가변배열의 버블정렬
void sort(Arr* tarr)
{
for (int i = 0; i < tarr->arrCount; i++) {
//-1을 무조건 붙여줘야함
for (int j = 0; j < tarr->arrCount-1; j++) {
if (tarr->arr[j] > tarr->arr[j + 1]) {
int tmp;
tmp = tarr->arr[j + 1];
tarr->arr[j + 1] = tarr->arr[j];
tarr->arr[j] = tmp;
}
}
}
}위처럼 간단히 구현했고,

2번째줄이 정렬된 배열의 값인데,
자꾸 이상한 값이 들어와있어서, 코드를 보다가 결국 알아냈다.
j문의 count-1을 해주어야만한다.
그 이유는, 2개를 바꿀건데, count만큼 해버리면,
3개가 존재할때, 3번을 바꾸는 작업을 하는 것이기 때문에,
3번째 j인덱스는, 본인 배열 바깥의 이상한 값을 참조하게 된다.
포인터라서 오류없이 했던것 같아서 소름이 돋았다.
추가로 어제했던 것은,
문자열이라는 자료형에 대해서 봤었고,
정수와 실수형의 2진수의 읽는 방법이 다르듯,
문자도 아스키코드로 2진수를 읽게 된다.
추가로, C++윈도우에서 문자열을 위해서 char형을 쓰는 것은 바람직하지 않다.
그 이유는 멀티바이트셋이라는 방식 때문인데,
모든 문자가 크기가 같게 배정되는 것이 아니기 때문에
wchar_t형인 2바이트로 모든 문자를 동등하게 표시하는 자료형을 사용하는 것이 좋다. L"ABC"
문자열은 주소로 받을 수 있다.
해당 주소는, 문자열이 기록된 ROM에 저장된 값을 의미하고,
해당 주소의 값을 수정시, 심각한 오류가 발생한다.
그렇기에 만약 wchar_t포인터에 따로 지역변수에 값을 담아서 매개변수로 주는 것이 아니라,
문자열을 그대로 받을시,
const wchar_t* _ch 처럼 const를 붙이는 것이 현명하다.
방어적으로 코딩
구조체 포인터 가능했고 -> 라는 기호도 배웠다.
동적할당과 malloc이라는 void포인터에 대해서 배웠고,
free로 힙메모리를 해제해주어야만 메모리 누수를 막을 수 있다.
추가로 가변배열의 구현을 배웠고,
이 과정에서, malloc으로는 메모리 공간만 만들뿐, 특정 주소에 만들라고 시킬 수는 없다는 것을 알았다.
함수 포인터
이건 일단 스킵한다.
간단하게 보면, 함수의 포인터를 설정할 수 있고,
포인터로 함수를 호출할 수 있다.
이를 사용하는 예시는,
업무에 있어서, 캐릭터가 점프를 한다는 기능을 A가 구현을 다 해놓았고,
B는 점프 후에, 착지하는 함수를 그 A의 기능에 추가하고 싶다고 할 때,
A는 만들어지지도 않은 B의 기능을 사용하겠다고 해야하는데,
이를 위해서 함수 포인터로, 해당 함수포인터가 존재하면, 동작해라 라고 코딩해놓을 수 있다.
A에 코드를 추가하면 되지만, 100번 1000번이고 계속 추가할 수가 없기 때문이다., 필요한 사람이 추가를 하면, 호출하는 코드만 추가를 하면 된다.함수포인터의 양식만 맞는다면, B뿐만아니라, C, D ...의 모든 함수를
사용할 수 있게 된다.
복습을 마치고 이제부터 리스트를 공부해보자.
가변배열처럼 데이터를 계속 추가할 수 있다.
하지만 배열과 데이터를 다루는 방법이 다르다.
배열은 메모리상에 연속적으로 배치되지만, 리스트는 아니다.각 리스트 인덱스 객체를 노드라고 하고,
각 노드는 다음 노드의 주소를 가리키게 된다.리스트도 똑같이 typedef로 구현한다.
iCount라는게 필요한가? 필요하다.
현재까지 저장된 데이터 개수는 알고 있어야 되기 때문.imaxCount라는건? 필요없다.
가변배열의 경우, 배열이란것은 항상 일정 크기를 정해놓고
꽉차면, 새로 Reallocate를 했었지만,
리스트는 연속된 메모리 주소를 참조하는 배열이란게 아니기때문에 ,
max를 가질 필요가 전혀 없다.그리고 각 노드는 다음 노드의 주소가 필요하다.
#pragma once typedef struct _tNode { int iData; tNode* nextNode; //틀린구문 struct _tNode = nextNode; //맞는 구문 }tNode; typedef struct _tList { int count; tNode* headNode; }tList;위처럼 이루어진다.
List는 count라는, 전체적인 데이터를 가지고 있고,
시작 노드의 포인터를 가지고 있다.노드라는 것은 본인의 데이터와, 다음 노드의 위치를 가지고 있다.
위에 틀린구문은 이유가 뭐냐면,
typedef A B라면, A를 B라고 정의하는 말인데,
A라는 것 내부에 B가 미리 존재해버리면,
B라는게 정의가 되지 않은 상태기 때문에 모순이다.
그래서 위와 같은 상황인 경우, A그대로를 내부에 써야한다.그래서 기능을 우선 연결형리스트 초기화,
연결형리스트 노드추가 2개를 추가해보자.//우선 이렇게만 세팅한다. //값이 들어올지 안들어올지 모르기 때문에. void initList(iLinkedList* ilist) { ilist->headNode = nullptr; ilist->iCount = 0; } //addList라는 것은, 값을 노드를 만들어서 넣어주고, 연결해줘야하는데, //사실상 노드의 초기화도 같이 진행해줘야한다. void addList(iLinkedList* ilist, int data) { //값을 담을 노드 iNode* thisNode = (iNode*)malloc(sizeof(iNode)); thisNode->iData = data; thisNode->nextNode = nullptr; //아무것도 없는 리스트에 들어왔다면, 노드를 생성하고, headNode가 된다. if (ilist->iCount == 0) { ilist->headNode = thisNode; ilist->iCount++; } //하나라도 존재하는 리스트라면, list처음부터, 다음 nextNode가 nullptr일때까지 찾아간다. //그러면 마지막노드의 주소를 알게 되고, 그곳에 값을 연결. else { iNode* tmpNode = ilist->headNode; while (tmpNode->nextNode) { tmpNode = tmpNode->nextNode; } tmpNode->nextNode = thisNode; ilist->iCount++; } }위처럼 리스트의 초기화와 값의 추가를 진행해 보았다.
리스트를 만들면서 느낀 것은,
인덱스로 접근할 수 없기 때문에 특정 값의 접근이 힘들다는 것이다
심지어는 마지막 노드도 while을 통해서 차례대로접근해야한다.//nextNode의 값을 임시로 저장하고, 현재노드를 free한다. //이를 반복. void freeList(iLinkedList* ilist) { iNode* thisNode = ilist->headNode; ilist->iCount = 0; while (thisNode->nextNode) { iNode* tmpNode = thisNode->nextNode; thisNode->iData = 0; free(thisNode); thisNode = tmpNode; } }추가로 위처럼 free하는 함수도 만들었다.
정상동작한다.지금의 연결리스트는 맨뒤의 값에 추가하도록 되었는데,
맨 앞에 추가하는 함수도 만들어보라고 했다.//head노드를 tmp에 놓고 리스트와 tmp 사이에 새로운 head를 낌. void changeHead(iLinkedList* ilist, int data) { iNode* newHeadNode = (iNode*)malloc(sizeof(iNode)); newHeadNode->iData = data; newHeadNode->nextNode = ilist->headNode; ilist->headNode = newHeadNode; ilist->iCount++; }리스트라 위처럼 그냥 연결하는 부분만 바꾸면 간단하게 바꿀 수 있다.
struct sObj { }; class cObj { };이제부터 C에서 발전된, C++에 추가된 기능을 사용한다.
typedef를 사용하지 않고 구조체를 정의한다.
추가로, class에 대해서도 배운다.class cObj { private: int a; };동시에, 접근제한 지정자에 대해서도 배운다.
private, protected, public
C++은 특이하게,
접근제한 지정자를 필드로 선언할 수 있다.class cObj { private: int a; public: cObj() { int a = 1; } }; int main() { cObj c; }
생성자를 만들 수 있다.
그냥 해당 class객체를 만들기만하면, 자동으로
해당 생성자가 호출되어 실행된다.public: cObj() : a(1) // ,b(100), c(10.5f) ... { } };그런데 C++은 위처럼, a에 값을 넣어서 생성하는 코드를 만들수도 있다.
소멸자도 존재한다.
객체가 사라질때 자동으로 해당 소멸자가 호출되어 실행된다.지역 클래스, 즉 main의 스택에 포함되는 클래스 조차도
끝나면서 소멸자가 자동으로 실행이 된다.그리고,
생성자와 소멸자를 만들지 않아도 알아서 dafault로 만들어놓는다.
코드상 아무 기능이 없지만 구색을 맞추는 것..
멤버함수 - 해당 클래스가 사용하는 전용함수.
클래스 내의 함수를 의미.
멤버함수를 호출하려면 반드시 해당 클래스의 객체로 접근해야 한다.int main() { cObj c; c.setInt(1); cObj c2; c.setInt(1); cObj c3; c.setInt(1); }그래서 위처럼, c.멤버함수로 접근을 한다.
그러면 각 객체의 변수가 값을 받게 되는데,
각 객체의 변수가 값을 받는 다는 말이 이전 List나 배열의 구현처럼
해당 객체의 주소값을 전달했기에, 해당 객체의 주솟값 내의
변수가 값을 수정하는 것이 아닌가 합리적인 의심을 할 수 있고,void setInt(int num) { a = num; } void setOrignInt(cObj* _this, int num) { _this->a = num; }위의 2개의 코드를 보면 설명이 된다.
둘은 같은 코드이고, C++는, 아래의 코드를 위처럼 쓸 수 있도록
작성할 수 있게 만들어놓았다.
멤버변수를 객체를 통해서 호출하면, 해당 객체의 주소가 자동으로
this 포인터로 전달이 된다.
즉, 호출하는 객체의 주소를 &this로 보이진 않지만 같이 넘기고 있는 것이다int main() { cObj c1; c1.setInt(1); cObj c2; c2.setInt(10); int a = 1, b = 3; a = b; c1 = c2; //어떻게 동작하는 것일까? }int a에 b를 대입하면, b의 값이 a의 위치에 복사되어 저장이 된다.
객체 c1에 c2를 대입한다면?
위의 함수가 호출이 되게 된다.
오퍼레이터 함수라고하고, 특정 연산자 작업에 자동으로 호출된다.
근데 자료형에& 붙은 기호는 처음봤다.
레퍼런스 변수라고 한다.[슬슬 헷갈릴 만한 것들] 1. 자료형* 변수명 //포인터변수 선언 2. *포인터변수명 //포인터 역참조 3. &변수 //변수의 주소값 4. 자료형& 변수명 //레퍼런스변수 선언4에 해당하는 것이다.
//a의 주소를 참조하는 포인터를 //역참조하여 100대입 int a = 10; //1 int* p = &a; *p = 100; //2 int& iRef = a; iRef = 100;위의 2개의 방식이 비슷한 작업을 한다고 한다.
그냥 포인터랑 작동방식은 비슷하다고 한다.
a의 주소를 iRef로 받고 직접 접근하여 100으로 바꾼다.그러면 레퍼런스를 왜 쓰는가에 대해서보면,
해당 iRef문의 연결을 바꿀 방법이 없다.
iRef = b로 하면 a=b처럼 되어버리니게 되므로.
즉 유사 포인터-const인 셈이다.한번 가리킨 대상, 한번 참조한대상을 절대 바꿀 수 없게 된다.
역참조도 할 필요가 없어서, iRef를 a처럼 쓸 수 있게 되는 것이다.
다시 위의 코드를 본다면,
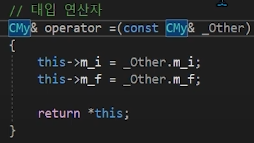
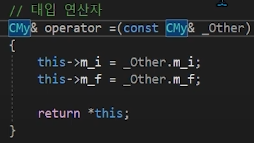
c1 = c2를 했을 때,
c1을 참조하는 레퍼런스변수가 this로 들어오고,C++의 생략
c2를 참조하는 const-레퍼런스변수가 _other로 들어오게 된다.
레퍼런스는 포인터-const였는데, const가 붙으므로, const-포인터-const가 된다. 즉 값을 바꿀 수도, 참조를 바꿀 수도 없다.
_other가 값과 참조를 바꿀 수 없어도 되는것이, c2의 값을 복사해서
c1에 그냥 대입만 하면 되기 때문이다.
그래서 각 대입이 이루어지고,return이 되게 되는데,
이전 강의에서
즉, 호출하는 객체의 주소를 &this로 보이진 않지만 같이 넘기고 있는 것이다라는 것처럼,
오퍼레이터 함수도, 호출한 객체(대입연산자의 왼쪽객체)가
this로 주솟값을 전달하게 되는데,해당 주솟값을 역참조하는 객체를 레퍼런스변수로 참조하여 돌려주는 것이다.
말이 어려운데, 그냥 주솟값을 역참조하는 객체를 반환값으로 준다는 것이다.
그 이유는, c1 = c2 = c3와 같은 경우에서,
c2=c3의 값이 대입되고, c2의 값이 또 c1에 대입이 되야하기 때문에
단순 대입뿐만이 아니라 반환값까지 필요한 것이기 때문이다.

클래스의 멤버들은 필드를 선언하지 않으면,
자동적으로 private형으로 선언이 된다.//클래스 선언부 밖에서 멤버함수를 구현하면, 명시해야한다. CArr::CArr() :iarr(nullptr), iCount(0), maxCount(2) { //iarr = (int*)malloc(sizeof(int) * 2); iarr = new int[2]; } CArr::~CArr() { //free(iarr); delete[] iarr; //단 하나의 값이라면, delete arr }위는 생성자와 소멸자이다.
#pragma once class CArr { private: int* iarr; int iCount; int maxCount; public: CArr(); ~CArr(); };위의 헤더에서 생성자, 소멸자를 선언만 하고,
다른 CArr.cpp파일에서 멤버함수를 구현하게 되면,
CArr:: 를 붙여서 클래스를 정확히 명시해야만한다.그래서 생성자를 보면, init으로 따로 함수를 만들어 했던 작업이
몇줄로 끝나버리는 것을 볼 수 있다.
그리고, iarr에 힙메모리 주솟값을 주는 방식도,
C언어에서 하듯이 malloc하는 것이 아니라,new라는 예약어를 통해서 int형 2개를 담을 공간을 만들고
주솟값을 간단히 넘겨주게 된다.소멸자의 경우에도 delete라는 예약어를 사용하여 간단히 해제한다.
.
이전의 malloc은 순수하게 메모리를 동적할당하고,
해당 메모리를 자료형을 가진 포인터로 가리켜서,
해당 메모리에 있는 2진수 값을 해당 자료형으로 보도록 하는
약간 투박하고 날것의 방법이었다.즉, malloc이라는 것 자체는 자료형은 알고 싶지 않고,
그냥 일단 메모리만 만들어두는 것이다..
C++에서 클래스라는 것은,
애초에 설계때부터, 만들어질 때, 생성자가 호출이 무조건 되어야만 한다.
해당 생성자는 위에서처럼, 사용자가 호출하는 것이 아니라,
컴파일러가 해당 객체가 생성되는 시점에 생성자를 호출을 해준다.생성자에서는 변수의 초기화를 진행하는데,
해당 변수에 대한 주솟값을 가지고 값을 넣어야하는데,
CArr c; 와 같은 경우라면, 이건 지역변수라서 굳이 생성자를 쓰지 않는다. 힙을 쓰지도 않고, Carr클래스를 쓴다고 명시를 했기 때문에,
해당 클래스 내의 변수들은 모두 알맞게 저장 및 해석이 된다.CArr* c_arr = (CArr*)malloc(sizeof(CArr));
위처럼은 C에서 쓰던 방식이고,
C++에서 추가된 클래스에서는, 사용자가 호출하지 않아도, 반드시 생성자가 호출이 되어야하는 기능이 존재하기 때문에, new를 사용하여, 자동으로 객체를 생성한다.
설명이 너무 이상하게 갔는데,
어떠한 용도로 사용되고 있는지 new와 delete가 다루게 되는데,
CArr* c_arr = new CArr;이렇게 쓴다면,
1. new Carr으로 Carr객체를 생성.
2. 객체가 만들어졌으니 생성자를 실행되어야 함. 클래스의 특성
3. 생성자가 실행되어서 해당 변수 값들이 초기화되어야하므로,
new를 통해서 전달한 CArr이라는 클래스자료형만큼의 크기,
sizeof(CArr)만큼의 힙공간을 자동으로 생성한다.
4. 생성자가 실행.
5. 해당 객체의 주솟값을 가져와서 c_arr에 대입함.
delete c_arr;delete도 해당 포인터의 자료형인 CArr과, 그 시작주소를 가지고,
소멸자를 실행
void CArr::addArr(int _iData) { //힙영역에 할당한 공간이 다참 if (this->iCount >= this->maxCount) { //재할당 } //데이터 추가 this->iarr[this->iCount] = _iData; this->iCount++; }위에서처럼 클래스로 만든 배열에
값을 추가하는 멤버함수를 작성해보았다.void CArr::addArr(int _iData) { //힙영역에 할당한 공간이 다참 if (iCount >=maxCount) { //재할당 } //데이터 추가 iarr[iCount] = _iData; iCount++; }하지만 그냥 위처럼 this를 빼도
클래스는 알아서 멤버변수라는 것을 인지한다.public: void addArr(int _iData); void resizeArr(int _iData); //void resizeArr(CArr* arr); << 객체를 가져오지 않아도 된다. //위에 addArr도, addArr(CArr* arr, int _num);인 것이다. };객체를 가져오지 않아도 된다는 C++의 클래스 특성때문에,
받아올 값이 없어져서 num이라는 변수를 추가해보았다.num만큼 크기를 증가시키는 것이다.
