데브 경수 - 만화








ㅋㅋ 넘 기여워서 가져와봄 아무튼~ 시작 해보쟈
naver.com 을 치면?
주소창에 치고 enter를 눌렀다면 무슨 일이 일어날까~
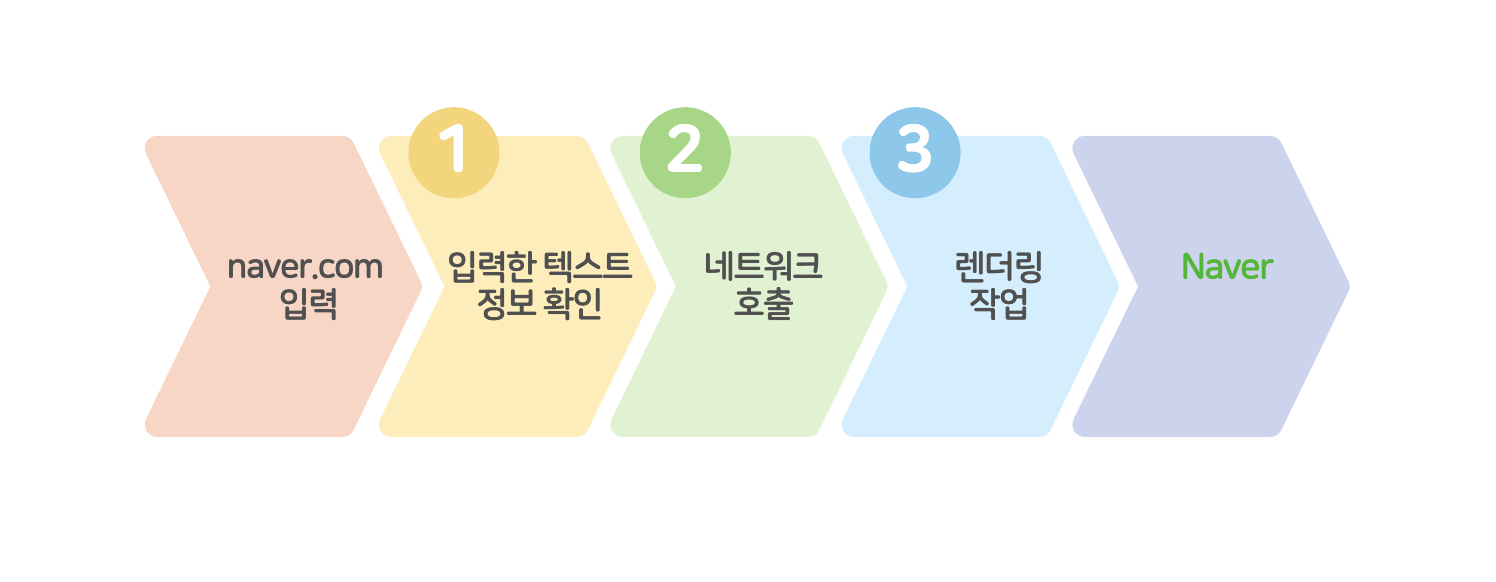
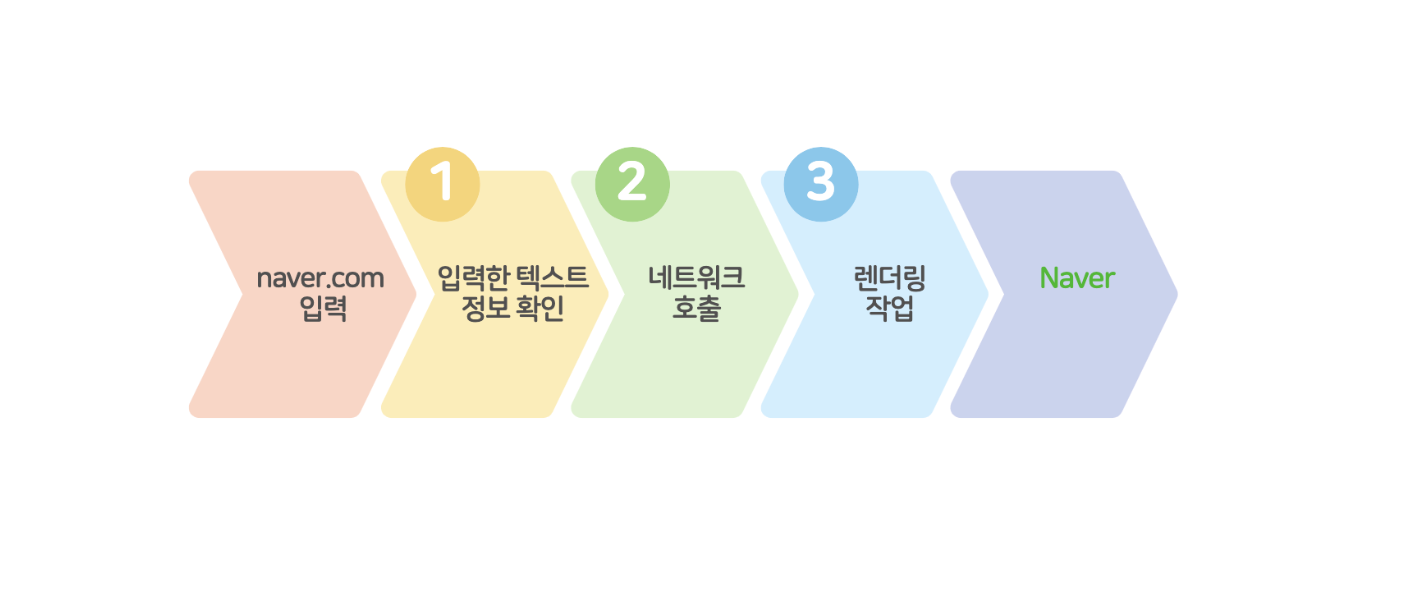
3개의 단계로 나누어 볼 수 있다 ~
아 내가 만든 단계표인데 네이버 위치 왜저래? 개빡친다 수정할 수도 없고
1️⃣ 주소창에 입력한 텍스트 정보 확인
인터넷 브라우저는 대부분 자사의 주소창을 검색창과 동일하게 사용 중이다. 대표적인 웹 브라우저 Chrome은 주소창을 구글의 검색창으로도 쓰고있다.
오 생각해보니 그렇네
브라우저는 사용자가 주소창에 어떤 텍스트를 입력하면 검색어인지 URL인지 판단한다.
- 만약 검색어라면?
브라우저는 검색 엔진의 URL에 검색어를 포함한 주소로 페이지를 이동시킨다.- 만약 URL이라면?
브라우저 엔진에서 네트워크 스레드를 통해 네트워크 호출을 수행한다.
이 주제는 naver.com이라는 URL을 입력하므로 네트워크 호출을 수행한당.
2️⃣ 네트워크 호출
브라우저가 네트워크 호출을 수행하는 이유?
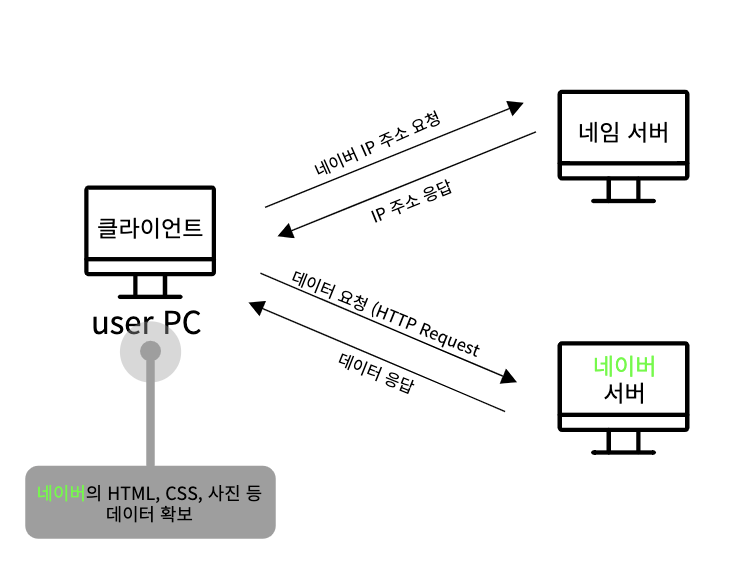
브라우저가 유저에게 네이버라는 사이트를 화면에 보여주려면 네이버의 HTML 문서, CSS 문서, 스크립트, 이미지 등등 데이터를 가지고 있어야한다.
하지만 현재 브라우저엔 이런 정보가 없고 이런 데이터들은 네이버 서버 컴퓨터에 존재한다.
그렇기에 네이버 서버와 네트워크 통신을 통해 데이터들을 가져와야한다. 그렇기에 서버가 어딘지 알아야 하니깐? 네이버 서버가 있는 컴퓨터의 IP 주소를 파악해야한다.
➔ 네이버 서버의 주소를 알기 위한 네임 서버(name server) 와 통신
➔ 알아낸 주소로 네이버 서버와 통신하여 원하는 데이터 받기
➔ 네이버 서버의 주소를 알기 위한 DNS 서버와 통신
브라우저는 캐시를 조회하여 해당 웹사이트의 IP 주소를 가지고 있는지 확인해본다.
요청된 도메인 네임의 IP 주소를 찾을 수 없다면 첫번째로 자신(로컬)의 host 파일에서 도메인 네임 (naver.com) 에 대응 하는 IP 주소가 있는지 확인한다.
URL이 host 파일 내에서도 발견되지 않으면 '네이버 IP 주소 알려줘' 라는 DNS 요청을 보낸다.
인터넷은 컴퓨터의 주소인 IP 주소를 기반으로 동작한다. 하지만 우리가 인터넷을 사용할 땐 사용하기 쉽도록 IP 주소 대신 사용하기 쉽도록 문자로 이루어진 도메인 네임을 사용한다.
그렇기에 도메인 네임 ➔ IP 주소로 변환해주는 환경 DNS(Domain Name System) 가 필요하며 이를 운영하는 장치를 DNS Server 혹은 Name Server 라고 한다.
네임 서버가 도메인 주소에 대응하는 IP 주소를 찾아준다. 클라이언트는 naver.com에 해당하는 IP 주소를 요청하고 응답 받을 수 있다.
➔ 알아낸 IP 주소로 네이버 서버와 통신하여 원하는 데이터 받기
자 이제 IP 주소를 알아냈다. 웹 사이트를 브라우저에 띄울 수 있게 웹 서버로부터 원하는 정보들을 받아야 한다.
어케 받아옴?
HTTP Request를 통해 요청하고
HTTP Response를 통해 받아오면 된다.
HTTP Request
인터넷 프로토콜을 사용해 해당 웹서버에 연결하기
인터넷 프로토콜을 여러 종류가 있지만, 웹 사이트의 HTTP 요청의 경우 일반적으로 TCP를 사용한다. TCP 커넥션을 위해 TCP 소켓을 연다.
네이버 서버의 IP 주소를 알게되면 주소와 포트 번호를 이용하여 시스템 라이브러리 함수를 호출해 TCP 소켓 스트림을 요청한다.
각 레이어에서는...
Transport layer - 출발지 포트를 커널의 동적 범위 포트에서 선택, 목적지 포트를 헤더에 추가
Network layer - 출발지와 목적지 서버의 IP 주소 등 추가적인 IP 헤더를 씌워 패킷 만듦
Link layer - 패킷에 MAC 주소 포함 프레임 헤더 추가
와 어카지 네트워크 계층들 이름만 기억나고 머하는지 하낫도 기억 안 남,,, (공부거리 +1)
TCP 3Way-Handshake
본격적으로 통신을 하기 전, Client와 Server가 잘 연결이 되었는지 확인하는 과정
(1) Client -> Server : TCP SYN 패킷을 서버에 보내 connection 요청
(2) Server -> Client : TCP SYN ACK으로 응답
(3) Client -> Server : TCP ACK 패킷을 보냄(SYN == Synchronize Sequence Numbers, ACK == Acknowledgement)
이러한 일종의 연결 검증 절차를 마치면 데이터를 주고 받을 준비가 끝난다.
HTTP Request를 Request Handler에게 전달하여 Request 내용을 읽고 Response를 생성한다.
그 후, HTTP Response를 JSON, XML, HTML 등의 특정 포맷으로 작성한다.
HTTP Response에 포함되는 정보
- Browser가 요청한 웹 페이지
- Status Code(현재 Response의 상태)
- Compression Type(Content-Encoding, 인코딩 방식)
- Cache-Control(페이지 캐싱 방법)
- (설정할 Cookie가 있다면) Cookie
- 개인 정보
- etc.
3️⃣ 렌더링 작업
네이버 서버로부터 응답받은 데이터는 바이트 형태의 텍스트 문서로, 브라우저 엔진이 읽을 수 없다.
따라서 브라우저 엔진(의 UI 스레드)은 렌더링 엔진에게 해당 데이터를 해석하고, 웹 페이지를 화면에 띄울 것을 요청한다.
요청을 받은 렌더링 엔진은 받은 데이터를 바탕으로 렌더링 프로세스를 수행하고, 이 과정이 끝나면 브라우저 엔진 에게 작업 완료를 알린다.
렌더링 프로세스
렌더링 엔진: 브라우저 엔진으로부터 요청받은 내용을 화면에 표시해주는 역할
- HTML을 파싱하여 DOM 트리 구축, CSS를 파싱하여 CSSOM 트리 구축 (+ JS 파싱)
- DOM 트리와 CSSOM 트리를 통해 랜더 트리 구축 (Attachment / 형상 구축)
- 랜더 트리 배치 (Layout / Reflow)
- 랜더 트리 그리기 (Paint)
파싱(Parsing) 이란?
문자 스트림을 브라우저가 이해할 수 있는 트리구조로 변환하는 과정
파싱(Parsing)의 2가지 종류
- 어휘 분석 (by 어휘 분석기) : 문자열을 의미있는 작은 단위인 토큰(token)으로 분해
- 구문 분석 (by 파서) : 문자열의 문법에 따라 토큰 간의 위계관계를 분석해 parsing tree를 생성
트리 형태
파싱 결과 생성되는 트리 형태를 parse 트리, parsing 트리, concrete syntax 트리 등 존재
1-1) HTML 파싱 ➔ DOM tree 생성
렌더링 엔진이 HTML 문서를 수신 받으면 HTML 파서가 파싱을 진행하고 그 결과물로 DOM 트리를 생성
- HTML 파싱 과정
-
서버에서 바이트 형태 HTML 문서 응답 받음
-
지정된 인코딩 방식(UTF-8) 에 따라 문자열로 변환
<meta charset="UTF-8">-
변환된 문자열 토큰으로 분해
-
토큰을 내용에 따라 객체(노드)로 변환
-
객체를 트리구조로 구성, DOM 생성
1-2) CSS 파싱 ➔ CSS DOM tree 생성
HTML 파싱 중 CSS 문서를 가져오는 link 태그를 만날 경우, DOM 생성이 잠시 중단되고 CSS 파싱이 시작된다.
CSS 문서 파싱 과정은 기본적으로 HTML 파싱 과정과 동일하며 CSS DOM tree의 노드는 DOM 트리 요소의 선택자에 맞춰 적용될 CSS 스타일 정보가 포함되어 있다.
1-3) Javascript 파싱
파싱 과정중 script 태그를 만나면 DOM 생성을 잠시 중지하고 서버에서 해당 자바스크립트 리소스를 브라우저 엔진으로부터 받아와 자바스크립트 엔진에게 제어권을 넘긴다.
자바스크립트 엔진을 자스 리소스를 파싱하여 추상 구문 트리(AST) 를 생성하고 이를 바이트 코드로 변환해 실행한다.
이 과정이 종료되면 다시 제어권을 돌려 받고 잠시 중지했던 DOM 생성을 이어간다.
DOM 조작 에러 위험을 방지하기 위해 script 태그는 body 태그의 가장 아래 위치해야 한다.
2. 렌더트리 구축
파싱 결과 만들어진 DOM tree, CSS DOM tree를 서로 결합하여 렌더 트리를 생성한다.
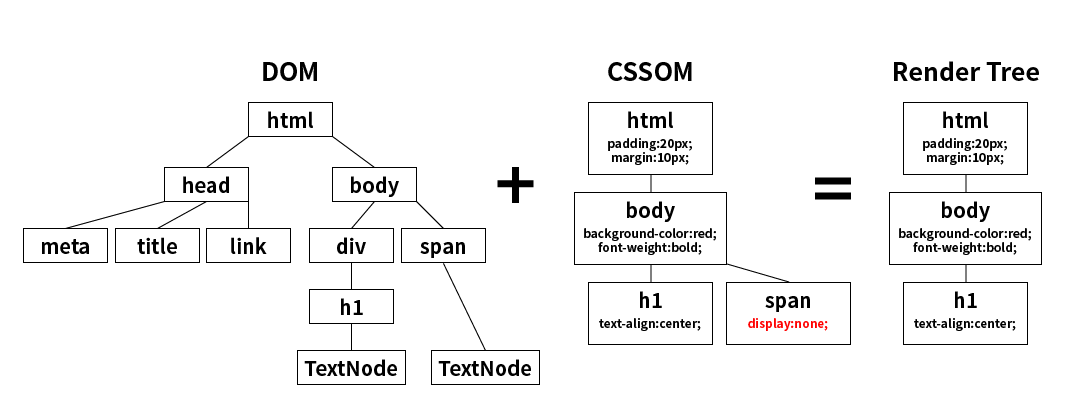 (DOM tree + CSS DOM tree = Render tree)
(DOM tree + CSS DOM tree = Render tree)
랜더트리 생성 과정
html태그,body태그를 처리해 랜더 트리 루트를 구성- DOM 의 최상위 노드 부터 순회하며 화면에서 보여지지 않는 노드는 구성에서 제외
- 화면에 보여지는 나머지 노드에 CSS DOM 규칙에 일치하는 CSS style 적용
3. 렌더트리 배치 (Layout)
생성된 랜더트리를 바탕으로 전체적인 웹 페이지 화면 안에서 각 노드 위치, 크기(너비와 높이)를 계산하고 화면에 배치하는 레이아웃 과정이 진행된다.
노드 위치는 (x,y) 좌표계 사용, 최상의 노드위치는 (0,0)
레이아웃은 전체의 배치과정이 필요한 경우인 글로벌 레이아웃,
일부의 배치과정만 변경되는 경우인 로컬 레이아웃으로 구분할 수 있다.
글로벌 레이아웃은 맨처음 레이아웃이 발생할 때, 초기 배치 이후 font 와 같은 전역 스타일이 변경되거나 창이 리사이즈 될 때 발생한다. 초기 배치 이후 레이아웃 작업을 다시 발생하는 것을 리플로우(Reflow)라고 한다.
로컬 레이아웃은 초기 레이아웃 이후 일부 DOM 노드에 변경이 생기는 것처럼, 특정 부분만 재배치가 필요한 상황일 때 발생한다. 전체 배치 과정이 다시 일어나 불필요한 낭비 발생을 막는다.
4. 렌더트리 그리기 (Paint)
마지막으로, 레이아웃 과정에서 계산된 정보들을 바탕으로 각 노드를 화면에 그려주는 paint 과정이 진행된다.
Paint는 렌더트리의 각 노드를 화면의 실제 픽셀로 변환해주는 작업이다. 픽셀로 변환하는 이과정을 래스터화 (Rasterizing) 라고 한다.
페인트 과정이 끝나면 브라우저 화면에 네이버 페이지가 보여지며 브라우저에서 특정 변경 사항이 생긴다면 다시 그려줘야한다. 그렇게 다시 페인트를 하는 과정이 생기는 것을 Repaint라고 하며 리플로우가 일어나면 기본적으로 리페인트도 같이 일어난다.
그렇게 페인트 과정까지 모두 끝나면 드디어 우리는 네이버 페이지를 볼 수 있게 된다.
이 모든 과정이 1초도 안되는 시간 안에 일어난다..!
위과정을 FE 관점과 BE 관점에서 생각해보기
FE에서는...
프론트엔드에서는 Front 라는 말에 맞게 사용자가 직접 보고 확인할 수 있는 부분이다.
웹 브라우저를 통해 요청을 보내는 것, 응답을 받고 해독하여 반영하는 부분까지 프론트엔드로 본다.
즉 유저의 naver.com 홈페이지를 보여달라는 요청을 수행하기 위해 필요한 데이터, 리소스를 서버에서 조회하여 화면에 띄우는 역할이다.
BE에서는 ...
백엔드는 프론트엔드와 반대의 개념이다. 사용자의 눈에 보이지 않아 직접 보고 확인할 수 없는 부분이다.
프론트엔드에서 보내준 요청을 처리하고, 다시 응답을 제공해주는 부분을 의미하고 있다. 프론트에서 요청하는 리소스들을 가공하여 내어주는 역할인 것이다.
도움을 주신 분1 - 주소창에 www.naver.com을 쳤을 때 생기는일
도움을 주신 분2 - 브라우저 주소창에 www.naver.com을 치면 일어나는 일
도움을 주신 분3
도움을 주신분4 -웹 브라우저의 동작원리를 알아보자
