
- https://github.com/awslabs/deequ
- https://aws.amazon.com/ko/blogs/big-data/test-data-quality-at-scale-with-deequ/
Deequ?
Amazon 에서 개발 및 사용되는 오픈 소스 도구
- Data Quality 제약 조건을 정의, 추가, 편집
- 데이터셋의 제약조건에 따른 data quality metric 을 정기적으로 계산
- 성공할 경우 데이터셋을 소비자에게 게시
- 오류가 발생하면, 데이터셋 게시가 중지될 수 있으며 생산자는 이를 조치해야함
- Data Quality 이슈는 소비자 데이터 파이프라인으로 전파되지않아 조치해야하는 반경이 줄어듬
Deequ 는 Apache Spark 을 기반으로 구축된 라이브러리
- 일반적으로 Spark 에서 다룰 수 있는 데이터셋(분산 파일 시스템 또는 데이터 웨어하우스) 에 대한 Data quality 측정 가능
- python 사용자는 Deequ용 Python 인터페이스인 PyDeequ를 사용할 수 있다
Overview
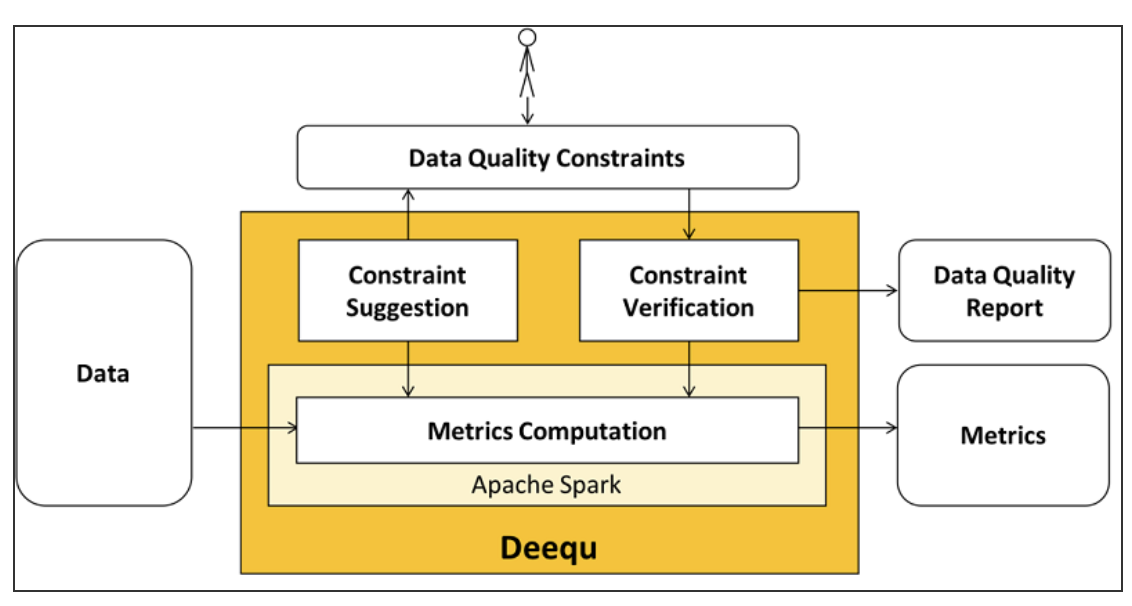
main component 들을 살펴보자
- Metric Computation
- data quality metric 계산 (such as completeness, max, min과 같은 통계)
- deequ 는 spark 을 사용하여 소스를 읽고 최적화된 집계 쿼리 세트를 통해 지표를 계산
- 계산된 원시 data quality metric 에 직접 접근 가능
- Constraint Verification
- 사용자는 확인할 data quality 제약 조건 집합을 정의하는 데 중점을 둔다
- deequ는 제약 조건 검증 결과가 포함된 data quality report를 생성
- Constraint Suggestion
- 제약조건 정의
- 사용자 지정 data quality 제약 조건을 정의하거나
- 유용한 제약 조건을 추론하기위해 데이터를 프로파일링하는 자동화된 제약 조건 제안을 할 수 있음
Requirements and Installation
- Java 8 의존
- deequ 2.x 는 spark 3.1에서 실행
- 이전 spark 버전을 사용하는 경우, deequ 1.x 버전 사용
maven
<dependency>
<groupId>com.amazon.deequ</groupId>
<artifactId>deequ</artifactId>
<version>2.0.0-spark-3.1</version>
</dependency>sbt
libraryDependencies += "com.amazon.deequ" % "deequ" % "2.0.0-spark-3.1"Main Function
Data Profiling
대규모 데이터셋의 이해가 어려운 경우, Column 단위 프로파일링 지원
- Column 의 완전성, 고유한 값의 대략적인 수, 유추된 데이터 유형
- 숫자 Column 의 경우, 최대/최소/평균/표준편차 등에 대해 추가적으로 제공
- 고유 값 수가 적은 경우, 전체 값에 대한 분포를 수집
Automatic suggestion of constraints
자동으로 제약 조건 제안
- 제약 조건을 명시하기 힘든 경우 활용 가능
- 제안된 제약 조건에 대한 설명과 제약 조건을 정의할 수 있는 코드를 반환한다
MetricsRepository
data quality metric을 파일 시스템에 저장
- local disk, hdfs 지원
- 출력을 json 으로 반환
Anomaly Detection
특정 metric을 MetricRepository 에 저장한 후, 현재와 과거 값을 비교하여 비정상적인 변경을 감지
- deequ는 고정된 제약 조건에 대한 data quality 뿐만 아니라 시간이 지남에 따라 변경되는 metric에 테스트를 적용할 수 있다
Test
- Deequ Examples 참고
- 데이터셋에 대해 다양한 통계 metric을 계산할 수 있다. Deequ Analyzers Package 에서 사용할 수 있는 metric 을 확인할 수 있다
Load Data
spark 에서 데이터를 읽는 것과 동일
val rawData = spark.read.parquet(path)rawData.printSchema() 를 통해 데이터 스키마를 살펴보자
root
|-- marketplace: string (nullable = true)
|-- customer_id: string (nullable = true)
|-- review_id: string (nullable = true)
|-- product_title: string (nullable = true)
|-- star_rating: integer (nullable = true)
|-- helpful_votes: integer (nullable = true)
|-- total_votes: integer (nullable = true)
|-- vine: string (nullable = true)
|-- year: integer (nullable = true)Define and Run Tests for Data
아래와 같이 룰을 정하고 Data가 이 조건을 만족하는지 Test를 진행해보자.
- 최소 300만개의 row가 있어야한다
review_id가 절대 NULL이 될 수 없다review_id는 Unique 해야한다star_rating는 1.0 ~ 5.0 사이의 값만 가질 수 있다marketplace오직 “US”, “UK”, “DE”, “JP”, “FR” 만 포함 가능하다year는 절대 음수가 될 수 없다
import com.amazon.deequ.{VerificationSuite, VerificationResult}
import com.amazon.deequ.VerificationResult.checkResultsAsDataFrame
import com.amazon.deequ.checks.{Check, CheckLevel}
val verificationResult: VerificationResult = { VerificationSuite()
// data to run the verification on
.onData(dataset)
// define a data quality check
.addCheck(
Check(CheckLevel.Error, "Review Check")
.hasSize(_ >= 3000000) // at least 3 million rows
.hasMin("star_rating", _ == 1.0) // min is 1.0
.hasMax("star_rating", _ == 5.0) // max is 5.0
.isComplete("review_id") // should never be NULL
.isUnique("review_id") // should not contain duplicates
.isComplete("marketplace") // should never be NULL
// contains only the listed values
.isContainedIn("marketplace", Array("US", "UK", "DE", "JP", "FR"))
.isNonNegative("year")) // should not contain negative values
// compute metrics and verify check conditions
.run()
}
// convert check results to a Spark data frame
val resultDataFrame = checkResultsAsDataFrame(spark, verificationResult)테스트 검증 결과 확인
resultDataFrame.show(truncate=false)

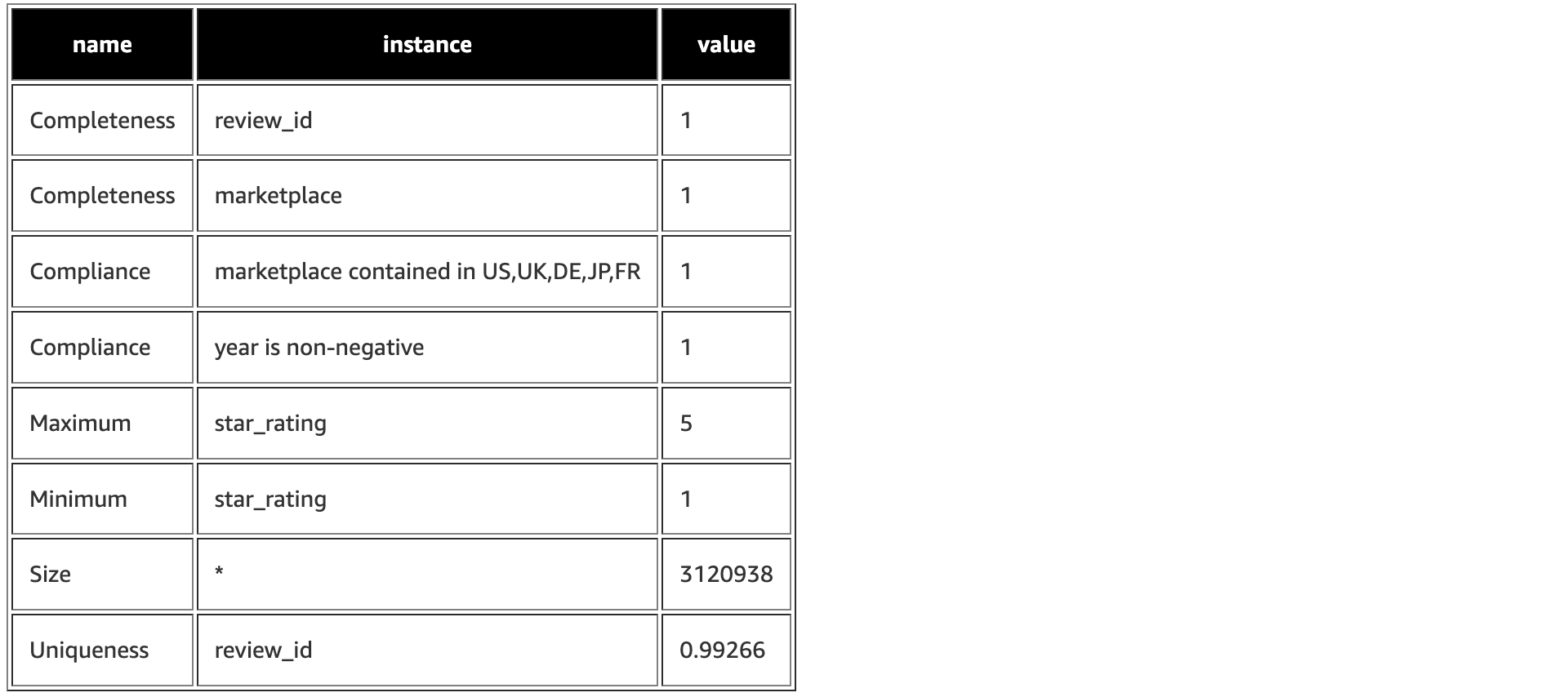
UniquenessConstraint(Uniqueness(List(review_id)))를 제외하고 모든 제약 조건을 만족하는 것을 확인할 수 있다- constraint_message 를 확인해보면, review_id는 99.2% 정도만 Unique 를 보장하고있음을 확인할 수 있다
계산된 모든 Metric 확인
VerificationResult.successMetricsAsDataFrame(spark, verificationResult).show(truncate=False)
Automated Constraint Suggestion
데이터의 열이 너무 많거나 수동으로 제약 조건을 정의하기 어려운 경우 사용합니다.
- 데이터 분포를 기반으로 유용한 제약 조건을 자동으로 제안
- 내부에서는 데이터 프로파일링을 진행한 후에 일련의 조건을 기반으로 제안하는 형식
import com.amazon.deequ.suggestions.{ConstraintSuggestionRunner, Rules}
import spark.implicits._ // for toDS method
// We ask deequ to compute constraint suggestions for us on the data
val suggestionResult = { ConstraintSuggestionRunner()
// data to suggest constraints for
.onData(dataset)
// default set of rules for constraint suggestion
.addConstraintRules(Rules.DEFAULT)
// run data profiling and constraint suggestion
.run()
}
// We can now investigate the constraints that Deequ suggested.
val suggestionDataFrame = suggestionResult.constraintSuggestions.flatMap {
case (column, suggestions) =>
suggestions.map { constraint =>
(column, constraint.description, constraint.codeForConstraint)
}
}.toSeq.toDS()제안된 제약 조건 확인
suggestionDataFrame.show(truncate=false)

제안된 제약 조건으로 Test 진행
val allConstraints = suggestionResult.constraintSuggestions
.flatMap { case (_, suggestions) => suggestions.map { _.constraint }}
.toSeq
val generatedCheck = Check(CheckLevel.Error, "generated constraints", allConstraints) //passing the generated checks to verificationSuite
val verificationWithSuggestionResult = VerificationSuite()
.onData(testData)
.addChecks(Seq(generatedCheck))
.run()
val verificationWithSuggestionResultDataFrame = checkResultsAsDataFrame(spark, verificationWithSuggestionResult)
verificationWithSuggestionResultDataFrame.show()
Data Engineer