가장 일반적인 지도학습 task 중에는 회귀(값 예측)와 분류(클래스 예측)가 있다. 이번 장에서는 분류 시스템을 집중적으로 다루겠다.
Binary Classifier 예시
사이킷런의 SGDClassifier 클래스를 사용해서 SGD(Stochastic Gradient Descent) 분류기로 시작해보자. (이 분류기는 매우 큰 데이터셋을 효율적으로 처리할 수 있는 장점을 지님.)
🔹모델 성능 평가
1) 교차 검증 --> 정확도 측정
- 어떤 클래스가 다른 것보다 월등히 많은 경우와 같이 '불균형한 데이터셋'을 다룰 때 정확도는 평가 지표로 지양된다.
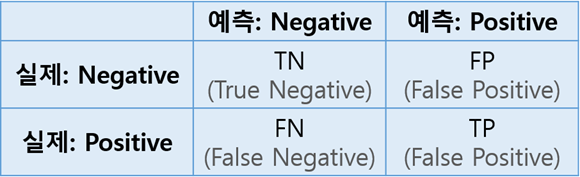
2) 오차 행렬 (Confusion Matrix)
- 클래스 A의 샘플이 클래스 B로 잘못 분류된 횟수 세기
- 정밀도_Precision (재현율_Recall 과 같이 사용하는 것이 일반적)

- 상황에 따라서 정밀도와 재현율의 각 중요도가 달라질 수 있다.
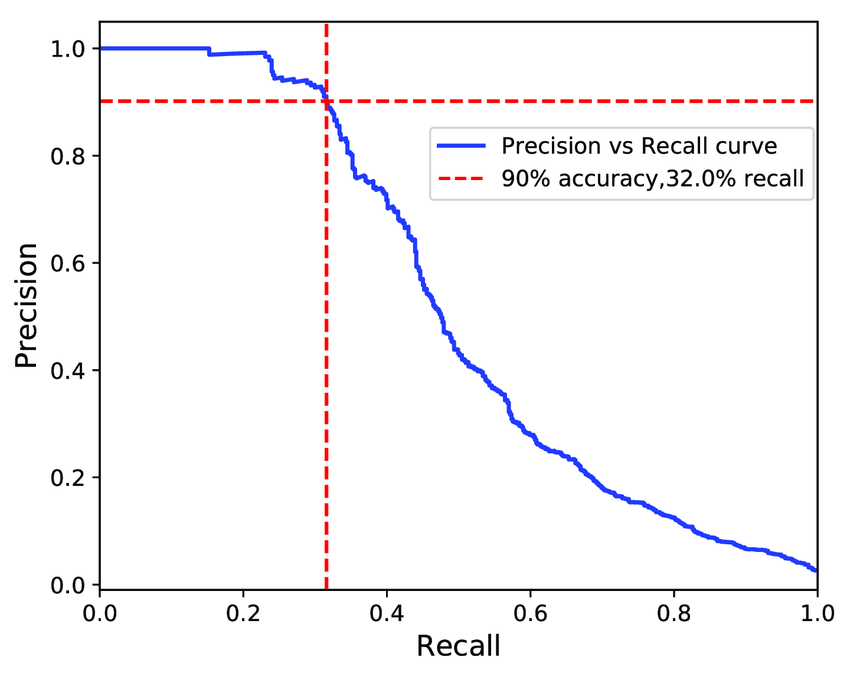
- 정밀도/재현율 Tradeoff 발생
- 아래 그림에서 재현율(Recall) 0.3 지점에서 정밀도가 급격하게 줄어들기 시작한다. 이 하강점 직전을 정밀도/재현율 Tradeoff로 선택하는 것이 좋다.
🔹ROC 곡선 (Receiver Operating Characteristic)
-
False positive rate(FPR)에 대한 True positive rate(TPR)의 곡선
-
재현율(민감도)에 대한 (1 - 특이도) 그래프
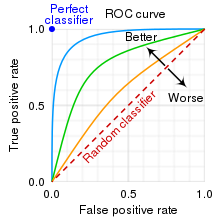
- 재현율(TPR)이 높을수록 분류기가 만드는 거짓 양성(FPR)이 증가.
- 곡선 아래 면적(AUC)을 측정하면 분류기를 비교할 수 있다. (완벽한 분류기=1, 완전 랜덤 분류기=0.5)
다중 분류 (Multiclass classifier)
: 둘 이상의 클래스를 직접 처리할 수 있는 알고리즘도 있지만, 이진 분류만 가능한 알고리즘의 경우, 이진 분류기를 여러 개 사용해 다중 클래스를 분류하는 기법도 많다. (OvR 전략(one-versus-the rest), OvO 전략(one-versus-one))
OvR 전략 : ex) 특정 숫자 하나만 구분하는 숫자별 이진 분류기 10개를 훈련시켜서, 클래스가 10개인 숫자 이미지 분류 시스템을 만들 수 있다. 이미지 분류 시, 각 분류기의 결정 점수 중 가장 높은 것을 클래스로 선택.
OvO 전략: ex) 0과 1, 0과 2, 1과 2 구별 등과 같이 각 숫자의 조합마다 이진 분류기를 훈련시키는 것. --- 클래스가 N개 라면, 분류기는 N*(N-1)/2 개가 필요하다. [이 전략의 주요 장점: 각 분류기 훈련에 전체 훈련 세트 중 구별하고자 하는 두 클래스에 해당하는 샘플만 필요로 함.]
대부분의 이진 분류 알고리즘에서는 OvR을 선호하지만, SVM 같은 일부 알고리즘은 훈련 세트의 크기에 민감해서 작은 훈련 세트에서 많은 분류기를 훈련시키는 쪽이 빠르므로 OvO를 선호한다.
