컨테이너화된 앱 업데이트는 컨테이너 오케스트레이터에서 관리하는 제로 다운타임 프로세스여야 합니다. 일반적으로 클러스터에는 관리자가 업데이트 중에 새 컨테이너를 예약하는 데 사용할 수 있는 예비 컴퓨팅 성능이 있으며 컨테이너 이미지에는 상태 확인 기능이 있어 클러스터에서 새 구성 요소가 실패하는지 알 수 있습니다. 이것들은 제로 다운타임 업데이트를 가능하게 하는 요소이며 이미 13장에서 Docker Swarm 스택 배포 프로세스를 완료했습니다. 업데이트 프로세스는 고도로 구성 가능하며 이 장에서 구성 옵션을 탐색하는 데 시간을 할애할 것입니다.
업데이트 구성 조정은 안전하게 건너뛸 수 있는 주제처럼 들릴 수 있지만 롤아웃의 작동 방식과 기본 동작을 수정할 수 있는 방법을 이해하지 못하면 고통을 유발할 수 있다는 제 경험을 통해 말씀드릴 수 있습니다. 이 장에서는 Docker Swarm에 중점을 두지만 모든 오케스트레이터에는 유사한 방식으로 작동하는 단계적 출시 프로세스가 있습니다. 업데이트 및 롤백이 작동하는 방식을 알면 업데이트가 성공적으로 작동하거나 자동으로 이전 버전으로 롤백될 것이라는 확신을 갖고 원하는 만큼 자주 프로덕션에 배포할 수 있도록 앱에 적합한 설정을 찾기 위해 실험할 수 있습니다.
14.1 Docker를 사용한 애플리케이션 업그레이드 프로세스
Docker 이미지는 아주 단순한 패키징 형식입니다. 이미지를 빌드하고 컨테이너에서 앱을 실행하면 배포할 새 버전의 앱이 있을 때까지 실행할 수 있지만 고려해야 할 배포 단계가 4개 이상 있습니다. 먼저 자체 앱과 의존성이 있고, 앱을 빌드하는 SDK, 실행되는 앱 플랫폼, 마지막으로 OS가 있습니다. 그림 14.1은 실제로 6개의 업데이트 주기가 있는 Linux용으로 빌드된 .NET Core 앱의 예를 보여줍니다.
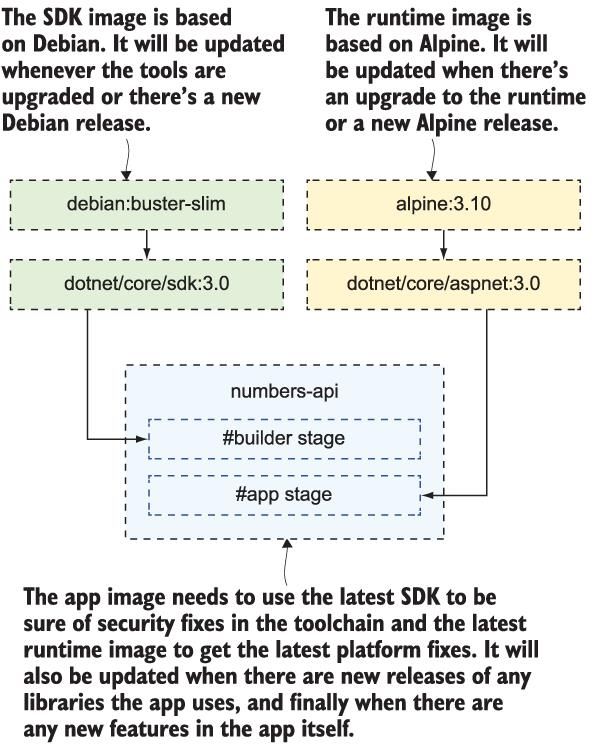
그림 14.1 Docker 이미지는 사용하는 다른 이미지를 포함할 때 많은 종속성을 갖습니다.
OS 업데이트를 다루기 위해 월별 일정에 따라 업데이트를 배포할 계획을 세우고 앱이 사용하는 라이브러리의 보안 수정 사항을 다루기 위해 언제든지 임시 배포를 시작하는 것이 편안해야 함니다. 이것이 빌드 파이프라인이 프로젝트의 핵심인 이유입니다. 파이프라인은 소스 코드에 대한 변경 사항이 푸시될 때마다 실행되어야 합니다. 그러면 새로운 앱 기능과 앱 종속성에 대한 수동 업데이트가 처리됩니다. 또한 매일 밤 빌드해야 하므로 항상 최신 SDK, 앱 플랫폼 및 OS 업데이트를 기반으로 릴리스 가능한 이미지를 빌드할 수 있습니다.
앱의 변경 여부에 관계없이 매달 주기적으로 릴리스하는 방식을 사용하면 조직 전체가 훨씬 더 건강한 사고 방식을 갖게 됩니다. 업데이트 릴리스는 일반적으로 사람이 개입하지 않고 항상 발생하는 지루한 일입니다. 정기적인 자동 릴리스가 있는 경우 각 업데이트는 프로세스에 대한 신뢰를 구축하고 다음 배포 창을 기다리지 않고 완료되는 즉시 새로운 기능을 릴리스한다는 사실을 인지하기 전에 새 기능을 릴리스합니다.
릴리스가 성공적일 때만 확신을 얻을 수 있으며, 이때 앱의 상태 확인이 중요합니다. 그들 없이는 안전한 업데이트 및 롤백을 할 수 없습니다. 이 장에서는 8장의 난수 앱을 사용하여 10장에서 배운 Docker Compose 재정의를 사용하여 이를 계속할 것입니다. 그러면 핵심 앱 정의가 포함된 깨끗한 단일 Compose 파일을 별도로 보관할 수 있습니다. 프로덕션 사양으로 파일을 작성하고 업데이트를 위한 추가 파일을 작성합니다. Docker는 여러 Compose 파일의 스택 배포를 지원하지 않으므로 먼저 Docker Compose를 사용하여 재정의 파일을 함께 조인해야 합니다.
TRY ch14/exercises에서 난수 앱의 첫 번째 빌드를 배포하는 것으로 시작하겠습니다. 단일 웹 컨테이너와 6개의 API 컨테이너 복제본을 실행하여 업데이트가 어떻게 출시되는지 확인할 수 있습니다. Swarm 모드에서 실행 중이어야 합니다. 그런 다음 일부 Compose 파일을 결합하고 스택을 배포합니다.
Join the core Compose file with the production override:
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml config > stack.yml
# deploy the joined Compose file:
docker stack deploy -c stack.yml numbers스택의 서비스를 확인
docker stack services numbers
numbers_numbers-api replicated 6/6 diamol/ch08-numbers-api:latest
numbers_numbers-web global 1/1 diamol/ch08-numbers-web:latest Docker Compose를 사용하여 재정의 파일을 함께 조인하는 것은 콘텐츠의 유효성도 검사하고 지속적인 배포 파이프라인의 일부가 될 수 있기 때문에 유용합니다. stack deploy는 오버레이 네트워크와 두 개의 서비스를 생성했습니다.
api는 replicated 모드에서 실행되지만 web은 global 모드에서 실행됩니다. 글로벌 서비스는 Swarm의 각 노드에서 단일 복제본으로 실행되며 해당 구성을 사용하여 수신 네트워크를 우회할 수 있습니다. 리버스 프록시와 같은 시나리오가 있지만 여기서는 롤아웃을 위해 복제된 서비스와 어떻게 다른지 볼 수 있도록 여기에서 사용하고 있습니다.
web 서비스에 대한 설정은 목록 14.1에 있습니다(prod.yml 재정의 파일에서 발췌).
목록 14.1 prod.yml에서 ingress 대신 호스트 네트워킹을 사용하는 global 서비스
numbers-web:
ports:
- target: 80
published: 80
mode: host
deploy:
mode: global이 새 구성에는 글로벌 서비스를 구성하는 두 개의 필드가 있습니다.
-
mode: global--deploy섹션의 이 설정은 Swarm의 모든 노드에서 하나의 컨테이너를 실행하도록 배포를 구성합니다. 복제본의 수는 노드의 수와 동일하며 노드가 조인되면 서비스에 대한 컨테이너도 실행됩니다. -
mode: host--port섹션의 이 설정은 수신 네트워크를 사용하지 않고 호스트의 포트 80에 직접 바인딩하도록 서비스를 구성합니다. 이것은 웹 앱이 노드당 하나의 복제본만 필요할 만큼 충분히 가볍지만 네트워크 성능이 중요하므로 수신 네트워크에서 라우팅 오버헤드를 원하지 않는 경우에 유용한 패턴이 될 수 있습니다.
이 배포는 상태 확인이 없는 원본 앱 이미지를 사용하며 API에 몇 번의 호출 후에 작동이 중지되는 버그가 있는 응용 프로그램입니다. http://localhost로 이동할 수 있으며 호출이 6개의 API 서비스 복제본 간에 로드 밸런싱되기 때문에 많은 난수를 요청할 수 있습니다. 결국 그것들은 모두 고장날 것이고 앱은 작동을 멈추고 스스로 수리하지 않을 것입니다. 클러스터는 컨테이너 상태가 좋지 않다는 것을 모르기 때문에 컨테이너를 교체하지 않습니다. 상태 확인 없이 업데이트된 버전을 출시하면 클러스터에서도 업데이트가 성공했는지 알 수 없기 때문에 안전한 위치가 아닙니다.
그래서 우리는 상태 확인이 내장된 버전 2의 앱 이미지를 배포할 것입니다. v2 Compose 재정의 파일은 v2 이미지 태그를 사용하며 상태 확인이 실행되는 빈도를 설정하기 위한 구성을 추가하는 재정의도 있습니다. 얼마나 많은 실패가 시정 조치를 유발하는지. 이는 Compose가 시정 조치를 취하지 않는다는 점을 제외하고 Docker Compose에서 동일한 방식으로 작동하는 일반 상태 확인 블록에 있습니다. 이 버전의 앱이 Docker Swarm에 배포되면 클러스터가 API를 복구합니다. API 컨테이너를 깨뜨리면 상태 확인에 실패하고 교체된 다음 앱이 다시 작동하기 시작합니다.
TRY 스택 배포 YAML을 얻으려면 상태 확인 및 프로덕션 재정의 파일과 함께 새로운 v2 Compose 재정의를 조인해야 합니다. 그런 다음 스택을 다시 배포하기만 하면 됩니다.
이전 파일에 대한 상태 확인 및 v2 재정의를 조인합니다.
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml -f ./numbers/prod-healthcheck.yml -f ./numbers/v2.yml --log-level ERROR config > stack.yml스택 업데이트:
docker stack deploy -c stack.yml numbers스택의 복제본을 확인합니다.
docker stack ps numbers이 배포는 웹 및 API 서비스를 해당 이미지의 버전 2로 업데이트합니다. 서비스 업데이트는 항상 단계적 출시로 수행되며 기본값은 새 컨테이너를 시작하기 전에 기존 컨테이너를 중지하는 것입니다. 이는 호스트 모드 포트를 사용하는 글로벌 서비스에 적합합니다. 이전 컨테이너가 종료되고 포트가 해제될 때까지 새 컨테이너를 시작할 수 없기 때문입니다. 애플리케이션이 최대 수준의 확장을 기대하는 경우 복제된 서비스에도 의미가 있을 수 있지만 업데이트하는 동안 오래된 컨테이너가 종료되고 교체가 시작되는 동안 서비스 용량이 부족하다는 점에 유의해야 합니다. 그림 14.3에서 그 동작을 볼 수 있습니다.
Docker Swarm은 서비스 업데이트 롤아웃에 신중한 기본값을 사용합니다. 한 번에 하나의 복제본을 업데이트하고 다음 복제본으로 이동하기 전에 컨테이너가 올바르게 시작되는지 확인합니다. 서비스는 교체를 시작하기 전에 기존 컨테이너를 중지하여 롤아웃하고 새 컨테이너가 올바르게 시작되지 않아 업데이트가 실패하면 롤아웃이 일시 중지됩니다.
책에서 권위 있는 어조로 제시하면 이 모든 것이 합리적으로 보이지만 실제로는 꽤 이상합니다. 새 컨테이너가 작동할지 알 수 없는데 왜 새 컨테이너를 시작하기 전에 이전 컨테이너를 제거하는 것을 기본으로 합니까? 자동으로 롤백하는 대신 시스템이 반쯤 망가질 수 있는 실패한 롤아웃을 일시 중지하는 이유는 무엇입니까? 다행히 롤아웃은 보다 합리적인 옵션으로 구성할 수 있습니다.
14.2 Compose로 프로덕션 롤아웃 구성
난수 앱 버전 2는 상태 확인으로 인해 자가 복구 중입니다. 웹 UI를 통해 많은 난수를 요청하면 API 복제본이 모두 중단되지만 20초 정도 기다리면 Swarm이 모두 교체하고 앱이 다시 작동하기 시작합니다. 이것은 극단적인 예이지만 가끔 오류가 발생하는 실제 애플리케이션에서 클러스터가 상태 확인을 기반으로 컨테이너를 모니터링하고 앱을 온라인 상태로 유지하는 방법을 볼 수 있습니다.
버전 2의 롤아웃은 기본 업데이트 구성을 사용했지만 API의 롤아웃이 더 빠르고 안전하기를 바랍니다. 해당 동작은 Compose 파일의 서비스에 대한 deploy 섹션에서 설정됩니다.
목록 14.2는 API 서비스에 적용하려는 update_config 섹션을 보여줍니다(이는 prod-update-config.yml 파일에서 발췌).
Listing 14.2 Specifying custom configuration for application rollouts
numbers-api:
deploy:
update_config:
parallelism: 3
monitor: 60s
failure_action: rollback
order: start-firstupdate_config 섹션의 네 가지 속성은 롤아웃 작동 방식을 변경합니다.
-
parallelism: 병렬로 대체되는 복제본의 수. 기본값은 1이므로 업데이트는 한 번에 하나의 컨테이너로 롤아웃됩니다. 여기에 표시된 설정은 한 번에 세 개의 컨테이너를 업데이트합니다. 더 많은 새 복제본이 실행되고 있기 때문에 더 빠르게 롤아웃하고 오류를 찾을 가능성이 높아집니다. -
monitor: 롤아웃을 계속하기 전에 Swarm이 새 복제본을 모니터링하기 위해 기다려야 하는 시간. 기본값은 0이고 이미지에 상태 확인이 있는 경우 Swarm이 이 시간 동안 상태 확인을 모니터링하기 때문에 확실히 변경하고 싶습니다. 이렇게 하면 롤아웃에 대한 신뢰도가 높아집니다. -
failure_action: 컨테이너가 모니터 기간 내에 시작되지 않거나 상태 확인에 실패하여 롤아웃이 실패한 경우 수행할 작업. 기본값은 롤아웃을 일시 중지하는 것입니다. 여기에서 이전 버전으로 자동 롤백하도록 설정했습니다. -
order: 복제본을 교체하는 순서.stop-first가 기본값이며 필요한 수보다 더 많은 복제본이 실행되지 않도록 보장하지만 앱이 추가 복제본과 함께 작동할 수 있는 경우 이전 복제본이 제거되기 전에 새 복제본이 생성되고 확인되기 때문에start-first가 더 좋습니다.
이 설정은 일반적으로 대부분의 앱에서 좋은 방법이지만 자신의 사용 사례에 맞게 조정해야 합니다. parallelism는 전체 복제본 수의 약 30%로 설정될 수 있으므로 업데이트가 상당히 빠르게 수행되지만 여러 상태 확인을 실행할 수 있을 만큼 충분히 긴 모니터링 기간이 있어야 다음 작업 세트가 이전 업데이트가 작동한 경우에만 업데이트됩니다.
한 가지 중요한 사항을 이해해야 합니다. 스택에 변경 사항을 배포할 때 업데이트 구성이 먼저 적용됩니다. 그런 다음 배포에 서비스 업데이트가 포함된 경우 새 업데이트 구성을 사용하여 롤아웃이 발생합니다.
TRY 다음 배포에서는 업데이트 구성을 설정하고 서비스를 이미지 태그 v3으로 업데이트합니다. 복제본 롤아웃은 새 업데이트 구성을 사용합니다.
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml -f ./numbers/prod-healthcheck.yml -f ./numbers/prod-update-config.yml -f ./numbers/v3.yml --log-level ERROR config > stack.yml
docker stack deploy -c stack.yml numbers
docker stack ps numbers몇 가지 업데이트를 수행하면 stack ps의 복제본 목록이 관리할 수 없을 정도로 커지는 것을 볼 수 있습니다. 모든 배포의 모든 복제본을 표시하므로 업데이트된 원본 컨테이너와 v2 컨테이너는 물론 새 v3 복제본도 표시됩니다. 그림 14.4에서 출력을 트리밍했지만, 아래로 스크롤하면 API 서비스의 3개 복제본이 업데이트되었으며 다음 세트가 업데이트되기 전에 모니터링되는 것을 볼 수 있습니다.
서비스 사양, 업데이트 구성 및 최신 업데이트 상태를 식별하는 Swarm 서비스에 대해 보고하는 더 깔끔한 방법이 있습니다. 그것은 pretty 플래그와 함께 inspect 명령을 사용하는 것입니다. 스택에 의해 생성된 서비스는 {stack-name}_{service-name} 명명 규칙을 사용하므로 스택 서비스를 직접 사용할 수 있습니다.
TRY 난수 API 서비스를 검사하여 업데이트 상태를 확인하십시오.
docker service inspect --pretty numbers_numbers-api주요 정보만 표시하기 위해 다시 잘라냈지만 출력을 스크롤하면 상태 확인 구성, 리소스 제한 및 업데이트 구성도 볼 수 있습니다.
UpdateStatus:
State: completed
Started: 3 minutes ago
Completed: About a minute ago
Message: update completed기본 업데이트 구성 설정을 변경할 때는 모든 후속 배포에 해당 설정을 포함해야 합니다. v3 배포에 사용자 지정 설정이 추가되었지만 다음 배포에 동일한 업데이트 파일을 포함하지 않으면 Docker는 서비스를 기본 업데이트 설정으로 되돌립니다. Swarm은 먼저 업데이트 구성을 변경하므로 업데이트 구성을 다시 기본값으로 설정한 다음 한 번에 한 복제본씩 다음 버전을 출시합니다.
Swarm 롤아웃에 대한 업데이트 구성 설정에는 롤백에 적용되는 동일한 집합이 있으므로 한 번에 복제본 수와 자동 롤백을 위해 집합 사이에 대기 시간을 구성할 수도 있습니다. 이것은 사소한 조정처럼 보일 수 있지만 프로덕션 배포를 위한 업데이트 및 롤백 프로세스를 지정하고 대규모 앱으로 테스트하는 것이 정말 중요합니다. 언제든지 업데이트를 출시할 수 있고 신속하게 적용되지만 문제가 있는 경우 자동으로 롤백할 수 있도록 충분한 확인을 거쳐야 합니다. 이러한 구성 설정을 사용하여 실패 시나리오를 처리함으로써 확신을 얻을 수 있습니다.
14.3 서비스 롤백 구성
docker stack rollback 명령이 없습니다. 개별 서비스만 이전 상태로 롤백할 수 있습니다. 심각한 문제가 발생하지 않는 한 서비스 롤백을 수동으로 시작할 필요가 없습니다. 클러스터가 롤아웃을 수행하고 모니터링 기간 내에 새 복제본에 장애가 있음을 식별하면 롤백이 자동으로 발생해야 합니다. 그런 일이 발생하고 구성이 올바른 경우 새 기능이 표시되지 않는 이유가 궁금할 때까지 롤백이 발생했음을 인식하지 못할 것입니다.
모든 것이 자동화된 경우에도 여전히 자동화 스크립트와 애플리케이션 YAML 파일을 작성하는 사람이 있고 때로는 잊어버리기 때문에 애플리케이션 배포가 다운타임의 주요 원인입니다. 난수 앱으로 새 버전을 배포할 준비가 되었지만 설정해야 하는 구성 옵션이 있음을 경험할 수 있습니다. 설정하지 않으면 API가 즉시 실패합니다.
TRY 난수 앱의 v5를 실행합니다(v4는 11장에서 지속적 통합을 시연하기 위해 사용한 버전이지만 v3과 동일한 코드를 사용했습니다). v5에 필요한 구성 설정이 Compose 파일에 제공되지 않았기 때문에 이 배포는 실패합니다.
# join lots of Compose files together
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml -f ./numbers/prod-healthcheck.yml -f ./numbers/prod-update-config.yml -f ./numbers/v5-bad.yml config > stack.yml
# deploy the update:
docker stack deploy -c stack.yml numbers
# wait for a minute and check the service status:
docker service inspect --pretty numbers_numbers-api이것은 일반적인 실패한 배포입니다. 새 API 복제본이 생성되어 성공적으로 시작되었지만 상태 확인에 실패했습니다. 상태 확인 구성은 컨테이너를 비정상으로 플래그 지정하기 전에 2초마다 실행하도록 설정되어 있습니다. 롤아웃의 모니터링 기간 동안 새 복제본이 비정상으로 보고되면 롤백 작업이 트리거됩니다. 이 작업은 이 서비스가 자동으로 롤백하도록 설정했습니다. 서비스를 검사하기 전에 배포 후 30초 정도 기다리면 업데이트가 롤백되었고 서비스가 v3 이미지의 6개 복제본을 실행하고 있다는 출력이 표시됩니다.
Labels:
com.docker.stack.image=diamol/ch08-numbers-api:v3
com.docker.stack.namespace=numbers
Service Mode: Replicated
Replicas: 6
UpdateStatus:
State: rollback_completed
Started: 29 seconds ago
Message: rollback completed배포가 잘못되면 재미가 없지만 자동으로 롤백되는 이와 같은 실패한 업데이트는 최소한 앱을 계속 실행하게 합니다. 시작 우선 출시 전략을 사용하면 도움이 됩니다. 기본 stop-first 를 사용한 경우 3개의 v3 복제본이 중지된 다음 3개의 v5 복제본이 시작되고 실패할 때 일정 기간 동안 용량이 감소합니다. 새 복제본이 자신을 비정상으로 표시하고 롤백이 완료되는 데 걸리는 시간에는 API의 활성 복제본이 3개뿐입니다. Docker Swarm은 정상적이지 않은 복제본에 트래픽을 보내지 않지만 API는 50% 용량으로 실행되기 때문에 사용자에게 오류가 표시되지 않습니다.
이 배포는 업데이트에 대한 기본 구성과 동일한 롤백에 대한 기본 구성을 사용합니다. 우선 중지 전략을 사용하는 한 번에 하나의 작업, 모니터링 시간 0, 교체 복제본이 실패하면 롤백이 일시 중지됩니다. 앱이 제대로 작동하고 배포가 중단된 상황에서는 일반적으로 가능한 한 빨리 이전 상태로 롤백하기를 원하기 때문에 너무 조심스럽습니다.
Listing 14.3은 이 서비스에 대해 선호하는 롤백 구성을 보여줍니다(prod-rollback-config.yml 에서).
numbers-api:
deploy:
rollback_config:
parallelism: 6
monitor: 0s
failure_action: continue
order: start-first여기서 목표는 가능한 한 빨리 되돌리는 것입니다. 병렬 처리는 6이므로 실패한 모든 복제본은 시작 우선 전략을 사용하여 한 번에 교체되므로 롤백이 종료에 대해 걱정하기 전에 이전 버전의 복제본이 시작됩니다. 새 버전의 복제본. 모니터링 기간이 없으며 롤백이 실패하면(레플리카가 시작되지 않아) 어쨌든 계속하도록 설정됩니다. 이것은 이전 버전이 양호했으며 복제본이 시작되면 다시 양호해질 것이라고 가정하는 적극적인 롤백 정책입니다.
TRY 사용자 지정 롤백 구성을 지정하여 v5 업데이트를 다시 시도합니다. 이 롤아웃은 여전히 실패하지만 롤백이 더 빨리 발생하여 v3 API에서 앱을 최대 용량으로 되돌립니다.
# join together even more Compose files:
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod.yml -f ./numbers/prod-healthcheck.yml -f ./numbers/prod-update-config.yml -f ./numbers/prod-rollback-config.yml -f ./numbers/v5-bad.yml config > stack.yml
# deploy the update again with the new rollback config:
docker stack deploy -c stack.yml numbers
# wait and you'll see it reverts back again:
docker service inspect --pretty numbers_numbers-api이번에는 롤백이 더 빠르게 발생하는 것을 볼 수 있지만 API 서비스에 있는 복제본이 소수에 불과하고 모두 단일 노드에서 실행되기 때문에 미미합니다. 20개의 노드에서 실행되는 100개의 복제본이 있을 수 있는 대규모 배포에서 이것이 얼마나 중요한지 알 수 있습니다. 각 복제본을 개별적으로 롤백하면 앱이 용량 미만으로 실행되거나 불안정한 상태에서 실행될 수 있는 시간이 길어집니다. 그림 14.7에서 내 출력을 볼 수 있습니다. 이번에는 롤백이 트리거된 것처럼 빠르게 포착하여 상태가 롤백이 시작되고 있음을 보여줍니다.
UpdateStatus:
State: rollback_started
Started: 15 seconds ago
Message: update rolled back due to failure or early termination of task qlgmm11ptqabz8sfi7gwqlek5이것을 직접 실행할 때 롤백이 완료되었을 때 전체 서비스 구성을 살펴보십시오. 롤백 구성이 기본값으로 재설정되었음을 알 수 있습니다. 롤백 구성이 적용되지 않았다고 생각할 것이기 때문에 혼란이 보장됩니다. 그러나 실제로는 전체 서비스 구성이 롤백되었기 때문입니다. 여기에는 롤백 설정이 포함됩니다. 복제본이 새 정책에 따라 롤백된 다음 롤백 정책이 롤백되었습니다. 다음에 배포할 때 업데이트 및 롤백 구성을 계속 추가해야 합니다. 그렇지 않으면 기본 설정으로 다시 업데이트됩니다.
여러개의 재정의 파일이 있는 것이 위험한 이유는 모두 필요하고 올바른 순서로 지정해야 하기 때문입니다. 일반적으로 한 환경에 대한 설정을 여러 파일에 분할하지 않습니다. 업데이트 및 롤백 과정을 더 쉽게 따라갈 수 있도록 하기 위해 그렇게 했습니다. 일반적으로 핵심 Compose 파일, 환경 재정의 파일 및 버전 재정의 파일이 있을 수 있습니다. v5 문제를 수정하고 앱이 다시 작동하도록 하여 최종 배포에 이 접근 방식을 사용할 것입니다.
TRY v5 업데이트가 실패하고 롤백되었습니다. 그래서 우리는 팀을 모아 중요한 구성 설정을 놓쳤다는 것을 깨달았습니다. v5.yml 재정의 파일은 이를 추가하고 prod-full.yml 재정의 파일에는 모든 프로덕션 설정이 한 곳에 있습니다. 이제 v5를 성공적으로 배포할 수 있습니다.
# this is more like it - all the custom config is in the prod-full file:
docker-compose -f ./numbers/docker-compose.yml -f ./numbers/prod-full.yml -f ./numbers/v5.yml --log-level ERROR config > stack.yml
# deploy the working version of v5:
docker stack deploy -c stack.yml numbers
# wait a while and check the rollout succeeded:
docker service inspect --pretty numbers_numbers-apiService Mode: Replicated
Replicas: 6
UpdateStatus:
State: completed
Started: 3 minutes ago
Completed: 2 minutes ago
Message: update completed이제 v5가 모든 영광으로 실행되고 있습니다. 실제로는 이전과 동일한 간단한 데모 앱이지만 롤백에 대한 마지막 요점을 설명하는 데 사용할 수 있습니다. 이제 앱이 제대로 작동하고 상태 확인이 제자리에 있으므로 API를 계속 사용하고 복제본을 깨뜨리면 교체되고 앱이 다시 작동하기 시작합니다. 상태 확인에 실패해도 마지막 업데이트가 롤백되지 않습니다. 업데이트 모니터링 기간 동안 오류가 발생하지 않는 한 교체용 복제본만 트리거합니다. v5를 배포하고 60초 모니터링 기간 동안 API 컨테이너를 중단하면 롤백이 트리거됩니다. 그림 14.9는 v3에서 v5로 업데이트할 때의 업데이트 및 롤백 프로세스를 보여줍니다.
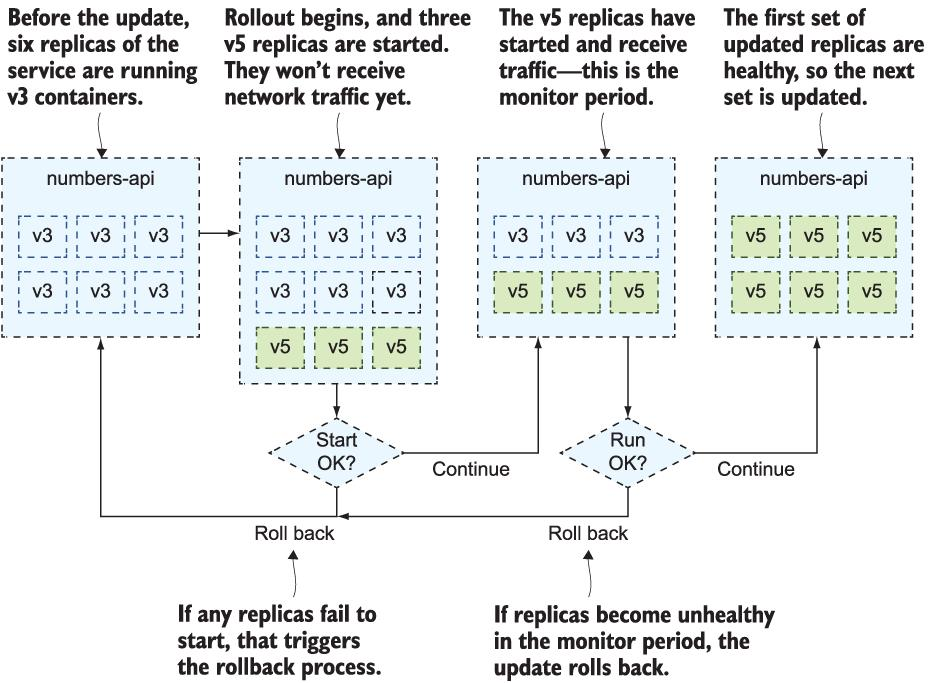
그림 14.9 이것은 순서도처럼 보이지만 업데이트 프로세스를 모델링하는 데 유용한 방법일 뿐입니다.
업데이트 및 롤백 구성을 위한 것입니다. Compose 파일의 배포 섹션에서 몇 가지 값을 설정하고 업데이트가 빠르고 안전하며 문제가 있는 경우 빠르게 롤백되는지 확인하기 위해 변형을 테스트하는 경우입니다. 이는 애플리케이션의 가동 시간을 최대화하는 데 도움이 됩니다. 클러스터에 있는 노드의 가동 중지 시간이 있을 때 가동 시간이 어떻게 영향을 받는지 이해하는 것만 남았습니다.
14.4 클러스터의 다운타임 관리
컨테이너 오케스트레이터는 여러 대의 머신을 강력한 클러스터로 전환하지만 궁극적으로 컨테이너를 실행하는 것은 머신이며 다운타임이 발생하기 쉽습니다. 디스크, 네트워크 및 전원은 모두 어느 시점에서 실패할 것입니다. 클러스터가 클수록 정전이 더 자주 발생합니다. 클러스터는 대부분의 중단을 통해 앱을 계속 실행할 수 있지만 계획되지 않은 일부 오류에는 적극적인 개입이 필요하며 계획된 중단이 있는 경우 Swarm이 문제를 해결하기 쉽게 만들 수 있습니다.
이 섹션을 따르려면 다중 노드 Swarm이 필요합니다. 가상 머신을 만들고 Docker를 설치하는 것이 마음에 들면 직접 설정하거나 온라인 플레이그라운드를 사용할 수 있습니다. Play with Docker는 이를 위한 훌륭한 선택입니다. 다중 노드 Swarm을 생성하고 추가 머신 없이도 배포 및 노드 관리를 연습할 수 있습니다.
https://labs.play-with-docker.com 으로 이동하여 Docker Hub ID로 로그인하고 새 인스턴스 추가를 클릭하여 가상 Docker 서버를 온라인 세션에 추가합니다. 세션에 5개의 인스턴스를 추가했으며 Swarm으로 사용할 것입니다.
TRY Play with Docker 세션을 시작하고 5개의 인스턴스를 만드십시오. 왼쪽 탐색 목록에 인스턴스가 표시되며 클릭하여 선택할 수 있습니다. 기본 창에서 선택한 노드에 연결된 터미널 세션을 볼 수 있습니다.
Select node1 and initialize the Swarm using the node's IP address:
ip=$(hostname -i)
docker swarm init --advertise-addr $ipShow the commands to join managers to the Swarm:
$ docker swarm join-token manager
docker swarm join --token SWMTKN-1-4azz9ussbp4m4kykamv62krmev2tjyyww93fn1mr9j1mf414r6-dedpntriv9bj29cg6git4aj38 192.168.0.14:2377Show the commands to join workers to the Swarm:
$ docker swarm join-token worker
docker swarm join --token SWMTKN-1-4azz9ussbp4m4kykamv62krmev2tjyyww93fn1mr9j1mf414r6-0kohh81qv851t8oxbm5helf44 192.168.0.14:2377Select node2 and paste the manager join command, then the same on node3
docker swarm join --token SWMTKN-1-4azz9ussbp4m4kykamv62krmev2tjyyww93fn1mr9j1mf414r6-dedpntriv9bj29cg6git4aj38 192.168.0.14:2377Select node4 and paste the worker join command, then the same on node5
docker swarm join --token SWMTKN-1-4azz9ussbp4m4kykamv62krmev2tjyyww93fn1mr9j1mf414r6-0kohh81qv851t8oxbm5helf44 192.168.0.14:2377Back on node1 make sure all the nodes are ready:
docker node lsHOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
node1 Ready Active 20.10.0
node2 Ready Active 20.10.0
node3 Ready Active Reachable 20.10.0
node4 Ready Active Reachable 20.10.0
node5 Ready Active Leader 20.10.0
가장 간단한 시나리오를 먼저 살펴보겠습니다. 서버의 운영 체제 업데이트나 기타 인프라 작업을 위해 노드를 중단해야 합니다. 해당 노드는 컨테이너를 실행 중일 수 있으며 컨테이너를 정상적으로 종료하고 다른 노드에서 교체하고 시스템을 유지 관리 모드로 전환하여 Docker가 수행해야 하는 재부팅 주기 동안 새 컨테이너를 시도하고 예약하지 않기를 원할 수 있습니다.
Swarm의 노드에 대한 유지 관리 모드를 drain 모드라고 하며 관리자나 작업자를 드레이닝할 수 있습니다.
TRY node1 관리자의 터미널 세션으로 전환하고 다른 노드 중 두 개를 드레인 모드로 설정하십시오.
# set a worker and a manager into drain mode:
docker node update --availability drain node5
docker node update --availability drain node3
# check nodes:
docker node ls두 개의 드레이닝된 노드가 있는 클러스터를 보여줍니다.
node1 Ready Active 20.10.0
node2 Ready Active 20.10.0
node3 Ready Drain Reachable 20.10.0
node4 Ready Active Reachable 20.10.0
node5 Ready Drain Leader 20.10.0drain 모드는 작업자와 관리자에게 약간 다른 의미입니다. 두 경우 모두 노드에서 실행 중인 모든 복제본이 종료되고 노드에 대해 더 이상 복제본이 예약되지 않습니다. 관리자 노드는 여전히 관리 그룹의 일부이므로 여전히 클러스터 데이터베이스를 동기화하고 관리 API에 대한 액세스를 제공하며 리더가 될 수 있습니다.
리더 매니저에 대한 정보는 무엇입니까? 고가용성을 위해서는 여러 관리자가 필요하지만 active-passive 모델입니다. 실제로 클러스터를 제어하는 관리자는 단 한 명이며 리더입니다. 나머지는 클러스터 DB의 복제본을 유지하고 API 요청을 처리할 수 있으며 리더가 실패할 경우 인계받을 수 있습니다. 이는 나머지 관리자 간의 선택 프로세스에서 발생하며 과반수 투표가 필요하며 이를 위해서는 항상 홀수의 관리자가 필요합니다. 일반적으로 작은 클러스터의 경우 3개, 큰 클러스터의 경우 5개입니다. 관리자 노드를 영구적으로 잃어버리고 짝수의 관리자가 있는 경우 작업자 노드를 관리자로 승격할 수 있습니다.
TRY Play with Docker에서 노드 오류를 시뮬레이션하는 것은 쉽지 않지만 리더에 연결하고 Swarm에서 수동으로 제거할 수 있습니다. 그런 다음 나머지 관리자 중 한 명이 리더가 되고 작업자를 승격하여 홀수 관리자를 유지할 수 있습니다.
# on node1 - forcibly leave the Swarm:
docker swarm leave --force
# on node 2 - make the worker node available again:
docker node update --availability active node5
# promote the worker to a manager:
docker node promote node5
# check the nodes:
docker node ls노드가 Swarm을 떠날 수 있는 두 가지 방법이 있습니다.
- 관리자가
node rm명령으로 노드를 시작하거나 - 노드 자체가
swarm leave로 시작할 수 있습니다.
node1 Ready Active 20.10.0
node2 Ready Active 20.10.0
node3 Ready Drain Reachable 20.10.0
node4 Ready Active Leader 20.10.0
node5 Down Active Unreachable 20.10.0노드가 스스로 떠나면 노드가 오프라인이 되는 것과 유사한 상황입니다. Swarm 관리자는 노드가 여전히 있어야 한다고 생각하지만 연결할 수 없습니다. 그림 14.12의 출력에서 볼 수 있습니다. 원래 node1은 여전히 관리자로 나열되지만 Down 상태이고 관리자는 Unreachable 상태입니다.
이제 Swarm에는 다시 3명의 관리자가 있어 고가용성을 제공합니다. node1이 예기치 않게 오프라인 상태가 된 경우 다시 온라인 상태가 되었을 때 node demote 를 실행하여 다른 관리자 중 하나를 작업자 풀로 되돌릴 수 있습니다. 이것들은 Docker Swarm 클러스터를 관리하는 데 필요한 거의 유일한 명령입니다.
덜 일반적인 몇 가지 시나리오로 마무리하겠습니다. Swarm이 이러한 시나리오를 접했을 때 어떻게 행동할지 알 수 있을 것입니다.
-
모든 관리자가 오프라인 상태가 됨 --모든 관리자가 오프라인 상태가 되지만 작업자 노드가 여전히 실행 중인 경우 앱은 여전히 실행 중인 것입니다. ingress 네트워크와 작업자 노드의 모든 서비스 복제본은 관리자가 없는 경우 동일한 방식으로 작동하지만 이제 서비스를 모니터링할 항목이 없으므로 컨테이너에 장애가 발생해도 교체되지 않습니다. 클러스터를 다시 정상 상태로 만들려면 이 문제를 수정하고 관리자를 온라인 상태로 전환해야 합니다.
-
리더와 한 명의 관리자를 제외한 모든 관리자가 오프라인 상태가 됨 --하나의 관리자 노드를 제외한 모든 관리자 노드가 오프라인 상태가 되고 나머지 관리자가 리더가 아닌 경우 클러스터에 대한 제어 권한을 잃을 수 있습니다. 관리자는 새 리더에게 투표해야 하며 다른 관리자가 없으면 리더를 선출할 수 없습니다.
force-new-cluster인수를 사용하여 나머지 관리자에서swarm init를 실행하여 이 문제를 해결할 수 있습니다. 이는 이 노드를 리더로 만들지만 모든 클러스터 데이터와 실행 중인 모든 작업을 보존합니다. 그런 다음 더 많은 관리자를 추가하여 고가용성을 복원할 수 있습니다. -
균등한 배포를 위한 복제본 재조정 -- 서비스 복제본은 새 노드를 추가할 때 자동으로 재분배되지 않습니다. 새 노드로 클러스터의 용량을 늘리지만 서비스를 업데이트하지 않으면 새 노드에서 복제본을 실행하지 않습니다. 다른 속성을 변경하지 않고
service update --force를 실행하여 복제본이 클러스터 전체에 고르게 분산되도록 재조정할 수 있습니다.
14.5 Swarm 클러스터의 고가용성 이해
앱 배포에는 고가용성을 고려해야 하는 여러 계층이 있습니다. 상태 확인은 앱이 작동하는지 클러스터에 알리고 앱을 온라인 상태로 유지하기 위해 실패한 컨테이너를 교체합니다. 여러 작업자 노드는 노드가 오프라인 상태가 되는 경우 컨테이너를 다시 예약할 수 있는 추가 용량을 제공합니다. 여러 관리자가 컨테이너 예약 및 작업자 모니터링을 위한 중복성을 제공합니다.
마지막으로 고려해야 할 영역은 클러스터가 실행 중인 데이터 센터입니다.
사람들은 여러 데이터 센터에 걸쳐 있는 단일 클러스터를 구축하여 지역 간에 고가용성을 얻으려고 자주 시도하기 때문에 이 장을 마무리하기 위해 이 내용을 아주 간략하게 다루겠습니다. 이론상으로는 이렇게 할 수 있습니다. 데이터 센터 A, B, C의 작업자와 함께 데이터 센터 A에 관리자를 만들 수 있습니다. 그러면 클러스터 관리가 확실히 간소화되지만 문제는 네트워크 대기 시간입니다. Swarm의 노드는 매우 수다스럽고 A와 B 사이에 갑작스러운 네트워크 지연이 있는 경우 관리자는 모든 B 노드가 오프라인 상태가 되었다고 생각하고 C 노드의 모든 컨테이너 일정을 변경할 수 있습니다. 그리고 이러한 시나리오는 분할 브레인(split-brain)을 가질 수 있는 가능성과 함께 더욱 악화됩니다. 서로 다른 지역의 여러 관리자가 자신을 리더라고 생각합니다.
지역 중단이 있을 때 앱을 계속 실행해야 하는 경우 유일한 안전한 방법은 여러 클러스터를 사용하는 것입니다. 관리 오버헤드가 추가되고 클러스터와 클러스터에서 실행 중인 앱 간에 드리프트가 발생할 위험이 있지만 네트워크 대기 시간과 달리 관리 가능한 문제입니다. 그림 14.13은 그 구성이 어떻게 생겼는지 보여줍니다.
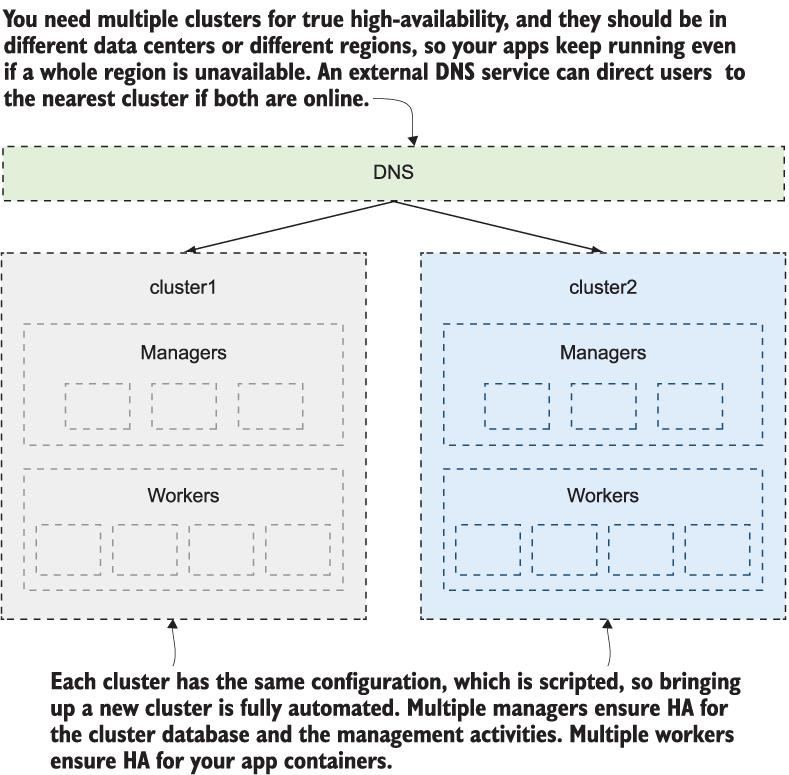
그림 14.13 데이터 센터 이중화를 달성하려면 서로 다른 지역에 여러 클러스터가 필요합니다.
14.6 Lab
이 실습의 이미지 갤러리 앱으로 돌아갔고 API 서비스에 대한 적절한 롤아웃 및 롤백 구성이 있는 스택 배포를 빌드할 차례입니다. 하지만 API 구성 요소에는 Docker 이미지에 내장된 상태 확인이 없으므로 서비스 사양에 상태 확인을 추가하는 방법에 대해 생각해야 합니다.
요구 사항은 다음과 같습니다.
-
diamol/ch04-access-log , diamol/ch04-image-of-the-day 및 diamol/ch04-image-gallery 컨테이너 이미지를 사용하여 이미지 갤러리 앱을 배포하는 스택 파일을 작성합니다.
-
API 구성 요소는 diamol/ch04-image-of-the-day 이며 4개의 복제본으로 실행되어야 하고 상태 확인이 지정되어야 하며 빠르지만 안전한 업데이트 구성과 다음과 같은 롤백 구성을 사용해야 합니다.
-
앱을 배포했으면 diamol/ch09-access-log , diamol/ch09-image-of-the-day 및 diamol/ch09-image-gallery 이미지로 서비스를 업데이트하는 다른 스택 파일을 준비하세요.
-
스택 업데이트를 배포하고 API 구성 요소가 예상 정책을 사용하여 롤아웃하고 잘못된 상태 확인으로 인해 롤백되지 않는지 확인합니다.
