하둡
1.하둡 프로그래밍 - 하둡 기초
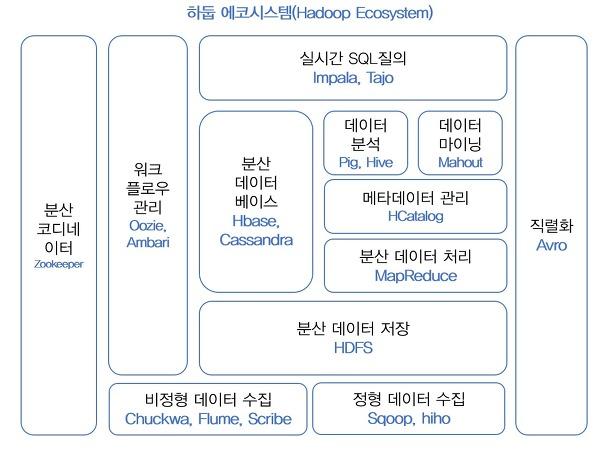
1. 빅데이터의 개념 빅데이터는 지금까지 명확한 개념으로 규정된 적이 없다. 맥킨지와 IDC에 따르면 다음과 같이 빅데이터를 정의했다. > 1. 데이터의 규모에 초점을 맞춘 정의 - 맥킨지 기존 데이터베이스 관리 도구의 데이터 수집, 저장, 관리, 분석하는 역량을 넘
2.하둡 프로그래밍 - 하둡 개발 환경 구축

1. 하둡 실행 모드 하둡의 실행 방식은 3가지가 있다. 독립 실행(Standalone) 모드 하둡의 기본 실행 모드이다. 하둡 환경설정 파일에 아무 설정도 하지 않고 실행하면 로컬 장비에서만 실행되게 된다. 때문에 독립 실행 모드는 로컬 모드라고도 한다. 다만, 하둡
3.하둡 프로그래밍 - HDFS
HDFS는 하둡에서 사용하는 분산 파일 시스템이다. HDFS 이전에도 다음과 같은 대용량 파일 시스템이 존재했다.DAS(Direct-Attached Storage) 서버에 직접 연결된 스토리지(storage)이며, 외장형 하드 디스크라고 생각하면 된다. 여러 개의 하드
4.하둡 프로그래밍 - MapReduce
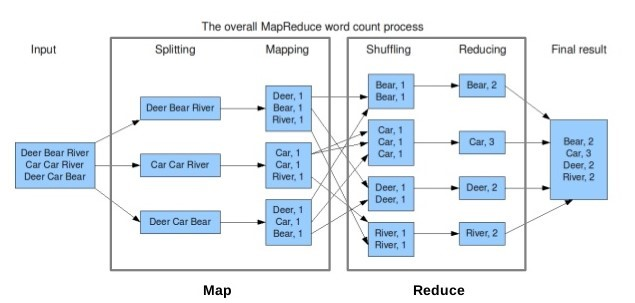
하둡은 기본적으로 HDFS, MapReduce로 구성된다. 맵리듀스는 HDFS에 저장된 파일을 분산 배치 분석을 할 수 있게 도와주는 프레임 워크이다. 개발자는 맵리듀스 프로그래밍 모델에 맞게 애플리케이션을 구현한다. 데이터 전송, 분산 처리, 내고장성 등의 복잡한 처
5.하둡 프로그래밍 - 미국 항공편 운항 통계 데이터 분석
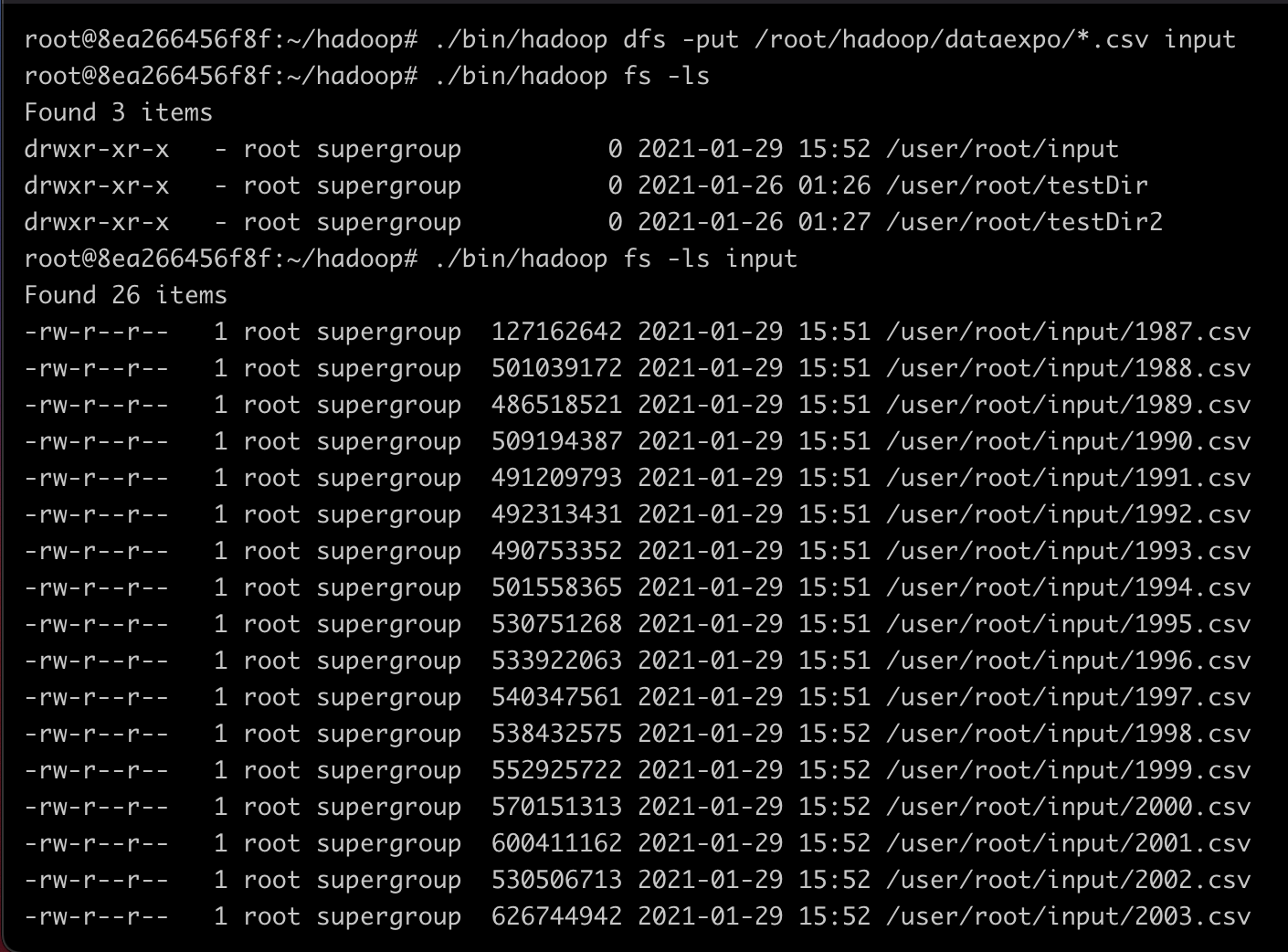
먼저, 데이터 분석에 들어가기 이전에 본인은 Docker에서 Ubuntu Container를 사용하여 하둡을 설치하고 환경 설정을 하였다. 1. 미국 항공편 운항 통계 데이터 분석 http://stat-computing.org/dataexpo/2009 에서 데이터를 가
6.하둡 프로그래밍 - MapReduce 응용
이전 게시물에서 항공 출발 지연 데이터에 대한 분석을 진행했었다. 반대로, 항공 도착 지연 데이터도 존재한다. 코드는 거의 유사하고, 동작 방식이나 출력 결과도 거의 다르지 않으므로 Github에만 업로드 하고 블로깅을 따로 하지는 않았다. 문제는 여기서 발생한다. 두
7.하둡 프로그래밍 - Secondary Sorting
하둡에서 정렬은 굉장히 많이 다뤄지고, 알려진 MapReduce의 핵심 기능이다. 맵리듀스는 기본적으로 입력 데이터의 키를 기준으로 정렬되기 때문에, 하나의 Reduce Task만 실행되게 한다면 정렬을 쉽게 해결하는 것도 가능할 것이다. 다만, 여러 데이터노드가 구성
8.하둡 프로그래밍 - Partial Sort
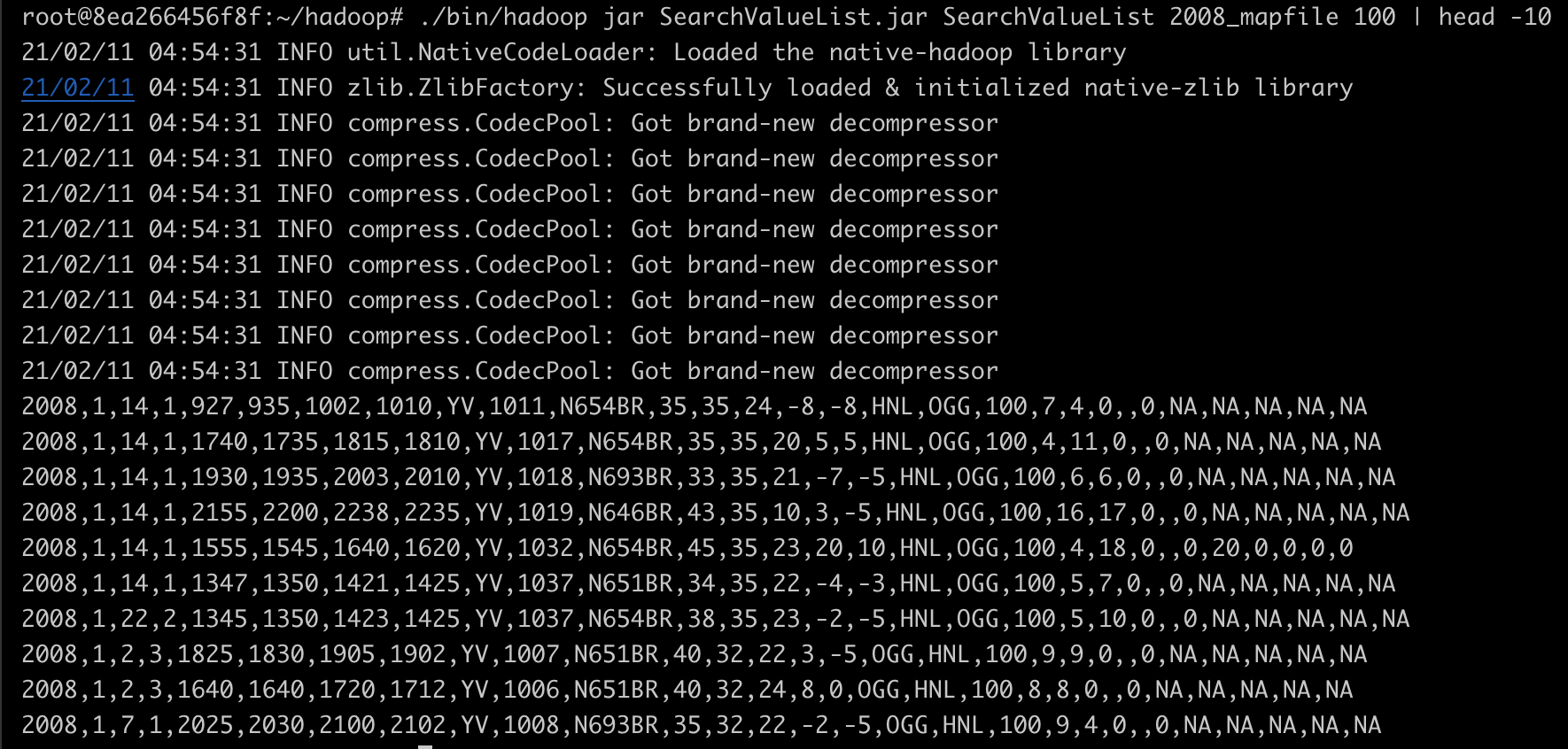
부분 정렬 (Partial Sort) 부분 정렬(Partial Sort)은 사실 정렬보다는 검색에 가깝다. 이 정렬 방식은 Mapper의 출력 데이터를 맵 파일(Map File)로 변경해 데이터를 검색하는 것이다. Map Task가 실행될 때 파티셔너는 Mapper의