Hadoop
1.Hadoop 환경 구성 및 설치
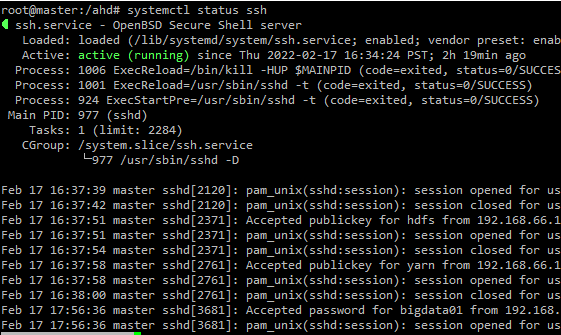
0. 준비 > ubuntu 3(master, worker1, 2)개를 준비하고, Network는 NAT로 설정 1. 컴퓨터 설정 0) 노드 >- 마스터 노드 : 192.168.66.10 워커 노드 : 192.168.66.20 / 192.168.66.30 1) 컴퓨터 이름 변경 (1) 마스터 노드 >vi /etc/hostname #이름을 master로 ...
2.Hadoop이란

1. Hadoop이란? > - Hadoop은 하나의 성능 좋은 컴퓨터를 이용하여 데이터를 처리하는 대신 적당한 성능의 범용 컴퓨터 여러대를 클러스터화하여 큰 크기의 데이터를 클러스터에서 병렬로 동시에 처리하여 처리 속도를 높이는 것을 목적으로 하는 분산처리를 위한 오픈소스 프레임워크 2. Hadoop의 구성요소 1) Hadoop Common > - 하둡의...
3.Hadoop 명령어
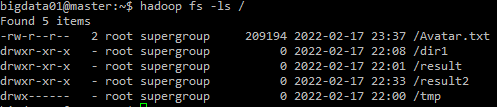
0. Hadoop 명령어 공식 홈페이지 >- 공식 홈페이지 명령어 설명서 공식 홈페이지 명령어 HDFS 명령어 틀 hdfs dfs -[서브명령어] or hadoop fs -[서브명령어] * 1. HDFS 명령어 >#### 1) ls 명령어 > 디렉토리 or 파일을 볼 수 있는 명령어 hadoop fs -ls [경로] 2-1) du 명령어 > 파일의 ...
4.Hadoop WordCount 예제
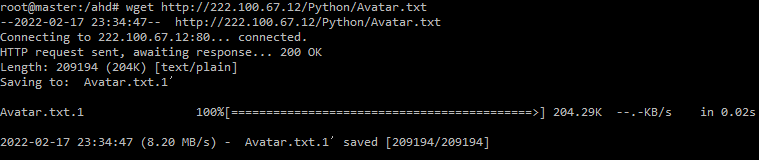
0. 영화 대본 다운로드 및 HDFS 파일시스템에 업로드 > #### 1)영화대본 Avatar.txt를 다운 wget http://222.100.67.12/Python/Avatar.txt 2) Avatar.txt 파일을 HDFS 파일시스템 최상위 디렉토리에 업로드 hadoop fs -put Avatar.txt / 3) HDFS 파일시스템에 Avatar.t...
5.WordCount
1. WordCount 1) mapper > 파일을 읽어 한 줄씩 출력 strip() : 양끝의 공백 제거 ex) ' abc ' > 'abc' split() : 괄호안의 값을 기준으로 나눠서 리스트에 저장 line.split(" ") > 공백을 기준으로 나눠서 저장 format : " [word] \t 1 " 이런식으로 출력 *