https://devjeong.com/algorithm/algorithm-1/
좋은 문자열문제를 따로 고를 필요없이,
정리된 위의 사이트의 문자열 문제들을 풀어본다.
1. 2870 - 문자열
https://www.acmicpc.net/problem/2870
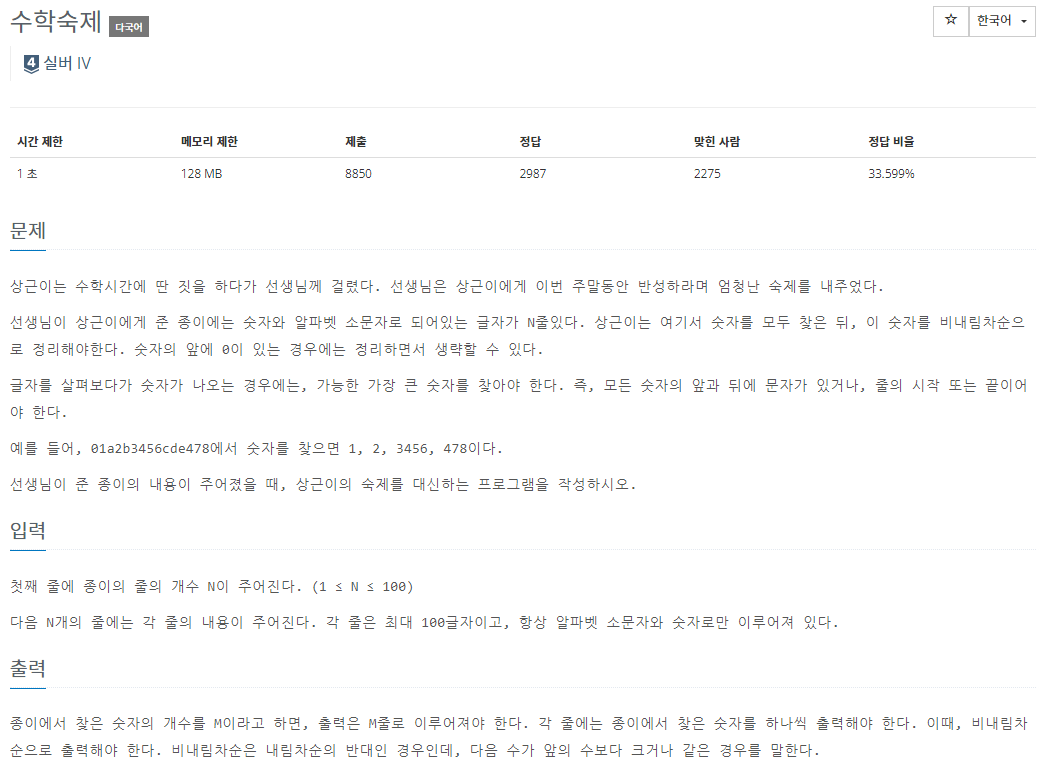
주어지는 문자열 속에서 숫자를 찾아내어 정렬을 하는 것이
핵심인 문제다.
중복도 가능하기 때문에 vector형에 sort를 사용해야겠다.
시도
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int N;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
cin >> N;
vector<int> num;
bool enterFlag = false;
while (N--)
{
string s, s_num;
cin >> s;
bool isEntered = false;
for (int i = 0; i < s.size(); i++)
{
if(isEntered)
{
s_num = "";
isEntered = false;
}
if (s[i] - 58 < 0)
{
s_num += s[i];
}
if (s_num != "" && (i == s.size()-1 || (i+1 != s.size() && s[i+1] - 58 > 0)))
{
num.push_back(stoi(s_num)); // string to int
isEntered = true;
}
}
}
sort(num.begin(), num.end());
for (auto n : num)
{
cout << n << "\n";
}
return 0;
}런타임 에러가 떴다.
그 이유는 문제의 조건 때문이었다.

위의 조건이었는데,
나올 수 있는 수의 최대값은 100글자짜리 수이다.
18~19자리인 long long을 아득히 뛰어넘는 말도 안되는 수였던 것이다.
그러니까 그냥 string으로 담으라는 이야기이다.
해결
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int N;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
cin >> N;
vector<pair<int, string>> num;
bool enterFlag = false;
while (N--)
{
string s, s_num;
cin >> s;
bool isEntered = false;
for (int i = 0; i < s.size(); i++)
{
if (isEntered)
{
s_num = "";
isEntered = false;
}
// 숫자면 s_num 문자열에 차곡차곡 쌓음
if (s[i] - 58 < 0)
{
if (s_num == "" && s[i] == '0') // 숫자의 처음인데, 0이 들어온경우
{
// 다음 문자가 숫자인 경우 스킵
if (i+1 != s.size() && s[i + 1] - 58 < 0)
{
continue;
}
}
// 그게 아닐 경우 더함. 이 경우는 0 홀로 숫자로 오는 경우도 포함.
s_num += s[i];
}
// 다음 문자가 문자라면 숫자가 끝났으므로 vector에 넣음
if (s_num != "" && (i == s.size() - 1 || (i + 1 != s.size() && s[i + 1] - 58 > 0)))
{
num.push_back({s_num.size(), s_num}); // string to int
isEntered = true;
}
}
}
sort(num.begin(), num.end()); // 숫자는 size에 맞게 정렬해야함.
for (auto n : num)
{
// cout << n.second << " : this" "\n";
for (int i = 0; i < n.first; i++)
{
cout << n.second[i];
}
cout << "\n";
}
return 0;
}풀이
조건이 굉장히 까다로운 문제였다.
0 혼자 나와도 되고, 숫자로 따지는 맨 앞의 0은 또 생략해도 되고,
정렬도 해야하고 그런 문제였는데,
조건만 제대로 구현하면 나머지는 이전에 풀어본 문제와 비슷했다.
vector<pair<int, string>>으로 만들어두고,
int에 size를 넣어서 size대로 정렬하고 같은 size면 string대로 정렬하는
전형적인 방식을 사용하였다.
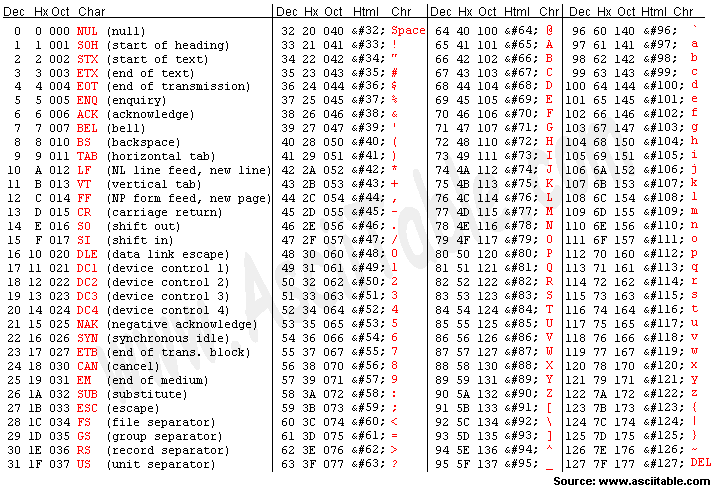
그리고 문자열 문제를 풀때마다 아스키 코드표를 참고하는데,
안보도록 숙달되어야 할 것 같다.
48~57까지 0~9
65~90까지 A~Z
97~122까지 a~z
한 번 cout으로 출력해보면 알긴 하기 때문에 굳이 외울 필요는 없겠지만,,
대략 40~60은 숫자 / 60~90은 대문자 / 90~130은 소문자
이런식으로나마 알아두면 좋을 것 같다.
2. 20920 - 문자열
https://www.acmicpc.net/problem/20920
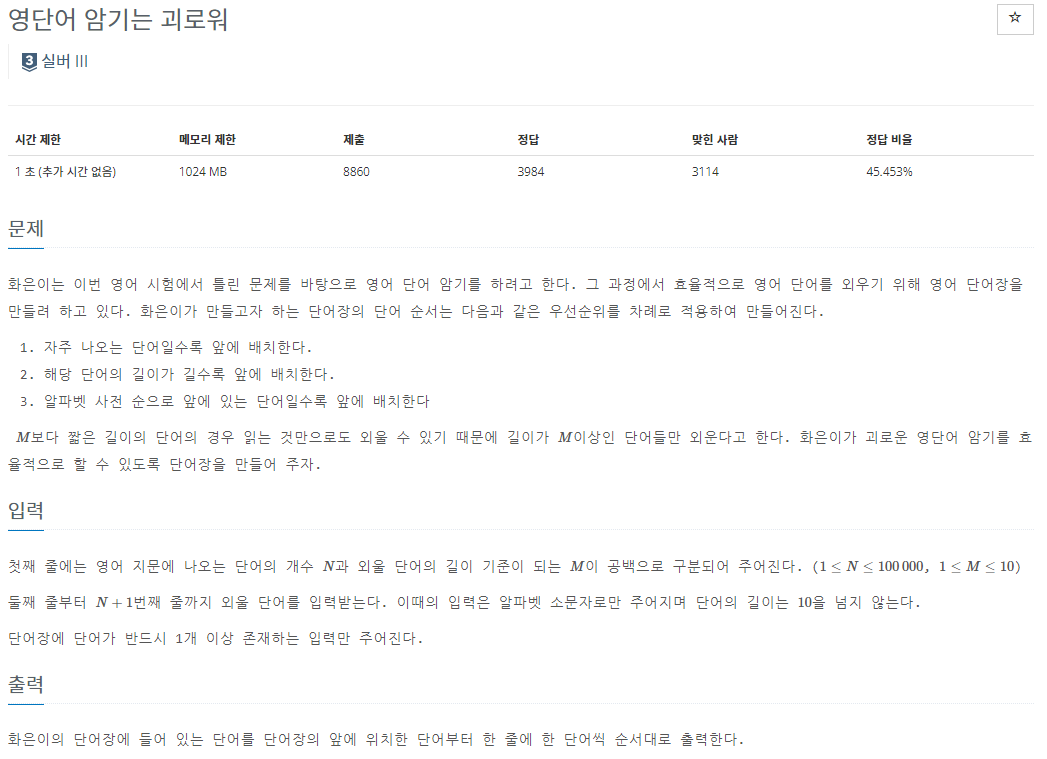

정렬 조건이 3개이다. vector로 sort하면 알아서 될 것 같긴한데..
한 번 해보자.
시도
#include <iostream>
#include <vector>
#include <map>
#include <algorithm>
using namespace std;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int N, M;
cin >> N >> M;
map<string, int> wordMap; // str, count
vector<pair<int, pair<int, string>>> wordVec; // (count, (size, str))
// 중복되는 입력을 하지 않고, count를 계산하여 Map에 저장
while (N--)
{
string s;
cin >> s;
if (s.size() < M)
{
continue;
}
if (wordMap.find(s) == wordMap.end())
{
wordMap.insert({s, 0});
}
else
{
wordMap[s]++; // 값을 수정 count ++
}
}
// 정렬하기 위해 벡터에 넣음
for (auto w : wordMap)
{
wordVec.push_back({w.second, {w.first.size(), w.first}});
cout << w.first << " : " << w.first.size() << " / " << w.second << "\n";
}
sort(wordVec.begin(), wordVec.end(), greater<pair<int, pair<int, string>>>());
//reverse(wordVec.begin(), wordVec.end());
// 출력
cout << "\n\n[print]\n";
for (auto str : wordVec)
{
cout << str.second.second << " : " << str.first << "\n";
}
return 0;
}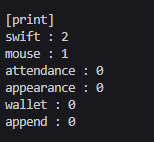
wallet이 먼저 나오는 것부터 이상하다.
해결
#include <iostream>
#include <vector>
#include <map>
#include <algorithm>
using namespace std;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int N, M;
cin >> N >> M;
map<string, int> wordMap; // str, count
vector<pair<int, pair<int, string>>> wordVec; // (count, (size, str))
// 1 중복되는 입력을 하지 않고, count를 계산하여 Map에 저장
while (N--)
{
string s;
cin >> s;
if (s.size() < M)
{
continue;
}
if (wordMap.find(s) == wordMap.end())
{
wordMap.insert({s, 0});
}
else
{
wordMap[s]++; // 값을 수정 count ++
}
}
// 2 정렬하기 위해 벡터에 넣음
for (auto w : wordMap)
{
wordVec.push_back({w.second, {w.first.size(), w.first}});
}
// 핵심 코드
sort(wordVec.begin(), wordVec.end(), [](pair<int, pair<int, string>> a, pair<int, pair<int, string>> b)
{
if(a.first == b.first && a.second.first == b.second.first)
{
return a.second.second < b.second.second;
}
return a>b;
}
);
// 3 출력
for (auto str : wordVec)
{
cout << str.second.second <<"\n";
//" : " << str.first << "\n";
}
return 0;
}풀이
풀이 순서는 주석과 같다.
먼저 map에 중복을 제거하고 입력을 담으면서, count를 세어 집어넣는다.
(key를 string으로 두어서 중복이 되지 않는다)
그 다음 map의 값을 vector에 적절히 집어넣는다.
그 이유는 vector의 sort연산을 하기 위함이다.
vector를 사용하는 이유는, 다양한 자료형이 가능해서이다.
pair의 pair를 감싼 형태를 사용한다.
그냥 sort를 하면, 오름차순으로 정렬이 된다.
0 1 2
하지만 greater를 사용하여 내림차순을 하면, 모든 조건이 내림차순이 되어버린다.
즉 글자도 wallet 다음 append가 나오는 불상사가 일어난다.
따라서 세부적인 조건을 설정해야했고,
sort함수에 비교함수를 집어넣었다.
// 핵심 코드
sort(wordVec.begin(), wordVec.end(), [](pair<int, pair<int, string>> a, pair<int, pair<int, string>> b)
{
if(a.first == b.first && a.second.first == b.second.first)
{
return a.second.second < b.second.second;
}
return a>b;
}위의 기능은 우선 맨 아래 a>b부터 보면,
a가 더 크면 더 먼저 나오게 한다는 것이다.
그러니까 내림차순을 의미한다.
if문을 보면, first가 같을 때, second.first가 같을 때
(3개중 2개의 조건이 같다면)
마지막 조건을 기준으로 정렬하라는 것인데,
a<b라는 것은 a가 더 작으면 먼저나오게 하라는 것이므로,
한 sort내에서 오름,내림차순 정렬을 섞어서 사용할 수 있게 된다.
비교함수 만드는 법은 은근 간단하다.
[] (내부자료형 a, 내부자료형 b) // 매개변수 { // 내부 코드 // 무조건 return bool 이어야 한다. // true라면, a를 b보다 먼저나오게 만든다. }비교함수만 제대로 사용하면, 조건이 몇백개라도 제대로 출력할 수 있게 된다.
문자열이 아니라 다른 문제에도 유용할 수 있을 것 같다.
3. 2607 - 문자열
https://www.acmicpc.net/problem/2607
GOD와 DOG는 비슷한 단어이다.
같은 문자가 같은 개수만큼 들어갔기 때문이다.
이런 비슷한 단어가 몇 개인지 출력한다.
단어는 100개, 각 단어의 최대길이는 10개라서
어떻게 구현하든 상관 없어보인다.
시도
#include <iostream>
#include <set>
using namespace std;
int main(){
ios::sync_with_stdio(0);
cin.tie(0);
//65
set<int[26]> similar;
int N;
cin >> N;
int count = 0;
while(N--)
{
int alphabet[26] = {0, };
string s;
cin >> s;
for(char c : s)
{
alphabet[c-65]++;
}
if(similar.find(alphabet) != similar.end())
{
count ++;
}
else
{
similar.insert(alphabet);
}
}
cout << count;
return 0;
}안된다.
set에 배열값을 넣는게 안된다.
그리고 애초에 문제를 이상하게 이해해서 전부 수정한다.
시도 2
#include <iostream>
using namespace std;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int N;
cin >> N;
bool alphabet[26] = {
false,
};
cout <<"\n\n[print]\n";
string answer;
cin >> answer;
for (char c : answer)
{
alphabet[c - 65] = true;
}
int count = 0;
for(int i=1; i<N; i++)
{
string s;
cin >> s;
bool similarFlag = true;
for (char c : s)
{
if (!alphabet[c - 65])
{
similarFlag = false;
break;
}
}
if(similarFlag)
{
cout << s <<"\n";
count ++;
}
}
cout << count;
return 0;
}안된다.
애초에 문제가 무슨 문제인지 이해하는게 필요해보인다..
[같은 구성]
1서로 같은 종류의 문자로 이루어져있다.
그리고
2같은 문자는 같은 개수만큼 있다.
- 다른 문자가 있을 경우는?
- 다른 문자는 다른 개수만큼 있을 경우는?
조건이 애매한데.. 일단 없다고 본다.
그러니까 GOD와 GODS는 다른구성이라는 것이다.[비슷한 단어] - 이걸 찾는게 목표
1[같은 구성]인 경우.
혹은
2한 문자를 더하기/빼기/바꾸기를 하여 [같은구성]이 되는 경우
헤결
#include <iostream>
#include <string>
using namespace std;
int count = 0;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int N;
cin >> N;
int alphabet[26] = {
0,
};
string s;
cin >> s;
int slength = s.length();
for (char c : s)
{
alphabet[c - 65]++;
}
for (int n = 0; n < N - 1; n++)
{
// tmpAlphabet에 값 복사
int tmpAlphabet[26];
for (int i = 0; i < 26; i++)
{
tmpAlphabet[i] = alphabet[i];
}
string str;
cin >> str;
int minus = 0;
int plus = 0;
bool wrongFlag = false;
// cout << str << " " << str.length() - slength <<"\n";
if (slength == str.length() || str.length() - slength == -1 || str.length() - slength == 1)
{
// 값 수정
for (int i = 0; i < str.length(); i++)
{
tmpAlphabet[str[i] - 65]--;
}
// minus / plus 요소 찾기
for (int i = 0; i < 26; i++)
{
if (tmpAlphabet[i] > 1 || tmpAlphabet[i] < -1)
{
wrongFlag = true;
break;
}
if (tmpAlphabet[i] == -1)
{
minus++;
}
else if (tmpAlphabet[i] == 1)
{
plus++;
}
}
if (wrongFlag)
{
continue;
}
// 입력값이 더 큰 경우 : 제거
if (str.length() - slength == 1 && minus == 1 && plus == 0)
{
// cout << "(DEL)" << str << "\n";
count++;
}
// 입력값이 같은 경우 : 완전히 같다
else if (str.length() - slength == 0 && minus == 0 && plus == 0)
{
// cout << "(SAM)" << str << "\n";
count++;
}
// 입력값이 같은 경우 2 : 수정
else if (str.length() - slength == 0 && minus == 1 && plus == 1)
{
// cout << "(MOD)" << str << "\n";
count++;
}
// 입력값이 더 작은 경우 : 추가
else if (str.length() - slength == -1 && minus == 0 && plus == 1)
{
// cout << "(ADD))" << str << "\n";
count++;
}
}
}
cout << count;
return 0;
}풀이
구현문제라고 해도 무방했다.
조건을 최대한 깨끗하게 작성해보려 했다.
하지만 조건이 워낙 복잡하다보니 최선으로 구현한 것 같다.
예외 상황도 많았고, 구현에 시간이 굉장히 많이 걸렸던 것 같다.
풀고나니 뿌듯하긴 한데, 무작정 코드를 짜지 말고
조건을 더 차분히 생각한 후에 진행하는 것이
시간을 더 아낄 수 있다는 생각이 들엇다.
4. 1213 - 문자열
https://www.acmicpc.net/problem/1213
입력으로 들어오는 글자를 적절히 조합해서
가능한 사전순으로 가장 빠른 회문을 만드는 것이 목표이다.
글자들의 개수를 받고,
홀수인 글자가 없거나, 단 하나라면 회문을 만들 수 있을 것이다.
그리고 글자순대로 배치하면 끝일 것이다.
해결
#include <iostream>
#include <queue>
#include <stack>
#include <string>
using namespace std;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
string s;
cin >> s;
int alphabet[26] = {
0,
};
// 입력
for (char c : s)
{
alphabet[c - 65]++;
}
// 회문이 가능한지 점검
int odd = 0;
for (int i = 0; i < 26; i++)
{
if (alphabet[i] % 2 == 1)
{
odd++;
}
}
if (odd > 1)
{
cout << "I'm Sorry Hansoo";
return 0;
}
// 회문 생성
int oddIDX = 0;
stack<char> half_back;
string half_front = "";
for (int i = 0; i < 26; i++)
{
if (alphabet[i] != 0 && alphabet[i] / 2 > 0) // 5/2 = 2 + 1
{
int m = alphabet[i] / 2;
for (int k = 0; k < m; k++)
{
alphabet[i] -= 2;
char a = (char)(i + 65);
half_front += a; // 될까?
half_back.push(a);
}
}
}
// 가운데 홀수글자 끼우기
if (odd == 1)
{
for (int i = 0; i < 26; i++)
{
if (alphabet[i] == 1)
{
half_front += (char)(i+65);
}
}
}
// 나머지 반 생성
while (!half_back.empty())
{
half_front += half_back.top();
half_back.pop();
}
cout << half_front;
return 0;
}풀이
alphabet이라는 글자의 개수를 담는 배열 하나를 두었다.
해당 배열로부터 홀수 글자가 1개 초과라면, 회문을 만들 수 없으므로 중지한다.
아니면 회문을 생성한다.
회문을 생성하는 방법은,
2로 나눴을 때, 몫이 있는 글자를, 몫만큼 반복하여
회문의 앞쪽에 더한다. (half_front)
(데칼코마니로 회문의 앞, 회문의 뒤로 나누어보았다)
같은 글자를 stack에 넣는다. (half_back)
홀수 글자가 있다면, half_front가 생성된 후에 추가한다.
그리고 half_back의 stack을 pop하면서 더하면 끝.
구현이 생각대로 되어서 상당히 쉬웠다.
alphabet배열을 생성한다는 점은 이전문제가 많은 도움이 되었다.
5. 9996 - 문자열
https://www.acmicpc.net/problem/9996
a*c 같은 조건이 주어지면, 시작이 a이고 끝이 c인 문자열을 구분한다.
맞으면 DA, 틀리면 NE 라고 한다.
별은 시작과 끝에 있지 않고, 단 하나만 중간에 존재한다는 점에서
매우 난이도가 쉬운 문제같은데.. 정답률이 30%가 안된다.
조건문이 a*h처럼 소문자 2개만 오지는 않을 수도 있다고 생각한다.
여러개의 소문자와 별표하나로 이루어져있다고 한다.
따라서 이 조건을 구현하는게 가장 핵심으로 보인다.
해결
#include <iostream>
#include <vector>
using namespace std;
int main(){
ios::sync_with_stdio(0);
cin.tie(0);
int N;
cin >> N;
vector<char> front;
vector<char> back;
string str;
cin >> str;
// 입력값을 2개의 vector에 나눠서 저장
bool isBack = false;
for(char c:str)
{
if(!isBack)
{
if(c == '*')
{
isBack = true;
continue;
}
front.push_back(c);
}
else
{
back.push_back(c);
}
}
while(N--)
{
string s;
cin >> s;
bool badWord = false; // 플래그
// 중요한 조건
if(s.size() < front.size()+back.size())
{
cout << "NE\n";
continue;
}
//앞 확인
for(int i=0;i<front.size();i++)
{
if(s[i] != front[i])
{
badWord = true;
}
}
//뒤 확인
for(int i=0;i<back.size();i++)
{
if(s[s.size()-1-i] != back[back.size()-1-i])
{
badWord = true;
}
}
//출력
if(badWord)
{
cout << "NE\n";
}
else
{
cout << "DA\n";
}
}
return 0;
}풀이
*을 기준으로 2개의 벡터에 입력을 담고,
입력받는 string의 앞에서, 뒤에서부터 글자를 각각 비교하였다.
// 중요한 조건
if(s.size() < front.size()+back.size())
{
cout << "NE\n";
continue;
}위의 조건을 빼먹었었는데,
상당히 중요한 조건이었다.
abc*cbd일 때, abcd라면 안되는 것이기 때문이다.
조건을 생각해내는 것 말고는 크게 어려운게 없는 문제.
6. 22233 - 문자열 / Unordered_Set
https://www.acmicpc.net/problem/22233

문제는 간단해보이는데, 제한이 상당히 빡빡해보인다.
vector에 다 담고, 나오면 erase하는 방식을 생각했었는데..
erase연산이 지우고, 인덱스를 당겨야하는 작업이라서
상당히 비용이 크다고 들었었기 때문에 다른 방법을 생각해본다.
시도
#include <iostream>
#include <vector>
using namespace std;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int N, M;
cin >> N >> M;
vector<pair<string, bool>> memo;
while (N--)
{
string s;
cin >> s;
memo.push_back({s, true});
}
while (M--)
{
string s;
cin >> s;
vector<string> keyword;
string tmp = "";
for (int i = 0; i < s.size(); i++)
{
if (s[i] != ',')
{
tmp += s[i];
}
if (s[i] == ',' || i == s.size() - 1)
{
keyword.push_back(tmp);
tmp = "";
}
}
for (auto key : keyword)
{
//cout << "[Key Is : " << key << "] \n";
for (auto& m : memo)
{
//cout << "Memo Is : " << m.first << " \n";
if (key == m.first)
{
m.second = false;
//cout << "this is same : " << m.second << "\n";
}
}
}
int count = 0;
for (auto m : memo)
{
if (m.second == true)
{
//cout << "count : " << m.first << "\n";
count++;
}
}
cout << count << "\n";
}
return 0;
}막상 구현해보니 다중 for문 없이 구현하기가 쉽지 않았다.
시간초과가 났다.
질문게시판을 보니, 특정 자료구조를 사용해야만 풀리는 문제라고 한다.
그건 set이고, set은 자동정렬이 되니까 이마저도 삭제한
unordered_set을 사용해야 풀린다고 한다.
해결
#include <iostream>
#include <vector>
#include <unordered_set> // 일반 set을 추가하면 안됨.
using namespace std;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int N, M;
cin >> N >> M;
unordered_set<string> memo;
while (N--)
{
string s;
cin >> s;
memo.insert(s);
}
while (M--)
{
string s;
cin >> s;
vector<string> keyword;
// 1 데이터 파싱
string tmp = "";
for (int i = 0; i < s.size(); i++)
{
if (s[i] != ',')
{
tmp += s[i];
}
if (s[i] == ',' || i == s.size() - 1)
{
keyword.push_back(tmp);
tmp = "";
}
}
// 2 키워드 있는지 검색 및 삭제
for (auto key : keyword)
{
if(memo.find(key)!=memo.end())
{
memo.erase(key);
}
}
// 3 출력
cout << memo.size() << "\n";
}
return 0;
}풀이
그냥 unordered_set을 사용하니 풀렸다.
사용하는 방법은 set과 같다.
erase나 find를 사용하여 훨씬 간단히 구현이 되었다.
순서가 상관없고, 중복없이 저장하기 위해선
자료구조 중에 unordered_set이 가장 효율적이겠다는 생각이 들었다.
