부분 정렬 (Partial Sort)
부분 정렬(Partial Sort)은 사실 정렬보다는 검색에 가깝다. 이 정렬 방식은 Mapper의 출력 데이터를 맵 파일(Map File)로 변경해 데이터를 검색하는 것이다.
Map Task가 실행될 때 파티셔너는 Mapper의 출력 데이터가 어떤 Reduce Task로 전달될지 결정하고, 파티셔닝된 데이터는 키에 따라 정렬되게 된다. 부분 정렬을 하기 위해서는 파티셔닝된 출력 데이터를 맵 파일로 변경해야 한다. 특정 키에 대한 데이터를 검색하고 싶은 경우 해당 키에 대한 데이터가 저장된 맵 파일에 접근해 데이터를 조회하게 된다. 이러한 단계는 다음과 같다.
- Input Data를 Sequence File로 생성한다.
- Sequence File을 Map File로 변경한다.
- Map File에서 데이터를 검색한다.
여기서 주의할 점이 있다. 부분 정렬은 org.apache.hadoop.mapred 패키지를 사용해 개발해야 한다.
Create Sequence File
public class SequenceFileCreator extends Configured implements Tool {
static class DistanceMapper extends MapReduceBase implements Mapper<LongWritable, Text, IntWritable, Text> {
private IntWritable outputKey = new IntWritable();
@Override
public void map(LongWritable key, Text value, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
try {
AirlinePerformanceParser parser = new AirlinePerformanceParser(value);
if(parser.isDistanceAvailable()) {
outputKey.set(parser.getDistance());
output.collect(outputKey, value);
}
}
catch(ArrayIndexOutOfBoundsException e) {
outputKey.set(0);
output.collect(outputKey, value);
e.printStackTrace();
}
catch(Exception e) {
outputKey.set(0);
output.collect(outputKey, value);
e.printStackTrace();
}
}
}
@Override
public int run(String[] args) throws Exception {
JobConf conf = new JobConf(SequenceFileCreator.class);
conf.setJobName("SequenceFileCreator");
conf.setMapperClass(DistanceMapper.class);
conf.setNumReduceTasks(0);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
// 입출력 경로 설정
conf.setOutputFormat(SequenceFileOutputFormat.class);
// 출력 포맷을 SequenceFile로 설정
conf.setOutputKeyClass(IntWritable.class);
// 출력 키를 항공 운항 거리(IntWritable)로 설정
conf.setOutputValueClass(Text.class);
// 출력 값을 라인(Text)으로 설정
SequenceFileOutputFormat.setCompressOutput(conf, true);
SequenceFileOutputFormat.setOutputCompressorClass(conf, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(conf, SequenceFile.CompressionType.BLOCK);
// 시퀀스 파일 압축 포맷 설정
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new SequenceFileCreator(), args);
System.out.println("MR-Job Result : " + res);
}
}우선적으로, Mapper의 입력 데이터를 연산하지 않기 때문에 Reducer는 필요하지 않다. 해당 코드에서 Reduce Task를 0으로 설정한 모습을 볼 수 있다. 해당 코드를 실행시켜 입력 데이터의 출력 포맷을 Sequence File로 하여 Sequence File을 생성하게 된다.
우선 Mapper를 Inner Class형태로 구현한다. 그 다음 데이터가 누락되어 있는 경우를 대비하여 예외 처리를 해주도록 한다. 이 때의 항공 운항 거리는 0으로 설정한다.
출력 키는 항공 운항 거리로 설정하고, 출력 값은 라인으로 설정한다.
위 코드를 실행시키면 사용자가 입력한 출력 디렉토리에 Sequence File이 아래와 같이 생성되어 있을 것이다. 편의상 2008년의 데이터만 실행하였다. 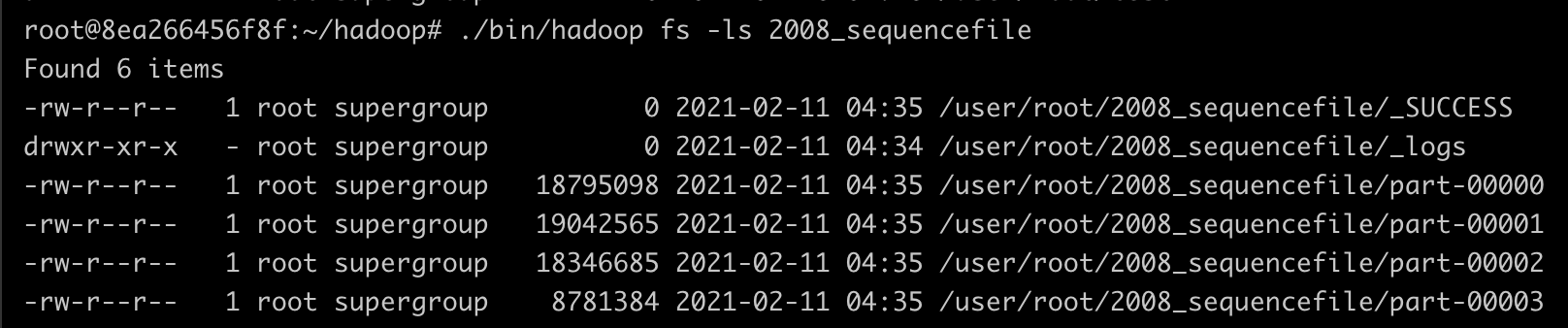
해당 파일을 확인해 보면 출력키로 항공 운항 거리, 출력값으로 라인이 출력되었음을 알 수 있다.
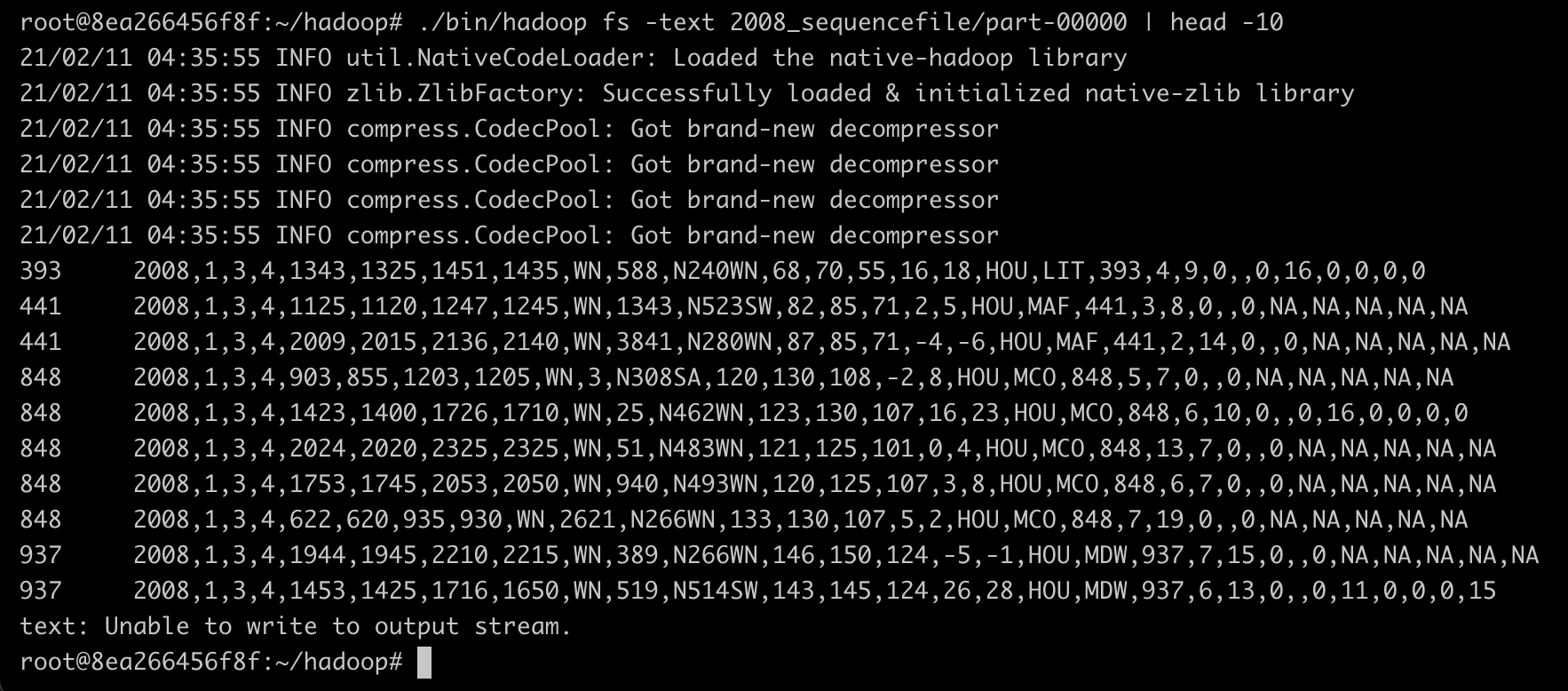
Create Map File
Sequence File을 생성했으므로 이제 Map File을 생성해 보자. 이번엔 입력 데이터를 Sequence File로 설정하고, 출력 데이터를 Map File로 설정하면 된다.
public class MapFileCreator extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MapFileCreator(), args);
System.out.println("MR-Job Result : " + res);
}
@Override
public int run(String[] args) throws Exception {
JobConf conf = new JobConf(MapFileCreator.class);
conf.setJobName("MapFileCreator");
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
// 입출력 경로 설정
conf.setInputFormat(SequenceFileInputFormat.class);
// 입력 데이터를 시퀀스 파일로 설정한다. 왜냐하면 이전 단계에서 시퀀스 파일로 생성했고, 이를 맵 파일로 변경해야 하기 때문이다.
conf.setOutputFormat(MapFileOutputFormat.class);
// 출력 데이터를 맵 파일로 설정
conf.setOutputKeyClass(IntWritable.class);
// 출력 데이터의 키값을 항공 운항 거리(IntWritable)로 설정
SequenceFileOutputFormat.setCompressOutput(conf, true);
SequenceFileOutputFormat.setOutputCompressorClass(conf, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(conf, SequenceFile.CompressionType.BLOCK);
// 시퀀스 파일 압축 포맷 설정
JobClient.runJob(conf);
return 0;
}
}데이터를 분석할 필요가 없으므로 Mapper와 Reducer Class를 지정하지 않는다. 별도로 지정하지 않는 경우, org.apache.hadoop.mapred.Mapper, org.apache.hadoop.Reducer을 기본값으로 설정하게 된다. 이제 코드를 실행해 보도록 한다.
코드를 실행하게 되면 아래와 같이 성공적으로 Map File이 생성되었음을 볼 수 있다.

그렇다면, part-00000 폴더를 조회해 보자.

위처럼 Map File의 규격에 맞게 데이터 파일과 인덱스 파일이 정상적으로 생성되어 있음을 확인할 수 있다. 이제 데이터 파일을 조회해 보자.
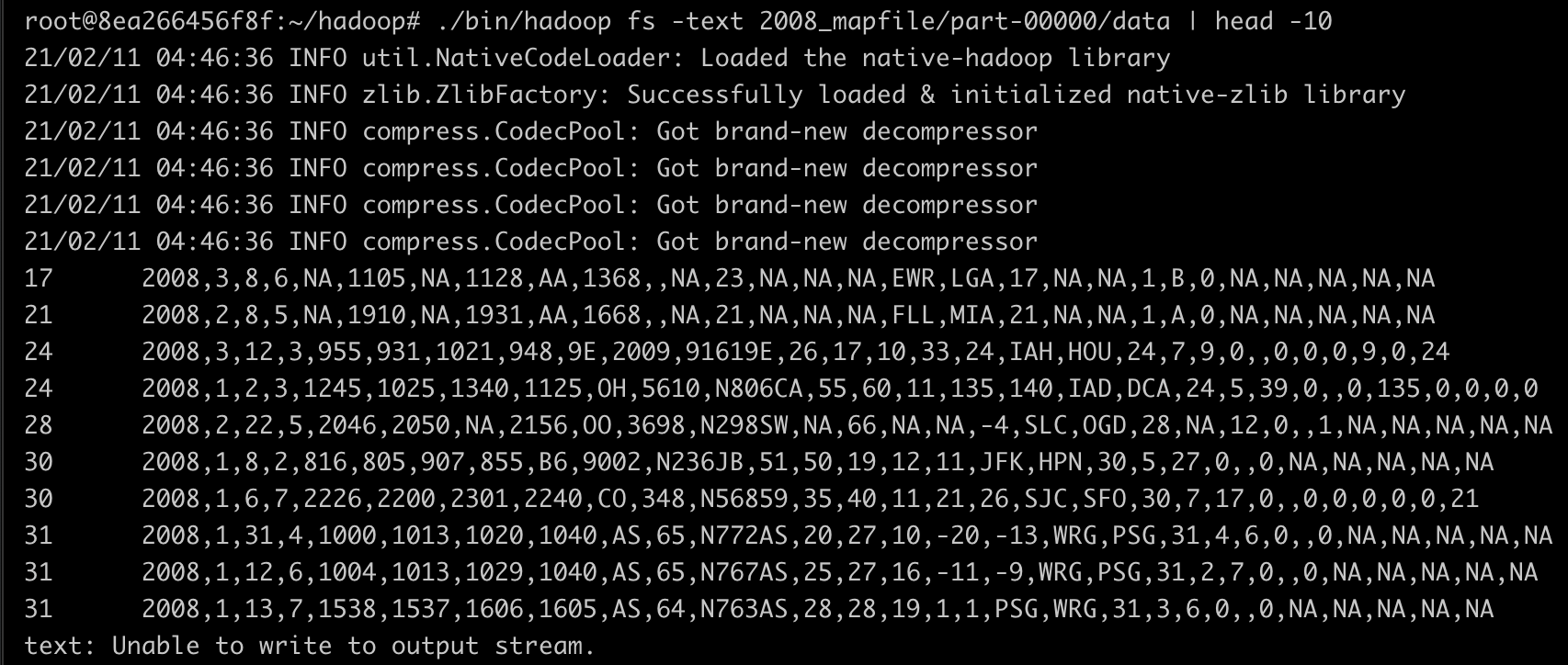
검색 프로그램 구현
파일을 Map File로 변경하는 데 성공했으므로, 이제 검색하는 방법에 대해 알아보도록 한다. 우선적으로 알아둬야 할 사항은, 검색 프로그램이 맵리듀스가 아니라는 것이다. 검색의 키는 파티셔너이다. 따라서, 키가 속하는 파티션 번호를 조회한 후 파티션 번호를 이용해 Map File에 접근하여 해당 키를 가진 데이터를 조회하면 될 것이다.
public class SearchValueList extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new SearchValueList(), args);
System.out.println("MR-Jobs Result : " + res);
}
@Override
public int run(String[] args) throws Exception {
Path path = new Path(args[0]);
FileSystem fs = path.getFileSystem(getConf());
MapFile.Reader[] readers = MapFileOutputFormat.getReaders(fs, path, getConf());
// 맵파일 조회
IntWritable key = new IntWritable();
key.set(Integer.parseInt(args[1]));
// 검색 키를 저장할 객체를 선언한다. 사용자가 입력한 운항 거리를 선언하는 것이다. 맵파일의 키가 운항 거리이기 때문이다.
Text value = new Text();
// 검색 값을 저장할 객체를 선언한다.
Partitioner<IntWritable, Text> partitioner = new HashPartitioner<IntWritable, Text>();
MapFile.Reader reader = readers[partitioner.getPartition(key, value, readers.length)];
// 파티셔너를 이용해 검색 키가 저장된 맵 파일을 조회한다.
// 이전 단계에서 맵 파일이 해시 파티셔너로 파티셔닝됐기 때문에 해시 파티셔너를 사용한다.
// getPartition 메소드는 특정 키에 대한 파티션 번호를 반환하게 된다.
Writable entry = reader.get(key, value);
// get 메소드를 사용하여 특정 키에 해당되는 값을 검색한다. 이 때, 검색되는 값은 첫 번째 값이다.
if(entry == null)
System.out.println("The requested key was not found.");
// 검색 결과 확인
// 첫 번째 값이 존재하지 않는다면 키에 해당되는 값이 없는 것이므로 위와 같이 출력한다.
IntWritable nextKey = new IntWritable();
do {
System.out.println(value.toString());
} while (reader.next(nextKey, value) && key.equals(nextKey));
// 맵 파일을 순회하며 키와 값을 출력한다.
// 검색된 값이 존재한다면 do/while문으로 순회하면서 맵 파일에 있는 모든 데이터를 조회하게 된다.
// 이 때, next 메소드는 다음 순서의 데이터로 위치를 이동하고, key와 value의 파라미터에 현재 위치의 값을 설정하게 된다.
return 0;
}
}코드에 대한 자세한 설명은 주석을 참고하도록 한다.
위 코드를 실행시키기 이전에, Map File을 생성했던 출력 디렉토리에서 로그 파일 디렉토리를 모두 삭제해야 한다. 로그 파일 때문에 Map File을 찾을 수 없다는 에러가 발생할 수 있기 때문이다.
위 코드를 실행해 보자.
./bin/hadoop jar SearchValueList.jar SearchValueList 2008_mapfile 100 | head -10거리가 100 마일인 항공 운항 거리를 검색하는 것이다.
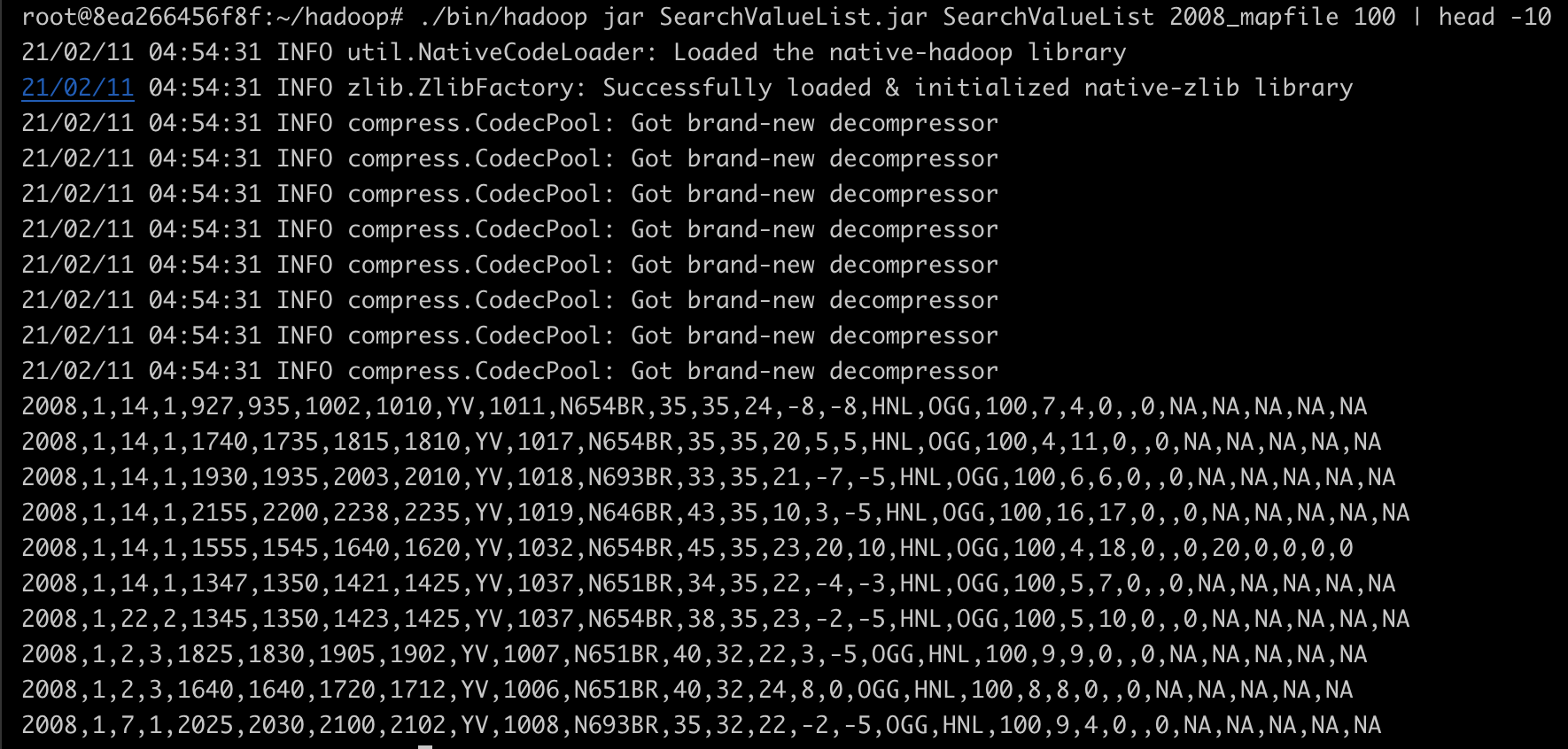
출력 결과는 위와 같다.
결론
결과적으로, 부분 정렬은 정렬보단 검색에 가깝다. 따라서, 내가 원하는 데이터를 찾아야 하는 경우 부분 정렬을 사용하여 특정 키에 해당되는 값을 검색하도록 하면 될 것이다.
