개요
- EC2로 실시간 크롤링하여 데이터를 Kafka를 이용하여 데이터를 전달할 예정
데이터
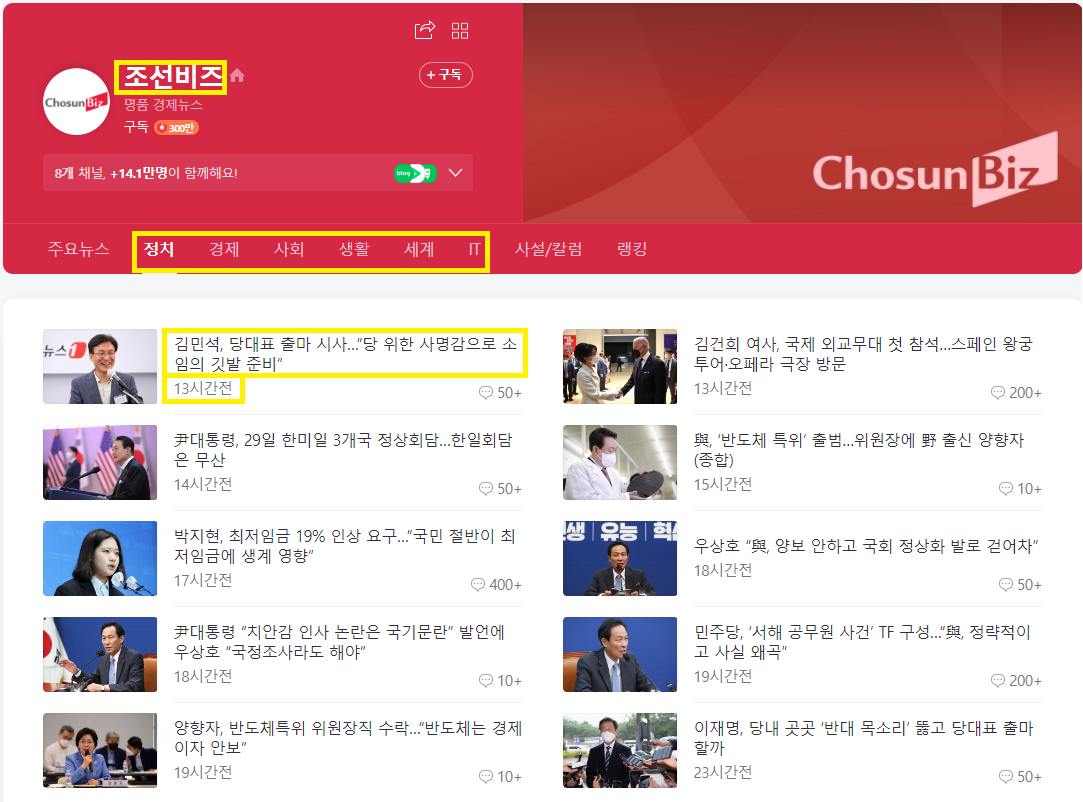
- 신문사
- 주제
- 시간
- 뉴스 url
제한사항
- 실시간 크롤링이므로
1분전인 글만 crawling 나머지들은continue - '.,`"[]?! 등 특수문자 제거
Install
pip install kafka-python
pip install elasticsearch
pip install beautifulsoup4Code
import requests
from bs4 import BeautifulSoup
from kafka import KafkaProducer
import time
from json import dumps
# 각 16 신문사 총 32 신문사 > 2개로 클러스터링
news_url_numbers = ['437','020','016','057','028','005','023','032','214','366','277','448','079','088','449']
# news_url_numbers = ['421','056','025','003','055','047','052','001','015','215','422','469','081','018','014','022']
# Kafka 프로듀서 셋팅 부분
producer = KafkaProducer(
acks=0,
compression_type='gzip',
bootstrap_servers=['Ipaddr:33149'],
value_serializer=lambda v: dumps(v).encode('utf-8'),
)
news_type_numbers = ['154', '100', '101', '102', '103', '104']
news_type = ['대선', '정치', '경제', '사회', '생활', '세계']
# 제거할 문자
remove_text = '''.,'"“”‘’[]?!'''
# 띄어쓰기로 교체할 문자
space_text = '·…'
title_list = ['' for num in range(0,15)]
# 크롤링 시작
while True:
start = time.time()
for news_url_number in news_url_numbers:
news_type_num = 0
for news_type_number in news_type_numbers:
# 네이버 뉴스 크롤링
response = requests.get('https://media.naver.com/press/' + news_url_number + '?sid=' + news_type_number)
if response.status_code == 200:
# time.sleep(0.5)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
news_titles = soup.select('.press_edit_news_title')
news_times = soup.select('.r_ico_b.r_modify ')
news_urls = soup.select('.press_edit_news_link._es_pc_link')
news_company = soup.select('.press_hd_name_link')[0].text.strip()
for i in range(0, 2):
try:
news_title = news_titles[i].text
news_url = news_urls[i].attrs['href']
news_time = news_times[i].text
except:
continue
if news_url.split('/')[5][:-8] in title_list:
continue
if '시간전' in news_time or '일전' in news_time or '2022' in news_time:
continue
if int(news_time.split('분전')[0]) < 2: # 몇분전 데이터를 >가져올 것인지
del title_list[0]
title_list.append(news_url.split('/')[5][:-8])
# print(title_list)
for remove in remove_text:
news_title = news_title.replace(remove, '')
for space in space_text:
news_title = news_title.replace(space, ' ')
# 'news' 토픽으로 전송
producer.send('news', {
'title': news_title,
'news_company': news_company,
'news_url': news_url,
'news_type': news_type[news_type_num],
})
producer.flush()
news_type_num += 1
print("time :", time.time() - start)결과
-
selenium & requests가 아닌 bs4 & requests를 사용한 이유
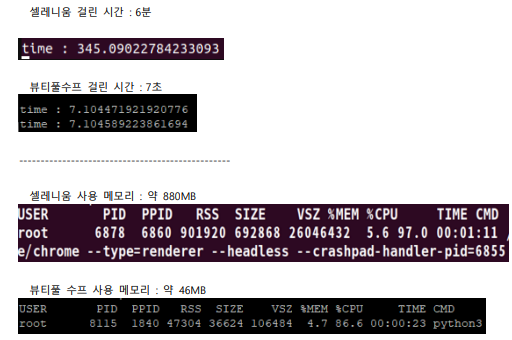
-
위 그림과 같이 셀레니움은 메모리를 많이 차지하여 속도가 느린 모습을 확인할 수 있음
-
EC2를 2개를 사용하여 실행하는 모습
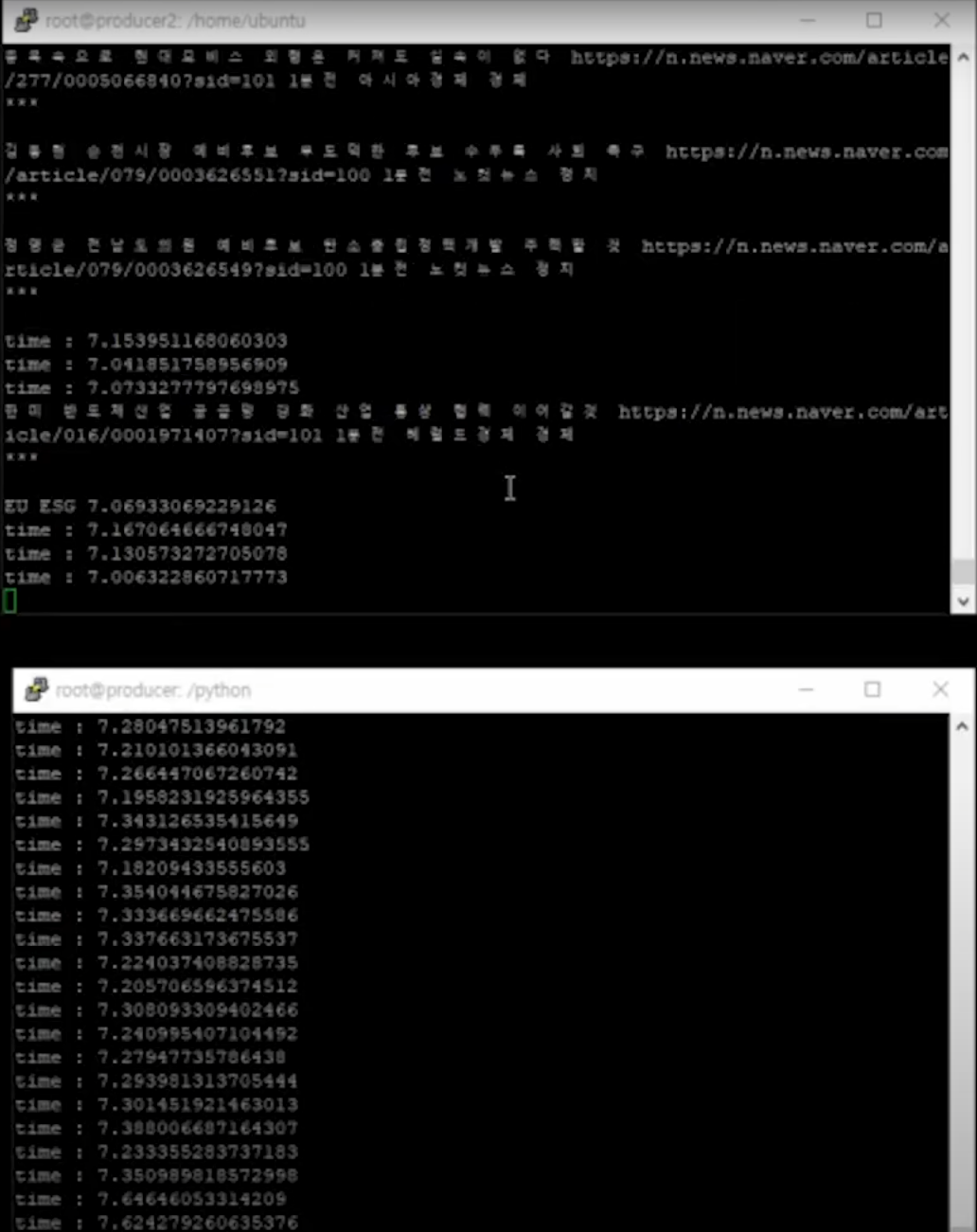
URL

사진은 남아 추억이 메모는 남아 스펙이 된다