
Overview

- 데이터 품질을 유지하고 팀 간 의사소통을 개선하기위해 데이터를 검증, 문서화, 프로파일링하는 도구
- 데이터에 대한 unit test, 데이터 문서 및 데이터 품질 보고서 생성
- python 기반 도구이기때문에 python 환경에서 잘 동작함 (이외 환경은 더 나은 선택지가 있을 수 있음)
Key Features
Expectations: 데이터에 대한 검증 가능한 주장Automated data profiling: 자동화된 데이터 프로파일링 제공- 라이브러리는 기본 통계를 얻기위해 데이터를 프로파일링하고, 데이터에서 관찰된 내용을 기반으로 일련의 Expectations를 자동으로 생성
Data validation: Expectations를 생성하고 나면 Great Expectations는 임의의 배치 또는 여러 데이터 배치를 로드하여 데이터를 검증할 수 있음- Great Expectations는 Expectation Suite 의 각 Exepctation이 통과 또는 실패했는지 여부를 알려주고, 테스트에 실패한 값을 반환하므로 데이터 문제 디버깅 속도를 크게 높일 수 있음
Data Docs: Great Expectations는 사람이 읽을 수 있는 HTML 데이터 문서를 반환Support for various Datasources and Store backends- Pandas Dataframe, Spark Dataframe, SQL Databases
- 다양한 데이터소스와 스토어를 지원. 즉, 데이터를 검증하기위해 특정 DB에 데이터를 보관할 필요없음
- 메타데이터 저장소를 구성하여 S3 및 Google Colud Storage와 같은 클라우드 저장소는 물론 파일 시스템, 데이터베이스에 모든 메타데이터(Expectations, 유효성 검사 결과 등)를 저장할 수 있다
Requirements and Installation
- python 3
- pip
$ pip install great_expectationsConcepts
저자가 느끼기에도 굉장히 복잡한 편이며 용어나 제공되는 API 가 굉장히 많다, 이런 전반적인 개념은 실제로 구축하면서 추가로 살펴보도록 하고 이 포스팅에서는 제공하는 튜토리얼 내용에 집중해서 기본적인 개념만 다루도록 하겠다.
- Great Expectations 에서 제공하는 튜토리얼 기반으로 개념을 간략하게 정리한다
1. Create a Data Context
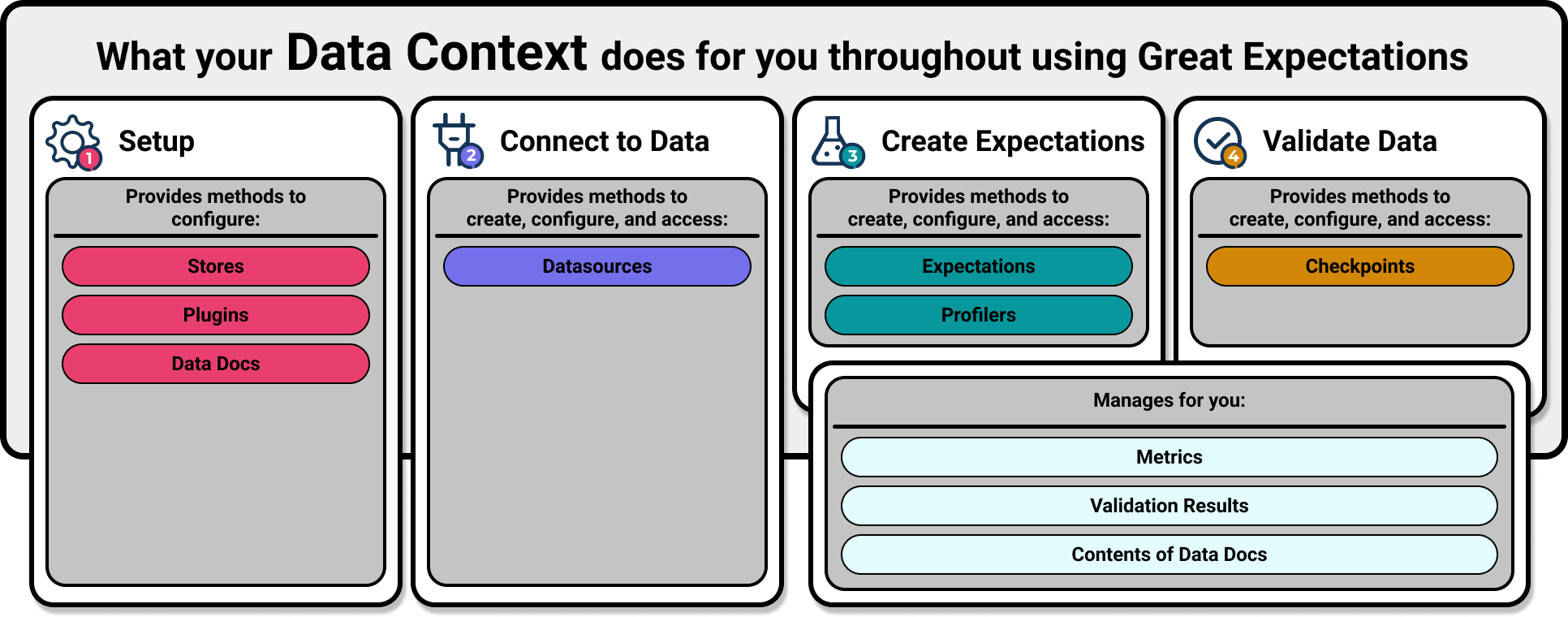
Data Context가 프로젝트 구성을 관리한다
- 프로젝트 디렉토리 내에서
great_expectations init를 실행 (git init 과 비슷)- 프로젝트 내에 great_expectations 디렉토리가 생성되고, 하위에 필요한 디렉토리 및 구성 파일을 구축
$ great_expectations init
Great Expectations will create a new directory with the following structure:
great_expectations
|-- great_expectations.yml # 배포의 기본 구성
|-- expectations # 모든 Expectation의 Json 파일
|-- checkpoints
|-- plugins # 배포의 일부로 개발하는 사용자들의 커스텀 플러그인
|-- .gitignore
|-- uncommitted # 버전 컨트롤에 있어서는 안되는 파일들
|-- config_variables.yml # 데이터베이스 credentials 과 같은 민감한 정보
|-- data_docs # Expectations, Validation Result, 기타 메타데이터에서 생성된 data docs
|-- validation # great expectations 에 의해 생성된 검증 결과 보유2. Connect to Data
Datasource 는 데이터 참조를 위한 일관된 cross-platform API 를 관리하고 제공한다
- 프로젝트 디렉토리 내에서
great_expectations datasource new를 실행- 연결할 데이터의 형식 (filesystem / 관계형 DB)
- 데이터 처리 방식 (pandas / pyspark)
- 데이터 경로
$ great_expectations datasource new
What data would you like Great Expectations to connect to?
1. Files on a filesystem (for processing with Pandas or Spark)
2. Relational database (SQL)
:1
What are you processing your files with?
1. Pandas
2. PySpark
:1
Enter the path of the root directory where the data files are stored. If files are on local disk
enter a path relative to your current working directory or an absolute path.
:data여기서 헷갈릴 수 있는 점은 위의 입력이 끝났다고 실제 Datasource 가 생성되는건 아니라는 것이다. 입력이 끝나면 위에서 정의한 Datasource 를 생성하기위한 몇 가지 상용구 코드가 포함된 jupyter notebook이 열린다.
- jupyter notebook 의 코드를 실행하면 Datasource 가 생성된다
great_expectaions.yml에서 생성된 Datasource를 확인/편집할 수 있다.
datasources:
getting_started_datasource:
class_name: Datasource
execution_engine:
module_name: great_expectations.execution_engine
class_name: PandasExecutionEngine
module_name: great_expectations.datasource
data_connectors:
default_inferred_data_connector_name:
class_name: InferredAssetFilesystemDataConnector
default_regex:
group_names:
- data_asset_name
pattern: (.*)
module_name: great_expectations.datasource.data_connector
base_directory: ../data
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
assets:
my_runtime_asset_name:
class_name: Asset
batch_identifiers:
- runtime_batch_identifier_name
module_name: great_expectations.datasource.data_connector.asset
module_name: great_expectations.datasource.data_connector3. Create Expectations
Expectations 는 Great Expectations의 핵심 개념이다
- 데이터에 대한 “데이터에 대해 검증 가능한 가정들 (A verifiable assertion about data)”이며 이는 python 함수 형태로 명시적으로 나타낼 수 있다
- 특정 컬럼의 값 범위가 주어진 조건에 맞는지, 특정 컬럼에 결측값이 존재하는지 등 데이터에 대한 검증 가능한 테스트들이라고 생각하시면 됩니다.
- 이미 많은 Expectations 를 제공하고 있으며 Custom 개발도 가능하다
- 프로젝트 디렉토리 내에서
great_expectations suite new를 실행Expectation Suite란 Expectation의 모음이다- 아래는 프로파일러를 통해 자동 Expectation 을 생성하는 예를 보여준다
$ great_expectations suite new
How would you like to create your Expectation Suite?
1. Manually, without interacting with a sample batch of data (default)
2. Interactively, with a sample batch of data
3. Automatically, using a profiler
: 3
A batch of data is required to edit the suite - let's help you to specify it.
Which data asset (accessible by data connector "default_inferred_data_connector_name") would you like to use?
1. yellow_tripdata_sample_2019-01.csv
2. yellow_tripdata_sample_2019-02.csv
: 1여기까지 진행했다면 Expectation Suite 의 이름을 작성하면된다. 여기서는 test.demo 라 하겠다.
Name the new Expectation Suite [yellow_tripdata_2019-01.csv.warning]: test.demo그럼 아래와 같이 몇가지 상용구 코드가 포함된 jupyter notebook 이 생성된다.
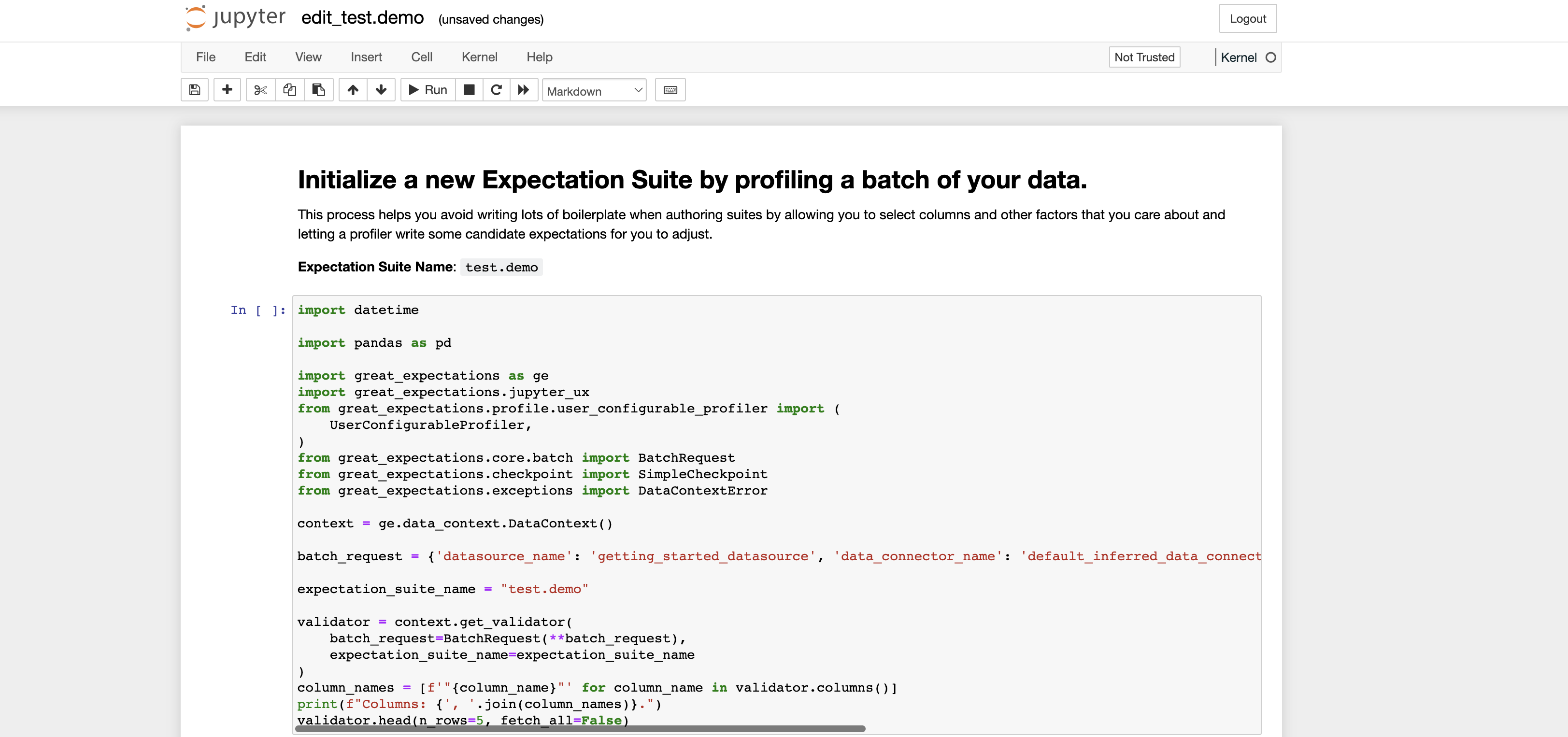
3.1 Expectation Suite 초기화
이제 데이터를 프로파일링하여 생성한 Expectation Suite를 초기화하는 작업이 필요하다. 본 섹션에서는 실행된 Notebook 파일의 구성을 살펴보고 마지막으로 생성한 데이터 문서 (Data Docs)를 살펴보도록 하겠다.
Expectation Suite를 생성하여 실행되는 Notebook 파일은 총 네 개의 코드 셀로 구성이 되어있다. 첫 번째 셀은 관련한 라이브러리를 임포트하고, Data Context를 불러온 다음 데이터 검증을 위한 Validator를 생성하는 내용을 포함하고 있다.
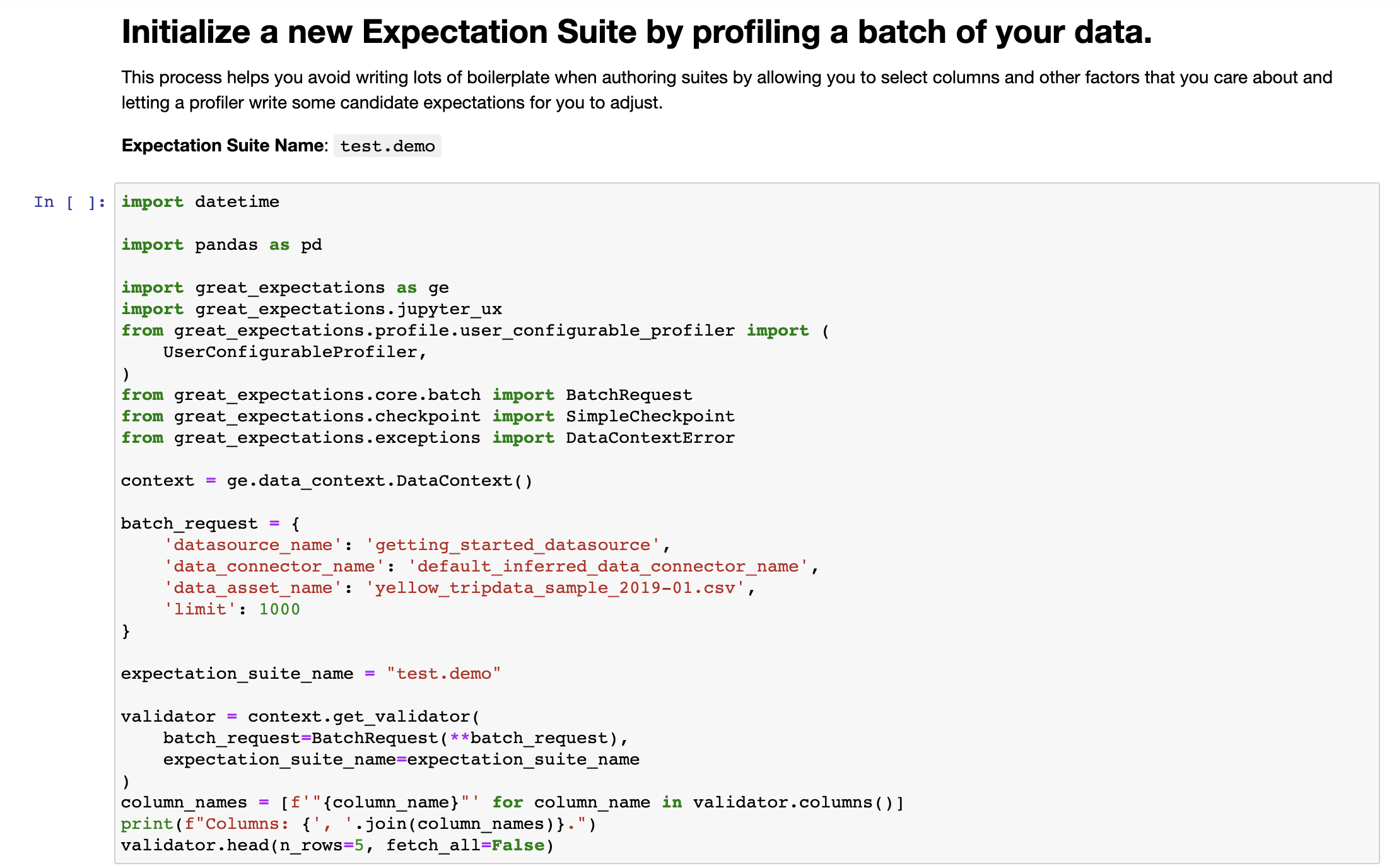
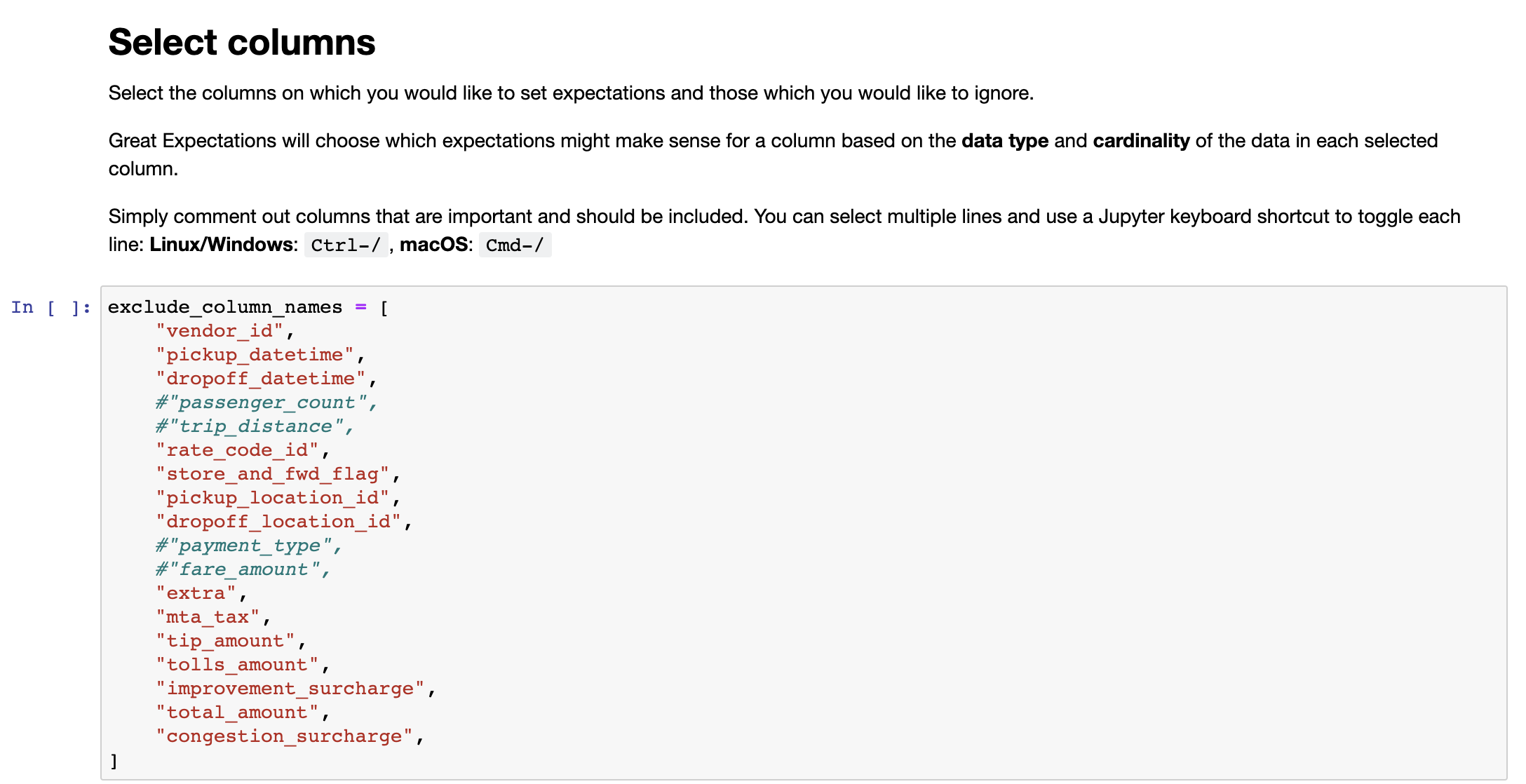
두 번째 셀은 데이터를 프로파일링할 때 무시할 컬럼들의 목록을 포함하고 있다. 기존 Notebook 파일에는 전체 컬럼으로 되어 있는데 필요에 따라 프로파일링할 컬럼들을 주석 처리하면 된다. 본 포스팅에서는 컬럼들 중 passenger_count, trip_distance,payment_type,fare_amount를 주석 처리해준다.
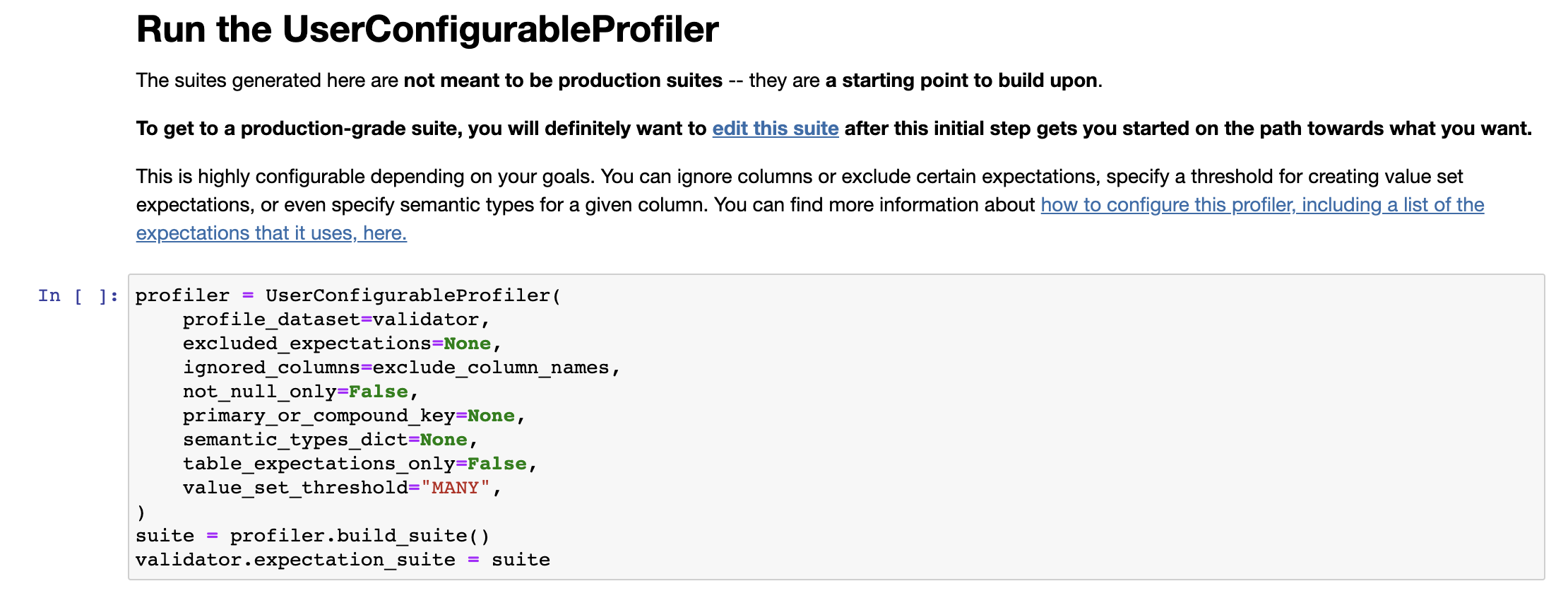
세 번째 셀은 사용자 설정 프로파일러 설정을 할 수 있다. 처음 프로파일러를 생성할 때는 별도로 설정할 값은 없다.
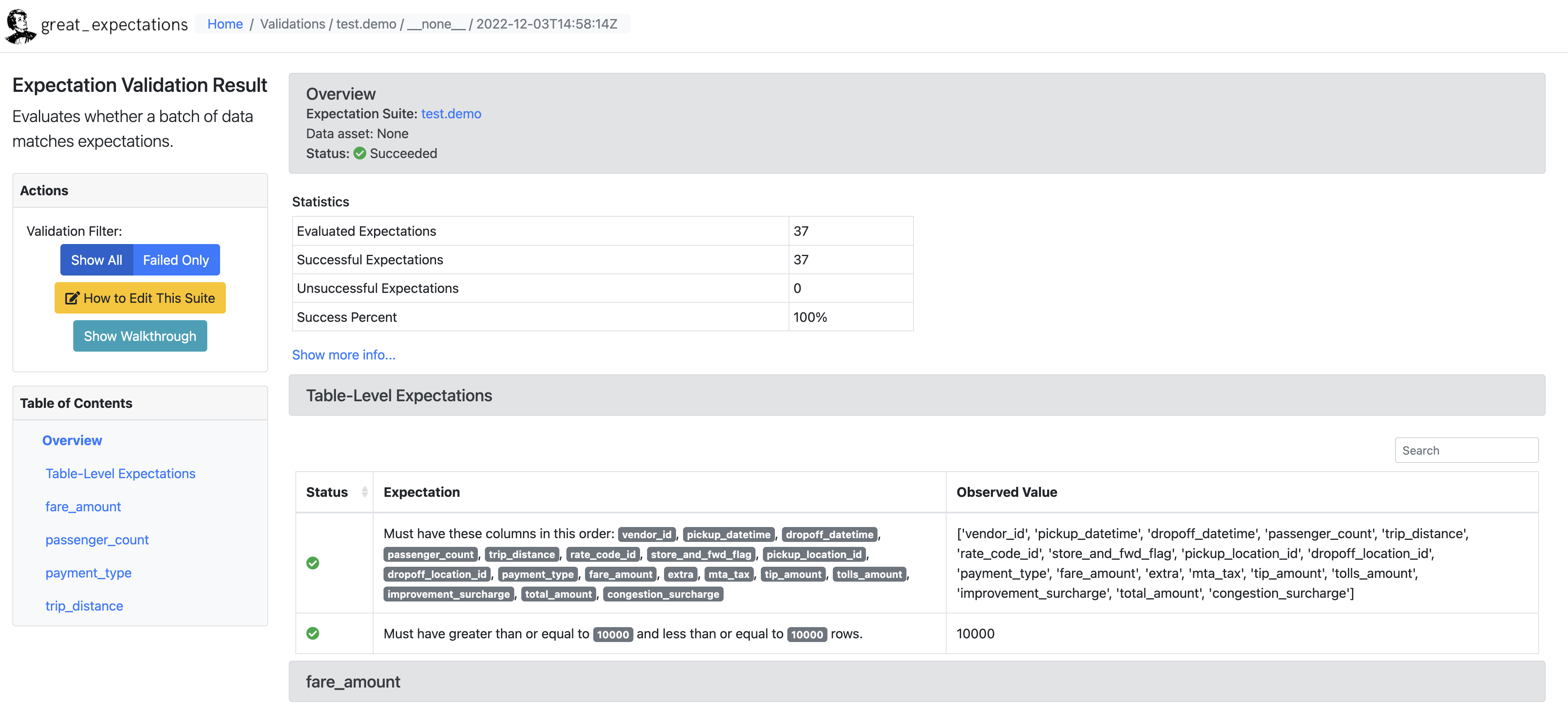
마지막 네 번째 셀은 Expectation Suite를 디스크에 저장하고 불러온 데이터 배치에 대해 검증을 수행한다. 그리고 데이터 문서를 실행시켜 주는데 여기서 검증 결과를 확인할 수 있다. 이 셀을 실행하면 지금까지의 설정을 바탕으로 작성된 데이터 문서를 확인할 수 있다.

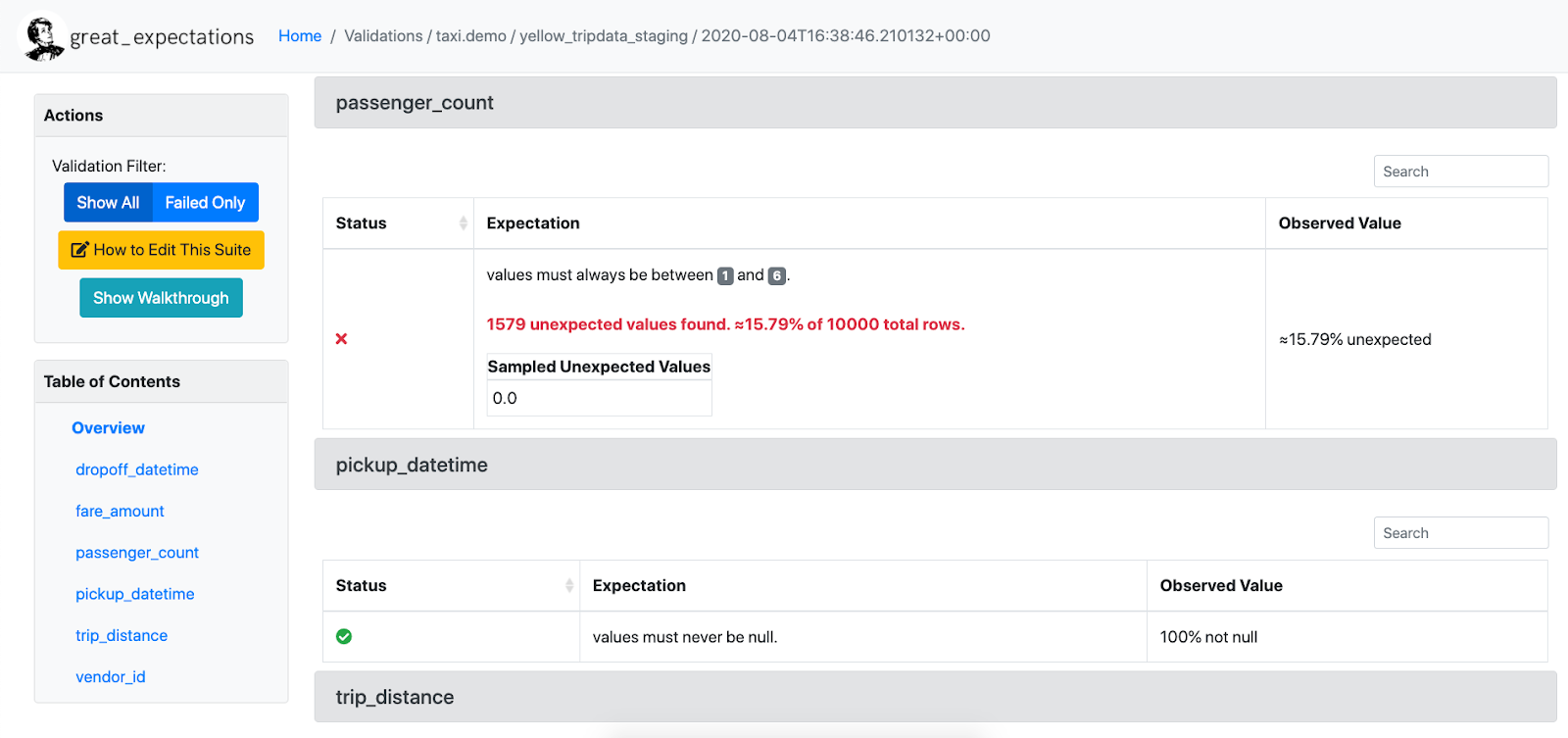
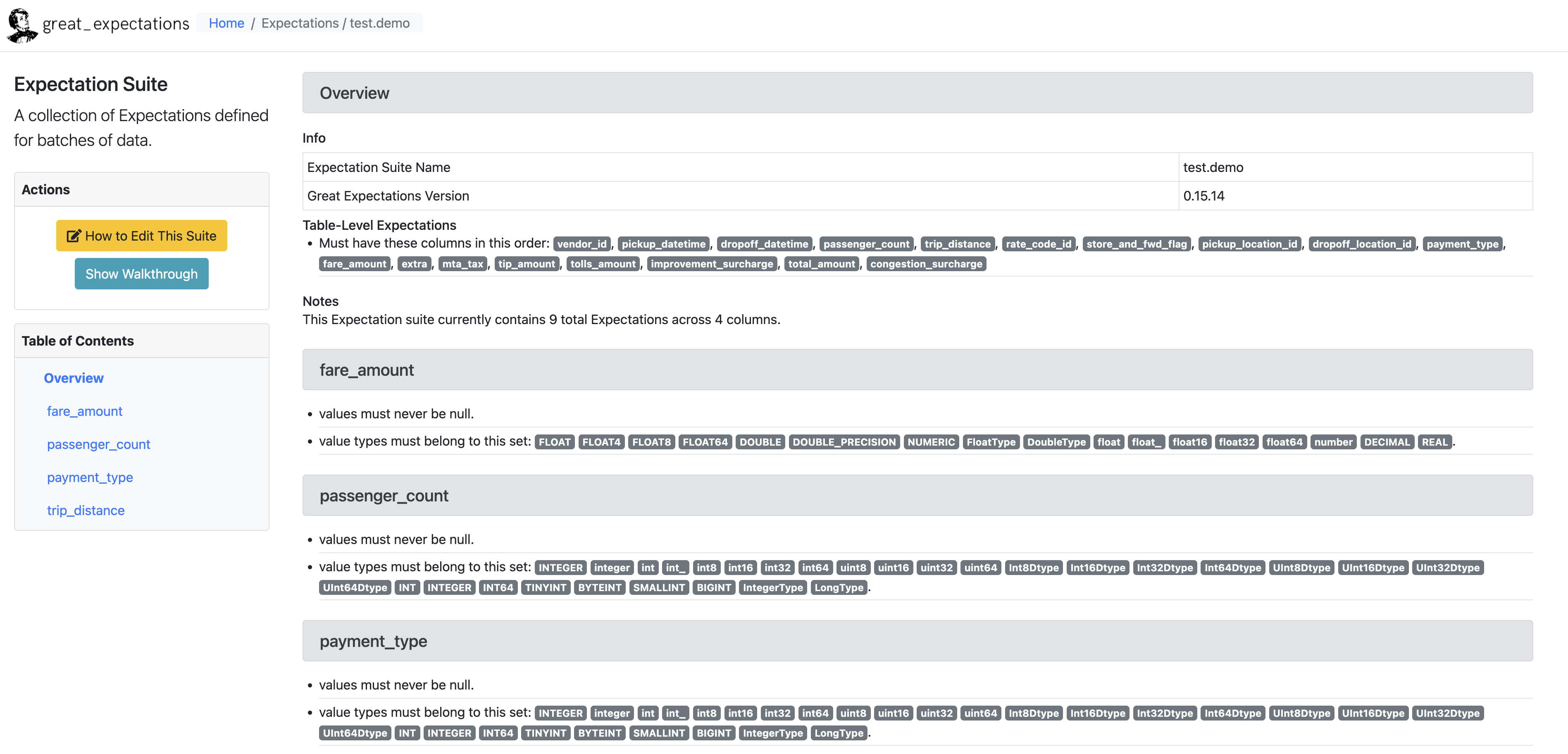
데이터 문서는 다음과 같이 생겼다.
3.2 Expectation 수정
데이터 문서를 살펴보면 여러 Expectation을 다루고 있다. 프로파일러를 통해 Expectation을 얻게 되면 기본적으로 다음과 같은 정보들을 얻게 된다.
- 컬럼의 데이터 타입
- 최솟값, 최댓값, 평균, 중앙값 등 단순 통계값
- 값의 빈도
- NULL 값의 개수
하지만 중앙값이 정확히 얼마가 나와야 한다던가, 데이터의 행 갯수가 정확히 몇 개여야 한다던가하는 불필요한 Expectations은 삭제하거나 수정할 필요가 있다. Expectation Suite를 수정하기 위해선 다음 명령어를 실행해야한다.
$ great_expectations suite edit test.demo그러면 Expectation Suite를 어떤 방법으로 수정할건지 물어보는 메시지가 출력되는데 본 포스팅에서는 1번을 선택했다.
Using v3 (Batch Request) API
How would you like to edit your Expectation Suite?
1. Manually, without interacting with a sample batch of data (default)
2. Interactively, with a sample batch of data
: 1그러면 edit_test.demo.ipynb 라는 notebook 파일이 하나 실행되는데 이 파일을 이용해서 Expectation Suite를 수정하면 된다. 기존에 존재하는 Expectation들을 삭제하기 위해서는 첫 셀의 내용을 조금 수정해야 한다.
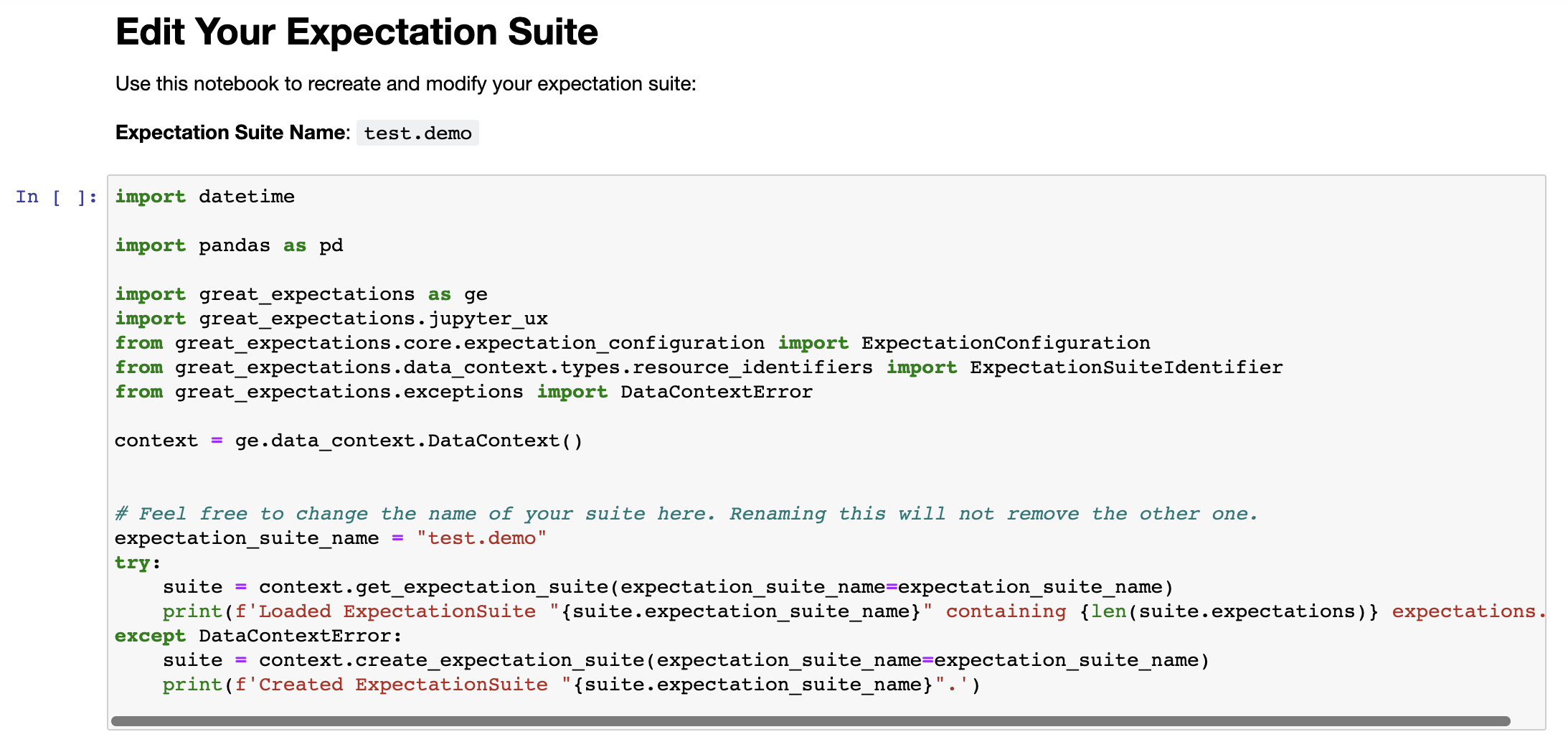
이 셀에서 맨 밑에 있는 try-except 문에서 except 부분만 사용해야한다. 그리고 다음과 같이 overwrite_existing=True를 추가한다.

그 이후 필요에 따라서 셀을 추가/수정하거나 삭제하면 된다.
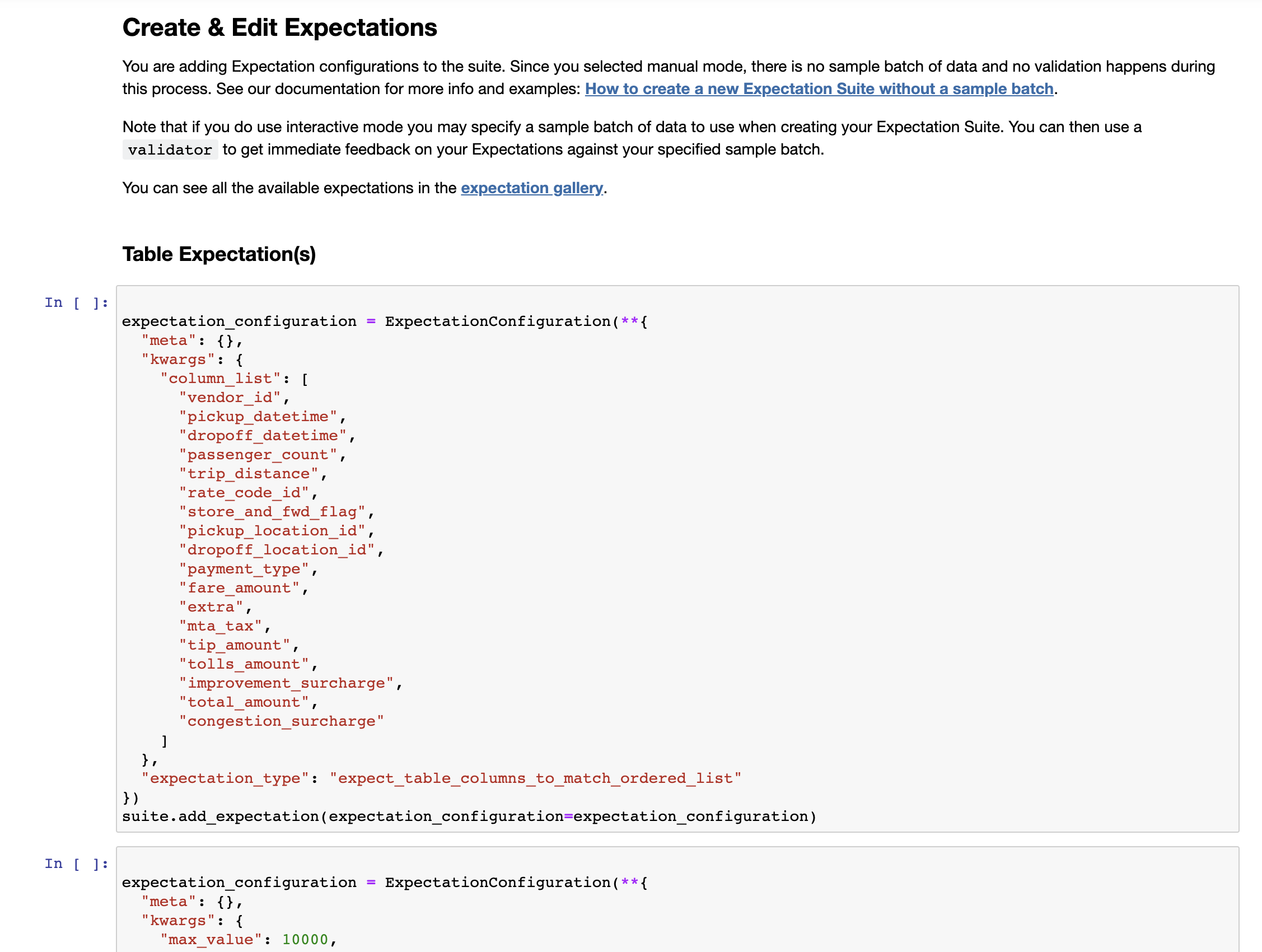
수정이 끝나면 모든 셀을 처음부터 끝까지 실행해준다. 그러면 데이터 문서가 다시 실행되고 올바르게 수정된 것을 확인할 수 있다.
great_expectations/expectations/test/demo.json 에서 JSON 파일로 Expectations Suite 를 확인할 수 있다.
{
"data_asset_type": null,
"expectation_suite_name": "test.demo",
"expectations": [
{
"expectation_type": "expect_table_columns_to_match_ordered_list",
"kwargs": {
"column_list": [
"vendor_id",
"pickup_datetime",
"dropoff_datetime",
"passenger_count",
"trip_distance",
"rate_code_id",
"store_and_fwd_flag",
"pickup_location_id",
"dropoff_location_id",
"payment_type",
"fare_amount",
"extra",
"mta_tax",
"tip_amount",
"tolls_amount",
"improvement_surcharge",
"total_amount",
"congestion_surcharge"
]
},
"meta": {}
},
{
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": {
"column": "passenger_count"
},
"meta": {}
},
..
]
"ge_cloud_id": null,
"meta": {
"great_expectations_version": "0.15.14"
}
}4.Validate Data
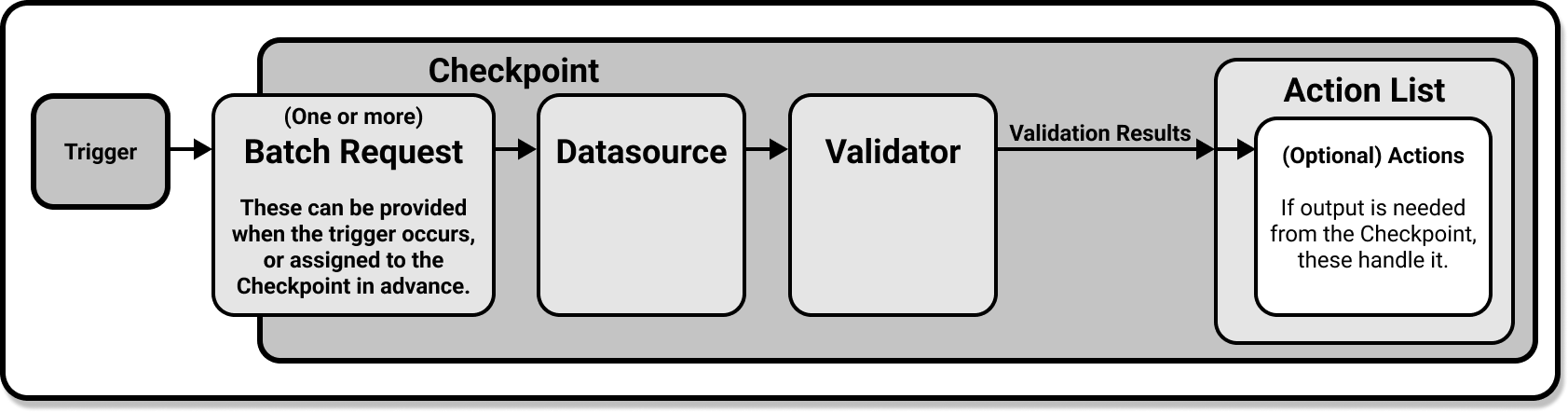
이제 마지막으로 데이터를 검증하는 일만 남았습니다. 여기서는 Checkpoint 사용한다.
- Checkpoint는 Great Expectations에서 프로덕션 배포에서 데이터를 검증하기 위한 기본 수단
- 데이터 배치에 대해 Expectation Suite를 실행하여 검증 결과를 생성
우선 터미널에서 아래 명령어를 입력하여 Checkpoint 를 생성한다.
$ great_expectations checkpoint new test_checkpoint두번째 셀을 보면 검증 데이터가 yellow_tripdata_sample_2019-02.csv 로 생성된 것을 확인할 수 있다. 검증에 사용할 Expectation Suite 는 test.demo 로 설정되어있다.
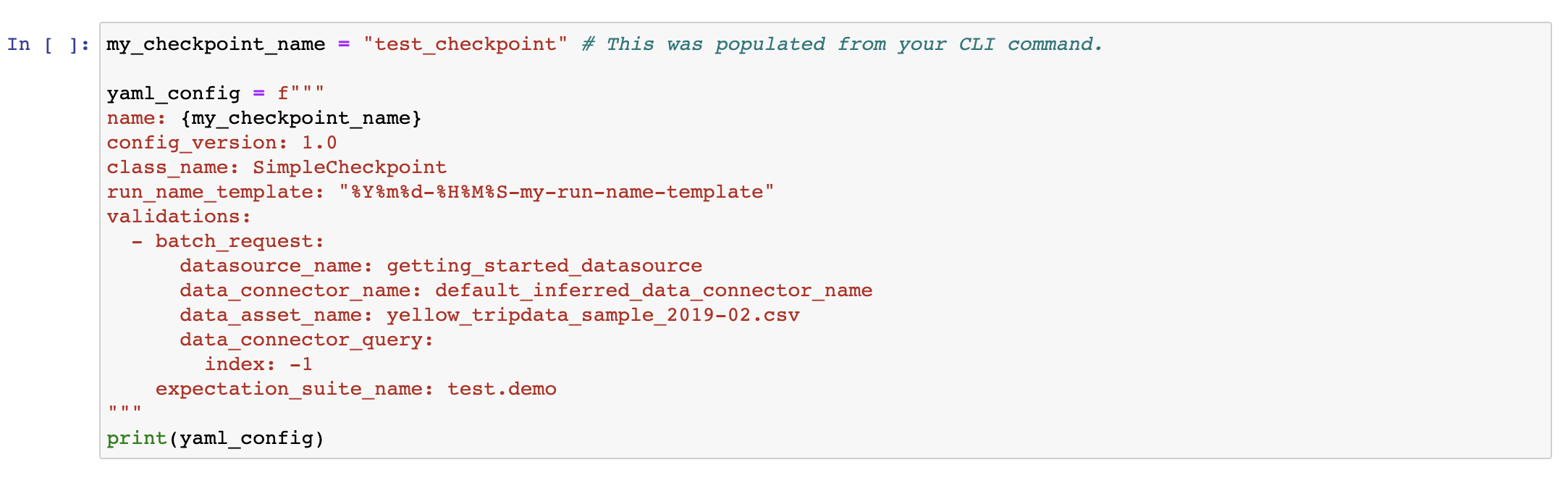
마지막 셀에 주석 처리되어있는 라인을 해제하여 Checkpoint 를 실행한다.

정상적으로 테스트가 통과한걸 확인할 수 있다.
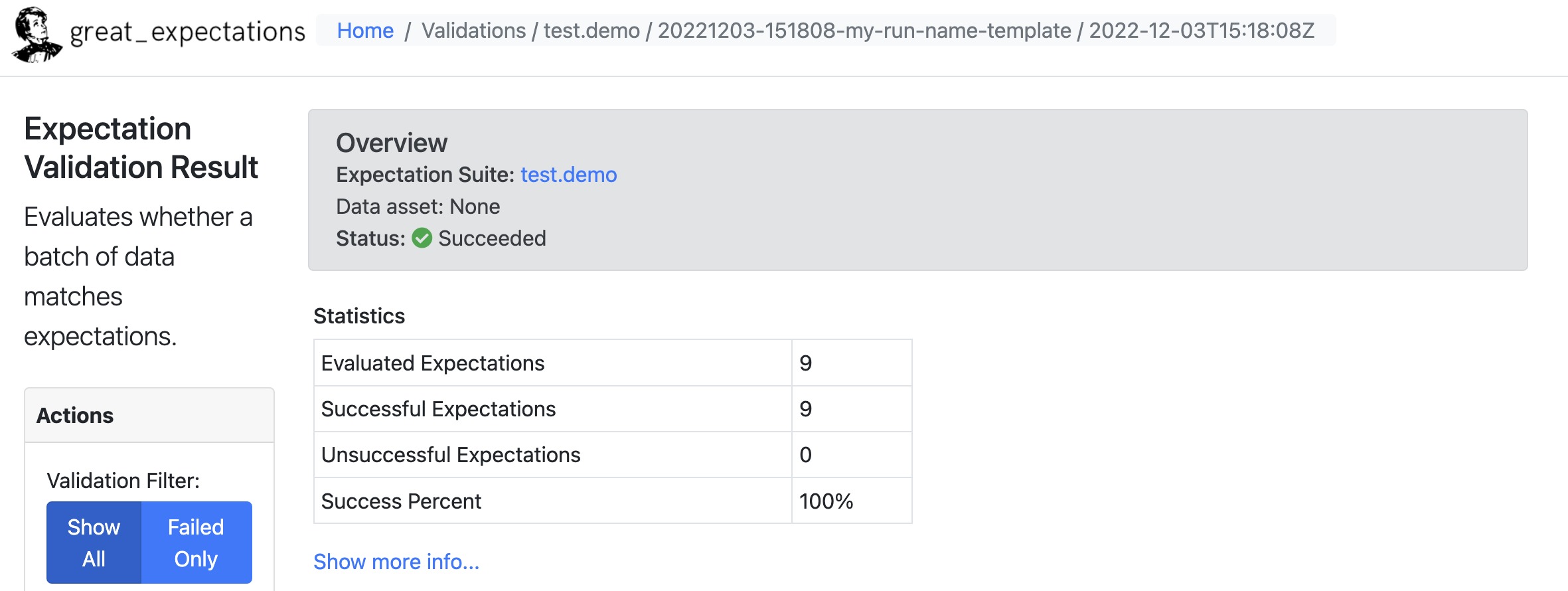
간략하게 튜토리얼을 통해 Great Expectations 의 전반적인 흐름을 살펴봤다.
다음 포스팅에서는 프로덕션 환경에서 Great Expectatios를 pyspark 을 이용하여 연동하는 방법을 살펴보겠다.

잘봤습니다.