다룰 내용들
Linear regression
LMS algrithm
Normal equation
Probabilistic interpretation
Locally weighted linear regression
Introduction
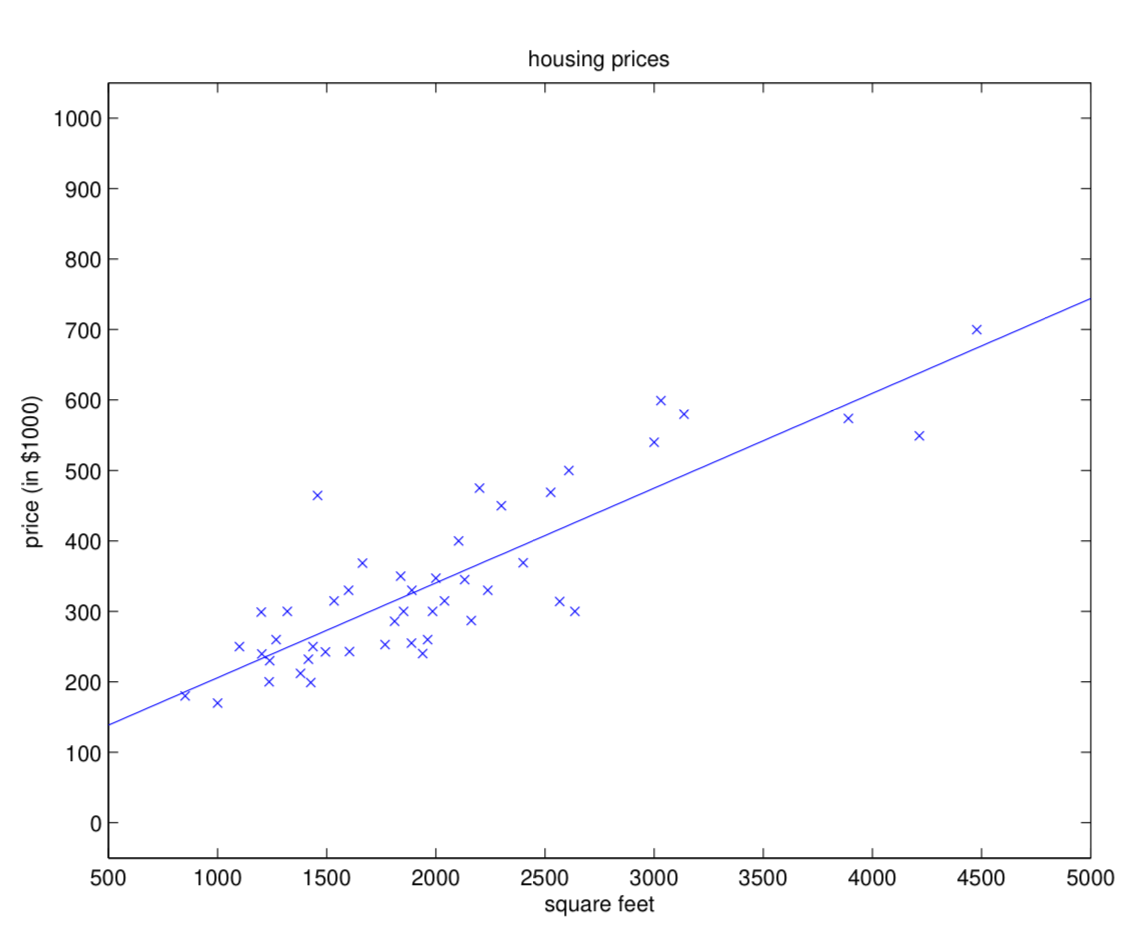
Linear regression (선형회귀)는 데이터가 산개되어 있을 때, 그 데이터를 잘 예측하는 선을 그려보자는 아이디어입니다.
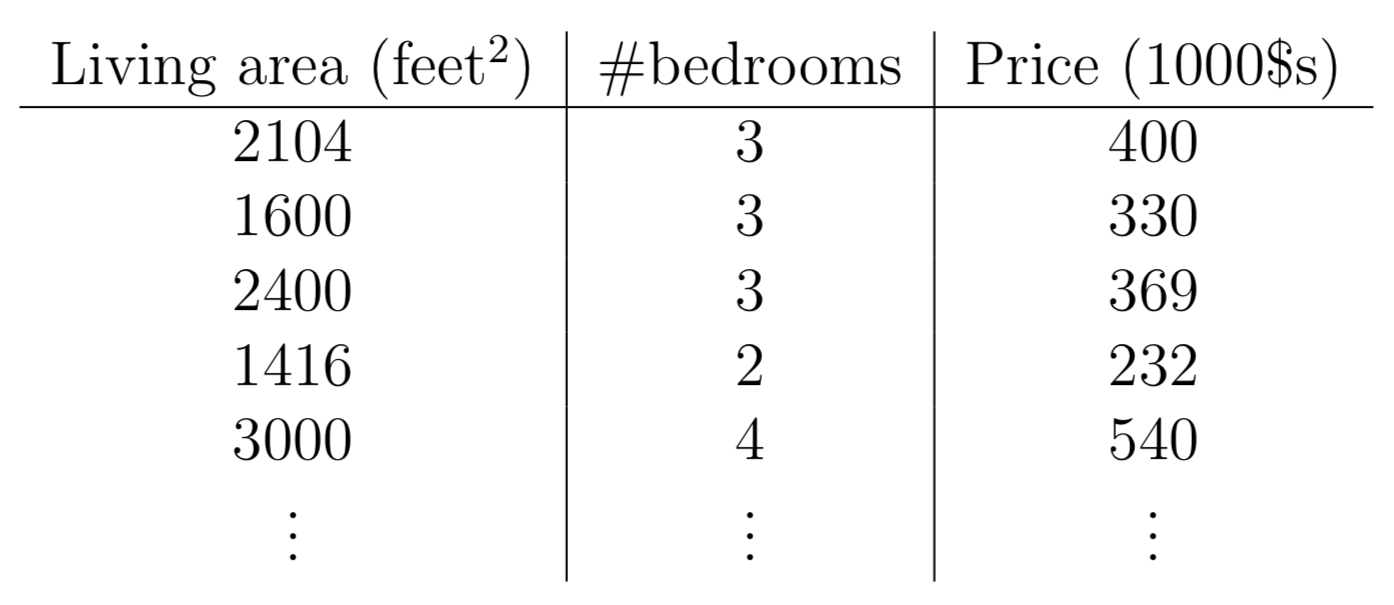
위와 같은 주거 데이터가 주어질 때, 저희가 Living area (x 1 ( i ) x_1^{(i)} x 1 ( i ) # bedrooms (x 2 ( i ) x_2^{(i)} x 2 ( i ) Price 를 예측해보고 싶다고 합시다.
즉, 집의 크기와 침실의 수가 입력되면, 집의 가격이 띡 나오는 식을 작성하고 싶다는 것이고, 우리는 이 식을 가설 h h h 라고 합니다. 그러면, x x x
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 h_\theta(x) = \theta_0 + \theta_1x_1 + \theta_2x_2 h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 θ j \theta_j θ j X \mathcal{X} X Y \mathcal{Y} Y θ 0 \theta_0 θ 0 bias 입니다.
이를 matrix form 으로 바꿔봅시다:
h ( x ) = ∑ i = 0 d θ i x i = θ T x , θ = [ θ 0 θ 1 ⋮ θ d ] , x = [ x 0 x 1 ⋮ x d ] , where x 0 = 1. h(x) = \sum_{i=0}^d \theta_ix_i = \theta^Tx, \\ \theta =\begin{bmatrix} \theta_0 \\ \theta_1 \\ \vdots \\ \theta_d\end{bmatrix}, x =\begin{bmatrix} x_0 \\ x_1 \\ \vdots \\ x_d\end{bmatrix}, \text{where } x_0 = 1. h ( x ) = i = 0 ∑ d θ i x i = θ T x , θ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ θ 0 θ 1 ⋮ θ d ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ , x = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ x 0 x 1 ⋮ x d ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ , where x 0 = 1 . 우리의 목표는 이 h θ ( x ( i ) ) h_\theta(x^{(i)}) h θ ( x ( i ) ) y ( i ) y^{(i)} y ( i ) cost function 은 아래와 같이 정의됩니다:
J ( θ ) = 1 2 ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2}\sum_{i=1}^{n}(h_\theta(x^{(i)})-y^{(i)})^2 J ( θ ) = 2 1 i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) 2
⚠️ 강의에서는 n이 m으로 치환되어서 사용되었으나 Ng 교수님의 갈대 같은 마음에 lecture note의 term은 반대가 되었습니다. 혼동되지 맙시다!
또한, h ( x ) h(x) h ( x ) h θ ( x ) h_\theta(x) h θ ( x )
이를 LMS (least mean sqaures)이라고 정의합니다.
아무튼, 저희는 이 cost function을 사용해서 ordinary least squares regression model 로 정의가 가능합니다.
1.1) LMS algorithm
저희의 목표는 x x x y y y θ j \theta_j θ j J ( θ ) J(\theta) J ( θ ) gradient descent (경사하강법) 을 사용할 수 있습니다:
θ j : = θ j − α ∂ ∂ θ j J ( θ ) \theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j}J(\theta) θ j : = θ j − α ∂ θ j ∂ J ( θ ) θ j \theta_j θ j α \alpha α
gradient를 구해봅시다:
∂ ∂ θ j J ( θ ) = ∂ ∂ θ j 1 2 ( h θ ( x ) − y ) 2 = 2 ⋅ 1 2 ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( h θ ( x ) − y ) = ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( ∑ i = 0 d θ i x i − y ) = ( h θ ( x ) − y ) x j \begin{aligned} \frac{\partial}{\partial \theta_j}J(\theta) &= \frac{\partial}{\partial \theta_j} \frac{1}{2} (h_\theta(x) - y)^2 \\ &= 2 \cdot \frac{1}{2}(h_\theta(x)-y) \cdot \frac{\partial}{\partial \theta_j}(h_\theta(x)-y) \\ &= (h_\theta(x)-y) \cdot \frac{\partial}{\partial \theta_j} \left( \sum_{i=0}^{d} \theta_ix_i - y\right) \\ &= (h_\theta(x)-y)x_j \end{aligned} ∂ θ j ∂ J ( θ ) = ∂ θ j ∂ 2 1 ( h θ ( x ) − y ) 2 = 2 ⋅ 2 1 ( h θ ( x ) − y ) ⋅ ∂ θ j ∂ ( h θ ( x ) − y ) = ( h θ ( x ) − y ) ⋅ ∂ θ j ∂ ( i = 0 ∑ d θ i x i − y ) = ( h θ ( x ) − y ) x j 이를 통해 LMS algorithm을 작성할 수 있습니다.
Repeat until convergence { \text{Repeat until convergence \{} Repeat until convergence {
θ j : = θ j − α ∑ i = 1 n ( y ( i ) − h θ ( x ( i ) ) ) x j ( i ) , ( for every j ) \text{} \\ \theta_j := \theta_j - \alpha \sum_{i=1}^{n}(y^{(i)}-h_\theta(x^{(i)}))x_j^{(i)},(\text{for every } j) θ j : = θ j − α i = 1 ∑ n ( y ( i ) − h θ ( x ( i ) ) ) x j ( i ) , ( for every j ) } \} }
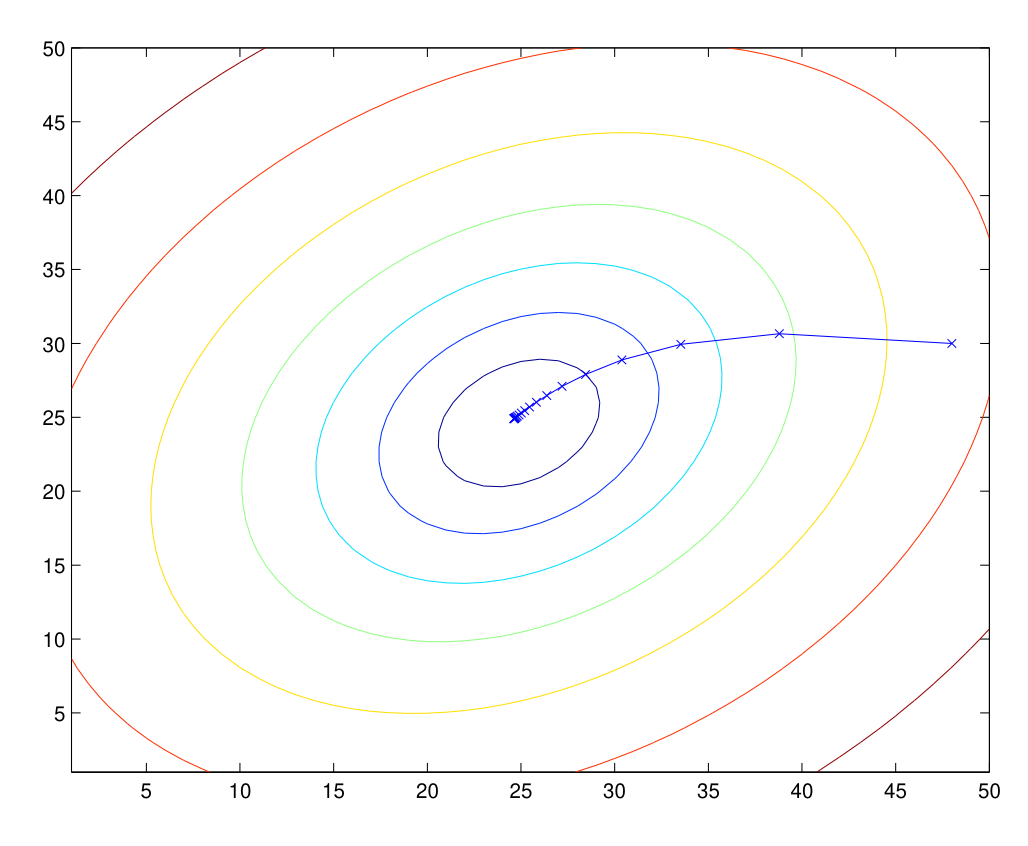
θ : = θ − α ∑ i = 1 n ( y ( i ) − h θ ( x ( i ) ) ) x ( i ) \theta := \theta - \alpha \sum_{i=1}^{n}(y^{(i)}-h_\theta(x^{(i)}))x^{(i)} θ : = θ − α i = 1 ∑ n ( y ( i ) − h θ ( x ( i ) ) ) x ( i ) 이를 batch gradient descent 라고 하며, 한번의 경사 업데이트를 위해 모든 데이터가 사용된다는 것이 특징입니다.
J ( θ ) J(\theta) J ( θ ) convex parabolic function 인데, 그렇기에 언제나 local minima가 global minima 임이 성립합니다. LMS를 사용하는 Linear Regression 문제는, 우리가 잘 구해둔 gradient는 언제나 global minima로의 수렴으로 이어진다는 좋은 뜻이 됩니다.
우리가 각 step마다 구한 gradient는 x 기호로 표시됩니다.θ \theta θ
다 좋은데, 문제는 하나의 업데이트, step을 밟기 위해서 모든 데이터셋이 필요하다는 점입니다. 만약에 데이터가 아주아주 많을 경우, 골치 아파지겠죠. 이를 해결하기 위해, 데이터셋 안의 데이터 하나 하나마다 업데이트를 해주는 stochastic gradient descent 가 있습니다.
Loop { \text{Loop \{} Loop { for i =1 to n { \qquad\text{for i =1 to n \{} for i =1 to n {
θ : = θ − α ∑ i = 1 n ( y ( i ) − h θ ( x ( i ) ) ) x ( i ) , ( for every j ) \text{} \\ \theta := \theta - \alpha \sum_{i=1}^{n}(y^{(i)}-h_\theta(x^{(i)}))x^{(i)},(\text{for every } j) θ : = θ − α i = 1 ∑ n ( y ( i ) − h θ ( x ( i ) ) ) x ( i ) , ( for every j ) } \qquad\} } } \} }
한번의 업데이트마다 한 데이터를 바라보고 fit하기 때문에, 어쩌면 영영 최고의 값에 도달하지 못할 수도 있습니다. step마다 learning rate를 줄여서 minimum에 근사하도록 함으로 문제를 해결할 수 있습니다.
1.2) The normal equations
iterative algorithm이 아닌, 행렬의 곱으로 나타내어서 한번에 딱! 식을 계산해봅시다. 이를 normal equation이라고 합니다.
1.2.1) Matrix derivatives
기존의 gradient는 다음과 같이 표현 해봅시다:
∇ θ J ( θ ) ( i ) = [ ∂ J ( i ) ∂ θ 1 ∂ J ( i ) ∂ θ 2 ⋮ ] \nabla_\theta J(\theta)^{(i)} = \begin{bmatrix} \frac{\partial J^{(i)}}{\partial \theta_1} \\ \frac{\partial J^{(i)}}{\partial \theta_2} \\ \vdots \end{bmatrix} ∇ θ J ( θ ) ( i ) = ⎣ ⎢ ⎢ ⎢ ⎡ ∂ θ 1 ∂ J ( i ) ∂ θ 2 ∂ J ( i ) ⋮ ⎦ ⎥ ⎥ ⎥ ⎤ ∂ J ( i ) ∂ θ j \frac{\partial J^{(i)}}{\partial \theta_j} \\ ∂ θ j ∂ J ( i )
함수 f : R n × d ↦ R f : \mathbb{R}^{n \times d} \mapsto \mathbb{R} f : R n × d ↦ R n × n n \times n n × n A A A
∇ A f ( A ) = [ ∂ f ∂ A 11 ⋯ ⋯ ∂ f ∂ A 1 d ⋮ ⋱ ⋮ ⋮ ⋱ ⋮ ∂ f ∂ A n 1 ⋯ ⋯ ∂ f ∂ A n d ] \nabla_A f(A) = \left[ \begin{array}{cccc} \frac{\partial f}{\partial A_{11}} & \cdots & \cdots & \frac{\partial f}{\partial A_{1d}} \\ \vdots & \ddots & & \vdots \\ \vdots & & \ddots & \vdots \\ \frac{\partial f}{\partial A_{n1}} & \cdots & \cdots & \frac{\partial f}{\partial A_{nd}} \\ \end{array} \right] ∇ A f ( A ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ ∂ A 1 1 ∂ f ⋮ ⋮ ∂ A n 1 ∂ f ⋯ ⋱ ⋯ ⋯ ⋱ ⋯ ∂ A 1 d ∂ f ⋮ ⋮ ∂ A n d ∂ f ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ 만약에 f ( A ) = 3 2 A 11 + 5 A 12 2 + A 21 A 22 f(A) = \frac{3}{2}A_{11}+5A_{12}^2+A_{21}A_{22} f ( A ) = 2 3 A 1 1 + 5 A 1 2 2 + A 2 1 A 2 2
∇ A f ( A ) = [ 3 2 10 A 12 A 22 A 21 ] \nabla_A f(A) = \left[ \begin{array}{cc} \tfrac{3}{2} & 10A_{12} \\ A_{22} & A_{21} \end{array} \right] ∇ A f ( A ) = [ 2 3 A 2 2 1 0 A 1 2 A 2 1 ] 1.2.2) Least squares revisited
design matrix X X X
X = [ — ( x ( 1 ) ) T — — ( x ( 2 ) ) T — ⋮ — ( x ( n ) ) T — ] X = \begin{bmatrix} — (x^{(1)})^T — \\ — (x^{(2)})^T — \\ \vdots \\ — (x^{(n)})^T — \end{bmatrix} X = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ — ( x ( 1 ) ) T — — ( x ( 2 ) ) T — ⋮ — ( x ( n ) ) T — ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ R n × d + 1 \mathbb{R}^{n \times d+1} R n × d + 1
또한, y ⃗ \vec{y} y n n n
y ⃗ = [ y ( 1 ) y ( 2 ) ⋮ y ( n ) ] \vec{y} = \begin{bmatrix} y^{(1)} \\ y^{(2)} \\ \vdots \\ y^{(n)} \end{bmatrix} y = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ y ( 1 ) y ( 2 ) ⋮ y ( n ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ 이제, h θ ( x ( i ) ) = ( x ( i ) ) T θ h_\theta(x^{(i)}) = (x^{(i)})^T \theta h θ ( x ( i ) ) = ( x ( i ) ) T θ
X θ − y ⃗ = [ ( x ( 1 ) ) T θ ⋮ ( x ( n ) ) T θ ] − [ y ( 1 ) ⋮ y ( n ) ] = [ h θ ( x ( 1 ) ) − y ( 1 ) ⋮ h θ ( x ( n ) ) − y ( n ) ] X\theta - \vec{y} = \begin{bmatrix} (x^{(1)})^T \theta \\ \vdots \\ (x^{(n)})^T \theta \end{bmatrix} - \begin{bmatrix} y^{(1)} \\ \vdots \\ y^{(n)} \end{bmatrix} = \begin{bmatrix} h_\theta(x^{(1)}) - y^{(1)} \\ \vdots \\ h_\theta(x^{(n)}) - y^{(n)} \end{bmatrix} X θ − y = ⎣ ⎢ ⎢ ⎡ ( x ( 1 ) ) T θ ⋮ ( x ( n ) ) T θ ⎦ ⎥ ⎥ ⎤ − ⎣ ⎢ ⎢ ⎡ y ( 1 ) ⋮ y ( n ) ⎦ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎡ h θ ( x ( 1 ) ) − y ( 1 ) ⋮ h θ ( x ( n ) ) − y ( n ) ⎦ ⎥ ⎥ ⎤ 따라서 벡터 z z z z T z = ∑ i z i 2 z^T z = \sum_i z_i^2 z T z = ∑ i z i 2
1 2 ( X θ − y ⃗ ) T ( X θ − y ⃗ ) = 1 2 ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) 2 = J ( θ ) \frac{1}{2}(X\theta - \vec{y})^T(X\theta - \vec{y}) = \frac{1}{2} \sum_{i=1}^{n} (h_\theta(x^{(i)}) - y^{(i)})^2 = J(\theta) 2 1 ( X θ − y ) T ( X θ − y ) = 2 1 i = 1 ∑ n ( h θ ( x ( i ) ) − y ( i ) ) 2 = J ( θ ) 전개해봅시다.
∇ θ J ( θ ) = ∇ θ 1 2 ( X θ − y ⃗ ) T ( X θ − y ⃗ ) = 1 2 ∇ θ ( ( X θ ) T X θ − ( X θ ) T y ⃗ − y ⃗ T ( X θ ) + y ⃗ T y ⃗ ) = 1 2 ∇ θ ( θ T X T X θ − y ⃗ T X θ − ( X θ ) T y ⃗ ) = 1 2 ∇ θ ( θ T X T X θ − 2 y ⃗ T X θ ) = 1 2 ( 2 X T X θ − 2 X T y ⃗ ) = X T X θ − X T y ⃗ \begin{aligned} \nabla_\theta J(\theta) &= \nabla_\theta \frac{1}{2}(X\theta - \vec{y})^T(X\theta - \vec{y}) \\ &= \frac{1}{2} \nabla_\theta \left( (X\theta)^T X\theta - (X\theta)^T \vec{y} - \vec{y}^T (X\theta) + \vec{y}^T \vec{y} \right) \\ &= \frac{1}{2} \nabla_\theta \left( \theta^T X^T X \theta - \vec{y}^T X\theta - (X\theta)^T \vec{y} \right) \\ &= \frac{1}{2} \nabla_\theta \left( \theta^T X^T X \theta - 2 \vec{y}^T X \theta \right) \\ &= \frac{1}{2} \left( 2 X^T X \theta - 2 X^T \vec{y} \right) \\ &= X^T X \theta - X^T \vec{y} \end{aligned} ∇ θ J ( θ ) = ∇ θ 2 1 ( X θ − y ) T ( X θ − y ) = 2 1 ∇ θ ( ( X θ ) T X θ − ( X θ ) T y − y T ( X θ ) + y T y ) = 2 1 ∇ θ ( θ T X T X θ − y T X θ − ( X θ ) T y ) = 2 1 ∇ θ ( θ T X T X θ − 2 y T X θ ) = 2 1 ( 2 X T X θ − 2 X T y ) = X T X θ − X T y 증명 중에 어려운 부분이 있다면, LLM을 사용해서 뜯어보시길 추천드립니다. (다 설명하기엔 너무 많아요!)
J J J normal equation 을 구할 수 있겠죠:
X T X θ = X T y X^TX\theta = X^Ty X T X θ = X T y 이를 사용해서, J ( θ ) J(\theta) J ( θ ) θ \theta θ
θ = ( X T X ) − 1 X T y ⃗ \theta = (X^TX)^{-1}X^T\vec{y} θ = ( X T X ) − 1 X T y 1.3) Probabilistic interpretation
이 섹션은 우리가 왜 squared error를 사용해야 하는지에 대한 답을 제시합니다.
우리가 데이터를 θ T x ( i ) \theta^Tx^{(i)} θ T x ( i ) ϵ ( i ) \epsilon^{(i)} ϵ ( i )
y ( i ) = θ T x ( i ) + ϵ ( i ) y^{(i)}=\theta^Tx^{(i)}+\epsilon^{(i)} y ( i ) = θ T x ( i ) + ϵ ( i ) 여기서 ϵ ( i ) \epsilon^{(i)} ϵ ( i ) N ( 0 , σ 2 ) \mathcal{N}(0,\sigma^2) N ( 0 , σ 2 ) ϵ ( i ) \epsilon^{(i)} ϵ ( i )
p ( ϵ ( i ) ) = 1 2 π σ exp ( − ( ϵ ( i ) ) 2 2 σ 2 ) p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left( - \frac{(\epsilon^{(i)})^2}{2\sigma^2} \right) p ( ϵ ( i ) ) = 2 π σ 1 exp ( − 2 σ 2 ( ϵ ( i ) ) 2 ) 이는 다음을 의미합니다:
p ( y ( i ) ∣ x ( i ) ; θ ) = 1 2 π σ exp ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) p(y^{(i)} | x^{(i)}; \theta) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left( - \frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2} \right) p ( y ( i ) ∣ x ( i ) ; θ ) = 2 π σ 1 exp ( − 2 σ 2 ( y ( i ) − θ T x ( i ) ) 2 ) 표기 p ( y ( i ) ∣ x ( i ) ; θ ) p(y^{(i)} | x^{(i)}; \theta) p ( y ( i ) ∣ x ( i ) ; θ ) x ( i ) x^{(i)} x ( i ) y ( i ) y^{(i)} y ( i ) θ \theta θ θ \theta θ p ( y ( i ) ∣ x ( i ) , θ ) p(y^{(i)} | x^{(i)}, \theta) p ( y ( i ) ∣ x ( i ) , θ ) θ \theta θ
또한, y ( i ) y^{(i)} y ( i )
y ( i ) ∼ N ( θ T x ( i ) , σ 2 ) y^{(i)} \sim \mathcal{N}(\theta^T x^{(i)}, \sigma^2) y ( i ) ∼ N ( θ T x ( i ) , σ 2 ) X X X x ( i ) x^{(i)} x ( i ) θ \theta θ y ( i ) y^{(i)} y ( i )
데이터의 확률은 다음과 같이 표현됩니다:
p ( y ⃗ ∣ X ; θ ) p(\vec{y} | X; \theta) p ( y ∣ X ; θ ) 이 값은 보통 y ⃗ \vec{y} y X X X θ \theta θ 우도 함수(likelihood function) 라고 부릅니다:
L ( θ ) = L ( θ ; X , y ⃗ ) = p ( y ⃗ ∣ X ; θ ) L(\theta) = L(\theta; X, \vec{y}) = p(\vec{y} | X; \theta) L ( θ ) = L ( θ ; X , y ) = p ( y ∣ X ; θ ) 각 ϵ ( i ) \epsilon^{(i)} ϵ ( i )
L ( θ ) = ∏ i = 1 n p ( y ( i ) ∣ x ( i ) ; θ ) = ∏ i = 1 n 1 2 π σ exp ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) \begin{aligned} L(\theta) &= \prod_{i=1}^{n} p(y^{(i)} | x^{(i)}; \theta) \\ &= \prod_{i=1}^{n} \frac{1}{\sqrt{2\pi}\sigma} \exp\left( - \frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2} \right) \end{aligned} L ( θ ) = i = 1 ∏ n p ( y ( i ) ∣ x ( i ) ; θ ) = i = 1 ∏ n 2 π σ 1 exp ( − 2 σ 2 ( y ( i ) − θ T x ( i ) ) 2 ) 이제 이 확률 모델을 바탕으로 y ( i ) y^{(i)} y ( i ) x ( i ) x^{(i)} x ( i ) θ \theta θ
최대우도 추정법(Maximum Likelihood Estimation, MLE) 의 핵심 원리는 데이터를 생성할 확률이 최대가 되도록 θ \theta θ
즉, 우리는 L ( θ ) L(\theta) L ( θ ) θ \theta θ L ( θ ) L(\theta) L ( θ ) log likelihood ℓ ( θ ) \ell(\theta) ℓ ( θ )
ℓ ( θ ) = log L ( θ ) = log ∏ i = 1 n 1 2 π σ exp ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) = ∑ i = 1 n log ( 1 2 π σ exp ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) ) = n log 1 2 π σ − 1 σ 2 ⋅ 1 2 ∑ i = 1 n ( y ( i ) − θ T x ( i ) ) 2 \ell(\theta) = \log L(\theta) \\ = \log \prod_{i=1}^{n} \frac{1}{\sqrt{2\pi} \sigma} \exp\left( - \frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2} \right) \\ = \sum_{i=1}^{n} \log \left( \frac{1}{\sqrt{2\pi} \sigma} \exp\left( - \frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2} \right) \right) \\ = n \log \frac{1}{\sqrt{2\pi} \sigma} - \frac{1}{\sigma^2} \cdot \frac{1}{2} \sum_{i=1}^{n} (y^{(i)} - \theta^T x^{(i)})^2 ℓ ( θ ) = log L ( θ ) = log i = 1 ∏ n 2 π σ 1 exp ( − 2 σ 2 ( y ( i ) − θ T x ( i ) ) 2 ) = i = 1 ∑ n log ( 2 π σ 1 exp ( − 2 σ 2 ( y ( i ) − θ T x ( i ) ) 2 ) ) = n log 2 π σ 1 − σ 2 1 ⋅ 2 1 i = 1 ∑ n ( y ( i ) − θ T x ( i ) ) 2 따라서, ℓ ( θ ) \ell(\theta) ℓ ( θ )
1 2 ∑ i = 1 n ( y ( i ) − θ T x ( i ) ) 2 \frac{1}{2} \sum_{i=1}^{n} (y^{(i)} - \theta^T x^{(i)})^2 2 1 i = 1 ∑ n ( y ( i ) − θ T x ( i ) ) 2 이 값은 우리가 알고 있는 원래의 최소제곱 비용 함수 J ( θ ) J(\theta) J ( θ ) ϵ ( i ) \epsilon^{(i)} ϵ ( i ) θ \theta θ σ 2 \sigma^2 σ 2 σ 2 \sigma^2 σ 2
1.4) Locally weighted linear regression (optional reading)
기존 linear regression이 parametric learning 이라고 불렸다면, LWR (Locally weighted linear regression)은 non-parametric learning이라고 불립니다. 이 차이는 파라미터의 숫자가 고정인지, 아니면 데이터의 크기에 따라 달라지는지에 따라 나뉘는데, 후자인 LWR은 데이터의 크기에 따라 파라미터의 숫자가 변하고, 그렇기에 non-parametric learning이라고 불립니다.
LWR은 x ( i ) x^{(i)} x ( i ) x x x θ \theta θ θ T x \theta^Tx θ T x
선형 회귀 모델:
∑ i ( y ( i ) − θ T x ( i ) ) 2 \sum_i(y^{(i)}-\theta^Tx^{(i)})^2 ∑ i ( y ( i ) − θ T x ( i ) ) 2 θ \theta θ θ T x \theta^Tx θ T x
LWR
∑ i w ( i ) ( y ( i ) − θ T x ( i ) ) 2 \sum_iw^{(i)}(y^{(i)}-\theta^Tx^{(i)})^2 ∑ i w ( i ) ( y ( i ) − θ T x ( i ) ) 2 θ \theta θ θ T x \theta^Tx θ T x
여기서 w ( i ) w^{(i)} w ( i ) x x x τ \tau τ w ( i ) w^{(i)} w ( i )
w ( i ) = exp ( − ( x ( i ) − x ) 2 2 τ 2 ) w^{(i)} = \exp \left( -\frac{(x^{(i)}-x)^2}{2\tau^2} \right) w ( i ) = exp ( − 2 τ 2 ( x ( i ) − x ) 2 ) 마치며
이번 글에서는 Linear regression과 이를 최적화하는 다양한 방법을 알아봤습니다.
궁금하신 점은 언제나 환영입니다.