1. 빅데이터의 개념
빅데이터는 지금까지 명확한 개념으로 규정된 적이 없다. 맥킨지와 IDC에 따르면 다음과 같이 빅데이터를 정의했다.
1. 데이터의 규모에 초점을 맞춘 정의 - 맥킨지
기존 데이터베이스 관리 도구의 데이터 수집, 저장, 관리, 분석하는 역량을 넘어서는 데이터이다.
2. 업무 수행 방식에 초점을 맞춘 정의 - IDC
다양한 종류의 대규모 데이터로부터 저렴한 비용으로 가치를 추출하고, 데이터의 빠른 수집 및 발굴, 분석을 지원하도록 고안된 차세대 기술 및 아키텍쳐이다.
위와 같은 빅데이터 정의만으로는 빅데이터를 이해하기 어려울 것이다. 이 때 빅데이터의 3대 요소를 알아봐야 한다. 이는 3V라고도 한다.
- Velocity (속도)
빅데이터를 처리하는 것은 속도가 당연히 중요하다. 빅데이터에서의 속도는 2가지로 나눌 수 있다.실시간 처리(Real Time Processing)와장기적 접근(Batch Processing)이다. 데이터의 특성, 서비스의 특징에 의해 실시간 처리를 하는 것이 유용한지, 장기적 접근이 유용한지를 구분지을 수 있다. 가령 금융 데이터라면 실시간으로 처리되어야 할 것이다. 반대로 오랜 기간 축적된 데이터를 분석함으로써 유용한 가치를 창출하려는 것이라면 빠른 처리보다 다양한 분석 기법과 표현 기술로 분석하는 Batch Processing 방식이 유용할 것이다.
- Varirty (다양성)
데이터는 다양하다. 단순화된 몇 개의 데이터라 하면 그것을 분석함으로써 얻는 결과도 단조로울 것이며, 큰 의미를 갖지 못할 것이다. 다양한 종류의 데이터를 이용해 분석할 수 있어야 하는 것이다. 데이터는정형 데이터(Structured Data),반정형 데이터(Semi-Structured Data),비정형 데이터(Unstructured Data)로 나눌 수 있다. 정형 데이터는 RDBMS 방식으로 처리가 가능한, 정해진 구조를 갖고 고정된 필드에 저장되는 데이터이다. 반정형 데이터는 JSON, XML 등이 해당되는데 고정된 필드에 저장되지는 않으나 메타 데이터나 스키마 등을 갖는 것이다. 비정형 데이터는 고정된 필드에 저장되지 않는 데이터를 말한다. 사진, 텍스트, 이미지, 동영상이 이에 해당할 것이다. 빅데이터는 이러한 모든 다양한 종류의 데이터를 분석할 수 있어야 한다.
- Volume (크기)
빅데이터를 처리하는데 있어 데이터의 크기가 크지 않다면 의미가 없을 것이다. 최근에는 데이터가 기존의 DW(Data Warehouse)에서 처리하기 어려울 정도로 급격하게 늘어나고 있다. 따라서,확장 가능한 방식으로 데이터를 저장하고 분석하는분산 컴퓨팅 기법이 필요할 것이다.
2. 하둡(Hadoop)
2-1. 왜 하둡일까?
데이터는 현재 시대에 상당히 빠른 속도로 많은 양이 생산되고 있다. 이에 따라 기존의 RDBMS로는 데이터를 보관, 처리하기 어려워졌다. 상용 RDBMS의 스토리지를 무한정 늘리는 것도 경제적으로 좋은 방법이 아니다. 게다가 정형 데이터의 경우 기존 RDBMS로 처리할 수 있었으나 비정형 데이터의 경우에는 그러기 어렵다.
반면 하둡의 경우 오픈소스 프로젝트라서 그에 대한 비용 부담이 없다. 만약 스토리지가 부족한 경우 리눅스 서버를 더 늘리면 된다. fault tolerance도 있기 때문에, 데이터가 유실될 경우 복구가 가능하다는 장점도 존재한다. 이러한 하둡은 성능 또한 좋다. 병렬 처리 방식으로, 데이터를 여러 서버에 저장하고 동시에 처리한다. 병렬 처리 방식을 통해 기존의 데이터 분석 방식보다 훨씬 더 빠른 성능을 보여줄 수 있게 됐다. 하둡은 de-facto standard라고도 한다. 사실상의 표준이라는 뜻이다. 이러한 장점들이 존재하기 때문에 하둡은 빅데이터 분야에서 사실상의 표준으로 자리잡게 됐다.
RDBMS는 트랜잭션 처리, 무결성 보장 등의 장점을 갖는다. 데이터는 기업의 사실상의 자산이다. 따라서 보안이 그만큼 중요한데, 하둡 1.0 부터는 보안성도 챙겼다. kerberos 인증을 통해 네트워크 전체에 걸쳐 강력한 보안을 확보하게 됐다. 거기에 WebHDFS REST API를 제공함으로써 하둡을 잘 모르는 개발자도 쉽게 사용할 수 있게 됐다.
2-2. 하둡 에코시스템(Hadoop Eco System)
하둡은 다양한 요구를 반영할 수 있도록 여러 서브 프로젝트를 제공한다. 아래 그림을 참고하자.
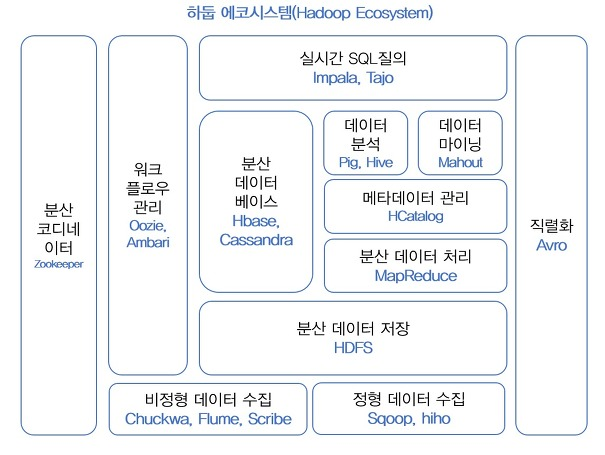
- 출처 : 시작하세요! 하둡 프로그래밍
위 그림을 보면 여러 서브 프로젝트들이 있음을 알 수 있다. 이 중에서 하둡 코어 프로젝트는 MapReduce, HDFS가 해당된다. 각 서브 프로젝트들은 다음과 같은 특징으로 분류할 수 있다. 참고로, 하둡 서브 프로젝트에는 자사에서 솔루션으로 활용하다가 오픈소스화 시킨 것도 있다.
- 코디네이터
-Zookeeper
- 분산 환경에서 서버 간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템이다.이것도 load balancing이라고 표현할 수 있는지는 모르겠다.
- 리소스 관리
-Yarn,Mesos
- 클러스터의 운영체제이다. 클러스터 환경에서 자원 관리를 하는 역할을 수행한다. Yarn의 경우 하둡 2.0 이상 버전부터 사용된다.
-
데이터 저장
-HBase,Kudu
- HBase의 경우 HDFS 기반의 컬럼 기반 데이터베이스이다. 실시간 랜덤 조회 및 업데이트가 가능하다.
- Kudu의 경우 컬럼 기반 스토리지이다. 특정 컬럼에 대한 데이터 읽기를 고속화할 수 있다고 한다. HDFS의 경우에도 컬럼 기반으로 데이터를 저장할 수 있으나 HDFS 자체가 온라인 처리에 유용하지 않다. 또한, HBase는 HDFS를 기반으로 온라인 처리가 가능하나 데이터 분석 처리가 느리다는 단점이 있었다. Kudu는 이러한 단점을 개선한 것이다. -
데이터 수집
-Chukwa,Flume,Scribe,Sqoop,Hiho,Kafka
- 말 그대로 데이터 수집이다. 필요한 데이터를 HDFS 로부터 수집하거나, 데이터를 수집하여 HDFS에 저장하는 등의 기능을 갖고 있다. -
데이터 처리
-Pig,Mahout,Spark,Impala,Presto,Hive,Tajo
- 이 또한 말 그대로 데이터 처리이다. 데이터를 여러 방식으로 처리하기 위한 방법들인 것이다. 특히 스파크는 가장 빠르게 성장하고 있는 오픈소스 프로젝트이다. -
워크플로우 관리
-Oozie,Airflow,Azkaban,Nifi
- 이 중에는 데이터의 흐름을 시각화 및 모니터링 하기 위한 것도 있고, 하둡 작업을 관리하는 워크플로우인 것도 있다.
-
데이터 시각화
-Zeppelin
- 빅데이터 분석가를 위한 웹 기반 분석 도구이다. 데이터를 시각화해준다. -
데이터 직렬화
-Avro,Thrift
- 데이터 직렬화란,serialization을 의미한다. 반대로 역직렬화는deserialization이다. 객체를 바이트 스트림으로 바꾸거나, 그 반대의 과정이다. 기본적으로 디스크에 저장된 데이터를 네트워크를 통해 전송하기 위해서는 객체를 바이트 스트림으로 바꿔줘야 한다.serialization은 디스크에서 데이터를 저장하거나, 전송하기 위해 사용하고deserialization은 디스크에 데이터를 읽거나 수신받고 데이터를 메모리에 쓸 수 있도록 하는 과정이다.
2-3. 하둡의 문제
당연하게도, 하둡도 문제가 있다. 하둡의 문제에 대해 알아보자.
고가용성(HA : High Availability)
하둡은 고가용성이 가장 큰 문제이다. 가용성이란, 시스템에서 장애가 발생한 이후 정상으로 시스템이 돌아오는 상태를 분석하는 척도이다. 고가용성은 99.999% 상태의 시스템 가용을 의미하고, 이를 시간으로 따지면 1년에 고작 30분 정도만 system down을 허용하는 것이다. 하둡은 기본적으로 master-slaves 구조이다. 만약 master가 down된다면 시스템 전체를 사용할 수 없게 될 수도 있다. 다만, 하둡 2.x 버전부터는 HDFS Namenode의 고가용성을 지원한다.
-
파일 네임스페이스 제한
HDFS의 Namenode는 메타 데이터를 메모리에서 관리한다. 이에 따라 메모리의 용량 탓에 HDFS에 저장할 수 있는 파일과 디렉토리의 수에 제한을 받게 된다. -
데이터 수정 불가
RDBMS는 가능하지만 하둡은 데이터를 update할 수 없다. 한번 저장한 데이터에 대해서는 update 할 수 없는 것이다. 다만, 저장된 데이터에 대해 append 기능은 제공한다. 빅데이터 관점에서 생각했을 때, 데이터의 update가 불가능한 것은 불편한 것은 맞으나 어느 정도 상식적으로 이해할 수 있다. 하둡은 굉장히 큰 데이터를 보관, 분석하는 용도이기 때문에 데이터를 수정한다기 보다 데이터를 분석하여 가치를 추출해내는 것이 더 유용할 것이기 때문이다. -
POSIX 명령어 미지원
하둡은 리눅스의 POSIX 명령어를 지원하지 않는다. 자체적인 셸 명령어와 API를 이용해 파일을 제어해야 한다. 다만, 하둡의 명령어는 리눅스의 POSIX 명령어와 유사하므로 익히는데 큰 시간이 걸리지는 않을 것이다. -
전문 업체 부족
국내에서는 하둡과 관련된 다양한 업체가 부족한 것이 현실이다. 해외의 아마존, 야후, 페이스북처럼 오랫동안 해당 분야에서 기술과 노하우를 쌓았지만 국내는 그렇지 않다. 이렇기 때문에 국내 기업들에서 하둡을 도입하기가 고민이 될 수밖에 없을 것이다.
