1. 병렬화 문제(Parallelization Challenges)
빅데이터를 다룰 수 있는 가장 좋은 방법은 분할 정복(Divide and Conquer) 이다.
분할 정복이란, 하나의 큰 Work를 여러 개의 work로 분할한 다음, 각각을 처리하여 다시 하나로 합치는 작업을 말한다. 우선 하나의 work를 세부적인 work로 쪼갠다. 그 다음, 각 작업의 처리를 담당하는 worker(각 작업을 처리하는 프로세스, 노드 등의 주체를 말함.)가 자신에게 할당된 각 작업을 동시다발적으로, 독립적으로 수행하고 각각 결과를 낸다. 그리고 그 결과를 합치게 된다.
다만 이러한 분할 정복 방법은 아래와 같은 병렬화 문제를 갖고 있다.
-
우리가 어떤 방식으로 작업을 분배할 것인가? (작업 분배를 적당히 data compute를 잘 쪼개어 보냈을 때 문제가 될 수 있는 것은, 똑같은
work unit(작업의 단위)이라 하더라도 실행 시간의 차이가 있기 때문이다.) -
worker 보다 work unit가 더 많은 경우, worker가 어쨌든 계속 실행해야 하는 상황이 된다. 이 경우, worker들에게 어떻게 작업 분배를 최적화 시켜줄 것인가? (
Load Balancing문제라고도 한다.
Load Balancing이란, 어떤 하나의 worker가 너무 많은 작업을 처리하면 그 하나 탓에 전체적으로 Processing이 느려지는 것을 말한다. 다른 worker가 작업이 끝났다고 하더라도 진행 중인 작업이 끝날 때까지 기다려야 하기 때문이다.) -
worker들이 각자 unit를 받아서 실행을 했는데, 실행 결과를 서로 공유해야 한다는 상황이라면 어떻게 공유할 것인가?
-
중간 결과물 및 산출물을 어떻게
aggregate할 것이냐?
(이 때aggregate는 여러 의미를 갖는다. 최종적인 목적은 하나로 합치는 것으로 동일하나 그 방법이 이미지를 만들거나, 통계를 내거나 등등의 방법이 있다.) -
모든 worker들이 수행이 끝나야만 하는데, worker들이 끝났다는 것을 어떻게 알 수 있을까?
-
worker가 작동 중 die 했다면?
위와 같은 문제들의 원인은 무엇일까.
worker들 간의 통신이 있을 때 혹은 공통된 자원에 접근하여 처리할 때 위와 같은 평행 문제가 발생한다. 따라서, 동기화 매커니즘(synchronization mechanism)을 통해서 worker 들의 상호 통신과 공통된 리소스에도 접근할 수 있도록 하는 매커니즘이 필요하다.
또한, 병렬성은 자체가 추론하기 어렵기 때문에 추구하는 것 또한 어렵다. Load Balancing, workers die 등의 문제가 있기 때문이다.
하지만, 이러한 이유 말고도 병렬성 문제가 더 어려울 수 있는 상황이 있다.
- 단순 몇 개의 worker 가 아니라 data center 급으로 크기가 크다면?
- 컴퓨터 에러 및 고장 등의 실패가 발생하게 된다면?
- 상호 작용하는 서비스가 많은 경우라면 병렬성을 보장하기 어렵다.
- 당연스럽게도, 디버깅은 말할 필요도 없이 돌다가 죽어버리면 무엇 때문인지 추론하기 매우 어렵다.
그리고 현실에서 한번 쓰고 버리는 것, 혹은 알아서 적당히 짜깁기한 커스텀 코드 등은 프로그래머에게 큰 부담이 될 수 있다. 결론적으로는, 병렬적으로 실행하기 위해서는 생각보다 많은 것을 고려해야 한다는 것을 알 수 있다.
2. Programming Models and Design Pattern
아래와 같은 프로그래밍 모델이 있다. 두 모델의 차이는 무엇일까.
- Shared memory (pthreads)
Shared memory방식은 하나의 메모리를 공유하면서 여러 개의 스레드를 실행하는 것이다. 이말은 즉슨, 하나의 컴퓨터밖에 안된다는 것이다. 즉,Scale Up이다.
- Message passing (MPI : Message Passing Interface)
Message passing방식은 메시지를 서로 주고 받으며 통신한다. 서로 다 다른 컴퓨터에서 프로세스가 돌아도 메시지 통신만 가능하다면병렬 처리가 가능해지게 된다. 즉,Scale Out이다. MPI는 주로 슈퍼 컴퓨터에서 많이 사용하는 방식이다.
아래와 같은 디자인 패턴에 대해 알아보도록 한다.
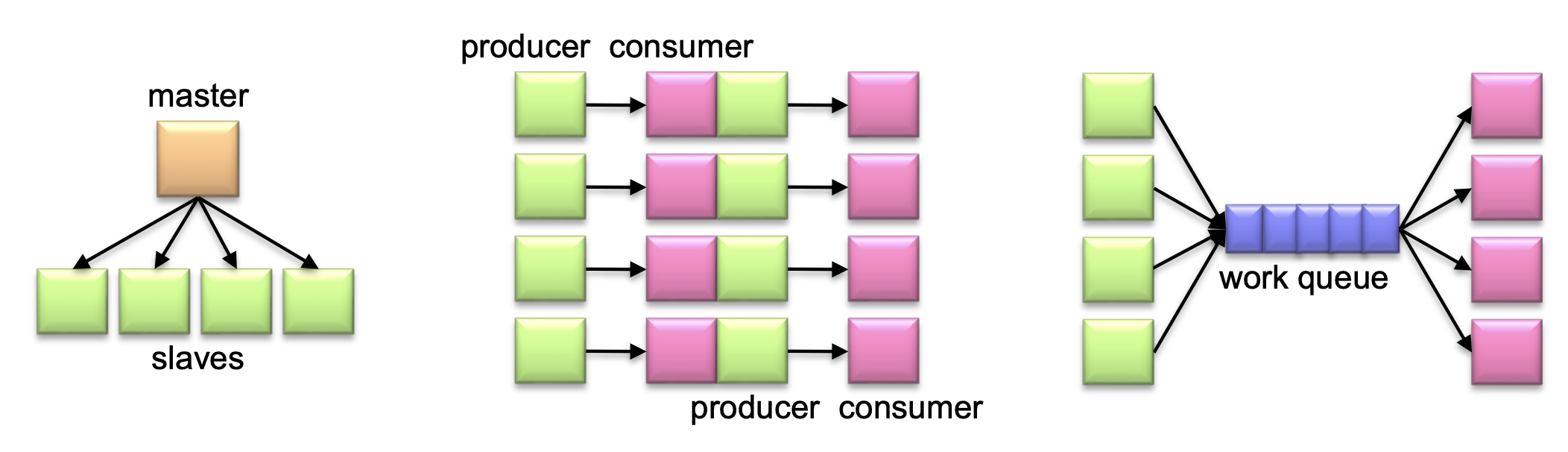
- Master-slaves
Master-slaves방식은 가장 구현하기 쉬워, 하둡 스파크 등의 빅데이터 플랫폼도 master-slave 구조를 갖는다. (master가 총 감독하며 작업을 처리하게 된다.)
- Producer-consumer flows
Producer-consumer flows방식에서 producer은 작업 생성을 담당하며 consumer은 어떤 producer가 생성한 작업이 관심이 있는지를 subscribe 한다고 한다.(= 관심 작업만 처리하도록 한다.)
- Shared work queues
Shared work queues는 producer 들이 작업을 생성한 후 queue에 삽입하면, 무작위로 consumer들이 작업을 queue에서 빼내어 실행하게 된다.
각 디자인 패턴에 대한 구조는 아래와 같다.
3. Making the datacenter as a computer
데이터 센터를 컴퓨터 처럼 하고 싶다라는 것은, 데이터 센터에는 수 많은 컴퓨터가 존재하는데 이때 이 수 많은 컴퓨터들을 하나의 컴퓨터처럼 동작하게 하고 싶다는 것이다.
빅데이터 문제를 다루는 데 있어 분할 정복(Divide and Conquer)을 해야 한다고 했다. 즉, 큰 데이터를 쪼개서 여러 컴퓨터(worker)에게 나눠 주고 그것을 병렬적으로 처리하면서 발생할 수 있는 문제들은 누군가 관리해 줬으면 좋겠다는 것이다.
이것에는 여러 조건이 존재한다.
-
단순한 하나의 컴퓨터 아키텍쳐를 넘어서 여러 대의 컴퓨터가 묶인 데이터 센터를 하나의 컴퓨터처럼 인식해 보자 한다면,
Instruction Set이라는 명령어의 집합이 있어야 한다. -
또 다른 조건도 있다. 시스템 level의 디테일은 개발자로부터 감추고 싶다는 것이다. 이 말은,
분할 정복방식을 실행할 때 수 많은one-off solution(일회용),custom code등이 난무하여 개발자가 parallel하게 실행하는 모든 책임을 전가하는 것이므로 상당히 부담되기에, 개발자들이 이를 걱정하지 않을 정도로 데이터 센터를 하나의 큰 컴퓨터화 했으면 좋겠다 하는 것이다. -
마지막으로 무엇을 할 것인지, 어떻게 할 것인지는 구분했으면 좋겠다고 하는 것이다. 개발자 입장에서 계산 및 처리가 하고 싶다고 명시를 하면 execution framework가 알아서 잘 handling 했으면 좋겠다라는 것이다. 즉,
"what을 주면 how는 해달라"라는 것이다.
데이터 센터를 하나의 큰 컴퓨터로 만들고 싶은데 어떻게 해야 할까? 아래 4가지의 접근법이 있다.
1. Scale out, not up
여러 컴퓨터로 확장하여 분산 시스템을 구축해야 한다.
2. Move processing close to the data
보통 처리하는 데이터의 양이 상당히 크므로 데이터를 옮기는 것은 비효율적일 것이다. bandwidth의 한계가 있기 때문에, 보내는 것 자체가 불가능에 가까울 수도 있다. 따라서, 데이터를 처리하는 processing 자체를 데이터와 가깝게 보내는 것이다.
3. Process data sequentially, avoid random access
하드웨어 seek 연산은 상당히 느리다. random access는 seek 연산이므로, 이를 계속 시행하는 것은 상당히 비효율적이며 좋지 않다.
4. Seamless scalability
효과적으로 확장 가능한 아키텍쳐 방향으로 가야 한다. 단순히 서버를 추가하면 전체적인 컴퓨팅 파워, storage 등이 자연스럽게 증가할 수 있는 구조로 가야 한다.
위 4가지 철학을 기반으로 탄생한 것이 아파치 하둡이다.
4. BigData & Hadoop
하둡은 de facto standard 라는 말을 한다. 사실상의 표준이라는 뜻이다. 즉, 국제 표준은 아니지만 실제로 아주 많이 사용된다는 것이다. 하둡은 빅데이터 저장 및 관리, 처리를 수행한다.
HDFS(Hadoop Distribute File System)는 데이터를 저장하는 하둡의 시스템이다.MapReduce는 데이터를 처리하는 역할을 맡는다.
하둡은 대용량 데이터를 분산 처리할 수 있는 자바 기반의 오픈소스 프레임워크이다. 그런데 왜 하둡을 사용할까?
엄청나게 많고 다양한 종류의 데이터를 처리하기 위해 등장했다고 보면 될 것이다. 지금까지 전통적인 방식(RDBMS)으로 정형 데이터는 충분히 처리할 수 있었다. 하지만, RDBMS 로는 비정형 및 반정형 데이터는 처리하기 어려웠다. 이에 따라 하둡이 등장했다. 하둡은 또한 여러 가지 장점을 갖는다.
오픈소스 프로젝트이므로소프트웨어 라이선스 비용의 부담이 적다.Commodity Hardware를 활용한다. (Commodity : 구하기 쉬운)Scale-Out아키텍쳐이다.- 데이터의 유실이나 장애를 데이터의 복제를 통해
복구할 수 있다. - 여러 대의 서버에 데이터를 분산 저장하고 데이터가 저장된 각 서버에서 동시에 데이터를 처리할 수 있다.
(Data Locality)
하지만 하둡에 대한 오해 또한 존재한다.
-
RDBMS를 대체한다?
하둡은 RDBMS와상호보완적인 특성을 가진다.ETL(Extraction, Transformation, Loading)과정의 효율적인 구현을 한다.
또한, 하둡은 RDBMS와는 다르게 신속한 데이터 처리, 즉 트랜잭션이 매우 중요한 데이터를 처리하는데 부적합하다. 하둡은 분산 시스템이기 때문에 많은 서버가 있어Batch 성 처리에 최적화되어 있기 때문이다. -
하둡은 NoSQL 이다?
하둡의 플랫폼 구성 요소 중 하나인HBase를 통해NoSQL(Not-Only-SQL)이 가능한 것이다. RDBMS는 타겟으로 하는work road(트랜잭션, 조인 등)이상당히 복잡하기 때문에 분산 환경에는 적합하지 않다. 잠깐NoSQL의 기능을 알아 보자.
+ NoSQL은Key-Value Pair로 구성된다.
+Index와 Data가 분리되어별도로 운영된다.
+조인(Join)이 없고, RDBMS에서는 여러 Row 형태로 존재하던 데이터들을 하나의 집합된 형태로 저장한다.
+Sharding이라는 기능을 이용하여데이터를 분할해서 다른 서버에 나누어 저장한다.
+ RDBMS처럼완벽한 데이터 무결성과정합성을 제공하지는 않는다.
참고로 메타 데이터란, 분산되어 있는 데이터에 대한 정보를 갖고 있는 것이다.
그렇다면 하둡의 문제점에 대해서 알아보도록 하자.
-
고가용성(HA : High Availability) 지원
고가용성(HA)은 99.999% 상태의 가용을 의미한다. 이를 수치로 환산하면 1년 중에 30분 정도를 제외하고 서비스가 가능한 수치이다.
Name Node(HDFS의 메타데이터 Master 이다.)의 중앙 집중적인 메타데이터 관리로,single point of failure & contention이 발생하게 된다. 이것은단일 고장 & 집중이라고 해석할 수 있는데, 모든 request가 한쪽으로 몰리는 것이다. 이 중에서도contention보다failure가 더 컸다.(master가 죽어버리게 된다면고가용성을 보장하기 어렵기 때문이다.) 따라서 master-slave 모델에서는 고가용성을 보장하기 어려움을 알 수 있다. -
파일 Namespace 제한
NameNode가 관리하는 메타데이터는 메모리로 관리한다. 메모리로 관리해야 빠르게 처리할 수 있기 때문이다.(Single point of contention(집중)이다보니 최대한 request를 빠르고 효율적으로 처리하기 위해 메타 데이터를 항상메모리에 상주시키는 것이다.) 메모리로 관리하기 때문에 메모리 용량에 따라HDFS에 저장되는파일과 디렉토리의 개수가 제한될 수밖에 없다.
이에 따라 작은 파일들이 많이 생기면 메모리 용량을 초과해 버릴 수 있기 때문에HDFS는 작은 파일들이 많이 생겨나지 않도록block size를 크게잡는다. -
데이터 수정 불가
한번 저장한 파일은수정할 수 없다.파일의 이동(move)이나이름 변경(rename)은 가능하지만 저장된 파일의 내용을 수정할 수는 없다. 따라서,파일 읽기 혹은 배치 작업만이 하둡에 적합하다는 것을 알 수 있다. (기존에 저장된 파일에 내용을 Append 하는 기능은 제공한다.) -
POSIX 명령어 미지원
기존 파일 시스템에서 사용하던 rm, mv와 같은POSIX 형식의 파일 명령어를 사용할 수 없다.다만, 하둡에서 별도로 제공하는Shell Command/API를 활용하면 된다.
