BFS/DFS - 다익스트라 - Floyd-Warshall 을 지나
문자열 파트로 넘어간다.
앞서 마찬가지로 공부의 효율을 위해, 무작정 바로 풀기보다
여러 코딩 팁과 알기 쉽게 설명하는 위의 강의를 참고한다.
내용을 요약해보면ㅡ
문자열은 Python으로 푸는게 압도적으로 좋다.
하지만 굳이 CPP로 풀어야한다면, string을 사용해라.
그 이유는, 관련 함수들이 더 많고 유용하기 때문이다.CPP는 Split함수를 지원하지 않아서 매번 따로 구현해야만 한다.
혹은 문자열 배열을 이용하여 구현한다.
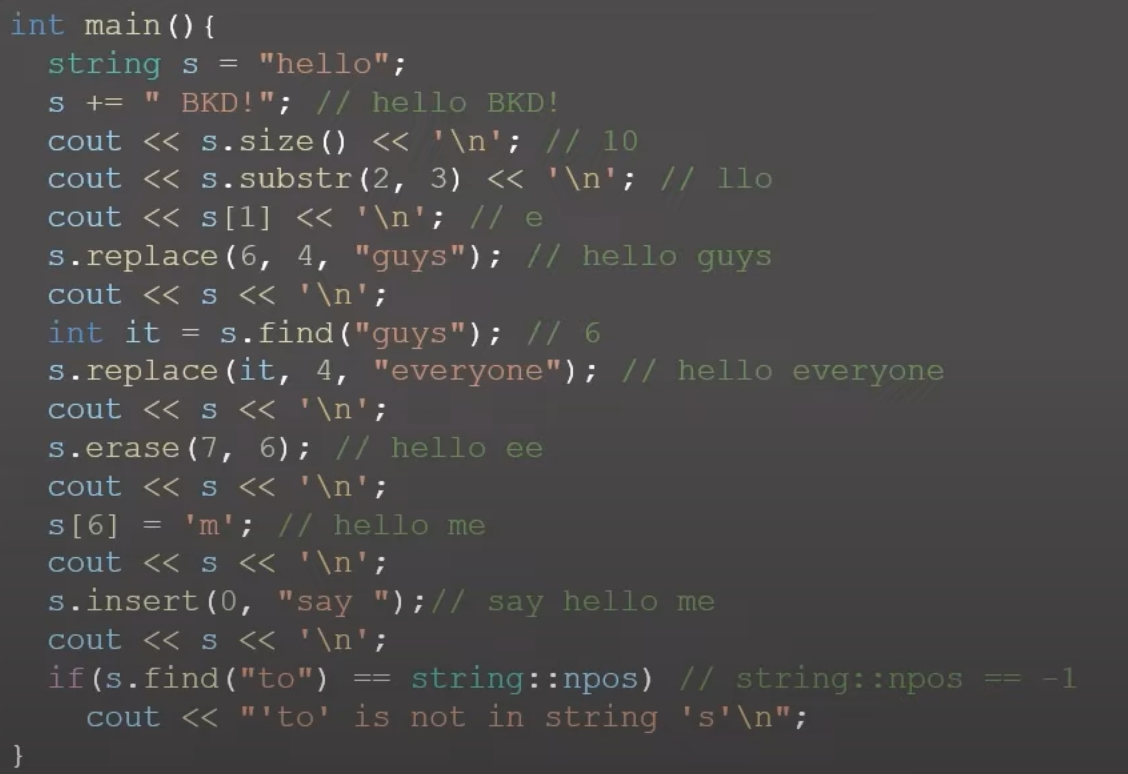
영상에 나온 string관련 함수 모음이다. 정리가 잘 되어있다.
[문자열 문제들 모음]
https://www.acmicpc.net/problemset?sort=ac_desc&tier=6%2C7%2C8%2C9%2C10%2C11%2C12%2C13%2C14%2C15&algo=158&algo_if=and
4. 1764 - 문자열
https://www.acmicpc.net/problem/1764
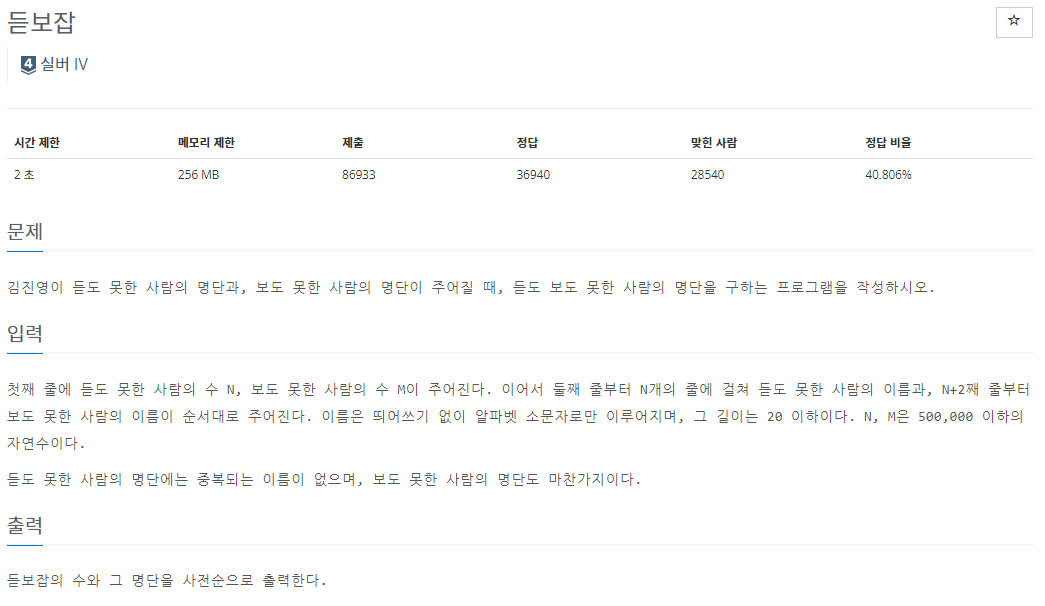
듣지도 못한사람 목록과
보지도 못한사람 목록이 주어진다.
둘 다 포함되는 사람의 이름들을 출력하면 되는 것이다.
시도
#include <iostream>
using namespace std;
int main(){
ios::sync_with_stdio(0);
cin.tie(0);
string s; // 듣지도 못한사람 목록
int N, M;
cin >> N >> M;
// 듣지도 못한사람 목록 추가
while(N--)
{
string a;
cin >> a;
s += a;
}
int count = 0;
string b[M]; // 보지도 못한사람 목록
while(M--)
{
string tmp;
cin >> tmp;
if(s.find(tmp) == -1)
{
continue;
}
else
{
b[count] = tmp;
count ++;
}
}
cout << count << "\n";
for(int i=0;i<count;i++)
{
cout << b[i] << "\n";
}
return 0;
}시간초과가 났다.
최대 1000만개의 글자를 입력으로 받을 수 있는 문제인데,
총 50만개의 문자열을 처리하기 위해선 다른 방법이 필요하다는 것이다.
문자열에 + 연산으로 추가할 때, s = s + "a"라는 연산을 조심하라고 해서
나름 += 연산자를 사용하여 시간복잡도를 줄였다고 생각했는데..
자료구조를 사용하여 더 간단히 만들어야 되는 듯 싶다.
그리고 출력 조건에 사전순으로 출력하는 부분도 염두에 두어야한다.
해결
#include <iostream>
#include <set>
using namespace std;
int main(){
ios::sync_with_stdio(0);
cin.tie(0);
string s; // 듣지도 못한사람 목록
int N, M;
cin >> N >> M;
set<string> d;
// 듣지도 못한사람 목록 추가
while(N--)
{
string a;
cin >> a;
d.insert(a);
}
int count = 0;
set<string> b;
while(M--)
{
string search;
cin >> search;
if(d.find(search)!=d.end()) //존재하면,
{
b.insert(search);
count++;
}
}
cout << count << "\n";
for(auto element : b)
{
cout << element << "\n";
}
return 0;
}풀이
Set자료구조를 사용하니 아주 간단히 해결되었다.
Set을 사용하여 먼저 듣 멤버들을 담는다.
굳이 Set을 하지 않아도 되고, 다만 find가 가능한 자료구조기만 하면 될듯
Set의 find를 사용하여 원소를 찾고, 해당 원소가 존재한다면,
다른 Set에 해당 원소들을 집어넣는다.
넣는 과정에서 자연스레 Set의 오름차순 Sort가 일어나게 되고,
출력조건에 맞게 정렬하여 출력할 수 있게 된다.
출력은 for문의 iterator를 사용하여 진행한다.
구현은 상당히 쉬웠지만, 조건이 생각보다 타이트했다.
실버4문제였는데, 경량화를 위한 부가적인 기능들에 대해 알 수 있어서 좋았다.
5. 1316 - 문자열
https://www.acmicpc.net/problem/1316
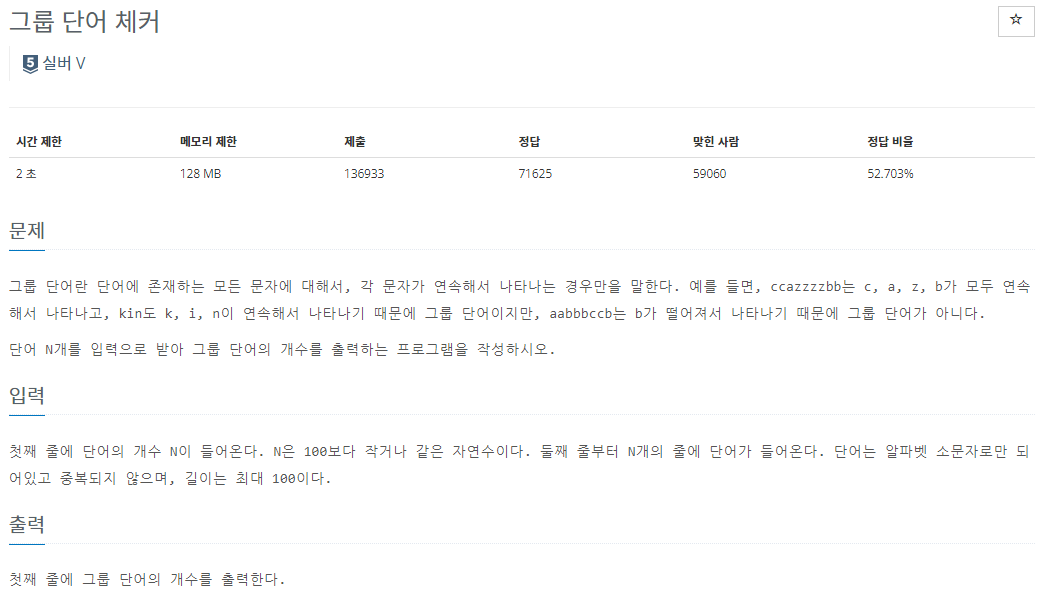
그룹단어라는 것의 개수를 체크하는 문제이다.
그룹단어는 abbcc, year 같은 1번이상 연속으로 나오는 단어를 의미한다.
abbcca면 안된다. 그러니까 한번 나왔던 문자가 또 나오면 안된다는 것이다.
visited를 만들고 나왔던 문자들을 표시하면 끝일 것이다.
해결
#include <iostream>
using namespace std;
int main(){
ios::sync_with_stdio(0);
cin.tie(0);
int N;
cin >> N;
// cout << 'a' << " : " << 'a' - 97;
// cout << 'z' << " : " << 'z' - 97;
int count = 0;
while(N--)
{
bool cantGroup = false;
bool visited[26] = {0, };
string s;
cin >> s;
for(int i=0; i<s.size(); i++)
{
if(i == 0)
{
visited[s[i] - 97] = true;
}
else
{
if(s[i-1] != s[i])
{
if(visited[s[i] - 97] == true)
{
cantGroup = true;
}
else
{
visited[s[i] - 97] = true;
}
}
}
}
if(cantGroup)
{
continue;
}
count ++;
}
cout << count;
return 0;
}풀이
단순 구현문제였다.
하지만 헷갈린 부분도 존재했다.
아스키 코드가 아직도 헷갈렸다.
- A가 65 / a가 97 인것을 명심하자
(알파벳은 총 26개)
cout << 'a' << " : " << 'a' - '97';
cout << 'a' << " : " << 'a' - 97;- 그리고 위처럼 빼는 수에 문자취급을 해야할까 잠시 헷갈렸는데,
문자나 문자열이 아닌 무조건 일반 숫자를 빼야한다.
a는 시도해보니 문자열과 문자 둘다 상관없었다.
6. 1181 - 문자열
https://www.acmicpc.net/problem/1181
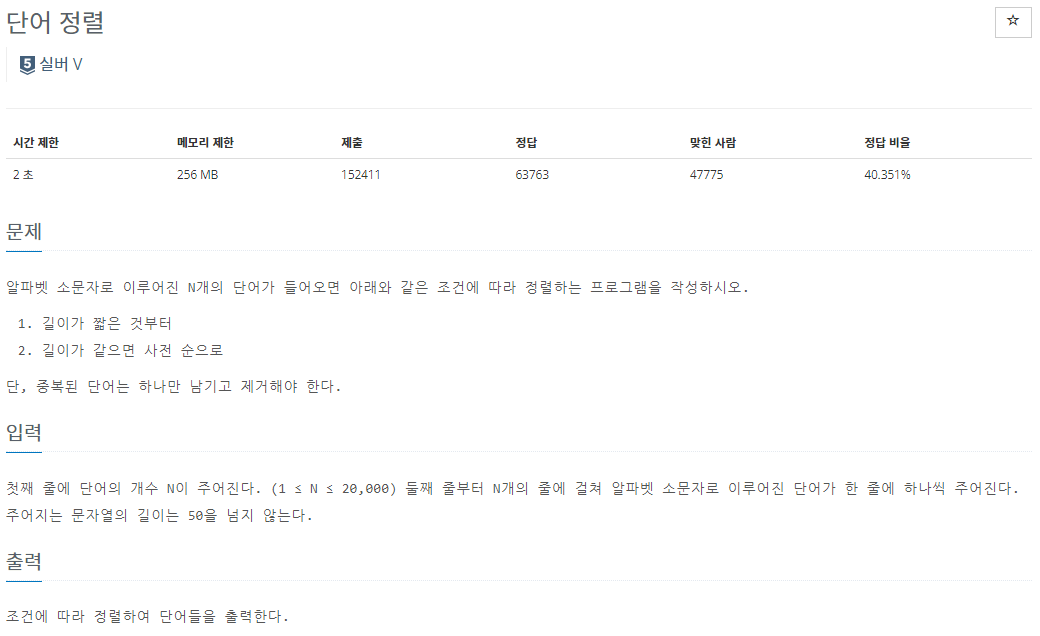
입력받은 단어들을 중복없이 출력하면 된다.
기준은 길이대로, 그리고 같은 길이면 사전순으로.
해결
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
string beforeSTR = " ";
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int N;
cin >> N;
vector<pair<int, string>> sGroup;
while (N--)
{
string s;
cin >> s;
//auto it = find(sGroup.begin(), sGroup.end(), make_pair(s.size(), s));
sGroup.push_back({s.size(), s});
}
sort(sGroup.begin(), sGroup.end());
for (auto element : sGroup)
{
if(beforeSTR!=element.second)
{
cout << element.second << "\n";
}
beforeSTR = element.second;
}
return 0;
}풀이
중복된 답이 출력이 되면 안돼서 set을 사용하여 진행했는데,
같은 길이의 문자열을 파악하기 힘들어서
vector 자료형에 pair<int, string>을 넣어 사용하였다.
#include <algorithm>을 추가하면, sort함수를 사용할 수 있다.
해당 함수로 vector를 정렬할 수 있게 된다.
vector의 pair정렬은 앞의것부터, 앞의조건이 같다면 뒤의조건으로.
이런식으로 진행이되어 한번에 알맞게 분류가 된다.
하지만,
중복된 단어는 vector가 제거하지 못했고,
find를 사용하여, 중복된 단어를 하였다.
하지만 vector의 멤버함수에는 find가 없고,
algorithm의 find를 사용해야하는데, pair면, find if를 사용하여
엄청 복잡한 식을 사용해야했다.
sort(sGroup.begin(), sGroup.end());
for (auto element : sGroup)
{
if(beforeSTR!=element.second)
{
cout << element.second << "\n";
}
beforeSTR = element.second;
}그래서 출력부에 위처럼 해결하기로 하였다.
전역변수 beforeSTR을 두고,
이전에 출력했던 값과 같다면, 출력하지 않는 단순한 코드이다.
해결.
