1. 변수
변수의 종류에는
1. 지역변수
2. 전역변수
3. 정적변수
4. 외부변수가 존재했고,
지역변수는 스택영역, 전역변수,정적변수, 외부변수는 데이터 영역에
기록된다고 했다.
전역변수는 한 파일내에서는 전역적으로 쓸 수 있지만,
모든 파일에서 전역적으로 쓸 수 없다.
정적변수는 선언부 위치에 따라 다르게 쓰일 수 있었다.
외부변수는 실제로 모든 파일에서 전역적으로 쓸 수 있다.
해당 변수가 있다는 것만 extern int fin; 이런식으로 써놓기만하면,
해당 파일에서 정의하지 않았더라도
다른 한 파일에서 변수를 초기화 했다면, 모든 파일에서 사용이 가능하다.
2. 포인터
그리고 포인터를 배웠다.
포인터는 주소를 저장하여 주소에 접근할 수 있는 변수인데,
포인터의 크기는
운영체제에서 주소의 크기(범위)와 같고, 64비트면 8바이트, 32비트면 4바이트이다.
주소의 개수는 8바이트개 있고, 이걸 마당의 개수라고 본다면,
마당의 평수는 1바이트 이다.
int* a;라는 것은,
a포인터에 저장된 주솟값에 해당하는 값을 읽을건데,
해당 주소로부터 int형의 크기만큼 (4바이트) 읽어서 int형으로 해석하겠다는 것이다.
그냥 포인터는 해당 데이터값이 int인지 float인지, 얼마나 읽어야할지를 모르기 때문에 명시적으로 선언.
a+1을 해서 주솟값을 1 증가시킨다면, 4바이트를 건너뛰게된다.
포인터의 배열의 경우, 연속적이기 때문에, 이를 이용하여 각 인덱스에 접근할 수 있다.
3. const
const int a = 10; 을 하면,
a값을 바꿀 때 오류가 발생한다. 상수화 시키는 것이다.
a라는게 10을 의미하고,
a=100;이라는 오류구문은, 10=100;과 같은 말도 안되는 말이기 때문이다.
const와 포인터를 같이 사용할 수도 있다.
3가지 방법이 존재한다.
1. const-포인터
const가 포인터 *를 가리키므로, 참조한 것의 값을 변경할 수 없다.
대신, 주소를 바꿔서 다른 변수를 가져올 수는 있다.
2. 포인터-const
const가 포인터 변수를 가리키므로, 주소를 바꿀 수 없다. const int a = 10과 유사하다.
대신에 해당 포인터가 참조하는 변수의 값은 바꿀 수 있다.
3. 둘을 혼합해서 사용도 가능하다.
이를 사용하는 이유는, 개발자가 주소를 바꾸지 못하도록, 혹은 값을 바꾸지 못하도록
명시적으로 막기 위함이지만,
C++의 자유도 높은 특성상, 강제 형변환하여 바꿀 수 있는 방법이 존재한다.
컴파일 차원에서의 방어책이다.
그리고 void포인터라고
자료형을 정의해놓지 않은 포인터를 배웠다.
포인터니까 일단 주소만 저장할 수 있는데,
값을 참조하거나, 주소에 +1을 하거나
자료형이 필요한 그런 기능들을 아예 못쓴다.
복습을 마치고 이어서 공부해보자.
int형과 float형의 데이터 저장방식이 아예 달랐듯이,
문자열도 아예 다르다.
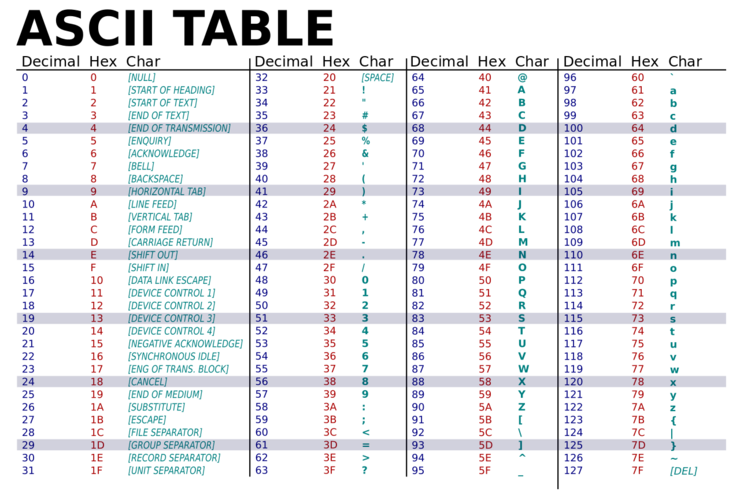
char c = 65;라고 한다면 c의 값을 출력했을 때, 'A'가 나올 것이다.
위의 아스키 코드를 따르고 있기 때문이다.
실제로 메모리에는 2진수로 65라는 값을 저장해놓고,
문자로 읽으라고 char형으로 변수를 명시했기 때문에 'A'로 읽은 것이다.즉, 1과 '1'은 다르다.
문자열로 보면 자세히 볼 수 있다.
만약 int형으로 459를 저장한다면, 메모리 상에는 2진수로 459가 저장될 것이다.
하지만, char형으로 459를 저장한다면, 4,5,9 각각의 아스키코드
52, 53, 57이 일정 칸을 가지면서 일련된 메모리에 저장이 될 것이다.
이게 차이이다.문자는 딱 하나의 문자만 받을 수 있고,
문자열은 여러개의 문자들을 받을 수 있다.
int형은 딱 4바이트이고, double형은 딱 8바이트인데,
문자열은 사용자가 정하기 나름이라, 고정된 크기가 존재하지 않는다.
그렇기 때문에, 문자의 끝을 알리는 의미로 2진수 값 0으로 채운다.
0은 아스키코드에서 null을 의미한다.그렇다면, 1과 '1'이 다르듯이,
'1'과 "1"도 다를 것이다.
char형은 메모리에 49에 해당하는 값이 들어가 있다면,
string형은 메모리에 49에 해당하는 값과 0이라는 값이 추가로 들어가있다는 것이다.wchar_t c[10] = L"abcedf"; const wchar_t* d = L"abcdef"; c[1] = 'z'; d[1] = 'z';위의 구문은 wchar_t라는, 문자 하나에 2바이트 크기를 갖는 자료형이고,
R-Value에 L선언을 해서, 해당 값도 2바이트씩 크기를 갖도록 한다.
약간 float에서 1.2f 쓰듯이 쓰는 방식인 듯 하다.그래서 위처럼 포인터를 작성하니 된다.
wchar_t c[10] = L"abcedf" 의 의미는,
wchar_t라는 2바이트씩 방을 갖는 데이터 10개를 만들어놓고,
(20바이트)
해당 방에 2바이트씩 차지하는 abcedf null을 각 방에 끌어와 넣어라라는 내용이다.
하지만 다음구문은??일단 에러없이 동작한다는 것은
L"abcdef"라는 문자열이 주솟값이라는 말일텐데...이를 알기 위해선 읽기전용(코드, ROM)에 대해서 알 필요가 있다.
결론부터 말하면, 해당 포인터는 메모리상 L"abcedf"가 존재하는 메모리의 주소를 담게 된다.프로그램을 실행시키기 위한 명령어들도 컴퓨터의 메모리상 어딘가에 존재할 것이다.
그래서 해당 포인터는,
해당 명령어에 담긴 L"abcdef"의 주소를 받게 되고,
d[1] = 'z'로 명령어를 침범하여 수정하게 된다.
const라서 해당 구문은 되지 않지만, 마찬가지로 강제형변환을 한다면
직접 수정할 수가 있게되고, 오류가 발생한다.중요한것은, 문자열 자체를 포인터에 대입할 "주소"로 받을 수 있다는 것이고,
참조는 하되, 값을 바꾸면 명령어의 실제 값(ROM에 저장된 값)을 바꾸는 것이라 심각한 오류를 초래한다는 것이다.char형은 윈도우의 멀티바이트셋이라는 방식때문에,
1바이트씩 담지 않을 수도 있다. 즉, 가변길이 방식을 사용한다.
한글같은 경우에는 아스키 코드표에도 없을정도로 표현할 때, 127개로 표현할 수가 없는데, 표현하기 위해서 1바이트를 2개 묶어서틀 사용하고,
char형에 한글이 들어왔을 경우, 알아서 변환하여 사용한다.이게 문제가 되는것은,
char ch[10] = "한글"; 일 경우,당연히 ch[0]는 한, ch[1]은 글 일 것 같지만,
ch[0],ch[1]이 한을 뜻하고, ch[1],ch[2]가 글을 뜻하게 된다.그래서 윈도우에선 위의 문제가 있기 때문에,
wchar_t noMatter[10] = L"한글"; 처럼
애초에 2바이트씩 담아두는 자료형을 사용하는 것이 바람직하다고 한다유니코드방식
38강 - 문자열(3)
38강부터 39강까지는 strlen, strcat, strcmp와 같은 함수를 직접 구현하는 것을 배운다.#include <iostream> #include "func.h"; ? //문자열의 길이를 정수형 return 하는 함수. //문자열의 맨 마지막을 NULL, '\0', 심지어는 0으로 쓸 수도 있다. int strLen(const wchar_t* _str){ int i=0; while (true) { if (NULL == *(_str + i)) { break; } i++; } return i; } //문자열 2개를 붙이는 함수 //첫 문자열 뒤에, 다음 문자열을 붙인다. //첫 문자열의 크기는 고려하진 않았음 void strCat(wchar_t* _first, const wchar_t* _last) { int f_len = strLen(_first); int l_len = strLen(_last); int i = 0; while (true) { if (NULL == *(_last + i)) { break; } *(_first + f_len + i) = *(_last + i); i++; } } //문자열 2개를 비교하는 함수, //저울과 같이, 왼쪽이 올라가면 -1, 오른쪽이 올라가면 1, 같으면 0을 출력 //올라간다는 것은 사전에서 A와 B가 존재하면, A가 올라가는 쪽에 속함. int strCmp(wchar_t* _left, wchar_t* _right) { int i = 0; while (true) { //둘의 글자가 같다면, 자릿수를 증가해서 끝까지 그런지 본다. if (0 == *(_left + i) - *(_right + i)) { i++; } else { if (*(_left + i) - *(_right + i) > 0) { return 1; } else return -1; } } } int main() { wchar_t ch_1[10] = L"ABC"; wchar_t ch_2[10] = L"DEF"; printf("%d", strCmp(ch_1, ch_2)); return 0; }위처럼 const-포인터를 사용하여
값을 수정하진 못하고 참조만 하도록 만들어 각 함수들을 만든다.

typedef struct one { int i; float f; }AB; int main() { AB str = {}; AB* pt = &str; //== one* pt = &str; (*pt).i = 1; (*pt).f = 1.5f; return 0; }위처럼 사용한다.
struct이름도 하나의 자료형으로 typedef가 된 것이기 때문에,
똑같은 방식으로 사용이 가능하지만,
해당 멤버변수에 접근하는 것이 특이한데,
위처럼 해당 값을 참조하고, 멤버를 추가로 적어야만 한다.
원래 구조체에서도 멤버변수에 값을 대입하기 위해 그랬어야 했었다.(*pt).i = 1; (*pt).f = 1.5f; pt->i = 100; pt->f = 150.5f;그리고 위처럼 축약해서 사용하는 것도 가능하다.
그냥 암기
C++ 메모리영역은 4가지
1. 스택영역
2. 데이터 영역
3. 읽기 전용(코드, ROM)
4. 힙 영역이 중에 먼저 1,2영역을 봤었고,
3영역은 문자열의 포인터참조에서 봤었고,4번 힙영역에 대한 부분을 지금 본다.
여태껏 변수라는 것은, 이건 무조건 쓸 것이라고 미리 정의해놓은 것들이었고,
힙영역은 실행시켜봐야지만 쓸지 말지 아는 데이터의 영역으로 볼 수 있다.동적할당이란, 프로그램 실행 도중에 원하는 만큼의 힙영역 메모리를 할당하여 쓰는 것으로,
힙영역에 공간을 만드는것은 malloc이다.int main() { int* a = (int*)malloc(100); }먼저 malloc하고, 100을하면,
힙 영역에 100바이트의 공간을 만들고, 해당 시작주소를 가지고 있다.
이를 a에 받는다.
즉, 원하는 만큼 힙영역에 메모리를 만들 수 있다.이때 malloc의 형변환을 하는 이유는,
malloc이 void 포인터이기 때문이다이제야 사용법이 밝혀진다..
자료형이 없고, 단지 주소만을 저장하는 포인터기 때문에
자료형을 작성해주어야 한다.포인터는 주소값을 가지고 있고, 그 자체로는 해당 주소값의 데이터가
뭔지 알려고 하질 않는다.
그래서 본인이 가지고 있는 주소에 있는 2진수 값은 이런 자료형이다라고 설명하기 위해서 자료형을 추가로 붙여주도록
int float char *이런 자료형이 붙게 되었는데,
malloc도 똑같이, 어떤 자료형인지 명시되어야한다.그래서 malloc은 어떻게 쓰일지는 모르겠지만, 그냥 힙공간만 만들어두고,
할당된 주소를 가져가는 쪽에서는 해당 공간에 대한 강제 형변환을 해야한다.그렇게 메모리를 설정하는데, 해제도 해야한다고 한다.
여태껏 int i를 선언하고, 전역, 정적, 지역, 외부 등 모두 선언하고
함수, 구조체 등등 사용자가 직접 해제할 필요가 없었다.
컴파일러가 다 해줬었다.하지만 동적할당은, 할당될수도 있고, 안될수도 있는,
프로그램 실행동안 malloc이 실행될 수도 있고, 안될수도 있는 것이라서,
해당 힙영역에 공간이 만들어질 수도, 만들어지지 않을 수도 있기 때문에,
미리 모든걸 파악하고 있는 컴파일러가 자동으로 해지할 수 없다.int main() { int* a = (int*)malloc(100); if (nullptr != a) { free(a); } return 0; }그래서 위처럼, 코드의 맨 마지막에 if문을 넣어서 nullptr이 아니라면, free로 해당 주소의 메모리를 해제시켜 준다.
스택메모리나 데이터메모리의 주소를 넣는다면 심각한 오류가 날 것이다.
int main() { int num = 10; int arr[num] = {}; return 0; }위의 구문은 오류가 난다.
왜냐하면, 배열의 크기선언부에 변수가 들어갈 수 없기 때문이다.왜 들어갈 수가 없냐면, 지역변수인 배열을 동적할당할 수는 없다.
해당 변수의 값이 프로그램 중에 바뀌면,
컴파일러가 미리 해당 배열의 크기를 메모리에 설정해 두는 것이 불가해지기 때문이다.그렇다면, 가변배열을 위해서는 힙메모리로 동적할당을 해야하다.
가변배열을 위해선 힙메모리로 동적할당을 해야한다.
동적할당을 일정량 하고, 해당 주소값을 받은뒤,
그 주솟값에 인덱스에 맞게 추가하고, 일정량이 넘어가면,
추가 동적할당을 하는 것이 최종 목표다.이걸 코딩해본다.
우선 정의하는 헤더 func.h #pragma once typedef struct _Arr { int* pInt; //데이터를 담을 주소 - 연속된 값이어야함. int iCount; //현재 배열의 개수 int imaxCount; //최대로 담을 수 있는 배열의 개수 }Arr; //배열 초기화 void InitArr(Arr* arr); //배열 데이터 추가 void AddArr(Arr* arr, int data); //배열 메모리 해제 void ReleaseArr(Arr* arr); //배열 길이 추가 void Reallocate(Arr* arr);위처럼 자료형, 함수만 정의해두고, func.cpp에서 구현한다.
#include "func.h" #include <iostream> void InitArr(Arr* arr) { //그냥 malloc 8 적는 것보다 낫다. arr->pInt = (int*)malloc(sizeof(int) * 2); arr->iCount = 0; //int형 최대 2개를 담을 수 있게 조금만 설정한다. arr->imaxCount = 2; } //이걸 구현할 수 있을까? void Reallocate(Arr* arr) { } void AddArr(Arr* arr, int data) { //먼저 가변길이를 넘었는지부터 판단을 해야한다. if (arr->iCount >= arr->imaxCount) { Reallocate(arr); } arr->pInt[arr->iCount] = data; } void ReleaseArr(Arr* arr) { free(arr->pInt); arr->iCount = 0; arr->imaxCount = 0; }그냥 수학 수식을 쓰듯 구현이 된다.
우선 imaxcount라는 것은 2로 구현을 했는데,
힙이라는건 동적할당메모리기에 쓸 수도 있고 안 쓸 수도 있어서
시작을 작게 잡았다.그래서 부족하면 추가적으로 malloc을 하도록 하면 될텐데..
구현을 하면서도 생각했고, 강의에서도 말했지만,
Reallocate를 구현할 수 있을까?나는 없다고 본다.
그 이유는 일단, malloc은 원하는 주소에 해당 바이트의 공간을 생성하는 함수도 아닐거라고 생각하고,
다른 방법으로 malloc을 그냥 새로 하나 크게 파서,
그 장소에 값을 이사시키는 것으로 대체하지 않을까 생각해보았다.45 - 가변배열 (3)
나름대로 구현해보려 했다.
tmp라는 이전의 값들을 가지고 있는 변수들을 저장해두고,
해당 값을 새로 지은 pInt라는 집에 옮기려했는데
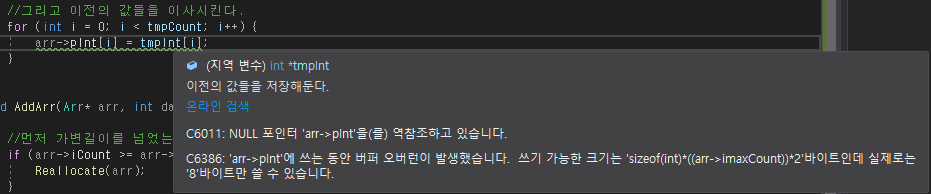
오류가뜬다.void Reallocate(Arr* arr) { //이전의 값들을 저장해둔다. int* tmpInt = arr->pInt; int tmpCount = arr->iCount; int tmpMaxCount = arr->imaxCount; //우선 imaxCount와, pint의 값을 2배로 변경시킨다. arr->pInt = (int*)malloc(sizeof(int) * (arr->imaxCount) * 2); //원래보다 2배더 크기 //그리고 이전의 값들을 이사시킨다. for (int i = 0; i < tmpCount; i++) { arr->pInt[i] = tmpInt[i]; } }위의 arr->pInt[i] = tmpInt[i] 구문이 경고가 뜬다.
우선 가장 이해가 안되는건, 아래의 구문이arr->pInt = (int*)malloc(sizeof(int) * (arr->imaxCount) * 2)왜 8바이트만 쓸 수 있는가이다.
malloc으로 int형크기 4에, imaxCount인 2에 2까지 해서 16바이트를
malloc해야하는데, 흠..
그리고 왜 arr->pInt가 nullptr인가이다. ㅋㅋㅋ
이해가 되질않는다.void Reallocate(Arr* arr) { //기존 최대값의 2배만큼의 int형을 수용할 수 있게 된다. int* tmpArr = (int*)malloc(arr->imaxCount ^ 2 * sizeof(int)); //max까지로해도 상관은 없다. for (int i = 0; i < arr->iCount; i++) { tmpArr[i] = arr->pInt[i]; }강의에 나온 그대로 구현해도 똑같은 경고가 뜨는데,
왜인지 전혀 모르겠다.일단 그대로 구현해 보았다.
void Reallocate(Arr* arr) { //새로 공간을 하나 만든다. //기존 최대값의 2배만큼의 int형을 수용할 수 있게 된다. int* tmpArr = (int*)malloc(arr->imaxCount ^ 2 * sizeof(int)); //기존 자료를 새로만든곳에 복사한다. for (int i = 0; i < arr->iCount; i++) { tmpArr[i] = arr->pInt[i]; } //기존 포인터 공간은 필요가 없어져서 삭제한다. free(arr); arr->pInt = tmpArr; //기존 변수를 수정한다. //arr->iCount; 이건 수정할 필요가 없다. arr->imaxCount *= 2; }
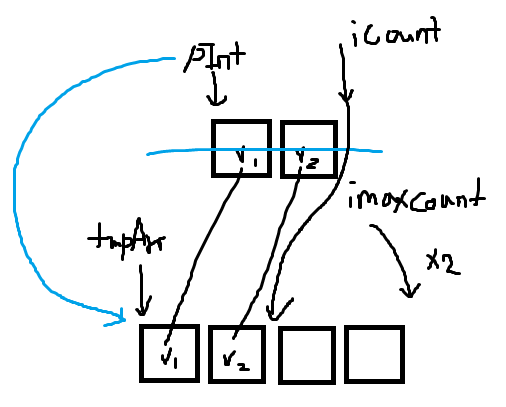
위 그림처럼 기존의 2배 크기의 새 tmpArr을 생성하고,
값을 복사한뒤, 기존의 포인터변수의 위치만 바꾼 것이다.
기존 iCount는 그대로 쓰고, imaxCount는 *2하여 사용한다.
[func.cpp]
#include "func.h"
#include <iostream>
void InitArr(Arr* arr)
{
arr->pInt = (int*)malloc(sizeof(int) * 2);
arr->iCount = 0;
arr->imaxCount = 2;
}
void Reallocate(Arr* arr)
{
//새로 공간을 하나 만든다.
//기존 최대값의 2배만큼의 int형을 수용할 수 있게 된다.
int* tmpArr = (int*)malloc(arr->imaxCount * 2 * sizeof(int));
//기존 자료를 새로만든곳에 복사한다.
for (int i = 0; i < arr->iCount; i++) {
tmpArr[i] = arr->pInt[i];
}
//기존 포인터 공간은 필요가 없어져서 삭제한다.
free(arr->pInt);
arr->pInt = tmpArr;
//기존 변수를 수정한다.
//arr->iCount; 이건 수정할 필요가 없다.
arr->imaxCount *= 2;
}
void AddArr(Arr* arr, int data)
{
//먼저 가변길이를 넘었는지부터 판단을 해야한다.
if (arr->iCount >= arr->imaxCount) {
Reallocate(arr);
}
arr->pInt[arr->iCount++] = data;
}
void ReleaseArr(Arr* arr)
{
free(arr->pInt);
arr->iCount = 0;
arr->imaxCount = 0;
}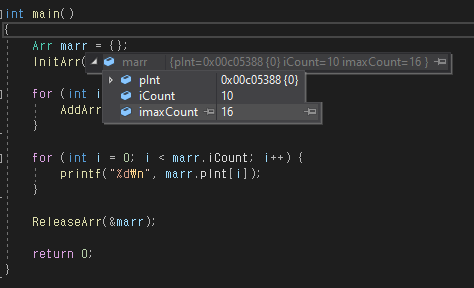
정상동작한다.
논리적으로 문제는 없었음을 의미한다.
