우리는 θ를 학습하기 위해서 gradient ascent (경사 상승법)을 사용합니다. Linear regression은 gradient descent (경사 하강법)을 사용했는데, 이는 J(θ)가 최소가 되게 하는 θ를 학습했기 때문입니다.
반대로 logistic regression에서는 ℓ(θ)가 최대가 되게 하는 θ를 학습해야 하기 때문에, gradient ascent를 사용합니다.
벡터 표기법으로는 다음과 같이 업데이트합니다:
θ:=θ+α∇θℓ(θ)
(※ 여기서는 최대화이므로, 업데이트 식에서 부호가 양수입니다.)
하나의 훈련 예제 (x,y)를 가지고 미분을 통해 확률적 경사 상승 규칙을 유도해 봅시다:
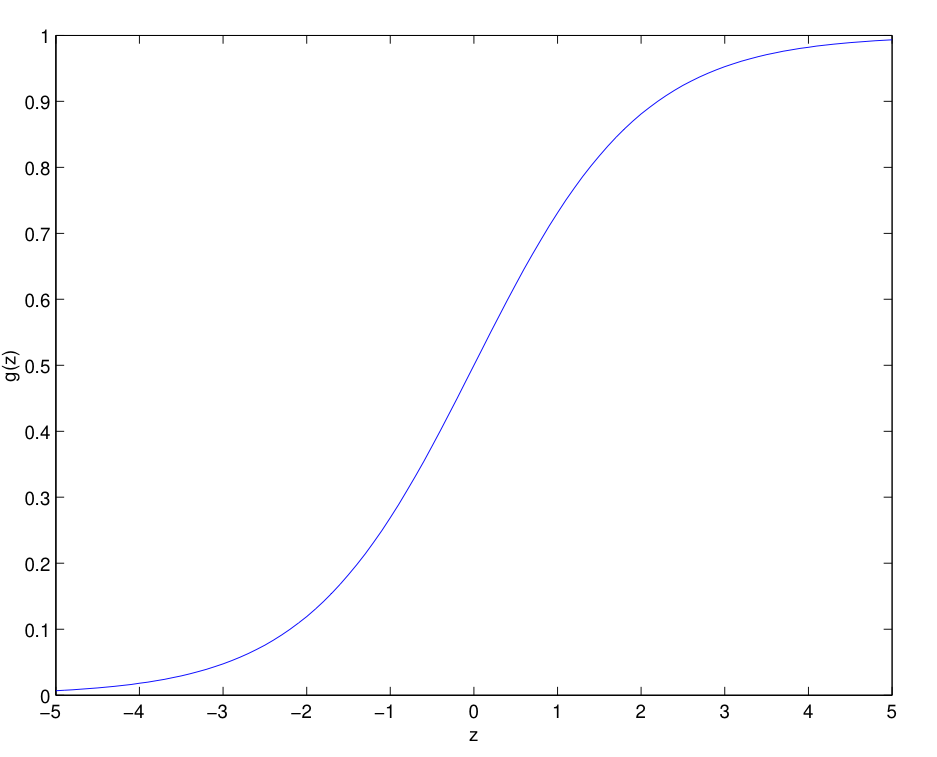
여기서 hθ(x)=g(θTx) 는 시그모이드 함수입니다.
이를 사용해서, 아래와 같은 gradient ascent rule을 작성할 수 있습니다:
θj:=θj(y(i)−hθ(x(i))xj(i)
신비롭게도, 우리가 구한 공식은 linear regression의 LMS update rule과 아주 유사한 공식을 유도해 냈습니다 (hθ(x(i))가 다르기 때문에).
이것은 단순한 우연일까요? 아니요! 이에 대한 답은 GLM (generalized linear model)에서 제공합니다.
2.2) Digression: the perceptron learning algorithm
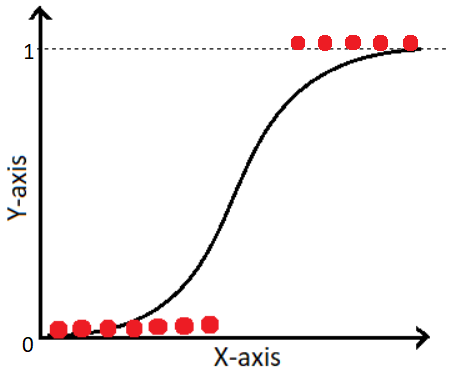
로지스틱 회귀가 출력을 확률 값으로 (0~1)로 반환했다면, perceptron은 출력을 0 또는 1로 강제합니다.
이를 위해 로지스틱 회귀의 시그모이드 함수 g(z) 대신, 계단 함수 (threshold function)으로 정의를 바꿉니다.
g(z)={10if z≥0if z<0
이제 예측 함수 hθ(x)=g(θTx)는 확률이 아닌, 이진출력 (0 또는 1)을 반환합니다.
Perceptron learning algorithm
1960년대에, 뇌의 뉴런 모델을 단순화했다고 해서 붙여진 이름입니다. 로지스틱 회귀와 비슷해 보이지만, 전혀 다른 방식입니다. 로지스틱 회귀는 확률적 해석과 우도 최대화 (maximum likelihood)가 가능하지만, perceptron은 그러한 통계적 해석이 전혀 불가능합니다.
로지스틱 회귀에서와 마찬가지로, Perceptron도 경사 상승과 비슷한 업데이트 규칙을 사용합니다:
θj:=θj+α(y(i)−hθ(x(i)))xj(i)
이 식은 다음 의미를 가집니다:
y(i): 실제 값
hθ(x(i)): 예측 값 (0 또는 1)
xj(i): 입력 벡터의 j번째 성분
α: 학습률
→ 예측이 틀렸을 때만 파라미터를 업데이트합니다.
2.3) Another algorithm for maximizeing ℓ(θ)
로지스틱 회귀는 closed form solution이 없습니다.
수치 해석학의 Newton's method를 사용해서, 정답에 가장 가까운 값을 근사할 수 있습니다.
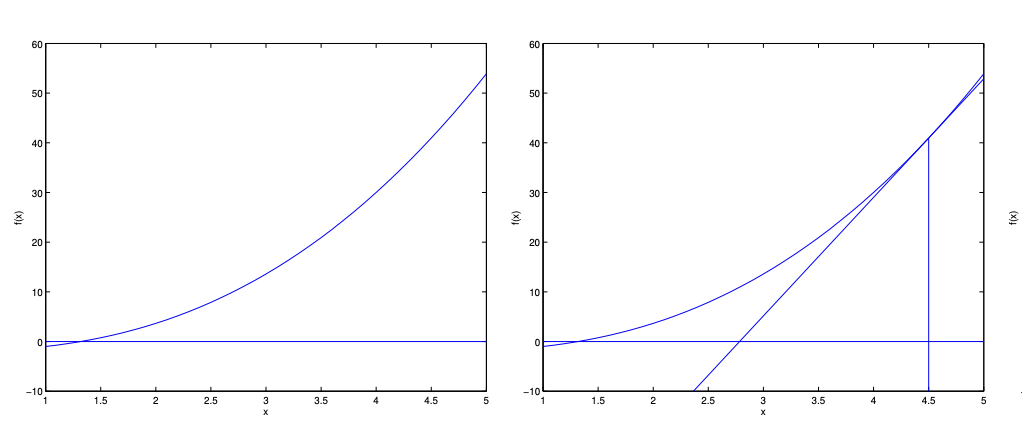
시작 f(x)와 1st step입니다. x를 4.5로 initialize한다면, tangent line을 그려서 f(x)=0이 되는 선을 그려서 x를 f(x)가 0이 되는 x의 값으로 가깝게 갈 수 있습니다.
여기서 가로를 Δx, 세로를 f(x)라고 할 때, x1:=x0−Δ 라는 식을 만들 수 있습니다 (xi는 i번째 step의 x).
f′(x0)=Δf(x0)임을 이용해서, Δ를 치환해보면:
x1=x0−f′(x)f(x)
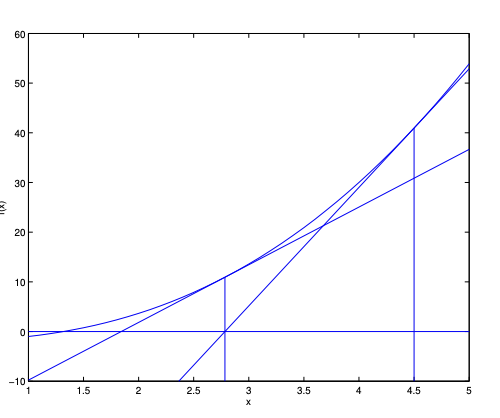
가 성립합니다. 다음 스텝을 통해 이해해봅시다:
우리가 구하고자 하는 x는 θ이며, 목표 함수인 f(x)은 ℓ′(θ)와 같습니다. ℓ의 미분값은 maxima에 근접할 수록 0이 되는 양상을 보이고, 최고값은 ℓ′(θ)=0인 곳에 있습니다.
그렇기에 ℓ′(θ)를 사용합니다. 아래를 Newton's method, 또는 Newton-Raphson method라고 부릅니다.
θ:=θ−ℓ′′(θ)ℓ′(θ)
마지막으로, 우리의 로지스틱 회귀에서는 θ는 벡터 값이기 때문에, 우리는 뉴턴 함수의 일반화가 필요합니다. 여러 차원에서의 설정을 해봅시다.
θ:=θ−H−1∇θℓ(θ)
여기서 Hij는 Hessian이라는 Rd+1×d+1 (intercept term 포함) 차원의 행렬입니다.
아래와 같이 정의되지만, 이게 정확히 어떤 역할을 하는지는 이해하지 않아도 괜찮습니다.
Hij=∂θi∂θj∂2ℓ(θ)
하지만, 더 중요한 점은 저희가 d (입력 특성 수)가 커질수록, Hessian 행렬을 구하기 위해 계산 비용이 제곱으로 증가합니다.
일반적인 경우에서는 Newton's Method가 훨씬 더 빠르지만, d가 너무 커질 경우, 우리는 돌아가 gradient ascent를 사용하는 것을 고려할 필요가 있습니다.
마치며
이번 글에서는 로지스틱 회귀 +α 를 배워보았습니다. 선형 회귀가 연속적인 변수를 예측하는데 사용된다면, 로지스틱 회귀는 이산적인 변수를 예측하는데 사용됩니다. 이 둘은 굉장히 유사한 경사 하강/상승법을 가지고 있는데, 이 점을 바로 다음 시간에 Generalized linear model로 하나로 아우를 수 있습니다. 선형 회귀와 로지스틱 회귀의 융합, 기대되지 않나요?