
이전 포스팅, [안드로이드 Clean Architecture에 관하여]를 보고오지 않으신 분은 꼭 보고 오시길 권장합니다.
25.07.04 수정
해당 글은 클린아키텍처가 아닌, 안드로이드 공식 홈페이지의 앱 아키텍처에 대한 글입니다.
0. 시작하며
저번 시간에는 안드로이드 클리 아키텍쳐에 관한 '개념적인 부분'을 많이 다루었어요. 그렇다면 오늘은 좀 더 세부적으로 코드를 살펴보며 안드로이드 클린 아키텍쳐란 무엇인지 와닿는 시간을 가져보도록 하겠습니다.
저번에 안드로이드에는 3개의 Layer가 있다고 말씀드렸어요. UI Layer, Domain Layer, Data Layer가 있었죠. 그리고 이 Layer들에는 모듈들이 있고, 이 모듈들은 각기 다른 책임을 갖고 있다고까지 말씀드렸습니다. 그러한 책임을 이해하는 것이야말로, 클린한 아키텍쳐의 앱을 만드는 방법이었죠. 간단하게 복습해보자면 다음과 같아요.
[UI Layer]
- [UI Elements]
- UI요소 그 자체를 의미한다. 예를 들면 Activity/Fragment와 이에 대응되는 xml.view파일이 있다.
- 요즘 HOT한 선언형 UI방식인 ComposeUI 또한 이에 해당한다.
- [UI State Holder]
- 직접적으로 대응되는 모듈은 ViewModel이다. 그리고 이들은 2가지 관점으로 설명이 가능하다.
- UpStream : 사용자의 이벤트를 받아 비즈니스 로직을 시작시킨다.
- DownStream : 상위 레이어(Domain or Data)로부터 받은 데이터를 상태 홀더 클래스(LiveData or StateFlow)에 저장시킨다. 그리고 이를 통해 UI에 데이터를 바인딩시킨다.
[Domain Layer]
- 직접적으로 대응되는 모듈은 UseCase이다.
- ViewModel이 지는 책임 이외의 비즈니스 로직이 정의된다.
- ViewModel에 해당하는 중복코드가 정의된다.
[Data Layer]
- 직접적으로 대응되는 모듈은 Repository와 DataSource이다.
- [Repository]
- UpStream : 하위 레이어(Domain or UI)로부터 앱 내 필요 정보를 요청받아 DataSource에게 요청한다.
- DownStream : DataSource로부터 전달받은 정보를 UI Layer에 필요한 형태로 가공 후, 하위 레이어(Domain or UI)로 전달한다.
- 그 외, 가공한 데이터를 Repository내에 캐싱할 수 있다.
- [DataSource]
- UpStream : Local or Remote Server에 데이터를 요청한다.
- DownStream : 응답받은 데이터를 raw한 형태로 Repository에 전달해준다.
그리고 [안드로이드 Clean Architecture에 관하여]에서 위의 개념을 '배달의 민족'예시와 '김밥천국'예시로까지 설명을 드렸으며 간단한 소스코드로도 설명을 드렸습니다. 이제 이 포스팅에선 좀 더 자세히 설명을 해볼까 합니다.
1. UI Layer의 책임은 무엇인가.
편의를 위해 저번 시간에 썼던 예제 코드를 그대로 사용하겠습니다.
@AndroidEntryPoint
class MainActivity: AppCompatActivity{
priate val viewModel: MainViewModel by injects()
priate val searchAdapter by lazy { SearchAdapter() }
fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding {
btnSearch.setOnClickListener {
viewModel.search($"etSearch.text")
}
rvMain.apply {
setHasFixedSize(true)
adapter = mainPagingAdapter
}
}
lifecycleScope.launch {
repeatOnLfecycle(Lifecycle.State.RESUMED) {
launch {
viewModel.searchResults.collectLatest { searchResults ->
adapter.submitData(searchResults)
}
}
}
}
}
}
@HiltViewModel
class MainViewModel @Inject constructor(
private val searchRepository: SearchRepository
) {
private val searchResults = MutableStateFlow<List<SearchUiState>>(emptyList())
val _searchResults = searchResult.asStateFlow()
fun search(keyWord: String) {
viewModelScope.launch {
searchRepository.fetchSearchResults(keyWord)
.flowOn(Dispatchers.IO)
.map { Result.success(it) }
.catch { emit(Result.failure(it)) }
.collect { result ->
result.fold(
onSuccess = { searchUiStates ->
_searchResults.update { searchUiStates }
},
onFailure = { }
)
}
}
}
}우선, UI Elements의 가장 큰 책임 중 하나는 바로 '사용자의 이벤트'입니다. 그러한 사용자의 이벤트를 트리거해주는 코드가 바로 클릭과 관련된 코드인 것이죠.
btnSearch.setOnClickListener { ... }사용자가 검색 버튼을 클릭하면 어떻게 해야할까요? 검색 결과 리스트 불러오기(=비즈니스 로직)를 시작해야겠죠? 그리고 이는 제가 여러번 말씀드렸듯이, ViewModel의 UpStream관점의 책임은 사용자의 이벤트를 받아 '비즈니스 로직을 시작'시키는 것을 의미했습니다.
btnSearch.setOnClickListener {
viewModel.search("$etSearch.text")
}그럼 이제 ViewModel로 이동해볼까요?
@HiltViewModel
class MainViewModel @Inject constructor(
private val searchRepository: SearchRepository
) {
private val searchResults = MutableStateFlow<List<SearchUiState>>(emptyList())
val _searchResults = searchResult.asStateFlow()
fun search(keyWord: String) {
viewModelScope.launch {
searchRepository.fetchSearchResults(keyWord)
.flowOn(Dispatchers.IO)
.map { Result.success(it) }
.catch { emit(Result.failure(it)) }
.collect { result ->
result.fold(
onSuccess = { searchUiStates ->
_searchResults.update { searchUiStates }
},
onFailure = { }
)
}
}
}
}ViewModel에서는 검색 결과를 받기 위해 상위 레이어이자, Data layer모듈인 Repository에 검색 결과 리스트를 요청하고 있습니다. 그리고 ViewModel에서는 검색 결과를 수신받기 위해 flow<T.>.collect() 메소드를 호출함으로써 검색 결과를 DownStream하도록 하고 있습니다.
Flow가 뭐지...?
Flow는 클린아키텍쳐를 구성하는데 있어 매우 중요한 Reactive Stream라이브러리입니다. 이를 통해 단방향 데이터 흐름을 UpStream과 DownStream으로 구분지음으로써 직관적으로 구현할 수 있을 뿐만 아니라, 데이터 변형(ex. map)도 아주 직관적이게 구현할 수 있습니다. 너무 중요한 내용이라 [ReactiveStream Flow 활용하기]를 꼭 읽어주세요!
Result가 뭐지...?
이는 Reactive Stream을 활용할때, [에러를 처리하는데 있어 안드로이드에서 권장하는 방식]입니다. 이를 통해 Reactive Stream내부에서 발생하는 에러를 안전하게 핸들링할 수 있지요.
결과적으로, 검색 결과에 대한 부분은 'List<SearchUiStates.>'형태로 받게 됩니다. 그리고 이 데이터를 이용해 UI에 데이터 바인딩을 시작하게 되죠.
하지만 여기서 UI에 데이터 바인딩을 시행해줄 때 중요한 점이 있습니다. 바로 '명령형 방식'이 아닌, '반응형 방식'으로 진행한다는 점이죠.
'명령형'과 '반응형' 방식의 차이?
아주 짧게 설명드리면, 명령형 방식은 메소드를 호출함으로써 특정 동작을 트리거해주는걸 의미합니다. 반면, 반응형 방식은 데이터에 반응하여 특정 동작을 옵저버 패턴 형식으로 트리거해주는 방식을 의미합니다. 자세한 부분은 [명령형 프로그래밍과 반응형 프로그래밍의 차이?]의 포스팅을 참고해 주세요
여기서 UI에 데이터 바인딩을 Reactive한 방식으로 진행시키기 위해 필요한 것이 바로, 상태 홀더 클래스(=UI State Holder)입니다. 그리고 이는 LiveData나 StateFlow를 의미합니다.
// UI State Holder 클래스, 이를 통해 UI에 Reactive한 방식으로 데이터를 바인딩하게 된다.
private val searchResults = MutableStateFlow<List<SearchUiState>>(emptyList())
val _searchResults = searchResult.asStateFlow()UI State Holder객체 선언과 초기화가 끝났습니다. 그러면, 이제 위 상태홀더에 데이터를 저장시켜야 합니다. 저장시키는 방법은 Flow<T.>.collect()를 호출함으로써 UpStream이 시작되죠.
...
.collect { result ->
result.fold(
onSuccess={ searchResult ->
_searchResult.update { searchResult }
},
onFailure={}
)
}
[collect를 호출함으로써 UpStream이 시작된다?]
Reactive Stream라이브러리는 consume + intermediate + produce의 3 과정이 있습니다. consume에 해당하는 collect는 데이터를 소비하기 위한 요청으로 UpStream을 트리거하고, 곧 상위 레이어로부터 데이터를 DownStream받게 됩니다. 더 자세한 내용은 [ReactiveStream Flow 활용하기]를 읽어주세요!
아시다시피, '_searchResults'프로퍼티는 StateFlow<T.>형식을 취하고 있습니다. 그리고 이는 MainActivity에서 아래와 같이 옵저버 패턴의 방식으로 데이터 전달이 이뤄집니다.
@AndroidEntryPoint
class MainActivity: AppCompatActivity{
priate val viewModel: MainViewModel by injects()
priate val searchAdapter by lazy { SearchAdapter() }
fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
...
lifecycleScope.launch {
repeatOnLfecycle(Lifecycle.State.RESUMED) {
launch {
// collect를 호출해줌으로써 'UI Elements계층'으로 데이터를 DownStream합니다.
viewModel.searchResults.collectLatest { searchResults ->
// DownStream받은 데이터는 리사이클러뷰 내에서 데이터가 바인딩 됩니다.
adapter.submitData(searchResults)
}
}
}
}
}
}
그리고 리사이클러뷰의 adapter.submitData를 호출합니다.
// MainAdapter 내부
private val items = mutableListOf<SearchUiState>()
fun submitData(data: List<SearchUiState>) {
items.clear()
items.addAll(data)
notifyDataSetChanged()
}위, submitData메소드를 호출함에 따라, 리사이클러뷰 각각의 ViewHolder엔 데이터들이 바인딩될 것이고, 리스트가 비로소 보이게 됩니다. (RecyclerViewAdapter의 동작방식은 아실거라 생각하고 생략하겠습니다.)
이로써 ViewModel이 짊어져야하는 책임이 비로소 끝났습니다.
[ViewModel의 책임?]
- UpStream관점 : 사용자의 이벤를 받아 비즈니스 로직을 시작시켜준다.
- DownStream 관점 : 상위 레이어(Domain or Data)로부터 받은 데이터를 상태 홀더 클래스(LiveData or StateFlow)에 저장시킨다. 그리고 이를 통해 UI에 데이터를 바인딩시킨다.
2. Domain Layer의 책임은 무엇인가.
Domain Layer의 책임은 ViewModel이 짊어져야할 책임 이외의 비즈니스 로직이라는 점. 그리고 여러 ViewModel의 공통 비즈니스 로직이 정의된다는 점. 이었습니다.
[ViewModel이 짊어져야할 책임 이외의 비즈니스 로직]
이를 설명드리기 위해선 '새로운' 상황을 가정해야합니다.
- [기존 상황]
- 단순히 Remote Server를 통해서만 검색 결과 리스트를 응답받음
- [새로운 상황]
- 사용자가 홈에서 이미지에 '좋아요'를 누를 수 있다.
- '좋아요'를 누른 이미지는 Local Server에 저장된다.
- 홈에 검색 결과 이미지를 가져올 땐, Local Server에 저장된 이미지와 비교하여 '좋아요'표시를 해준다.
(아래는 위 샘플 코드를 기반으로한 샘플앱 입니다.)
그럼 이 로직은 아래와 같이 변경하는게 좋을까요? (변경된 부분은 combine 중간 연산 함수가 포함되었다는 점입니다.)
@HiltViewModel
class MainViewModel @Inject constructor(
private val searchRepository: SearchRepository
) {
private val searchResults = MutableStateFlow<List<SearchUiState>>(emptyList())
val _searchResults = searchResult.asStateFlow()
fun search(keyWord: String) {
viewModelScope.launch {
combine(
searchRepository.fetchSearchResults(keyWord),
searchRepository.localSearchResult) { remoteItems, localItems ->
// remoteItems와 localItems를 비교하여 새로운 List<SearchUiState>를 만들어내는 긴~ 로직
}
.flowOn(Dispatchers.IO)
.map { Result.success(it) }
.catch { emit(Result.failure(it)) }
.collect { result ->
result.fold(
onSuccess = { searchUiStates ->
_searchResults.update { searchUiStates }
},
onFailure = { }
)
}
}
}
}물론 위 방법도 틀린 방법은 아닙니다. 하지만 제가 생각했을 때 위의 로직은 클린 아키텍쳐의 UI Layer가 짊어져야할 책임보다 더 많은 책임을 지고 있다고 생각합니다. 그리고 이는 결국 ViewModel을 불필요하게 크게 만든다고 생각하고요. 그 이유는 ViewModel의 책임은 단순 UI State Holder에 데이터를 저장하는 것이고, 이를 통해 UI에 Reactive한 방식으로 데이터를 바인딩하는 것이기 때문이죠. [안드로이드 공식 홈페이지 Domain Layer란?]
따라서 위 'HomeViewModel'내의 로직은 'GetHomeItemsWithCheckedUseCase'로 분리하면 좀 더 깔끔한 로직이 될 수 있습니다.
class GetHomeItemsWithCheckedUseCase @Inject constructor(
private val searchRepository: SearchRepository
) {
operator fun invoke(keyWord: String): Flow<List<SearchUiState>> {
return combine(
searchRepository.fetchSearchResult(keyWord),
searchRepository.localSearchResult) { remoteResults, localResults ->
// remoteItems와 localItems를 비교하여 새로운 List<SearchUiState>를 만들어내는 긴 로직
val results: List<SearchUiState> = ...
return@combine results
}
}
}그리고 ViewModel에서는 위에 정의한 UseCase를 호출하기만 하면 됩니다. (변경된 부분은, 생성자 주입이 Repository -> UseCase로 바뀌었다는 점입니다.)
@HiltViewModel
class MainViewModel @Inject constructor(
private val getHomeItemsWithCheckedUseCase: GetHomeItemsWithCheckedUseCase
) {
private val searchResults = MutableStateFlow<List<SearchUiState>>(emptyList())
val _searchResults = searchResult.asStateFlow()
fun search(keyWord: String) {
viewModelScope.launch {
getHomeItemsWithCheckedUseCase()
.flowOn(Dispatchers.IO)
.map { Result.success(it) }
.catch { emit(Result.failure(it)) }
.collect { result ->
result.fold(
onSuccess = { searchUiStates ->
_searchResults.update { searchUiStates }
},
onFailure = { }
)
}
}
}
}어떤가요? UseCase를 적용함으로써 ViewModel의 로직에는 수정을 가하지 않았습니다. 그리고 ViewModel의 다른 로직들도 위와 비슷한 패턴을 가져간다면 가독성이 더 좋아지지 않을까요?
[여러 ViewModel의 공통 비즈니스 로직]
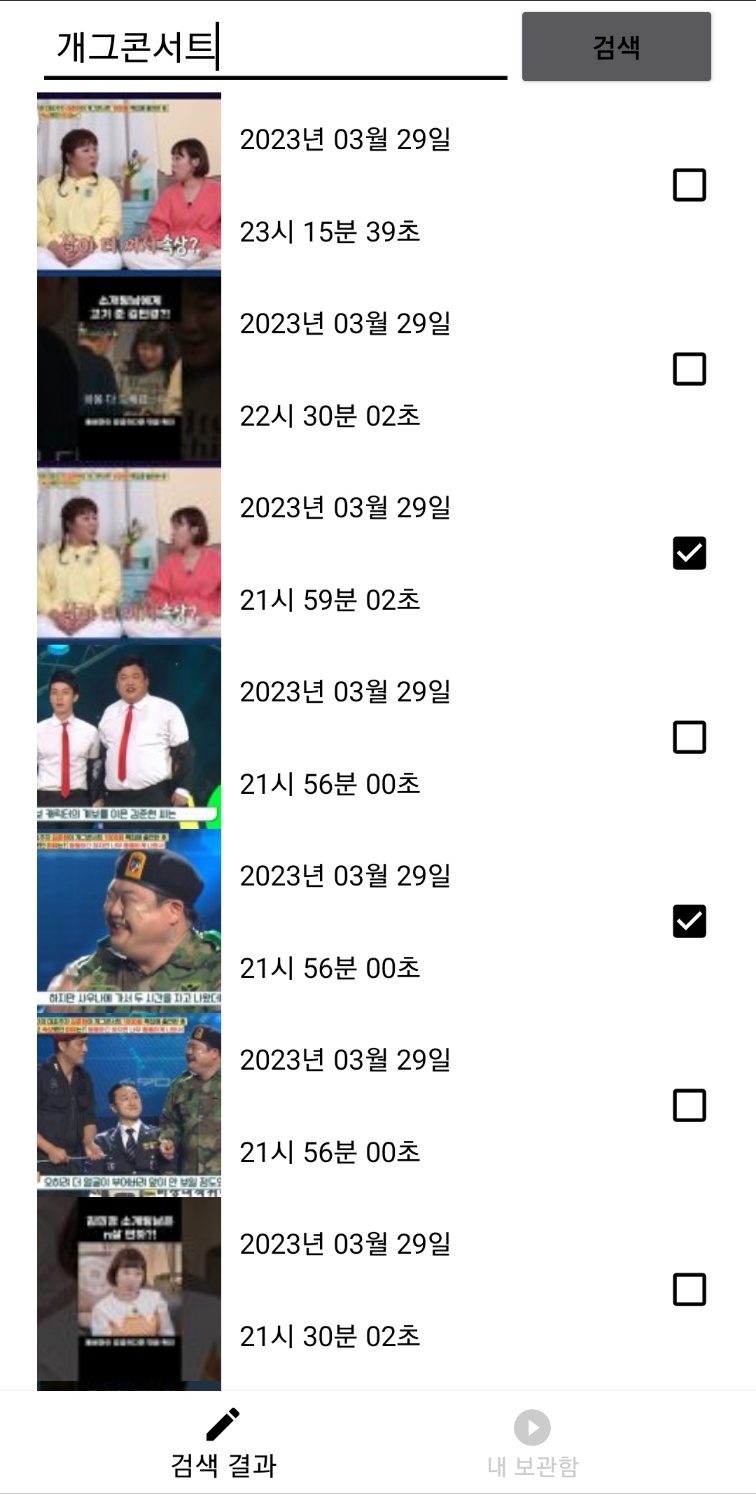
이번엔 새로운 상황을 가정해볼게요. 아까 보셨던 앱 기억하시나요? 위 앱의 하단을 보면 '검색 결과'와 '내 보관함'으로 나뉘어져 있었습니다.

따라서 이 앱의 구조는 다음과 같아질 수 있겠죠?
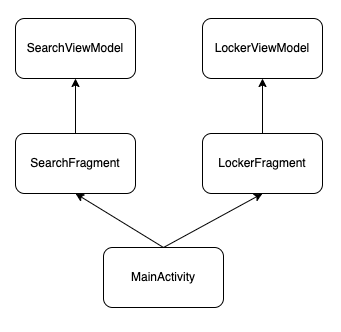
하지만, 여기서 기능의 추가가 발생합니다. 바로, '검색결과'의 부분과 '내 보관함'의 부분에 '로그인'기능을 추가해달라는 기획부서의 요청입니다. 그리고 이는, 곧, SearchFragment와 LockerFragment의 사용자 이벤트에 맞춰 '로그인 동작'이라는 비즈니스 로직을 시작시켜줘야하는걸 의미합니다.
그럼 이때, 우린 각각의 ViewModel(=SearchViewModel, LockerViewModel)에 로그인 관련 비즈니스 로직을 추가하면 되는걸까요?
class SearchViewModel @Inject constructor(
private val userRepository: UserRepository
): ViewModel() {
private val _userUiState = MutableStateFlow<UserUiState>()
val userUiState = _userUiState.asStateFlow()
fun login(userId: String) {
viewModelScope.launch {
.flowOn(Dispatchers.IO)
.collect {
// 로그인 완료 후의 비즈니스 로직
...
// 로그인 완료에 따른 뷰 변경 로직
_userUiState.update { ... }
}
}
}
}
class LockerViewModel @Inject constructor(
private val userRepository: UserRepository
): ViewModel() {
private val _userUiState = MutableStateFlow<UserUiState>()
val userUiState = _userUiState.asStateFlow()
fun login(userId: String) {
viewModelScope.launch {
userRepository.login()
.flowOn(Dispatchers.IO)
.collect {
// 로그인 완료 후의 비즈니스 로직
...
// 로그인 완료에 따른 뷰 변경 로직
_userUiState.update { ... }
}
}
}
}ViewModel이 위처럼 딱 2개만 있다면, 그나마 봐줄 수는 있을지도 모릅니다. 하지만 화면이 많아지고, 그에 따른 ViewModel이 많아진다면? 그에 따른 로그인 로직도 함께 추가된다면? 이는 상당한 양의 중복코드를 야기하게 됩니다. 따라서 위의 경우는 아래와 같이 추상화할 수 있습니다.
class LoginUseCase @Inject constructor(
private val userRepository: UserRepository
) {
operator fun invoke(userId: String)
= userRepository.login().map { loginResponse ->
// 로그인 완료 후의 비즈니스 로직
}
}UseCase를 추가함으로써 '로그인 완료 후의 비즈니스 로직'에 대한 부분은 UseCase가 책임을 맡게 되었습니다. 그렇다면 이제야 말로, ViewModel에서는 그저 StateFlow의 상태 홀더 클래스를 사용하여 UI를 바인딩하는 책임만 지면 되게 됩니다.
class SearchViewModel @Inject constructor(
private val loginUseCase: LoginUseCase
): ViewModel() {
fun login(userId: String) {
viewModelScope.launch {
loginUseCase()
.flowOn(Dispatchers.IO)
.collect {
// 로그인 완료에 따른 뷰 변경 로직
_userUiState.update { ... }
}
}
}
}
class LockerViewModel @Inject constructor(
private val userRepository: UserRepository
): ViewModel() {
fun login(userId: String) {
viewModelScope.launch {
loginUseCase()
.flowOn(Dispatchers.IO)
.collect {
// 로그인 완료에 따른 뷰 변경 로직
_userUiState.update { ... }
}
}
}
}3. Data Layer의 책임은 무엇인가.
Data Layer에서는 UI Layer에서 사용될 수 있는 새로운 모델 생성합니다. 그리고 이를 하위 레이어(Domain Layer or UI Layer)로 전달해주는 책임을 가지고 있습니다.
이를 가능하게 하기 위해 첫 번째로 선행되어야 하는 부분은 Data Layer에서 받은 ReponseModel이 Repository로 전달되는 것이 첫 번째가 되겠습니다.
이렇게 전달받은 후, Repository에선 ResponseModel을 UiModel로 변환작업을 시행합니다.
참고 : [Android Data Layer 비즈니스모델 모델링하기]
아래의 예시는 2군데의 DataSource로부터 ResponseModel을 수신받고, 이를 Repository모듈 내에서 UiModel로 변환하는 작업입니다.
[2군데의 DataSource]
첫 번째 데이터 소스 : 이미지 검색 api
두 번째 데이터 소스 : 비디오 검색 api
class ImageSearchDataSource @Inject constructor(
private val api: Api
){
fun fetchImages(query: String): Flow<ImageSearchResponseModel> {
emit(api.fetchImageSearch(query))
}
}
class VideoSearchDataSource @Inject constructor(
private val api: Api
){
fun fetchVideos(query: String): Flow<VideoSearchResponseModel> {
emit(api.fetchVideoSearch(query))
}
}그리고 아래는 위 DataSource를 수신받을 SearchResultRepository입니다.
class SearchResultRepository @Inject constructor(
private val imageSearchResultDataSource: ImageSearchResultDataSource,
private val videoSearchResultDataSource: VideoSearchResultDataSource
) {
fun fetchSearchResult(query: String): Flow<List<SearchUiModel>> {
combine(
imageSearchResultDataSource.fetchImage(query),
videoSearchResultDataSource.fetchVideo(query)
) { imageSearchResult, videoSearchResult ->
val searchResults = imageSearchResult.list.toMutableList() + videoSearchResult.list.toMutableList()
searchResults.map { searchResult ->
SearchUiModel(
field1 = searchResult.~~
field2 = searchResult.~~
field3 = searchResult.~~
field4 = searchResult.~~
)
}
}
}위의 코드는 두 DataSource로부터 받은 ResponseModel안에 있는 검색 결과를 의미하는 list필드끼리 더해준 후, UI Layer에서 필요로하는 형식에 맞게 맞게 반환해주는 의사 코드입니다.
그 후, Domain Layer나 UI Layer에선, Data Layer가 어떻게 구현되었는 알 필요 없이 그저 위의 메소드를 호출해주기만 하면 됩니다.
[중요]
하위 레이어는 상위 레이어가 어떻게 구현되었든 알 필요가 없습니다. 그저 상위 레이어의 interface만 보고 그에 맞는 api만 호출해주면 끝입니다. 이제부터 이 부분이야말로 안드로이드 Clean Architecture의 꽃이라고 생각하며, 이에 대한 부분 또한 설명드리려 합니다. [안드로이드 Clean Architecture란 무엇인가3]를 참고해주시기 바랍니다.
Domain Layer나 UI Layer에선 아래와 같이 호출해주면 됩니다.
[Domain Layer에서의 호출]
class FetchSearchResultUseCase @Inject constructor(
private val searchResultRepository: SearchResultRepository
) {
operator fun invoke(query: String)
= searchResultRepository.fetchSearchResult(query)
}[UI Layer에서의 호출]
@HiltViewModel
class HomeViewModel @Inject constructor(
// 아래는 Data Layer를 참조합니다.
private val searchResultRepository: SearchResultRepository,
// 아래는 Domain Layer를 참조합니다.
private val fetchSearchResultUseCase: FetchSearchResultUseCase
) {
private val _searchUiModels: MutableStateFlow<List<SearchUiModel>>(emptyList())
val searchUiModels = _searchUiModels.asStateFlow()
// Data Layer를 참조하는 경우
fun fetchSearchResult(query: String) {
viewModelScope.launch {
searchResultRepository.fetchSearchResult(query)
.collect { searchUiModels ->
// 리액티브 스트림 업데이트를 통한 UI Elements의 데이터 바인딩 및 UI 업데이트
_searchUiModels.update { searchUiModels }
}
}
}
// Domain Layer를 참조하는 경우
fun fetchSearchResult(query: String) {
viewModelScope.launch {
fetchSearchResultUseCase(query)
.collect { searchUiModels ->
// 리액티브 스트림 업데이트를 통한 UI Elements의 데이터 바인딩 및 UI 업데이트
_searchUiModels.update { searchUiModels }
}
}
}
}비록 의사코드이긴 하지만, 최대한 상세히 설명드리려는 마음에 좀 길어진 부분이 없지않아 있습니다. 그래도 주석과 함께 천천히 보시면 이해가 갈거라 생각합니다.
그럼 이제 Data Layer의 책임과 위의 코드를 매칭해보며 설명을 드려보겠습니다. 우선, 이전에 말했던 Data Layer의 모듈은 Repository와 DataSource로 나뉜다고 설명드렸습니다. 그리고 이 모듈들은 각각 UpStream과 DownStream의 관점으로 책임이 있다고 말씀드렸는데요. 이 부분을 중점으로 설명드려보도록 하겠습니다.
[Data Layer]
- [Repository]
- UpStream : 검색결과를 가져오기 위해, 2개의 DataSource호출(=ImageSearchResultDataSource, VideoSearchResultDataSource)
- DownStream : 2개의 데이터 소스로부터 가져온 데이터를 UI Layer에 필요한 형태(=SearchUiModel)로 가공
- [DataSource]
- UpStream : 검색결과를 가져오기 위해 각각의 api호출(=api.fetchImageSearch(), api.fetchVideoSearch())
- DownStream : 가져온 ResponseModel Reactive Stream인 Flow를 통해 데이터 생산 및 방출 작업 진행(=가져온대로 그대로 반환)
마치며
지금까지 안드로이드 Clean Architecture란 무엇인가에 대해 '개념적인 부분'과 '세부적인 코드 부분'까지 2개의 포스팅을 통해 알아보았습니다.
이제 3편으로 [안드로이드 Clean Architecture란 무엇인가3]에서 아키텍쳐 설계에 대한 부분을 다뤄보도록 하겠습니다. 3편에선 제가 설계에 가장 중요하다고 생각하는 의존 역전의 원칙이 있으며, 의존역전의 원칙을 위한 인터페이스를 설계하고, 인터페이스 내, 함수 시그니처를 설계하기 위해 도메인을 주도로 설께하는 DDD에 대해서도 다뤄보려 합니다.
긴 글 읽어주셔서 감사합니다.
