1. BeautifulSoup
- 웹에서 가져온 데이터에서 원하는 특정 태그나 태그 안의 내용 등을 쉽게 파싱할 수 있도록 도와주는 라이브러리
- bs를 사용하면서 중요한 것은 내가 원하는 특정 태그를 찾아서 그 값을 가져오는 것 > HTML을 잘 알아야 함
본 크롤링은 Python을 기반으로 함
1) 설치
pip install beautifulsoup42) 기본 사용법
import requests
from bs4 import BeautifulSoup
url = 'http://www.naver.com'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
print(soup)
else :
print(response.status_code)
- html의 전체 코드를 가져온 모습을 확인할 수 있음
3) 특정 태그를 선택하는 법
(0) 기준
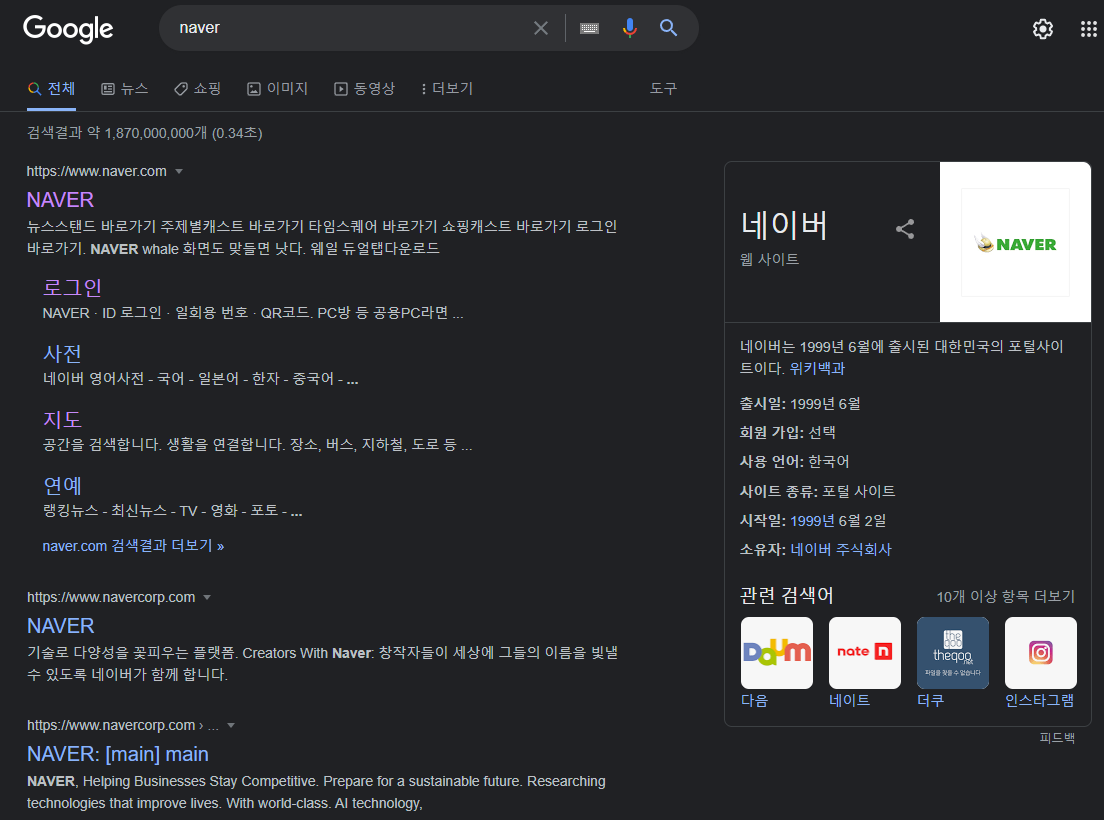
- 구글에 naver를 검색한 화면을 기준으로 설명
(1) soup.find_all()
soup.find_all('태그이름')
soup.find_all(class_='클래스이름')
soup.find_all(attrs={'class':'클래스이름'})
soup.find_all(attrs={'id':'아이디'})
- html에서 태그를 찾아가는 방법은 크게 3가지 방법이 있음
- 태그명
- 빨간 박스처럼
<div> <h3> <form>등 <>으로 묶이는 태그로 찾아갈 수 있음- 클래스 이름
- 초록 박스처럼 class="클래스명"으로 찾아갈 수 있음
- id
- 파란 박스처럼 id="아이디 이름"으로 찾아갈 수 있음
- 이는 soup.find와 동일함
P.S. soup.find_all() vs soup.find() 차이
import requests
from bs4 import BeautifulSoup
url = 'https://www.google.com/search?q=naver&oq=naver&aqs=chrome..69i57j35i39j0i433i512l2j0i131i433i512j0i433i512l2j0i512l2.551j0j15&sourceid=chrome&ie=UTF-8'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
h3 = soup.find('h3')
h3_list = soup.find_all('h3')
print('soup.find')
print(h3)
print('******************\n\n')
print('soup.find_all')
print(h3_list)
- soup.find('h3') => 가장 첫 번째 h3 태그를 출력
- soup.find_all('h3') => 모든 h3 태그를 출력(리스트 형식으로 출력
(2) soup.select()
soup.select("#id")
soup.select(".클래스이름")
soup.select("태그 이름")
soup.select("태그 이름 > 태그 이름")
- ID 는 앞에 #을 붙임
클래스이름은 앞에 .을 붙임
태그 이름은 그냥 태그 이름을 씀
자식 태그는 부모 > 자식 처럼 씀(직계)- soup.find_all() 보다 더 많이 쓰임

사진은 남아 추억이 메모는 남아 스펙이 된다