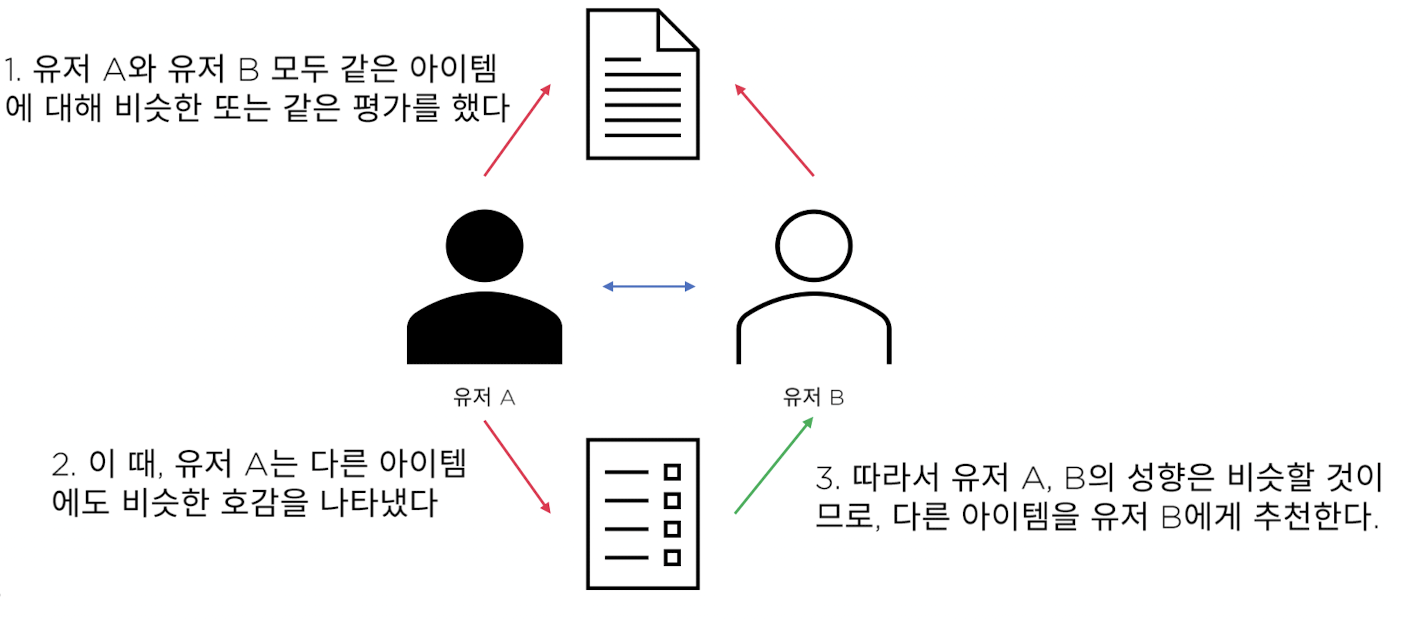
많은 사람의 의견으로 더 나은 추천을 한다. (집단지성)
이웃 기반 협업 필터링
- user-item 간의 평점 등 주어진 데이터로 새로운 아이템을 예측
- 구현이 간단하다
- Model Based에 비해 계산량이 적다
- 새로운 user, item이 추가되더라도 비교적 안정적이다.
- 새로운 content를 추천할 수 있다.
user based
- 두 사용자가 얼마나 유사한 항목을 좋아했는지 바탕으로 추천
- 취향이 비슷한 사용자끼리의 데이터를 바탕으로 추천
- 플랫폼에서 유저가 많은 부분을 차지하는 시스템에 적용하기 적절한 알고리즘 ex) sns 친구추천
- user의 수 < item의 수 : user-based가 정확
- 여러 유저의 데이터를 보기 때문에 더 새로운 추천을 할 수 있다
- 설명력이 낮다
item based
- 아이템-아이템 사이의 유사도 계산
- 여러 사용자의 과거 선호도 데이터로 연관성 높은 아이템을 찾고, 해당 아이템 추천
- 과거 아이템 데이터에 의존하기 때문에 새로운 item을 추천하기 어렵다
- 설명력이 높다
- user의 수 > item의 수 : item-based가 정확
- item의 수가 크게 변하지 않는다면, item-based
단점
- cold-start 문제
- 충분한 데이터가 없다면 좋은 추천을 할 수 없다
- 유저에 대한 아무런 기록이 없다면, 새로운 아이템에 대한 정보가 없다면, 추천 불가능
- 계산량
- 데이터가 많아질수록 유사도 계산이 많아진다
- 하지만 데이터가 많아야 추천 품질이 좋아지는...
- Long-tail economy
- 대부분의 사용자가 관심갖는 소수 아이템으로 쏠림 현상
- 관심이 상대적으로 부족한 아이템은 추천되지 못하는 현상
유사도
- 자카드 유사도
- 집합의 개념을 이용한 유사도 계산
- 집합 A와 B 사이에 얼마나 많은 아이템이 겹치는지로 판단
- 주로 여러 단어로 구성된 문서 또는 문장이 유사한지 판단할 때 사용
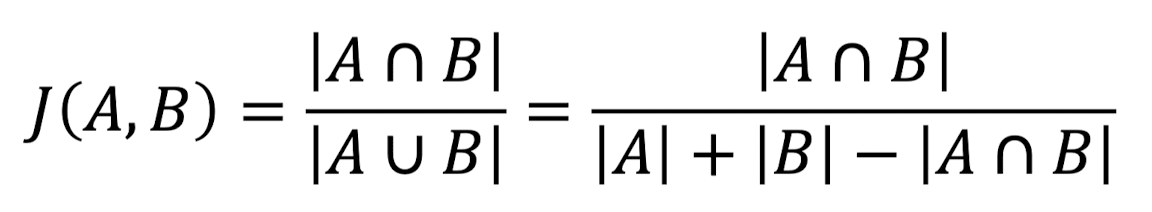
- 피어슨 유사도
- 각 vector의 표본평균으로 각 vector을 정규화하고, 코사인 유사도를 구한다
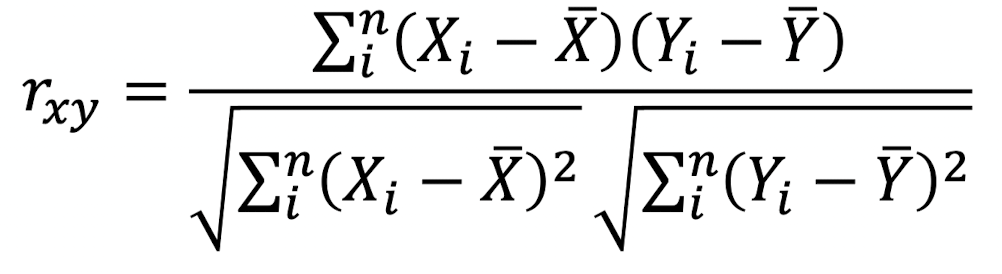
- 각 vector의 표본평균으로 각 vector을 정규화하고, 코사인 유사도를 구한다

Frontend & Artificial Intelligence