- single core CPU를 여러 개 사용하는 multiprocessor 방식에 한계가 있어
multi-core CPU를 사용하는 multicore processor 방식이 등장하였다. - single application을 실행하는데 있어서 CPU의 core의 개수는 중요하지 않다.
single core로만 실행할 수 있기 때문이다.
그래서 single application을 threads를 사용해 rewrite하여 parallel하게 실행되도록 하였다.
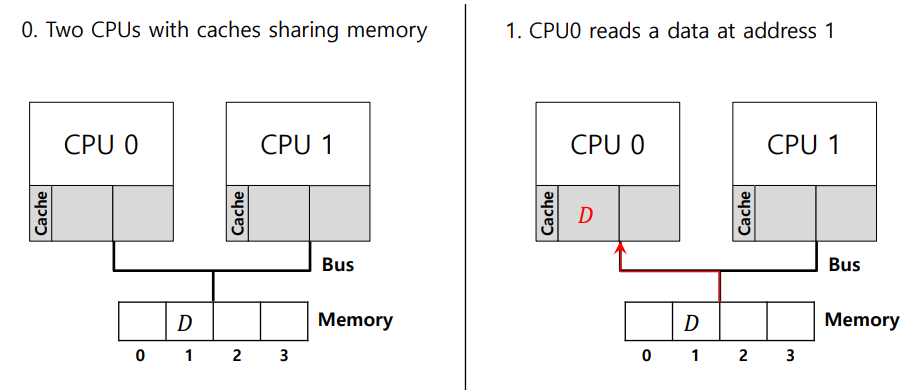
Single CPU with cache

cache는 느린 memory가 빠르게 느껴지도록 해준다. cache는 눈에 안 보이기 때문이다.
Cache coherence
- cache에서의 data consistency 문제이다.
data를 write할 때 write back 방식과 write through 방식이 있다.
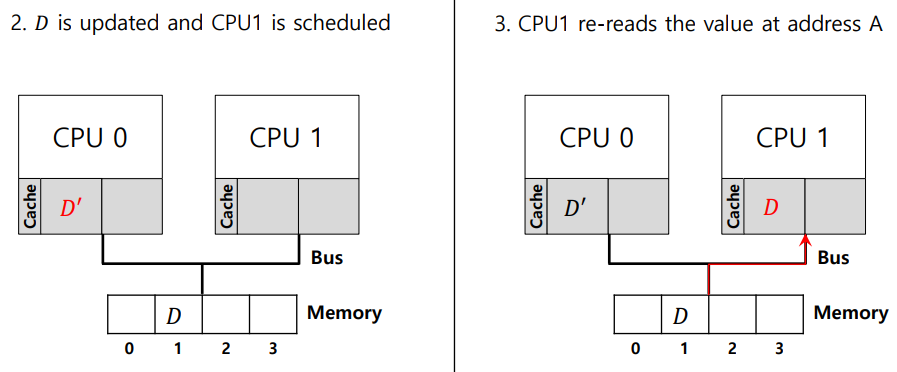
아래 그림은 write back 방식에서의 cache coherence 문제이다.
Bus Snooping
Write-through 방식에서 cache coherence 문제의 해결 방법이다.
Bus를 계속 주시하고 있다가 data를 write하면
1. 다른 cache에 있는 값들도 update하거나
2. 다른 cache에 있는 값들을 invalidate한다.
Don't forget synchronization
2개의 CPU A,B에서 실행할 process를 Ready queue에서 꺼내기 위해
List_Pop() 함수를 실행한다고 생각해보자
1 typedef struct __Node_t {
2 int value;
3 struct __Node_t *next;
4 } Node_t;
5
6 int List_Pop() {
7 Node_t *tmp = head; // remember old head ...
8 int value = head->value; // ... and its value
9 head = head->next; // advance head to next pointer
10 free(tmp); // free old head
11 return value; // return value at head
12 }위의 코드에서 문제는 CPU A에서 free(tmp)를 하고나서 CPU B에서 free(tmp) 문장을 실행하면
이미 free로 해제된 메모리를 다시 해제하는 문제가 발생한다는 것이다.
1 pthread_mtuex_t m;
2 typedef struct __Node_t {
3 int value;
4 struct __Node_t *next;
5 } Node_t;
6
7 int List_Pop() {
8 lock(&m)
9 Node_t *tmp = head; // remember old head ...
10 int value = head->value; // ... and its value
11 head = head->next; // advance head to next pointer
12 free(tmp); // free old head
13 unlock(&m)
14 return value; // return value at head
15 }해결 방법은 위와 같이 lock(&m), unlock(&m)을 추가하는 것이다.
CPU A에서 List_Pop()을 실행하면 나머지 CPU는 대기 상태가 되며 CPU A에서 return을 해야 다음 CPU에서 List_Pop()을 실행할 수 있다. 즉 여러 개의 core/cpu가 동시 실행이 불가능한 것이다.
line 9~12를 critical section이라고 부른다.
Cache Affinity
- Keep a process on the same CPU if at all possible
같은 CPU에서 process가 계속 실행된다면 cache에 원하는 data가 많이 저장되어 있어서 빠르다. - A multiprocessor scheduler should consider cache affinity when making its scheduling decision.
Single queue Multiprocessor Scheduling (SQMS)
- processor는 여러 개지만 ready queue는 1개이다.
- 구현이 쉽지만 앞서 List_Pop() 처럼 동기화 문제가 발생하고 1개의 cpu(core)를 제외한 나머지 cpu(core)는 낭비되는 문제가 발생한다 -> lack of scalability
- cache affinity는 있을 수도 있고 없을 수도 있다
- Example:
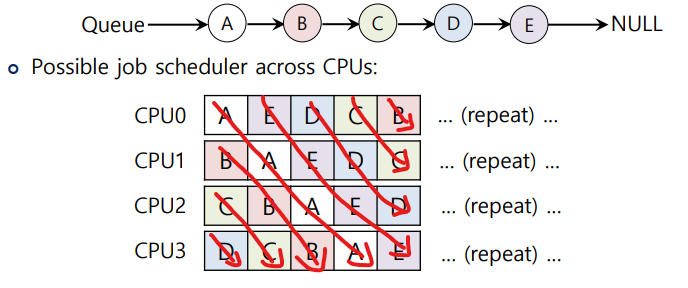
위와 같이 CPU는 4개이고 process는 5개인 경우 cache affinity가 충족되지 못한다.
Scheduling example with cache affinity
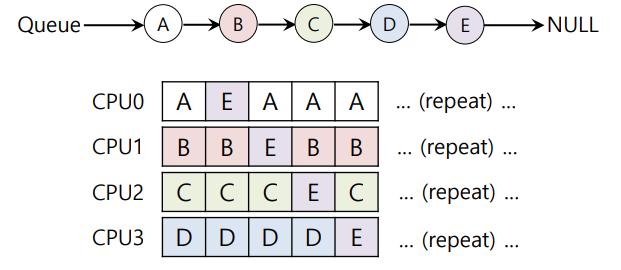
같은 예제에서 A,B,C,D는 각각 같은 CPU에서 실행되게 하고 E는 4개의 CPU에서 번갈아가면서 실행되게 만들어 cache affinity를 충족하게 만들 수 있다.
그러나 cache affinity를 보장하는 것은 구현이 어렵고 복잡하다.
Multi-queue Multiprocessor Scheduling (MQMS)
- processor가 자신만의 ready queue를 가진다.
동기화의 문제를 해결할 수 있다.
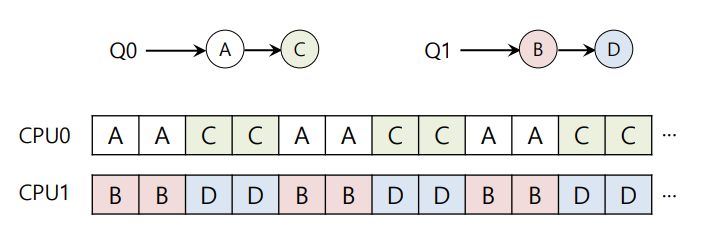
SQMS보다 cache affinity와 높은 scalability를 제공한다.
Load imbalance issue of MQMS
Q0에서 C가 끝난 상황
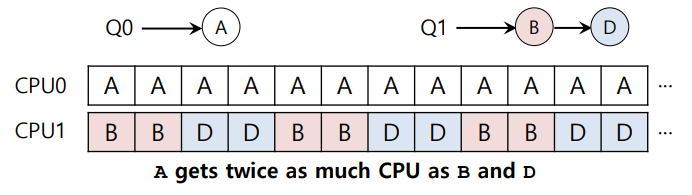
Q0에서 A도 끝난 상황
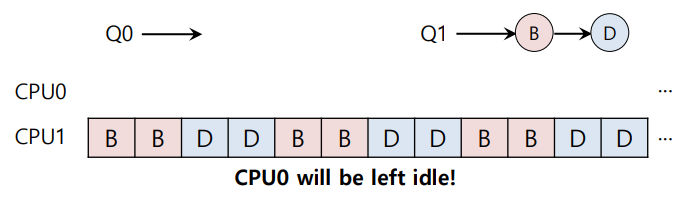
위와 같이 각 큐에 존재하는 job의 개수가 imbalance한 경우가 발생한다.
이 때 job들의 실행 횟수(비율)이 달라져 unfair한 문제가 생긴다.
How to deal with load imbalance?
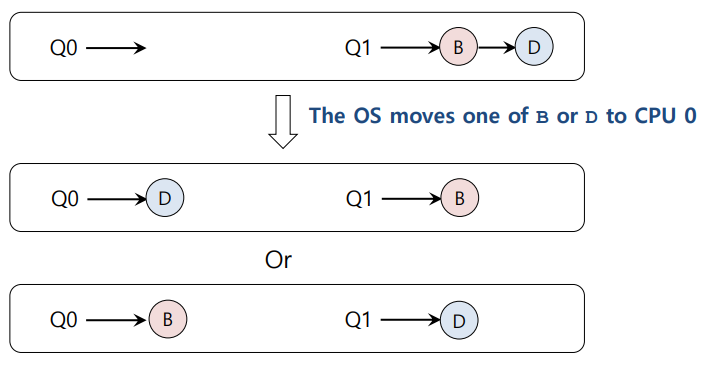
위와 같이 job을 이동시킨다. (migration)
위와 같이 가능한 migration 경우의 수는 여러 가지 존재한다.
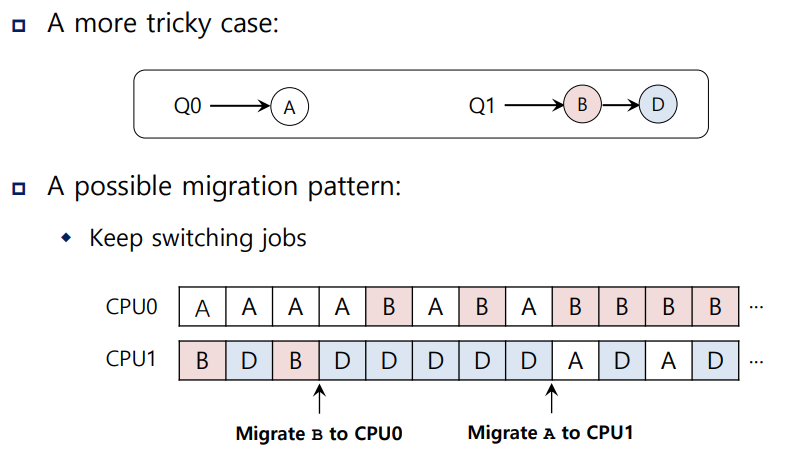
Work Stealing
- migration을 할 때 무엇을/어디로 이동시킬 지 결정하는 방법 중 하나이다.
job의 개수가 적은 queue를 source queue로 정한다.
나머지 target queue를 보면서 target queue의 job 개수가 source queue의 job 개수보다 많으면
job을 1개 혹은 1개 이상 훔쳐온다.
SQMS의 scalability문제를 해결하기 위해 MQMS 방식을 사용하는 것인데 여기서도 같은 문제가 발생한다.
CPU0가 CPU1의 Job을 가져오는 동시에 CPU1가 큐에 어떤 작업을 하게 되는 경우
동일 큐에 동시 접근하는 동기화 문제가 발생한다.
따라서 모든 CPU의 함수에 lock-unlock을 추가해주어야 한다 -> overhead
- CPU가 여러 개 존재할 때 1번 CPU의 큐가 job의 개수가 많다고 해보면
나머지 CPU에서 job을 steal하기 위해 접근하려하니까 scalability 문제 발생
그래도 CPU가 자기 자신 큐에 접근할 때는 동기화 문제가 발생하지 않기 때문에
SQMS의 scalability 문제보다 심각하지는 않다.