넣는다.
for filename in os.listdir(DATA_DIR_TRAIN):
filename = normalize('NFC', filename)
try:
# wav 포맷 데이터만 사용
if '.wav' not in filename in filename:
continue
wav, sr = librosa.load(DATA_DIR_TRAIN+ filename, sr=16000)
mfcc = librosa.feature.mfcc(wav, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
# mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
padded_mfcc = pad2d(mfcc, 110)음성 데이터를 학습하기 위해서는 아날로그 데이터인 음성 데이터를 디지털 신호로 변환해야 하는데, 음성 데이터를 특징 벡터화 해주는 알고리즘에는 MFCC가 있다. 파이썬에서 제공하는 librosa 라이브러리를 이용해 간단히 MFCC 값을 추출할 수 있었다.
sr은 sampling rate로 초당 16000개의 샘플을 가지고 있는 데이터라는 의미이다. 따라서 audio shape와 sr을 이용해서 오디오 길이 계산을 할 수 있다.
mfcc = librosa.feature.mfcc(wav, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)이 부분이 음성 데이터의 특징을 추출하는 코드인데 넘겨준 파라미터로는 sr, n_mfcc, n_fft, hop_length가 있다.
① sr
sampling rate를 말한다. default값은 22050Hz인데 앞서 음성 데이터를 load 할 때 sr을 16000Hz으로 했기 때문에 꼭 sr=16000을 파라미터로 삽입해야 한다. (사람의 목소리는 대부분 16000Hz 안에 포함된다고 함)
② n_mfcc
return 될 mfcc의 개수를 정해주는 파라미터이다. default값은 20인데 더 다양한 데이터 특징을 추출하기 위해서 이를 100까지 증가시켰다.
③ n_fft
frame의 length를 결정하는 파라미터이다. n_fft를 설정하면 window size가 자동으로 같은 값으로 설정되는데 window size의 크기로 잘린 음성이 n_fft보다 작은 경우 0으로 padding을 붙여주는 작업을 하기 때문에 n_fft는 window size보다 크거나 같아야 한다.
일반적으로 자연어 처리에서는 음성을 25m의 크기를 기본으로 하고 있으며 이는 16000Hz인 음성에서는 400에 해당하는 값이다. (16000 * 0.025 = 400) 즉, n_fft는 sr에 frame_length인 0.025를 곱한 값이다.
④ hop_length
hop_length의 길이만큼 옆으로 가면서 데이터를 읽는다. 10ms를 기본으로 하고 있어 16000Hz인 음성에서는 160에 해당한다. (16000 * 0.01 = 160) 즉, hop_length는 sr에 frame_stride인 0.01를 곱해서 구할 수 있다.
window_length가 0.025이고 frame_stride가 0.01이라고 하면 0.015초씩은 데이터를 겹치면서 읽는다고 생각하면 된다.
padded_mfcc = pad2d(mfcc, 110)그 다음은 model에 들어갈 input shape를 조정하기 위해서 일정 범위까지만 데이터를 보는 작업을 추가했다. 즉, input의 길이보다 긴 경우는 자르고 짧은 경우는 padding을 붙여서 크기를 조절했다.
이 과정이 필요한 이유는 모은 음성 데이터의 길이가 일정하지 않고 다양한 길이를 가졌기 때문이다. 모은 음성데이터의 길이 평균이 1.1초이므로 이 길이를 110으로 정했다.
# 새 이름 별로 dataset에 추가
# 까마귀 : 0, 꿩 : 1, 뱁새 : 2, 오리 : 3, 참새 : 4, 황새 : 5
if filename[0] == '까':
trainset.append((padded_mfcc, 0))
elif filename[0] == '꿩':
trainset.append((padded_mfcc, 1))
elif filename[0] == '뱁':
trainset.append((padded_mfcc, 2))
elif filename[0] == '오':
trainset.append((padded_mfcc, 3))
elif filename[0] == '참':
trainset.append((padded_mfcc, 4))
elif filename[0] == '황':
trainset.append((padded_mfcc, 5))
except Exception as e:
print(filename, e)
raise
# 학습 데이터를 무작위로 섞는다.
random.shuffle(trainset)test 셋도 위 과정과 동일하게 반복한다.
# test data를 넣는다.
for filename in os.listdir(DATA_DIR_TEST):
filename = normalize('NFC', filename)
try:
# wav 포맷 데이터만 사용
if '.wav' not in filename in filename:
continue
wav, sr = librosa.load(DATA_DIR_TEST+ filename, sr=16000)
mfcc = librosa.feature.mfcc(wav, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
# mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
padded_mfcc = pad2d(mfcc, 110)
# 새 이름 별로 dataset에 추가
# 까마귀 : 0, 꿩 : 1, 뱁새 : 2, 오리 : 3, 참새 : 4, 황새 : 5
if filename[0] == '까':
testset.append((padded_mfcc, 0))
elif filename[0] == '꿩':
testset.append((padded_mfcc, 1))
elif filename[0] == '뱁':
testset.append((padded_mfcc, 2))
elif filename[0] == '오':
testset.append((padded_mfcc, 3))
elif filename[0] == '참':
testset.append((padded_mfcc, 4))
elif filename[0] == '황':
testset.append((padded_mfcc, 5))
except Exception as e:
print(filename, e)
raise
# 평가 데이터를 무작위로 섞는다.
random.shuffle(testset)위 코드로 모든 train/test 데이터에 대해 mfcc 특징을 추출한 np array를 구할 수 있었다.
train_mfccs = [a for (a,b) in trainset]
train_y = [b for (a,b) in trainset]
test_mfccs = [a for (a,b) in testset]
test_y = [b for (a,b) in testset]
train_mfccs = np.array(train_mfccs)
train_y = tf.keras.utils.to_categorical(np.array(train_y))
test_mfccs = np.array(test_mfccs)
test_y = tf.keras.utils.to_categorical(np.array(test_y))
print('train_mfccs:', train_mfccs.shape)
print('train_y:', train_y.shape)
print('test_mfccs:', test_mfccs.shape)
print('test_y:', test_y.shape)train_mfccs: (3300, 100, 110)
train_y: (3300, 6)
test_mfccs: (300, 100, 110)
test_y: (300, 6)
train_X_ex = np.expand_dims(train_mfccs, -1)
test_X_ex = np.expand_dims(test_mfccs, -1)
print('train X shape:', train_X_ex.shape)
print('test X shape:', test_X_ex.shape)train X shape: (3300, 100, 110, 1)
test X shape: (300, 100, 110, 1)
학습 데이터와 테스트 데이터가 모두 준비되면 모델의 층을 쌓고 학습한다.
우선 Conv2D, MaxPooling2D를 각각 3개씩 쌓는다.
ip = Input(shape=train_X_ex[0].shape)
m = tf.keras.layers.Conv2D(32, kernel_size=(4,4), activation='relu')(ip)
m = tf.keras.layers.MaxPooling2D(pool_size=(4,4))(m)
m = tf.keras.layers.Conv2D(32*2, kernel_size=(4,4), activation='relu')(m)
m = tf.keras.layers.MaxPooling2D(pool_size=(4,4))(m)
m = tf.keras.layers.Conv2D(32*3, kernel_size=(4,4), activation='relu')(m)
m = tf.keras.layers.MaxPooling2D(pool_size=(4,4))(m)CNN에서 Convolution Layer와 Pooling Layer를 반복적으로 거치면서 주요 특징만 추출되는데 이 때 추출된 주요 특징은 2차원 데이터로 이루어져 있지만 Dense와 같이 분류를 위한 학습 레이어에서는 1차원 데이터로 바꾸어서 학습이 되어야 한다.
이때 Flatten Layer가 2차원 데이터를 1차원 데이터로 바꾸는 역할을 한다.
dense layer은 입력과 출력을 연결짓는 layer이다.
m = tf.keras.layers.Flatten()(m)
m = Dense(64)(m)
m = BatchNormalization()(m)
m = Activation("relu")(m)
op = Dense(6, activation='softmax')(m)
model = tf.keras.Model(ip, op)예측 결과 확인
100회의 epoch를 거치면서 학습을 진행했는데, 처음에는 기본 Learning rate 설정값이 너무 높게 설정되어 있는 바람에 Validation loss가 급증하는 구간이 있었다. 이러한 문제에 관해 음성처리 분야를 전문으로 담당하고 계시는 현직자님을 만나 리뷰를 부탁드린 후 Learning rate를 낮춰보는 것이 좋을 것 같다는 코칭을 받을 수 있었고, Cosine decay 방식의 Learning rate scheduler, Early stopping, Model checkpoint와 같은 콜백 함수들을 사용하여 모델이 훈련용 데이터 셋에 과적합되지 않도록 할 수 있었다.
하이퍼 파라미터는 실험을 거듭하며 휴리스틱한 방법으로 수정해 나갔다.
cos_decay = tf.keras.experimental.CosineDecay(initial_learning_rate=0.0002, decay_steps=50, alpha=0.0)
learning_rate_scheduler = LearningRateScheduler(cos_decay)
early_stopping = EarlyStopping(monitor='val_loss', patience=10, verbose=1)
best_model = ModelCheckpoint(filepath='best_model.h5',
monitor='val_loss',
save_best_only=True)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(train_X_ex,
train_y,
epochs=100,
verbose=1,
callbacks=[early_stopping, best_model,learning_rate_scheduler],
validation_data=(test_X_ex, test_y))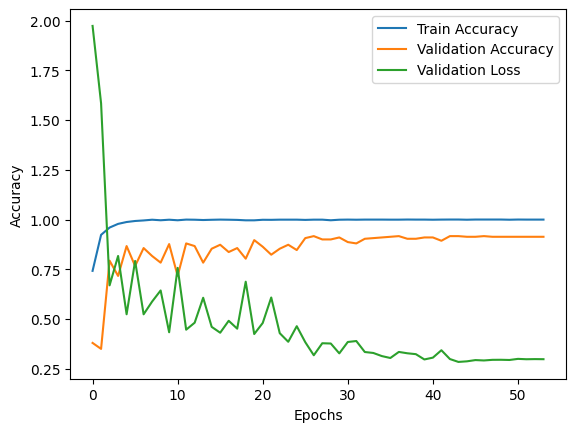
결과적으로 점진적으로 감소하는 Validation Loss를 나타내었고, 약 92% 정도의 Validation accuracy를 확보할 수 있었다.
이제 아까 빼둔 60개의 데이터셋으로 검증을 진행해본다.
# 샘플 오디오 데이터
model = tf.keras.models.load_model('best_model.h5')
DATA_DIR = './특화_음성/real_bird/validation/'
bingo = 0
# 까마귀 : 0, 꿩 : 1, 뱁새 : 2, 오리 : 3, 참새 : 4, 황새 : 5
for i in range(1,61):
if i < 10:
wav, sr = librosa.load(DATA_DIR + '참새60'+str(i)+'.wav', sr=16000)
mfcc = librosa.feature.mfcc(wav, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
# mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
padded_mfcc = pad2d(mfcc, 110)
padded_mfcc = np.expand_dims(padded_mfcc, 0)
result = model.predict(padded_mfcc)
if np.argmax(result) == 4:
bingo += 1
else:
print(np.argmax(result))
else :
wav, sr = librosa.load(DATA_DIR + '참새6'+str(i)+'.wav', sr=16000)
mfcc = librosa.feature.mfcc(wav, sr=16000, n_mfcc=100, n_fft=400, hop_length=160)
# mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
padded_mfcc = pad2d(mfcc, 110)
padded_mfcc = np.expand_dims(padded_mfcc, 0)
result = model.predict(padded_mfcc)
if np.argmax(result) == 4:
bingo += 1
else:
print(np.argmax(result))
print('맞춤 :', bingo/60 * 100)
맞춤 : 88.33333333333333
참새 데이터 뿐만 아니라 다른 새들에서도 괜찮은 성능을 보여주었다.
