
25.07.04 수정
해당 글은 클린아키텍처가 아닌, 안드로이드 공식 홈페이지의 앱 아키텍처에 대한 글입니다.
0. 시작하며
[안드로이드 Clean Architecture란 무엇인가]의 이전 포스팅에선 다음을 다뤄보았습니다.
이번 포스팅에선 각 레이어들의 개념과 책임에 대해 명확히 알고 있다는 전제로 안드로이드 클린 아키텍쳐를 설계하는 방법에 대해 알아보고자 합니다.
[잠깐]
설계에는 정답이 없습니다. 어찌보면 예술의 영역이라고도 할 수 있죠. 그러기에 이 글에서 말씀드리는 설계 방법은 여러가지 중 하나일 뿐, 정답이 아니라는것을 말씀드립니다.
그리고 아키텍쳐를 설계하는데 있어, 제가 가장 중요하다고 생각하는 SOLID원칙 중 하나인 '의존성 역전의 원칙'에 대해 먼저 알아볼까 합니다. 그 후, 의존성 역전 원칙을 사용한 설계 과정을 알아보도록 하겠습니다.
1.의존성 역전이란?
이는 간단히 말해 두 모듈간의 의존이 역전되었다는걸 의미합니다. 예를 들어, UserInfoRepository모듈이 UserInfoDataSource모듈의 프로퍼티와 메서드를 사용하고자 합니다. 그러면 UserInfoRepository모듈은 UserInfoDataSource모듈에 필연적으로 의존해야만 합니다. 아래와 같이 말이죠.
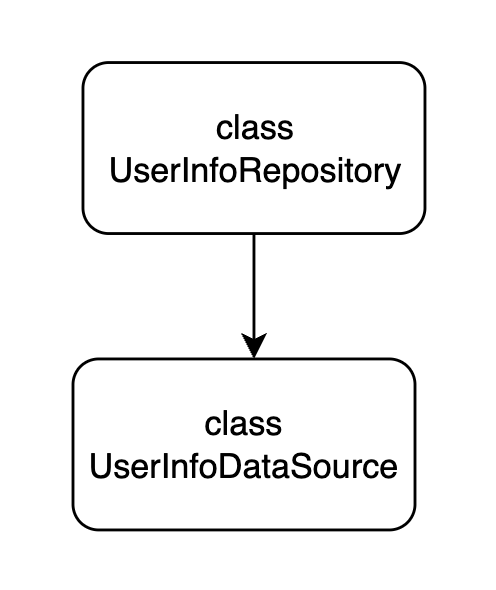
class UserInfoRepository {
val userInfoDataSource = UserInfoDataSource()
userInfoDataSource.getUserInfo(id = "...")
}
class UserInfoDataSource {
fun getUserInfo(id: String): UserInfo { ... }
}만약 소스코드가 위와 같은 의존구조를 가지게 된다면 문제가 발생합니다. 그것은 바로, 위와 같은 의존 구조로 인해 UserInfoDataSource모듈이 변경이 되었을 때, UserInfoRepository모듈에도 필연적인 영향이 간다는 것이죠.
class UserInfoRepository {
val userInfoDataSource = UserInfoDataSource()
userInfoDataSource.getUserInfo(id = "...") // Compile Error
}
class UserInfoDataSource {
// country 파라미터의 추가
fun getUserInfo(id: String, country: String): UserInfo { ... }
}하지만 Interface를 통해 의존성이 역전되면 어떻게 될까요?
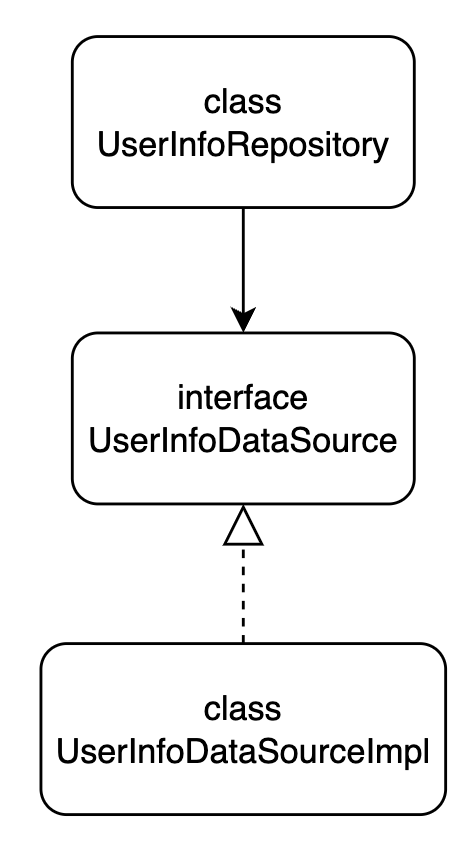
class UserInfoRepository {
val userInfoDataSource: UserInfoDataSource = UserInfoDataSourceImpl()
userInfoDataSource.getUserInfo(id = "...")
}
interface UserInfoDataSource {
fun getUserInfo(id: String): UserInfo
}
class UserInfoDataSourceImpl {
fun getUserInfo(id: String, country: String = "ko"): UserInfo { ... }
}위 화살표 방향과 코드를 보고 직관적으로 알 수 있듯, UserInfoRepository모듈이 UserInfoDataSourceImpl모듈에 '직접 의존하지 않습니다.'
UserInfoRepository의 의존은 추상 모듈인 UserInfoDataSource에 하고 있으며, UserInfoDataSourceImpl엔 '직접 의존하지 않습니다.' 그리고 이때 UserInfoDataSourceImpl모듈은 UserInfoDataSource인터페이스 모듈을 '구현함으로써 인터페이스에 의존하게 됩니다.'
그럼 위와 같은 구조가 왜 유용한 걸까요?? 그 이유는 바로 소프트웨어의 변경사항에 더 유연하게 대처할 수 있기 때문입니다. 구체적으로 말해보자면, 'interface가 보유하고 있는 추상 메서드의 시그니처와 반환 타입을 유지한 상태로, 메서드 내부 구현만 변경하면 되기 때문'입니다. 아주 중요한 개념이므로 한번 더 강조하고 가겠습니다.
유지보수는 메서드의 시그니처와 반환타입을 유지한 상태로 단순히 메서드 내부의 구현만 변경한다.
그렇게 되었을 때, UserInfoRepository가 의존하고 있는 UserInfoDataSource는 아무런 변경이 진행되지 않습니다. 그저, UserInfoDataSourceImpl의 내부 구현만 변경하면 될 뿐입니다. 그에 따라, UserInfoRepository는 작업 진행의 필요성 또한 사라지게 되는 것입니다.
interface UserInfoDataSource {
// 확장성을 고려하여 country의 기본 값을 "ko"라고 설정함으로써 interface메서드를 설계하였다.
fun getUserInfo(id: String, country: String = "ko"): UserInfo
}
class UserInfoRepositoryImpl {
override fun getUserInfo(id: String, country: String = "ko"): UserInfo {
// 기존엔 유저 정보를 한국 서버로부터만 가져오도록 되어 있었다.
// 하지만 요구사항의 변경으로 외국으로부터 유저 정보를 가져올 수 있게 하도록 변경되었다.
// 만약 interface가 잘 설계되어 있었다면, getUserInfo()메서드에 의존하고 있는 모듈은 그 어떤 변경도 하지 않아도 된다.
}
}
즉, 위 이미지의 화살표 방향을 통해서 직관적으로 알 수 있듯, 두 모듈간 의존 화살표 방향이 바뀌는 형태를 '의존성이 역전되었다'라고 합니다.
하지만 이런 의문이 드실 수 있다고 생각합니다.
아니.. 그럼 요구사항 변경에 있어서 메서드의 시그니처를 바꿔야만 하는 상황은 어떻게 해야해??
결론부터 말씀드리면, 그런 요구사항의 변경이 있다면 아마 interface의 메서드 시그니처와 반환타입을 변경해야할지도 모릅니다. 하지만 interface를 설계하는 가장 큰 의의 중 하나는 미래에 있을 소프트웨어의 변경사항에 대비하여 메서드 시그니처와 반환타입을 심도 있게 설계함으로써 내부 구현만 변경할 수 있도록 진행하는 것을 의미합니다.
좀 더 구체적으로 말씀드려보겠습니다. 위에서 보여드린 인터페이스의 메서드는 아래와 같은 구조로 되어 있습니다.
fun getUserInfo(id: String, country: String = "ko"): UserInfo위의 구조에서 메서드의 시그니처는 String타입의 id와 country가 존재하며, 반환타입은 UserInfo로 존재합니다. 즉, 인터페이스를 설계할 땐, 위처럼 변경에 강하도록 구조를 미리 설계하고 이 형태를 최대한 지켜나가겠다 라는 의도로 설계해야 해야하는 것입니다.
이제 의존성 역전 원칙에 대한 설명이 끝났으며 안드로이드 클린 아키텍쳐를 위한 각 Layer들의 Interface설계에 대해 알아보도록 하겠습니다.
2. 각 Layer들의 Interface설계하기
이전에서 알아봤듯, 각 Layer들엔 다음과 같이 있었습니다.
- UI Layer
- Activity, Fragment, view.xml, Compose UI
- ViewModel(StateFlow or/and LiveData)
- Domain Layer
- UseCase
- Data Layer
- Repository
- DataSource
위 모듈들 중, DomainLayer와 Data Layer를 먼저 다뤄보겠습니다. 위 Layer들의 각 모듈은 모두 Interface를 가질 수 있었습니다. 즉, 아래와 같은 형태로 말이죠.
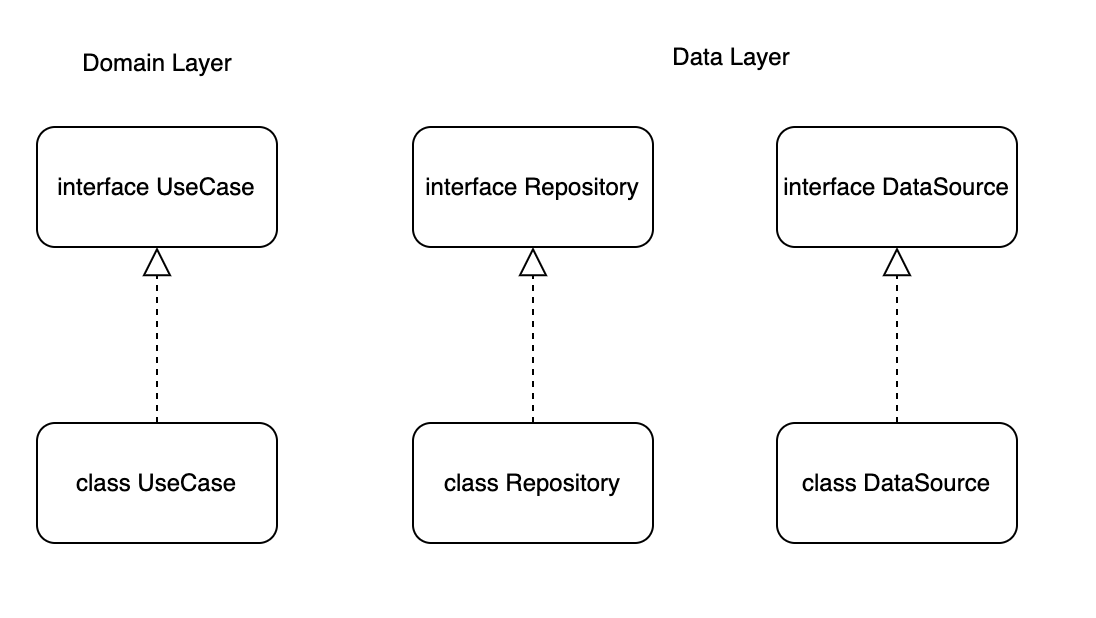
위의 화살표를 보시면 아시겠지만, 구체적인 class모듈들은 모두 추상적인 interface모듈에 의존하고 있습니다. 이를 코드로 나타내보면 아래와 같은 모습을 띄게 됩니다.
// UseCase
interface LoginUseCase { ... }
class LoginUseCaseImpl: LoginUseCase { ... }
// Repository
interface UserInfoRepository { ... }
class UserInfoRepositoryImpl: UserInfoRepository { ... }
// DataSource
interface UserInfoDataSource { ... }
class UserInfoDataSourceImpl: UserInfoDataSource { ... }코드는 아주 단순한 구조로 이루어져 있습니다. 상위 Interface추상 모듈이 있고, 이를 class구체 모듈이 의존하고 있는 구조입니다.
그럼 이제 위 모듈들을 하나의 그래프로 합쳐보도록 하겠습니다. 우선, 합치기 전에 이전 포스팅에선 제가 안드로이드의 아키텍쳐 구조는 아래 이미지의 형상을 띈다는 것을 말씀드렸습니다.
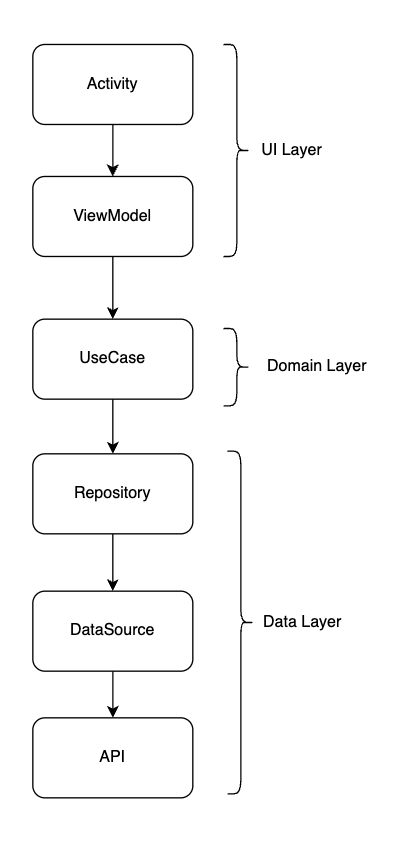
하지만 위의 아키텍쳐 구조에서 추상화된 모듈이 들어가면 어떻게 바뀔까요? 바로 '의존성 역전'원칙에 따라 모듈들간의 의존구조가 역전되게 됩니다. 아래와 같이 말이죠.
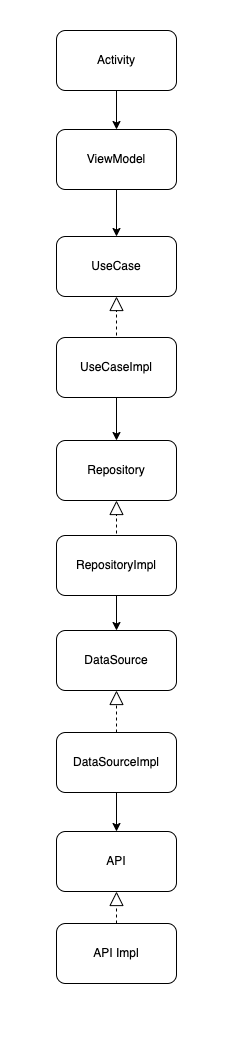
그럼 이제 위 아키텍쳐를 기반으로 안드로이드 클리 아키텍쳐를 설계하는 과정을 보여드리도록 하겠습니다. 다만 설계 전, 요구사항이 어떤지 먼저 알아야 앱 설계가 가능하겠죠?
3. 요구사항 정의
앱을 설계하기 위해선 반드시 고객의 요구사항을 정확히 알고 있어야만 합니다. 또한 요구사항 분석이 끝난 후, 기획팀의 의도를 분석해야하고, 서버팀의 API의도를 분석해야 하죠. 설계에 들어가기 전, 업무의 프로세스를 다음과 같은 순서로 대략적으로 나타내볼 수 있습니다.
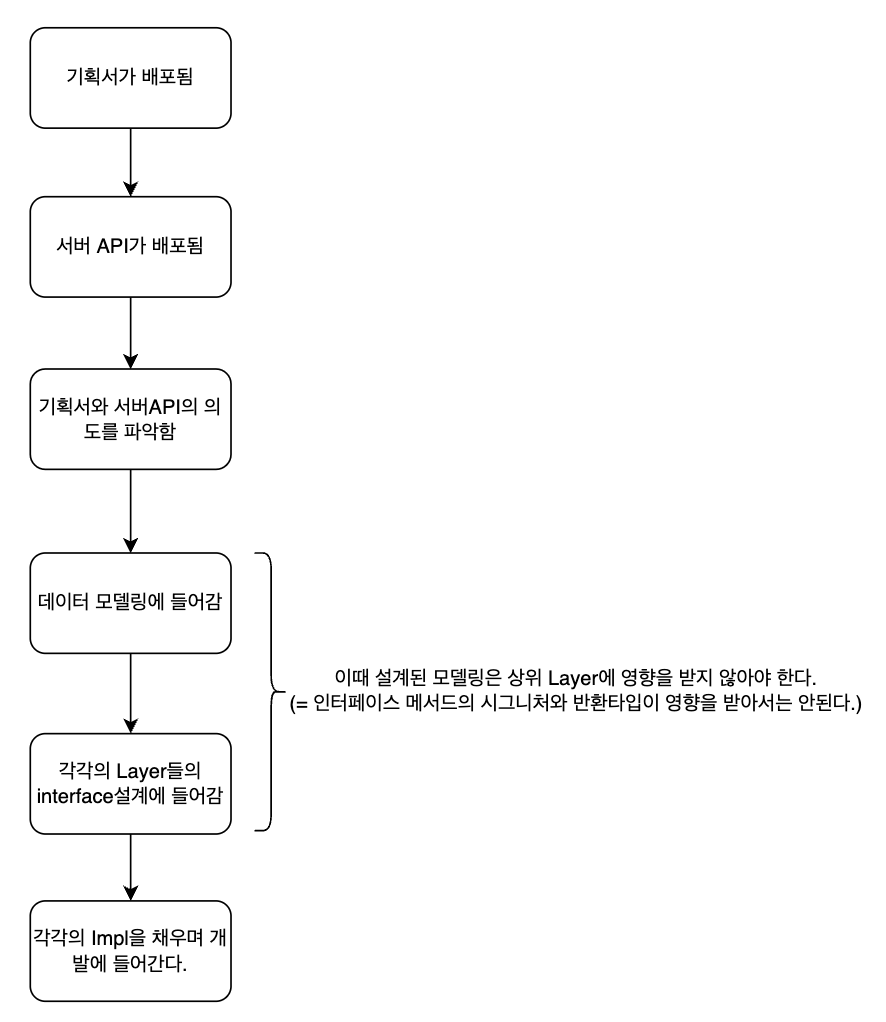
자, 위의 프로세스대로 아래와 같이 기획서가 배포되었으며, 서버API 또한 배포되었다고 가정해보겠습니다.
3.1. 기획 의도 파악하기
- 개요 : 동영상을 검색 및 조회한 후, 이를 저장하는 앱을 만든다.
- 세부사항
- 앱 하단엔 2개의 탭을 둔다. ( 1. 검색 결과 2. 내 보관함 )
- [검색 결과]
- [데이터 구조]
- 썸네일
- 타이틀
- 작성자
- 동영상 제생 시간
- 동영상 저장 & 삭제 체크 박스
- [기능]
- 상단에 검색어를 입력 후, 검색 버튼을 누른다.
- 앱 화면에 검색 결과 리스트들이 뜬다.
- 검색 결과 리스트엔 체크박스가 있다. 클릭 시, '내 보관함'에 저장된다.
- 체크박스 해지시, '내 보관함'에 저장된 이미지들이 삭제된다.
- [데이터 구조]
- [내 보관함]
- [데이터 구조]
- [검색 결과]의 데이터 구조와 동일
- [기능]
- 검색 결과에서 저장한 이미지 리스트들이 먼저 저장된 순서대로 상위에 뜬다.
- [데이터 구조]
- [검색 결과]
- 앱 하단엔 2개의 탭을 둔다. ( 1. 검색 결과 2. 내 보관함 )
[완성된 앱]
위와 같은 기획 의도가 나왔다고 가정해 봅시다. 그럼 이제 위 기획의도에 적합한 서버 API를 검토해야하고, 이 두가지를 잘 조합하여 앱의 아키텍쳐 설계를 들어가야 합니다. 서버 API의 의도는 아래와 같습니다.
3.2. 서버 API 의도 파악하기
- 개요 : 검색 결과를 반환하는 API
- 세부 사항
- URL : https://dapi.kakao.com/v2/search/vclip
- Method : POST
- Request Body : query, sort, page, size
- Response Body :
{ "meta":{ "total_count":0, "pageable_count":0, "is_end":false }, "documents":[ { "thumbnail":"", "datetime":"", "title":"", "url":"", "play_time":0, "author":"" } ] }
서버 API를 보시면 아시겠지만, 위 response 구조는 기획 의도에 알맞은 형태이기도 합니다. 자, 이제 기획서와 서버API가 모두 나왔으니, 이 정보를 통해 아키텍쳐를 설계해보도록 하겠습니다.
4. UI Layer의 Interface설계하기
사실상 UI Layer에선 interface를 설계할 필요가 없습니다. 왜 그럴까요? UI Element의 관점과 UI State Holder의 관점에서 말씀드려보도록 하겠습니다.
[UI Element]
우선, 아키텍쳐의 가장 하위 레이어인 UI Element부분들은 그 어디에서도 의존하지 않기에 interface를 둘 필요가 없습니다. 이는 여러분들도 잘 아시겠지만, activity, fragment, composeUI에 interface를 두는 경우는 본적이 없으실 것입니다. 그 이유는 UI Element는 그 어디에서도 의존하지 않기 때문입니다.
[UI State Holder]
UI State Holder는 이전에도 StateFlow나 LiveData와 같은 객체를 사용하여 view의 상태를 유지하는 홀더 클래스라고 말씀드렸습니다. 그리고 이러한 홀더 클래스는 ViewModel내부에 존재한다고도 말씀드렸죠.
그렇다면 ViewModel에도 Interface를 두어야 할까요? 결론부터 말하자면 그렇지 않습니다. 그 이유는 ViewModel은 오로지 단 하나의 UI Element요소만을 위한 컴포넌트이기 때문이며, 좀 더 구체적으로 말해보자면 ViewModel은 하나의 Activity나 Fragment의 LifeCycle과 맞물려있기 때문입니다.
즉, LifeCycle의 상태에 따라서 StateFlow나 LiveData를 사용해 반응형 방식으로 데이터의 변경을 UI Elements에 '직접적으로 통지'해 준다는 말이고, 이는 굳이 interface를 통해 의존을 느슨하게 만들 필요가 없다는 의미이기도 합니다.
[안드로이드 공식 홈페이지의 ViewModel사용 주의점]

따라서 ViewMdoel에서는 interface를 통해 메서드의 시그니처와 반환타입을 설계하는것보단, 단순히 구체적인 클래스 내부에 존재하는 메서드의 시그니처와 반환타입을 설계하는 것이 더 좋을 수 있습니다.
하지만 UI Layer에서 아무런 설계도 안하는 것은 아닙니다. UI Layer는 UI에 보여질 데이터들을 모델링 하는 과정이 들어가죠. 기획서와 서버 API를 검토해 봤을 때, 아래 구조의 UI 모델링이 가능합니다.
// 동영상 검색 결과 리스트 하나의 아이템 model
data class SearchResultItem(
val thumbnailUrl: String? = null,
val title: String? = null,
val playTime: Int? = null,
val author: String? = null,
var isFavorite: Boolean = false
)
모델의 설계가 끝났다면, 이제 사용자의 이벤트로 인해 어떤 비즈니스로 로직이 실행되는지를 파악해야 합니다. 위 기획 의도 관점으로 파악해봤을 때 2가지는 확실히 파악할 수 있습니다.
- 사용자가 검색을 시행함에 따라 동영상 아이템을 로드하기
- 사용자가 동영상 아이템을 클릭함에 따라 동영상 아이템을 저장 및 삭제하기
//SearchResultViewModel.kt
// 사용자가 동영상 검색을 실행했을 때 트리거할 비즈니스 로직 함수
fun search(keyWord: String) { ... }
// 사용자가 동영상 아이템을 저장 및 삭제했을 때 트리거할 비즈니스 로직 함수
fun updateSearchResultToLocal(searchResultItem: SearchResultItem) { ... }하지만 여기까지 설계하기는 뭔가 부족합니다. 사용자가 검색을 할때 불러오는 동영상 리스트에는 다음 정보도 포함이 된 상태여야 하기 때문이죠.
- 원격 서버로부터 불러오는 동영상 아이템이 사용자가 이전에 저장했던 아이템인가?
따라서 사용자가 불러오는 검색 결과에는 반드시 '내부 저장소와의 동기화가 이루어진 상태'가 포함되어야만 합니다. 즉, 이는 원격 서버로부터 불러들이는 검색 결과와 내부 저장소로부터 불러들이는 검색 결과의 동기화가 이루어져야 한다는 뜻이기도 합니다.
그리고 이러한 로직은 원격 서버의 검색 결과와 내부 저장소에 있는 검색 결과를 비교 연산작업을 수행해야 하는 만큼 상당히 복잡한 로직이 들어갈 수 있다고 예상할 수 있습니다. 따라서 이는 Domain Layer의 UseCase모듈로 분리하는 것이 하나의 방법이 될 수도 있습니다.
5. Domain Layer의 Interface 설계하기
그럼 이제 Domain Layer의 UseCase모듈을 간단히 설계해보도록 하겠습니다. 제가 이전에 interface를 설계하기 위해선 2가지 요소를 고려해야한다고 말씀드렸습니다.
[interface설계시 고려 요소]
- UseCase함수의 파라미터
- UseCase함수의 반환 타입
어떻게 각 요소들을 설계할까요? 우선 해당 UseCase모듈은 아시다시피, 사용자가 검색을 실행했을 때 호출될 함수입니다. 따라서 파라미터 부분에 '검색 키워드'는 반드시 들어가야 할 것입니다.
operator fun invoke(keyWord: String)이제 반환 타입입니다. 반환 타입은 어떻게 들어가야 할까요? 반환 타입은 사용자에게 보여질 UI형태를 그대로 따라야 합니다. 그럼으로써 이전에 설계한 'SearchResultModel'의 List가 반환되어야만 위에서 보여드린 UI가 사용자에게 보여질 것입니다. 따라서 UseCase 함수는 아래와 같이 완성할 수 있습니다.
operator fun invoke(keyWord: String): List<SearchResultModel> {
// TODO : 원격 서버로부터 불러오는 동영상 아이템이 내부 저장소로부터 불러오는 동영상 아이템을 포함하는 경우, isFavorite를 true로 체크하여 새로운 List를 반환한다.
}하지만, 원격 서버로부터 검색결과를 불러올 때, 저희는 JetPack라이브러리인 Paging3를 사용하려 합니다. Paging3를 써보면 아시겠지만, List형태의 데이터를 Paging형태로 표현합니다. 따라서 List타입을 PagingData타입으로 바꾸어서 재설계 합니다.
interface GetHomeItemsWithCheckedUseCase {
// 개발 시작 시, 아래 함수의 구현부를 채워가며 개발을 시작합니다.
operator fun invoke(keyWord: String): PagingData<SearchResultModel>
}[설계에 있어 Framework의 제약을 고려하기]
개발 경력이 늘고, 설계 경력이 늘어날 수록, 비즈니스 요구사항과 Framework 제약사항의 교집합을 찾는 능력이 향상됩니다. 이로써 설계를 할때, Framework의 특성을 잘 고려하여 사전 설계를 진행할 수 있게 됩니다. 마치 List대신 PagingData를 사용하여 설계한것처럼 말입니다 :)
6. Data Layer의 Interface 설계하기
6.1. Repository 설계하기
이제 UseCase모듈이나 ViewModel모듈이 의존할 Repository모듈을 설계하도록 하겠습니다.
설계에 있어 해당 Repository는 어떤 정보를 저장하고 있어야 할까요? 이 포스팅을 쭉 정주행 하신 분이라면 아마 '동영상 검색 아이템'에 대한 Repository가 정의되어야 할것이라고 예상하셨을것 같습니다. 따라서 해당 Repository는 아래와 같이 네이밍을 붙여불 수 있겠습니다.
interface SearchResultRepository이제 위 Repository에 함수들을 설계할 차례입니다.
[Repository 설계 팁]
Repository는 고유한 모델을 가지고 있는 것이 좋습니다. 비유를 들어, 정육점Repository라 하면 고기만 주는것이 이치에 맞고, 꽃집Repository라하면 꽃만 주는것이 이치에 맞습니다. 따라서 SearchResultRepository는 SearchResultItem모델만을 반환하는것이 자연스러울 수 있습니다.
ㄴ> Each repository has its own models.
참고 : [Android아키텍쳐 Repository설계 권장 사항]
우선, SearchResultRepository는 원격 서버로부터 검색 결과를 반환하는 함수가 있어야겠죠? 그리고 사용자가 어떠한 검색어를 입력했는지도 알 수 있어야 합니다. 그러므로 SearchResultRepoisitory는 아래의 함수를 가질 수 있습니다.
interface SearchResultRepository {
fun fetchRemoteSearchResultModels(keyWord: String): Flow<PagingData<SearchResultItem>>
}하지만 원격 서버로부터만 아이템을 가져온다면...? 내부 저장소에 저장된 검색 결과 아이템을 알 수 없을것이고, 이는 [검색 결과]화면의 요구사항을 충족할 수 없을 것입니다. 따라서 내부 저장소에 있는 검색 결과들을 조회하는 함수도 포함되어야만 합니다.
그리고 내부 저장소로부터 불러오는 검색 결과에 대한 함수는 특정 키워드가 필요하지 않고 그저 불러오기만하면 됩니다. 같은 말로 이는 파라미터가 필요 없다는 뜻입니다. 그러므로 내부 저장소의 검색 결과를 조회하는 기능은 '함수'가 아닌 '프로퍼티 타입'으로 좀 더 간결하게 선언할 수 있습니다.
interface SearchResultRepository {
// 사용자의 검색어를 입력 받아 이에 대한 Stream결과값을 반환하는 함수
fun fetchRemoteSearchResultModels(keyWord: String): Flow<PagingData<SearchResultItem>>
// 사용자가 좋아요를 클릭한 검색 결과값 Stream을 반환하는 함수
val localSearchResultModels: Flow<List<SearchResultItem>>
}이로써 검색 결과를 조회하는 함수를 모두 설계했습니다. 이제 마지막으로 사용자가 아이템을 저장 및 삭제하는 함수를 설계하도록 하겠습니다.
interface SearchResultRepository {
// 사용자의 검색어를 입력 받아 이에 대한 Stream결과값을 반환하는 함수
fun fetchRemoteSearchResultModels(keyWord: String): Flow<PagingData<SearchResultItem>>
// 사용자가 좋아요를 클릭한 검색 결과값 Stream을 반환하는 함수
val localSearchResultModels: Flow<List<SearchResultItem>>
// 사용자가 검색 결과를 저장할때 호출하는 함수
fun saveSearchResultToLocal(imageUiState: SearchResultItem)
// 사용자가 검색 결과를 삭제할때 호출하는 함수
fun deleteSearchResultToLocal(imageUiState: SearchResultItem)
}하지만 막상 설계하고나니 고민이 됩니다. sharedPreference를 사용하여 검색 결과의 저장 및 삭제를 시행할땐 내부 구현 로직의 상당한 중복이 생길거라 예상된다는 점이죠. 따라서 위 두 함수를 하나의 함수로 합쳐도 문제가 없다는 생각이 들어서 다음과 같이 설계를 바꾸어 보기도 합니다.
interface SearchResultRepository {
// 사용자의 검색 결과를 받고 동영상 아이템에 대한 검색 결과를 반환하는 함수
fun fetchRemoteSearchResultModels(keyWord: String): Flow<PagingData<SearchResultItem>>
// 사용자가 좋아요를 클릭한 동영상 아이템들을 반환하는 함수
val localSearchResultModels: Flow<List<SearchResultItem>>
// 사용자가 동영상 아이템을 저장 및 삭제할때 호출될 함수
fun updateSearchResultToLocal(imageUiState: SearchResultItem)
}[설계 팁]
설계의 경험이 많아지다보면, 내부 구현 로직이 더욱 잘 떠오르게 되고, 그에 따라 설계 추상화 정도를 더 멋지게 조절할 수 있다고 생각합니다.
6.1. DataSource 설계하기
방금 설계했던 SearchResultRepository는 원격 서버로부터의 이미지를 저장하기도 하고, 내부 저장소의 이미지를 저장하기도 합니다. 이는 마치 정육점에서 돼지고기와 소고기, 오리고기 등을 파는 것과 같은 맥락이기도 하죠.
그럼 이러한 정육점이 어떤 1차 생산자로부터 고기를 들여오는지 또한 알 필요가 있습니다. 이제 1차 생산자를 설계해볼 것이며 이것이 바로 DataSource를 설계하는것이라 이해하시면 되겠습니다.
DataSource를 어떻게 설계해야 할까요? Repository설계까지 잘 이해하신 분이라면, DataSource의 설계에 대해서도 상당한 느낌이 오셨을거라 생각합니다.
[필요한 DataSource]
- LocalSearchResultDataSource
- RemoteSearchResultPagingSource
우선 LocalSearchResultDataSource먼저 설계해보도록 하겠습니다. 해당 DataSource에는 2가지 기능이 들어가야 합니다. 우선, 사용자가 조회할 내부 저장소의 동영상 검색 결과 조회의 기능입니다. 두 번째로는 사용자가 저장 및 삭제를 시행하는 기능입니다.
interface LocalSearchResultDataSource {
// 사용자가 내부 저장소로부터 동영상 검색 결과를 조회할 함수
val searchResultModels: Flow<List<SearchResultItem>>
// 사용자가 동영상 아이템에 대한 저장 및 삭제를 시행하는 함수
fun updateSearchResult(searchResultItem: SearchResultItem)
}이제 마지막으로 RemoteSearchResultPagingSoure입니다. 하지만 이번에 설계할 DataSource는 기존의 interface를 통해서 설계하는 것이 아닌 추상 클래스를 통해 설계를 하게 됩니다. 그 이유는 PagingSource는 사용자의 동적 이벤트로 삽입 될 keyWord를 포함해야 한다는 점이고, 이로써 의존주입 설정 문제를 해결할 수 있기 때문입니다. 따라서 keyWord프로퍼티를 추가한 추상 클래스를 통해 RemoteSearchResultPagingSource를 설계합니다.
[설계에 Framework가 미치는 제약 사항]
설계를 많이 해보지 않으신 분이라면 아무래도 비즈니스 요구사항과 Framework의 제약사항을 조율하는데 어려움을 겪을 수밖에 없습니다. 예를 들어, Paging3를 써보지 않으신 분은 Pager에 동적으로 파라미터를 전달함과 동시에 Dagger Hilt로 의존주입 설정에 제약이 생긴다는점을 모를 수 있을수도 있습니다. 이는 설계를 중간에 바꾸어야하는 문제가 생길 수도 있는 것이죠. 하지만 그럼에도 불구하고, 설계는 해보면 해볼수록 향상되는 것이니 많은 설계를 해보는게 좋다고 생각합니다 :)
추가적으로, RemoteSearchResultPagingSource는 PagingSource가 제공해주는 API 사용해야 한다는 점을 염두하고 아래와 같이 설계가 들어갑니다.
abstract class RemoteSearchResultPagingSource: PagingSource<Int, SearchResultItem>() {
open var keyWord: String = ""
abstract override suspend fun load(params: LoadParams<Int>): LoadResult<Int, SearchResultItem>
abstract override fun getRefreshKey(state: PagingState<Int, SearchResultItem>): Int?
}이로써 모든 설계가 끝났습니다. 지금까지 설계한 전체 설계도를 보여드리면 아래와 같아집니다.
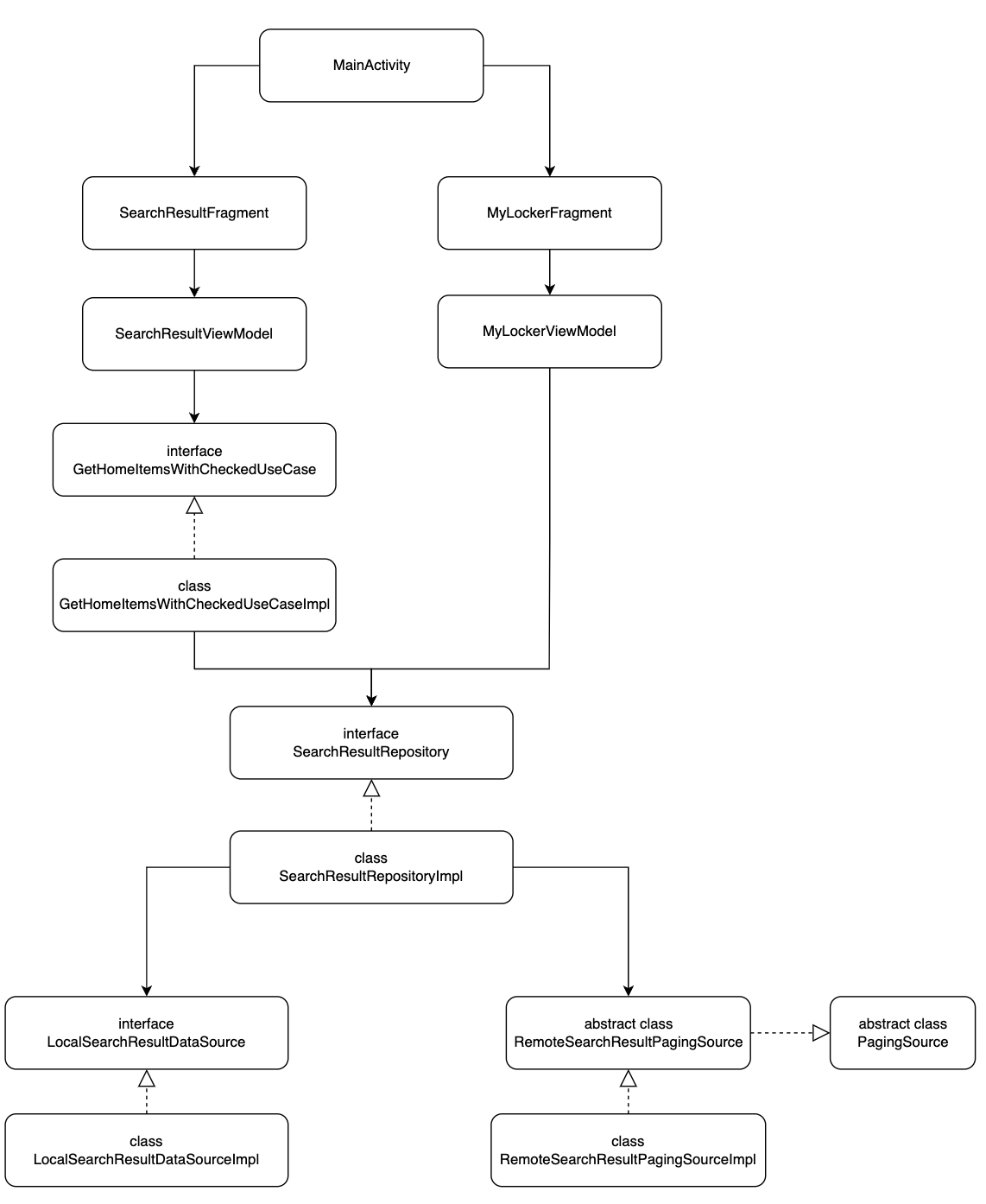
[Impl이 어떤지 궁금하다면?]
Impl의 구현법을 이 글에 담기엔 너무 길어질것같단 생각이 들었습니다. 자세한 Impl구현을 보시려면 하단의 git을 참고해 주세요 :)
Android Clean Architecture Sample : https://github.com/squart300kg/SSYArchitectureSampleApp
7. 마치며
그동안 Android Clean Architecture란 무엇인가를 알아보기 위해 기나긴 3편을 달려왔습니다. 여기까지 글을 읽어주신 분들께 감사드리며, 저의 글을 통해서 안드로이드 개발의 작은 지식을 얻어가셨다면 정말 기쁠 따름입니다.
또한 제가 설계한 방법은 정답이 아니라는 사실을 말씀드리고 싶습니다. 설계하는 방법에는 여러가지가 있으며, 제가 서술한 설계법은 그 중 하나의 방법일 뿐이라는 사실을 말씀드리고 싶습니다.
저의 설계법을 통해서 여러분들의 설계법에 영감을 얻으셨다거나 도움을 받았기를 바라는 마음으로 Android Clean Architecture란 무엇인가의 시리즈를 마무리짓도록 하겠습니다.
감사합니다.
