
SSAFY 특화 프로젝트 기간에 6명의 팀원이 7주간 진행했던 프로젝트이다.
자율주행, 빅데이터 등 다양한 도메인 중에서도 인공지능 음성 도메인을 선택한 이유는
당시 음성처리 기술로 만들어보고 싶었던 확고한 서비스가 있었기 떄문이다.
원래는 음원 표절 탐지 서비스를 만들어보고 싶었다.
당시 내가 좋아했었던 아티스트인 '토이'의 표절 시비가 핫한 이슈였다.
토이에게 배신감과 실망을 느끼면서도,
이 무구한 세월 속에서 발매된 수많은 음악들 속에서 표절을 피해 새로운 곡을 만들어 내야하는 작곡가들의 애로사항이 분명 있을거라고 생각했다.
하지만 이 프로젝트 기획은 결국 실현되지 못했다.
왜냐하면 어쩄든 음악이 표절인지 아닌지를 판별하기 위해서는 모델이 수많은 음원들을 학습해야했고 그 '학습 데이터'들을 마련할 방안이 없었기 때문이다.
어찌보면 당연한 것인데... 내 생각이 많이 짧았다. 뭘 믿고 덤볐지?
그냥 운명적인 거였...나?
어찌됐든 이제 도메인을 바꿀수도 없는 난처해진 상황에서 음성처리를 활용한 새로운 프로젝트 주제를 생각해내야했고, 결국 음성인식으로 진행하는 한국어 및 한국문화 학습 게임 서비스를 만들어보자고 팀원들과 의견을 모으게 되었다.



'말해봐요, 알파곰'의 게임은 크게 STT, TTS 기술을 활용한 게임, AI 딥러닝 모델을 활용한 게임으로 구성되었는데, Pretrained된 딥러닝 분류 모델을 가져다 쓰는 것이 아닌, Tensorflow의 케라스를 기반으로 하고 있고 Librosa 라이브러리를 활용한 음성 데이터 특징 추출을 통해 음성인식을 가능케하는 새로운 CNN 모델을 직접 제작하여 사용하였다.
게임의 진행을 위해 문제의 정답에 해당하는 단어를 음성으로 입력받기 위해 기존에 없던 새로운 데이터 셋이 필요했고, 구글 티쳐블 머신의 녹음 기능을 활용하여 6명이서 총 13590개의 모델 학습용 음성 데이터 셋을 직접 생성하여 사용했다. 팀원들이 남자 2, 여자 4로 구성되어 있고, 나이대도 달라서 다양한 양상의 데이터를 수집할 수 있었다고 생각한다.
그리고 파이썬에서 제공하는 librosa 라이브러리를 통해 MFCC feature 수치를 추출 및 활용하여 음성 데이터들의 고유한 특징을 구분했다. 이를 기반으로 모델에 각 음성 데이터들을 학습시켰고 Test set 이외에 별도의 Validation set을 두어 예측 결과를 확인하였다.
학습 데이터가 충분하지 못한 상황이었기 때문에 훈련, 테스트 데이터 셋의 비율을 약 8:2로 설정하였고 세 개의 모델 모두 학습 과정에 배치 정규화와 스케일링 코드를 삽입하여 모델의 정확도를 향상시켰다.
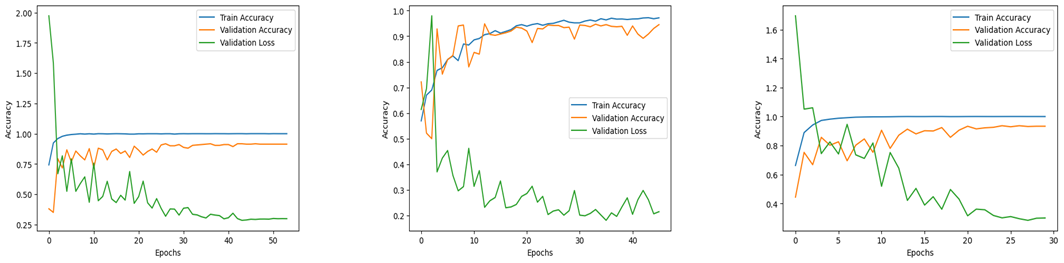
게임에 사용한 3개의 모델들의 학습 양상 시각화 그래프이다.
평균 30회의 epoch를 거치면서 학습을 진행했는데, 처음에는 기본 Learning rate 설정값이 너무 높게 설정되어 있는 바람에 Validation loss가 급증하는 구간이 있었다. 이러한 문제에 관해 음성처리 분야를 전문으로 담당하고 계시는 현직자님을 만나 리뷰를 부탁드린 후 Learning rate를 낮춰보는 것이 좋을 것 같다는 코칭을 받을 수 있었고, Cosine decay 방식의 Learning rate scheduler, Early stopping, Model checkpoint와 같은 콜백 함수들을 사용하여 모델이 훈련용 데이터 셋에 과적합되지 않도록 할 수 있었다.
결과적으로 게임 내의 모델 모두 점진적으로 감소하는 Validation Loss를 나타내었고, 평균 92% 정도의 Validation accuracy를 확보할 수 있었다.
팀원들 중 아무도 AI를 다뤄본 경험이 없어 혼자 고민하고 결정을 내려야 하는 과정이 어색하고 힘들기도 했지만, Notion, Git, Notion, Jira 등의 협업 툴을 활용해 온오프라인으로 협업하는 과정에서 많은 것을 배울 수 있었던 것 같다.
무엇보다 '직감'의 중요성을 많이 깨닫게 된 것 같다. AI가 데이터를 기반으로 학습하는 것처럼, AI 개발자는 이론적인 공부보다 직접 파라미터를 수정하고 모델을 생성해보면서 학습하고 성장할 수 있는 것 같다는 생각이 들었다.
프로젝트에 사용된 데이터 하나하나의 소중함도 느끼게 되었다. 데이터의 개수에 따라, 그리고 그로부터 결정되는 훈련/테스트 데이터셋을 나누는 비율에 따라, AI의 성능에 엄청난 차이가 나는 것을 보고 데이터 확보의 중요성과 효율적인 데이터셋 활용에 관해 배울 수 있었다.
자세한 프로젝트 설명은 이곳에서 확인할 수 있다.
말해봐요, 알파곰 깃허브
