1. WordCount
1) mapper
f = open("C:/vmware/frozen_script.txt", "r") lines = f.readlines() #'f' 파일을 한줄씩 읽어온다. for line in lines: #line 한줄씩 출력 print(line) f.close파일을 읽어 한 줄씩 출력
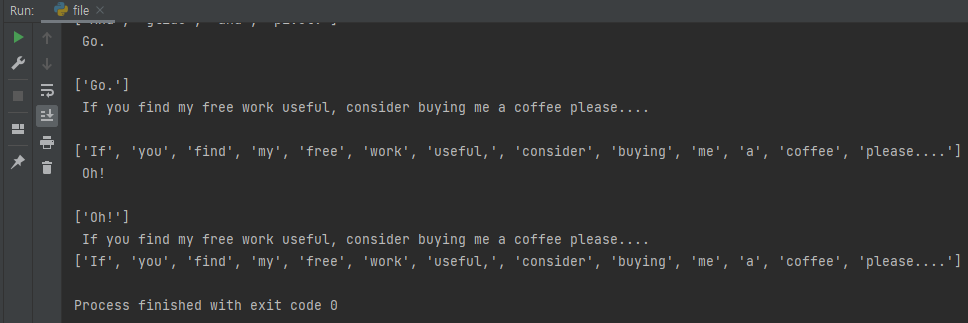
f = open("C:/vmware/frozen_script.txt", "r") lines = f.readlines() #'f' 파일을 한 줄씩 읽어온다. for line in lines: print(line) words = line.strip().split(" ") #양 끝의 공백을 지우고 공백으로 나뉨 print(words)
- strip() : 양끝의 공백 제거 ex) ' abc ' > 'abc'
- split() : 괄호안의 값을 기준으로 나눠서 리스트에 저장 line.split(" ") > 공백을 기준으로 나눠서 저장
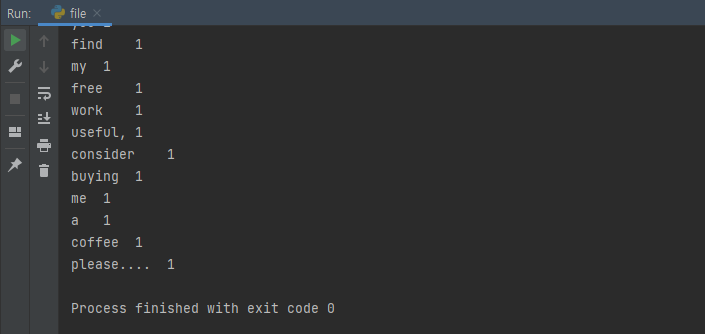
f = open("C:/vmware/frozen_script.txt", "r") lines = f.readlines() #'f' 파일을 한 줄씩 읽어온다. for line in lines: print(line) words = line.strip().split(" ") #양 끝의 공백을 지우고 공백으로 나뉨 for word in words: print('{}\t{}'.format(word, 1)) #format : 문자열을 특정 형식으로 바꿔주는 명령어 > 따라서 결과는 word\t1로 출력한다 f.close
- format : " [word] \t 1 " 이런식으로 출력
import sys for line in sys.stdin: #stdin : standard input > 표준입력 print(line)
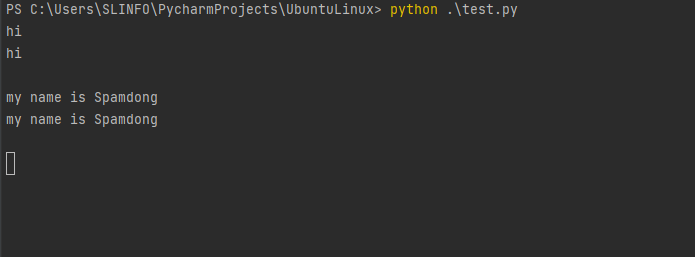
python .\test.py
import sys는 Terminal에서 실행시킨다.
실행시, linux명령어인 cat처럼 표준입력을 받아 그대로 출력 시킨다.
#file.py import sys for line in sys.stdin: #stdin : standard input > 표준입력 words = line.strip().split(" ") #양 끝의 공백을 지우고 공백으로 나뉨 for word in words: print('{}\t{}'.format(word, 1)) #format : 문자열을 특정 형식으로 바꿔주는 명령어 > 따라서 결과는 word\t1로 출력한다
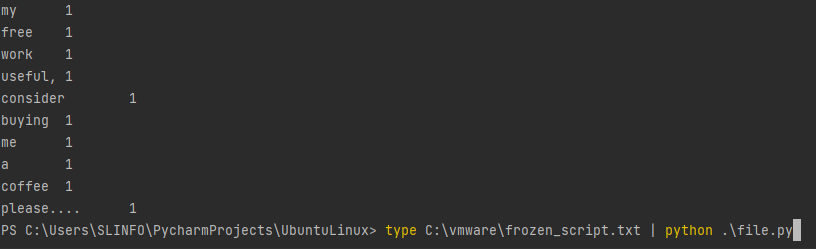
type C:\vmware\frozen_script.txt | python .\file.py #python
cat /frozen_script.txt | python3 ./file.py #linux
type은
명령어를 이용해 겨울왕국 txt파일 실행
이를 이용해 Linux에서도 실행이 가능함(결과는 같음)

2) reducer
- 1)에서 만든 mapper는 중복된 단어가 있어도 1이 출력됨 > 이제 같은 단어가 있으면 count가 +1이 될 수 있도록 작업
import sys current_word = None current_cnt = 0 word = None for line in sys.stdin: #stdin : standard input > 표준입력 columns = line.strip().split('\t') word = columns[0] count = int(columns[1]) if current_word == word: current_cnt += count else: current_cnt = count current_word = word if current_word == word: print('{}\t{}'.format(current_word, current_cnt))
cat Avatar.txt | python3 mapper.py | python3 reducer.py리눅스에 실행시
a 1 a 2 a 3 b 1 b 2정렬이 안된 상태에서 실행시
a 1 a 2 b 1 a 1 b 1따라서, 정렬이 무조건 필요하다
cat Avatar.txt | python3 mapper.py | sort | python3 reducer.py
Avatar.txt 파일을 표준출력 > mapper.py 실행 > 정렬 > reducer.py 실행


사진은 남아 추억이 메모는 남아 스펙이 된다