1. 빅데이터의 정의
클라우드 컴퓨팅 강의의 1주차 수업 복습이다.
빅데이터의 정의에 대해 알아 본다. 빅데이터의 정의로는 2가지로 나눌 수 있다.
-
기존 데이터베이스 관리 도구의 데이터 수집, 저장, 관리, 분석하는 역량을 넘어서는 데이터이다. 맥킨지에서 2011년 6월에 정의했다.
-
업무 수행 방식에 초점을 맞춘 정의이다. 다양한 종류의 대규모 데이터로부터 저렴한 비용으로 가치를 추출하고, 데이터의 빠른 수집, 발굴, 분석을 지원하도록 고안된 차세대 기술 및 아키텍처이다. IDC에서 2010년 4월에 정의했다. 여기서 말하는 저렴한 비용에 대해 다시 보자. 만약 가치 추출에 들어가는 비용보다 데이터를 저장하고 처리하는 비용이 더 높다면, 원래 목적에 위배된다. 따라서, 이 정의 방식은 저비용 고효율 방식을 지원할 수 있는 차세대 기술 및 아키텍처가 빅데이터다 라고 정의하는 것이다.
2. 빅데이터의 3대 요소
빅데이터에는 3대 요소가 존재한다. 이것을 3V라고도 한다.
Volume(크기), Velocity(속도), Variety(다양성) 이다. 여기에 Value(가치 창출)을 합쳐 4V라고도 한다.
2-1. Volume(크기)
- Volume(크기)는 일반적으로 수십 테라 바이트(Tera Byte) 혹은 수십 페타 바이트(Peta Byte) 이상이다. 즉, 용량이 얼마나 됐든 노드 안에 들어가기 어려운 규모가 되어야 빅데이터가 될 수 있다.
여기서 노드란, 분산 시스템에서 네트워크에 연결된 하나의 컴퓨터를 말한다.
또한, 최근에는 데이터의 양이 데이터 웨어하우스(DW : Data Warehouse) 같은 솔루션에서 소화하기 어려울 정도로 급격히 늘어났기 때문에 이에 대한 새로운 접근법이 필요해졌다. 그 접근법은,확장 가능한(Scalable) 방식으로 데이터를 저장하고 분석하는 분산 컴퓨팅(Distributed Computing) 기법이다.
확장 가능성(Scalable)에는 Scale Up과 Scale Out이 있다.
- Scale Out : 일반적으로 Scalable라 하면 해당되는 것으로, 컴퓨터 1대로는 부족하므로 여러 컴퓨터를 묶어 처리하고자 하는 방식이다.
- Scale Up : 하나의 컴퓨터의 자원을 증가시키는 것을 말한다.
2-2. Velocity(속도)
- Velocity(속도)는 실시간 처리(Real-Time Processing)와 장기적 접근(Batch Processing)으로 나눌 수 있다.
- 오늘날 디지털 데이터는 매우 빠르게 급속도로 생성되고 있으며,
실시간 처리 방식은 교통, 금융 거래, 쇼핑, SNS, 의료 등의 서비스가 해당된다고 할 수 있다. 실시간 처리 방식의 경우 데이터의생산,저장,유통,수집,분석의실시간 처리가 핵심이다. 장기적 접근(Batch Processing)은 수집된 대량의 데이터를 다양한 분석 기법과 표현 기술로 분석하는 것이다.데이터 마이닝,기계 학습,자연어 처리등이 이에 해당된다. 예시로, 구글이 하둡의 근간이 되는 파일 시스템과 MapReduce를 만들었을 때 구글이 사용하는 검색 인덱스를 만들기 위해Batch Processing이 더 중요한 목적이었다고 한다.
- 오늘날 디지털 데이터는 매우 빠르게 급속도로 생성되고 있으며,
2-3. Variety(다양성)
- Variety(다양성)을 알아 보자. 데이터의 종류에는 정형 데이터(Structured), 반정형 데이터(Semi-Structured), 비정형 데이터(Unstructured)가 있다.
- 정형 데이터 : 고정된 필드에 저장되는 데이터를 말한다. 매우 형식적인 form을 갖춘 데이터라고 할 수 있다.
- 반정형 데이터 : 고정된 필드로 저장되지는 않으나 XML, HTML, JSON과 같이 메타 데이터나 스키마를 포함하는 데이터를 말한다.
- 비정형 데이터 : 고정된 필드에 저장되어 있지 않은 데이터로, 동영상, 사진, 오디오 데이터, 메신저 내역 등 틀이 아예 없는 데이터를 말한다. 이 경우 다양한 형태의 데이터 저장 기술(Hadoop, RDB, Spark, Mongo DB 등)을 사용한다.
3. 클라우드의 정의
클라우드의 개념에 대해 알아보자. 클라우드의 개념을 소개할 때는 "As a Service" through the Internet 라는 문장이 함께 온다. 클라우드 컴퓨팅은 결국 솔루션을 As a Service 형태로 제공하는 것인데, 그 솔루션이 플랫폼을 제공하는 것인지, 하드웨어 OS SW 등의 인프라를 제공하는 것인지, 메일 같은 SW를 제공하는지에 따라 3가지로 구분한다.
3-1. IaaS
IaaS(Infrastructure-as-a-Service)란, 서버/스토리지/네트워크 등의 하드웨어 자원을 필요에 따라서 사용할 수 있게 제공하는 형태이다. IaaS 분야에서는 AWS(아마존 웹 서비스)가 선두주자라고 한다. 사용자 측면으로는 기업의 IT 부서가 사용한다.
3-2. PaaS
Paas(Platform-as-a-Service)란, 서비스를 개발할 수 있는 안정적인 환경(Platform)과 응용 프로그램을 개발할 수 있는 API까지 제공하는 형태이다. PaaS 분야에서는 Windows Azure가 선두주자라고 한다. 사용자 측면으로는 개발자들이 사용한다.
3-3. SaaS
SaaS(Software-as-a-Service)란, 클라우드 환경에서 동작하는 응용 프로그램을 서비스 형태로 제공하는 형태이다. SaaS 분야에서는 구글의 여러 Apps, Office 365 등이 선두주자라고 할 수 있다. 사용자 측면으로는 일반적인 사용자가 사용한다.
위 3가지가 클라우드 컴퓨팅의 대표적인 3가지 서비스라고 할 수 있다.
4. 서비스, Utility Computing
Utility Computing이라는 개념이 있다. 이것은 컴퓨팅 자원을 측정할 수 있도록 하여 서비스를 제공하고 사용한 만큼 돈을 내는 것을 말한다. 이로써 동적으로 자유롭게 가상머신을 우리가 사용할 수 있는 상태가 되는 것이다.(dynamically provision = 동적으로 구동시킨다. = 동적으로 사용한다.)
이러한 서비스를 왜 사용할까?
4-1. 서비스 사용 이유
비용적인 면에서 이러한 시스템을 사용하게 된다면 초기 투자 비용을 상당히 절약할 수 있을 것이다. Scalability(확장 가능성) 측면에서는 사실상 무한에 가까운 용량을 사용할 수 있게 된다. (실제로 무한대라는 것은 절대 아니다.) 그 다음 Elasticity 측면에서는 탄력적으로 용량을 사용할 수 있게 된다.
4-2. 월트 디즈니 사례
밑 그림의 월트 디즈니의 애니메이션 랜더링 사례에서 알 수 있다. 프로젝트 초기 초기 투자 용량에 비해 사용량은 훨씬 덜 했으나 후반으로 갈수록 초기 투자 비용을 넘어 사용했음을 알 수 있다. 이러한 서비스를 사용하게 된다면 초기 투자 용량에 비해 사용하지 않은 만큼은 클라우드 자원을 조금 쓰다가, 자원을 많이 사용하게 되었을 때 클라우드 자원을 더 많이 사용할 수 있게 하는 방식이다. 이러한 방식은 수요와 공급을 맞아 떨어지게 할 수 있으며 효율적으로 프로젝트를 운용할 수 있게 해준다. 또한, 이러한 서비스의 사용으로 프로젝트의 기간을 좀 더 앞당길 수 있다. 그렇다고 가격이 비싸느냐? 그렇지 않다. 밑 그림 맨 위에 검은색 글자에서 알 수 있듯, 20분 만에 4만 개의 코어를 준비할 만큼 속도도 빠르며 1코어 사용시 시간당 0.02$로, 가격도 저렴하다. 즉, 클라우드 시스템이 실제로 상당히 효율적인 시스템임을 알 수 있다.
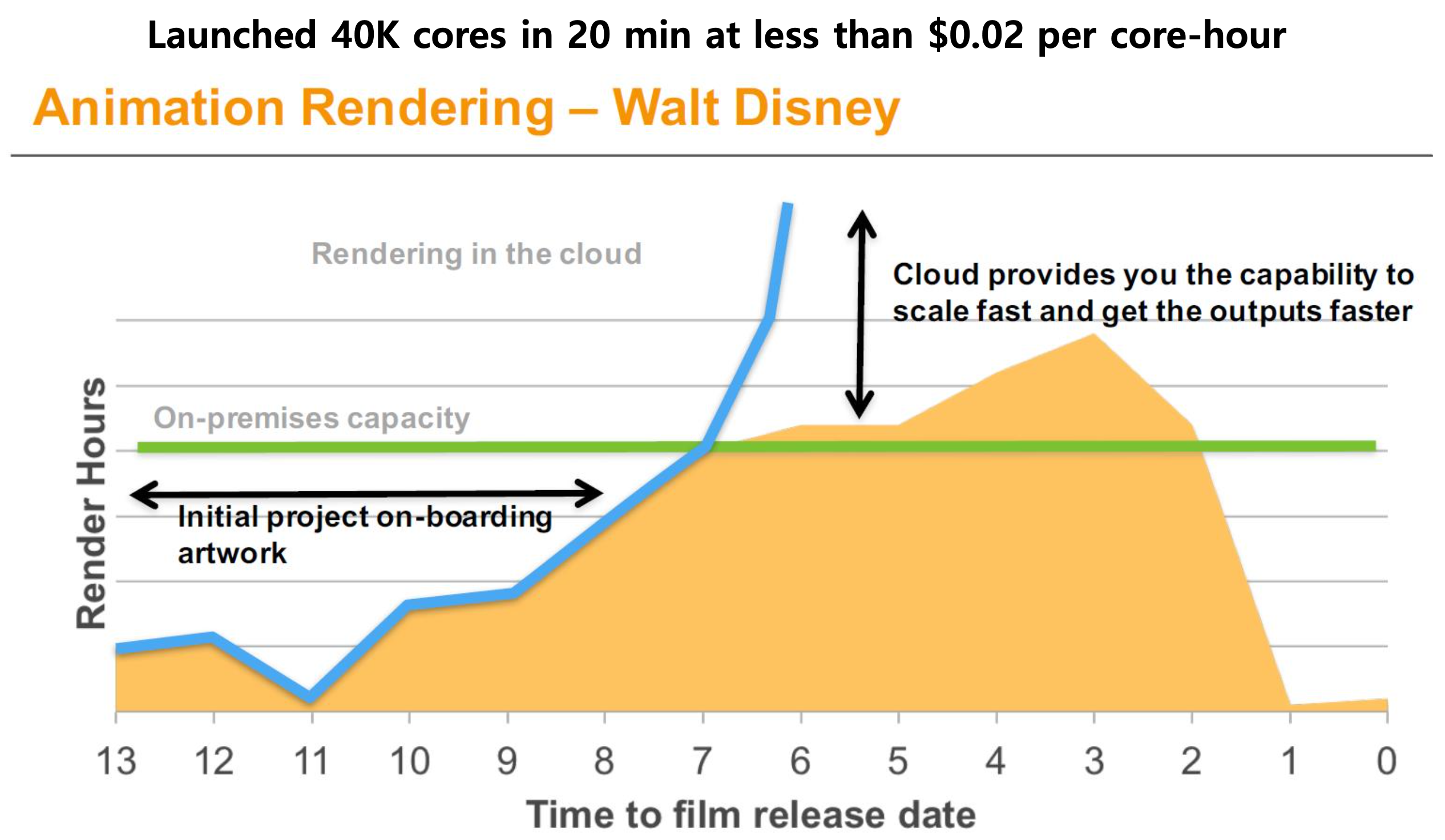
- 출처 : http://www.slideshare.net/AmazonWebServices/cmp404-cloud-rendering-at-walt-disney-animation-studios
5. 가상화 기술
다음으로 클라우드 시스템의 핵심 기술인 가상화(Virtualization) 기술에 대해 알아보자.
기존 전통적인 방법으로는 하드웨어 위에 OS가 있고, OS에서 여러 응용 프로그램을 구동하는 방식이었다. 그러나 가상화 기술은 하드웨어 위에 Hypervisor 이라고 불리는 가상화 기술의 핵심이 존재하고 그 위에 여러 OS가 존재한다.
Hypervisor : 하나의 물리적인 자원에서 구동할 수 있는 OS의 종류가 다양해졌다. 즉, 하나의 물리자원을 최대한 잘 공유하여 여러 개의 운영체제가 공존할 수 있도록 만든 것이 Hypervisor 기술이다.
가상화 기술에는 Type1, Type2가 있다. 아래 그림을 보자.
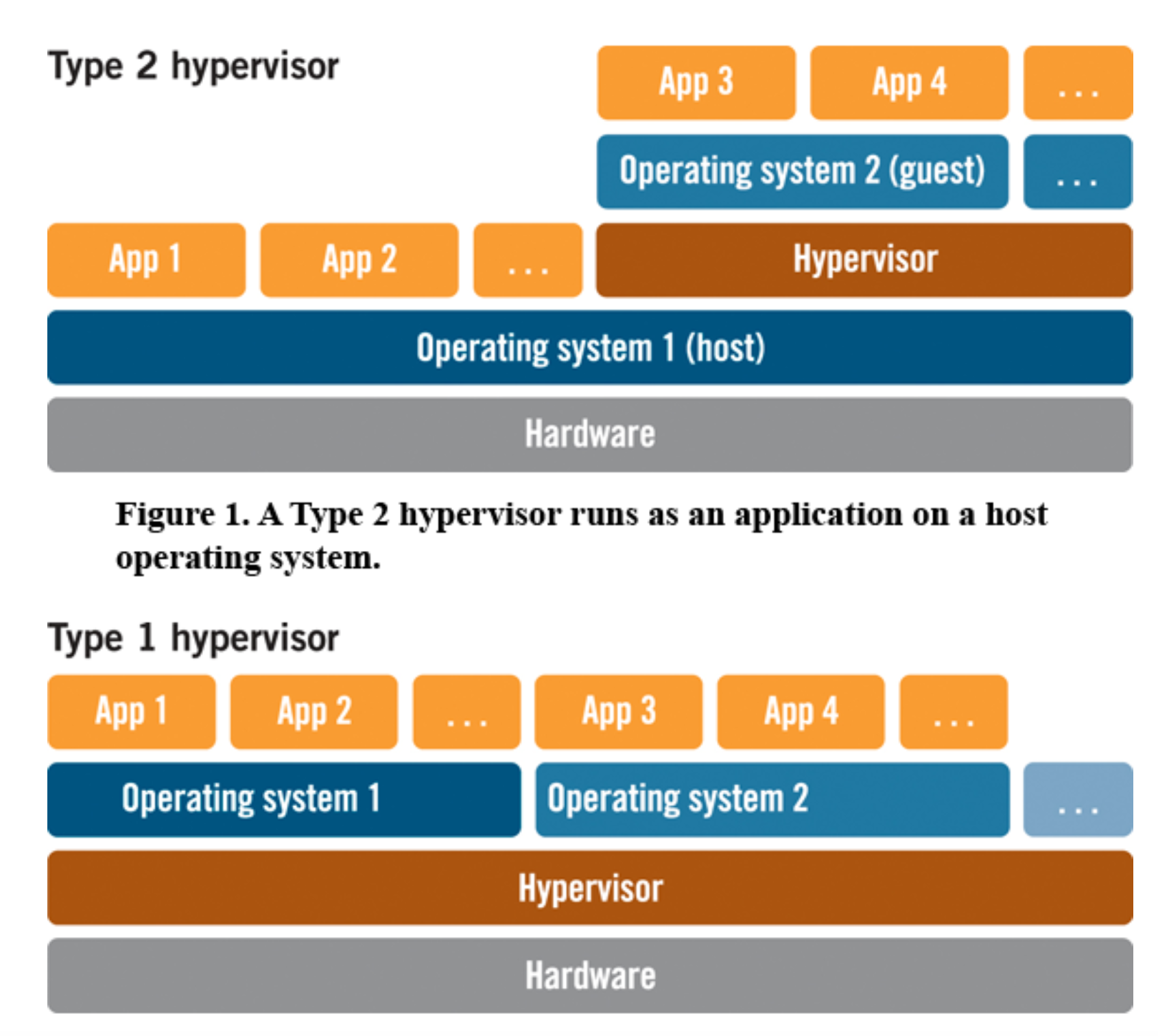
- 출처: https://www.ecnmag.com/article/2010/04 /can-hypervisors-stand-test-real-time
Type2는 우리가 흔하게 사용하던 방식이다. 우리가 사용하는 노트북에 가상 머신을 설치하고, 가상 머신에 CentOS, Ubuntu 등을 구동하는 것과 같다.
반면 Type1은 Host OS가 Type2에 비해 사라졌다. Type1은 보통 데이터 센터에서 사용하는 서버용이다. 또한, Layer가 많을 수록 오버헤드가 많다는 것을 의미한다.
5-1. 컨테이너 기반 가상화 기술
하지만 위의 두 가지 방식 모두 어찌됐건 Hypervisor 위에 OS가 올라간다는 것은 바뀌지 않는다. 운영체제는 상당히 무겁기 때문에 이를 개선한 것이 Container-based Virtualization 이다. 아래 그림을 보자.
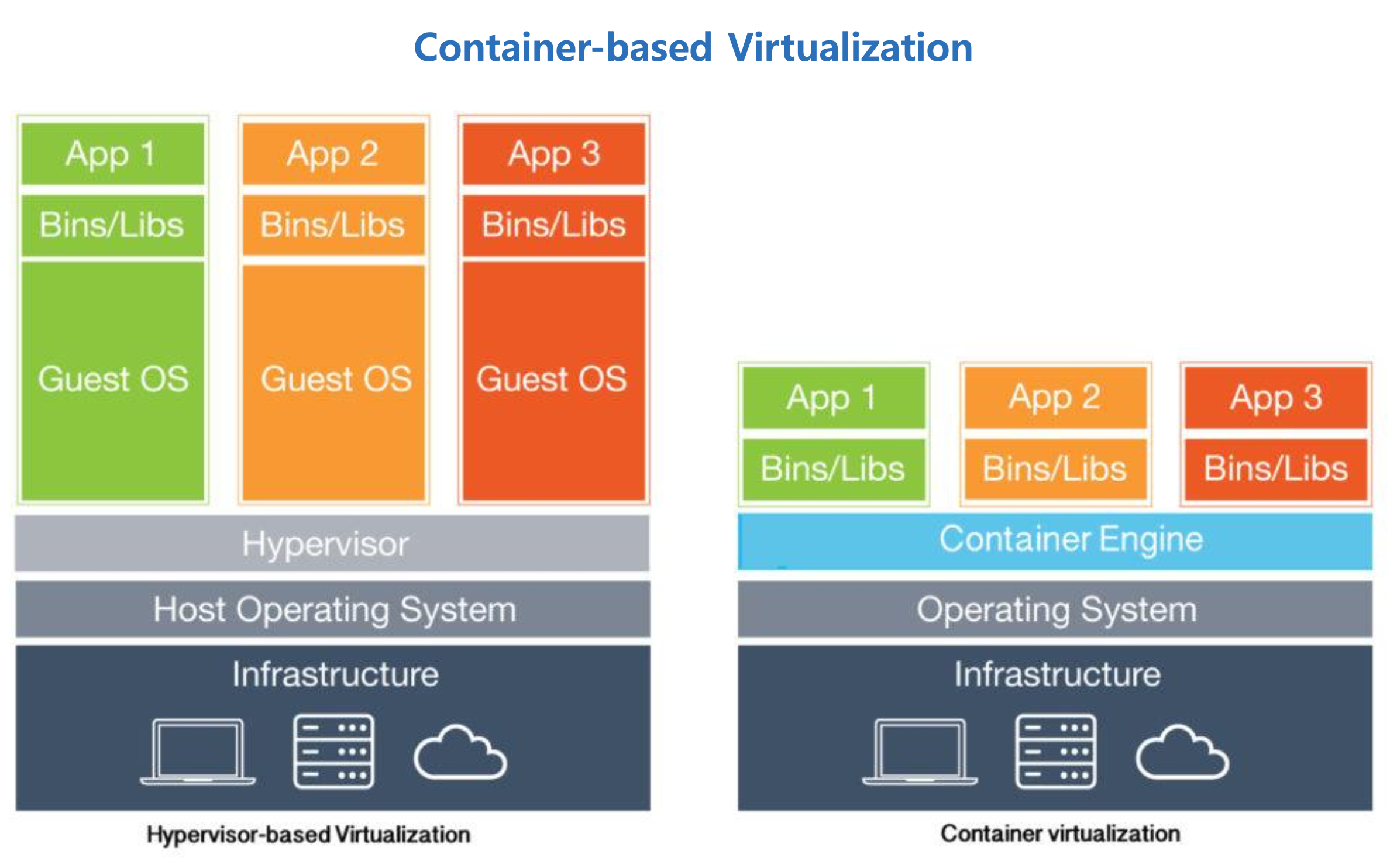
왼쪽의 Hypervisor-based Virtualization은 결국 guest OS가 포함되어 있다. 하지만, 컨테이너 기반 가상화 기술은 guest OS가 없다. 따라서, Container Engine이 host OS의 커널 기능을 공유하여 guest OS가 없어도 다른 응용 프로그램이 구동될 수 있도록 해준다. 따라서, Hypervisor에 비해 상당히 가볍다는 장점을 가진다.
다만, 컨테이너 기반 기상화 기술은 무조건 리눅스 시스템에서만 사용할 수 있다. 또한, 컨테이너 위의 layer도 모두 리눅스여야 한다. 컨테이너 기반 가상화 기술은 대표적으로 Docker가 있다.
이상 첫 주의 클라우드 컴퓨팅 강의 정리를 마치도록 한다.
