알고리즘
1.[알고리즘] Bubble Sort(거품 정렬)

Bubble Sort는 인접한 두 수의 크기를 비교해서 조건에 맞게 자리를 교환하며 정렬하는 알고리즘이다.매 차례마다 앞에서부터 비교를 진행하며 가장 큰 수는 맨 마지막에 위치하게 되고, 다음 비교 대상에서 제외된다.시간 복잡도: 크기가 N인 배열의 경우 (N-1) +
2.[알고리즘] Selection Sort(선택 정렬)
Selection Sort에 대해 설명해보세요. Selection Sort의 작동 방식 Selection Sort는 매 차례 최솟값을 선택하여 앞으로 보내면서 정렬하는 방식의 알고리즘이다. 차례가 끝나면 선택된 원소는 다음 차례에서 선택할 때 제외된다. Selec
3.[알고리즘] Insertion Sort(삽입 정렬)
Insertion Sort는 매 차례마다 해당 원소를 삽입할 수 있는 위치를 찾아 넣는 정렬 알고리즘이다.두 번째 원소부터 앞에 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 원소들을 뒤로 옮기고 해당 위치에 삽입한다.시간 복잡도: 최선의 경우(이미 정렬되어 있는
4.[알고리즘] Quick Sort(퀵 정렬)
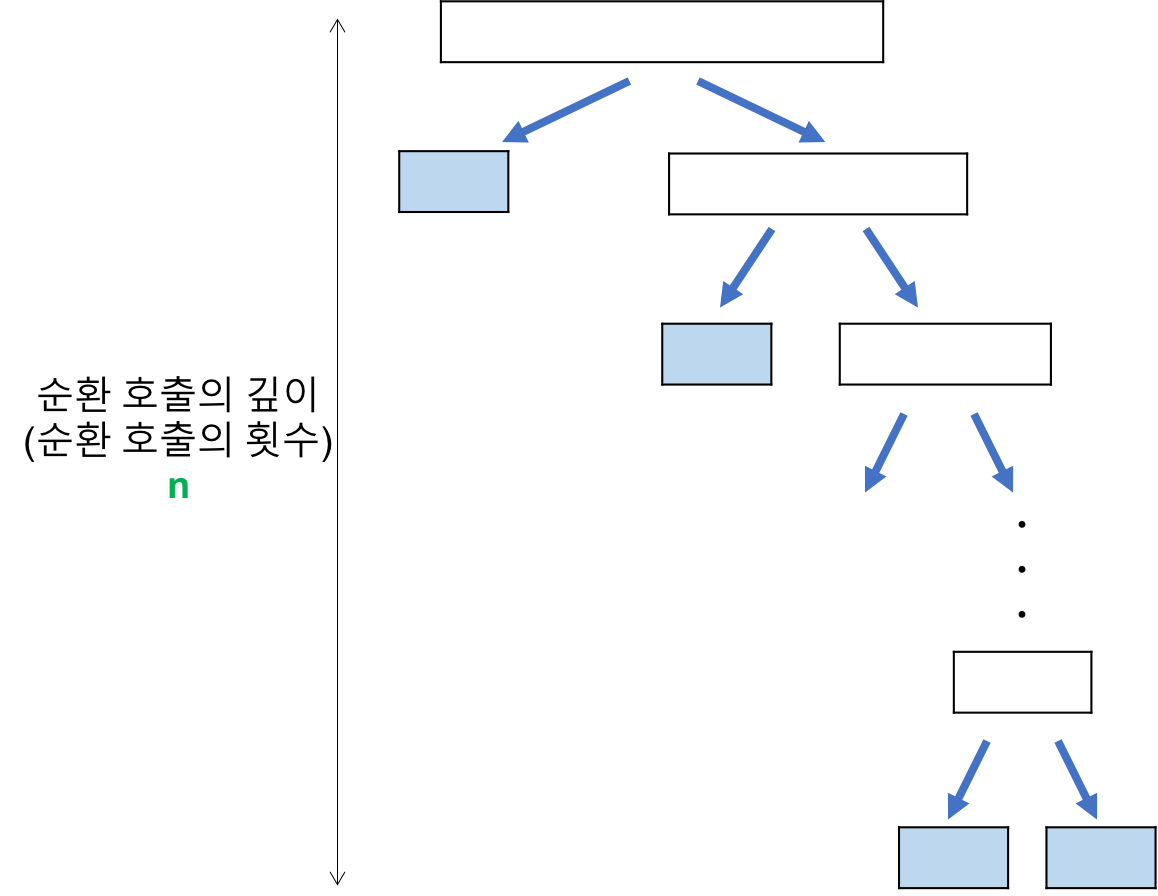
Quick Sort에 대해 설명해보세요. Quick Sort의 작동 방식 분할 정복 알고리즘의 하나로, 분할 정복 알고리즘은 문제를 두 개의 문제로 분리하여 각각을 해결한 후 다시 결합하는 방법을 말한다. 하나의 기준점(피벗, pivot)을 정해서 해당 숫자를 기준
5.[알고리즘] Merge Sort(병합 정렬)
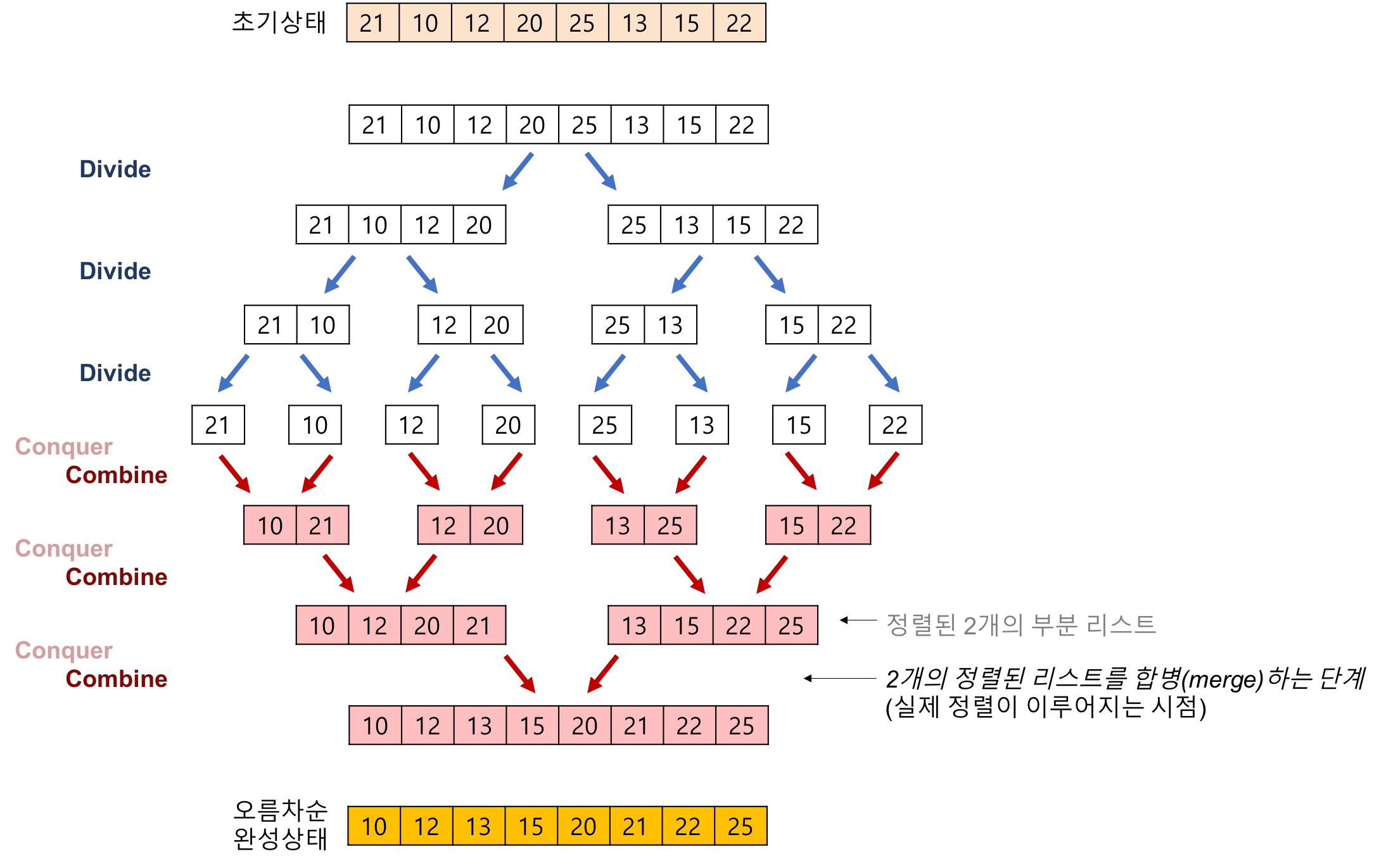
분할 정복 알고리즘의 한 종류로, 배열이 충분히 작아질 때까지 재귀적으로 분할하고 부분 배열들을 합병하면서 정렬이 되는 방식이다.부분 배열의 크기가 0 또는 1이 될 때까지 분할한다.부분 배열을 정렬하면서 하나의 배열로 합병한다.시간 복잡도: 최선, 평균, 최악의 경우
6.[알고리즘] Radix Sort(기수 정렬)
기수 정렬은 낮은 자리수부터 비교하면서 정렬하는 알고리즘이다. 비교 연산을 하지 않기 때문에 빠른 속도로 정렬이 가능하지만 자릿수가 존재하지 않는 데이터에 대해 정렬은 불가능하다. 가장 작은 자리수부터 비교하는 방법을 LSD(Least-Significant-Digit)
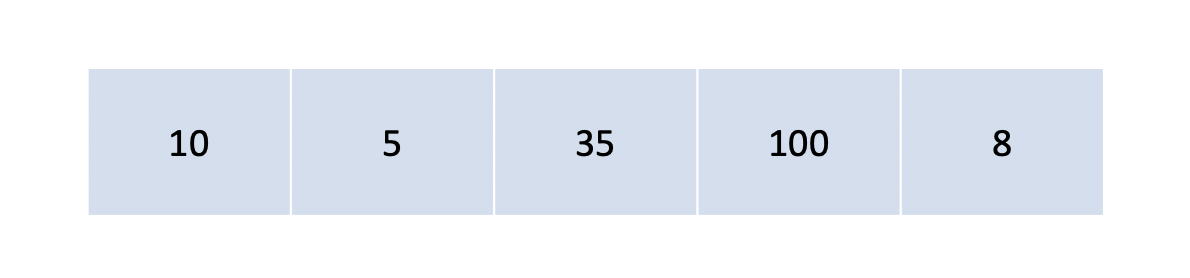
7.[알고리즘] Counting Sort(계수 정렬)
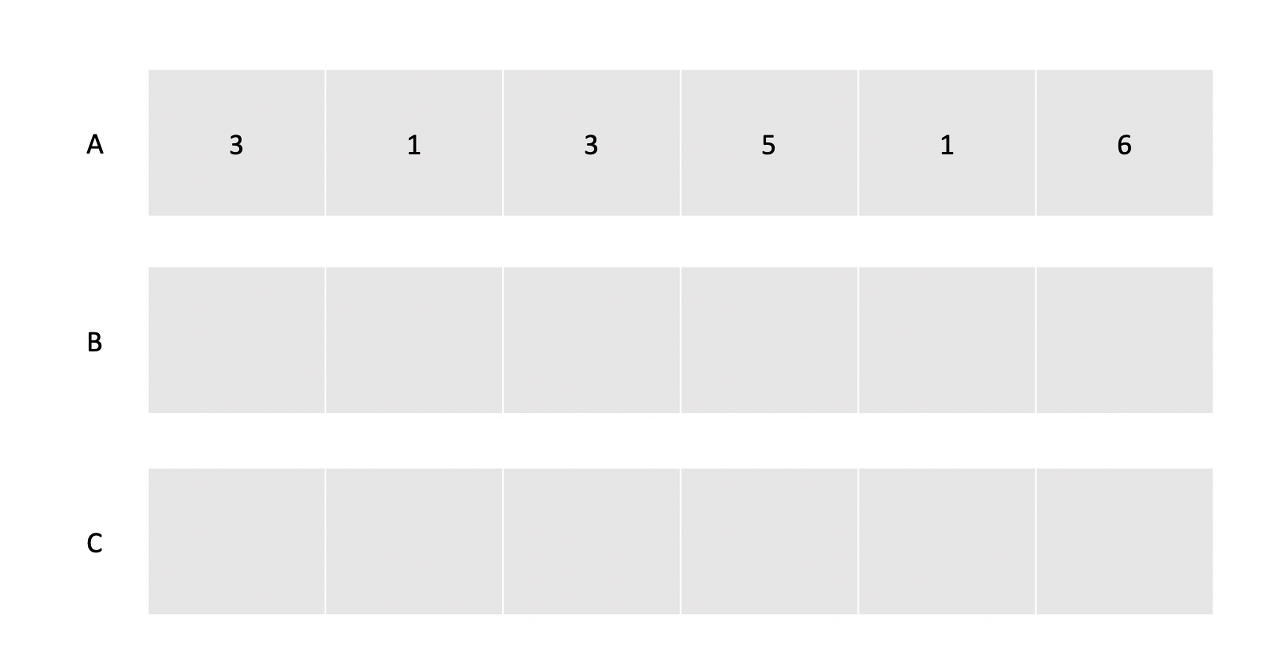
계수 정렬은 배열 내에 특정 값의 개수에 따라 정렬을 수행하는 알고리즘이다. 각 값의 개수를 세기 위한 배열과 결과를 저장할 추가 배열이 필요하다. 그림을 통해 알아보자.배열 A를 입력받고 개수를 저장하기 위한 배열 B와 결과를 저장할 C를 준비한다.A를 순회하며 각
8.[알고리즘] Floyd-Warshall(플로이드-워셜)
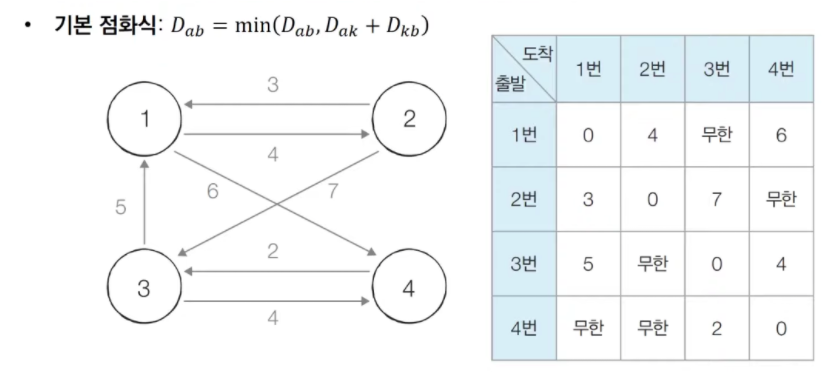
DP에 해당하는 알고리즘으로, 모든 노드에서 다른 모든 노드까지의 최단 경로를 구하는 알고리즘이다. 1\. 모든 노드 간의 최단 거리를 저장할 2차원 행렬을 만든다. 자기 자신은 모두 0으로, 연결되지 않은 노드는 임의의 큰 값으로 초기화 한다. 2\. 1번 노드
9.[알고리즘] Bellman-Ford(벨만-포드)
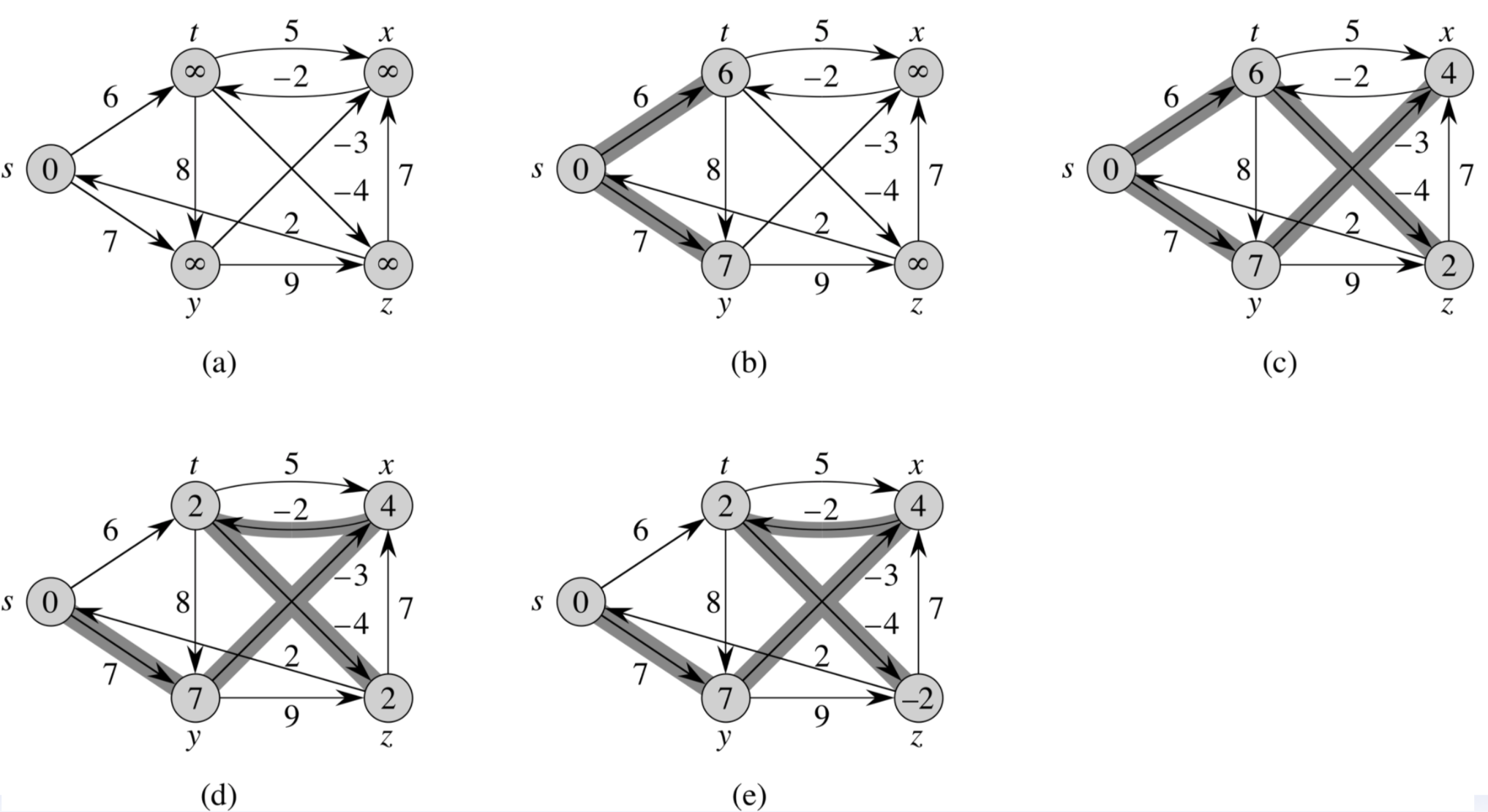
DP에 속하는 알고리즘으로, 음수 간선이 포함된 그래프에서도 적용 가능한 한 노드에서 다른 모드 노드까지의 최단 경로를 구하는 알고리즘이다.시작 노드를 선택한다.최단 거리를 저장할 1차원 배열을 시작 노드 기준으로 본인은 0으로, 나머지 노드는 임의의 큰수로 초기화한다
10.[알고리즘] A* 알고리즘
A\* 알고리즘은 그리디 알고리즘의 한 종류로, 시작 노드로부터 목표 노드까지의 최단 경로를 구하는 알고리즘이다.시작 노드부터 현재 노드까지의 비용을 g(n), 현재 노드에서 목표 노드까지의 예상 비용을 h(n)이라고 하면, 이 두 값을 더한 f(n) = g(n) +
11.[자료구조/알고리즘] Dijkstra Algorithm(다익스트라 알고리즘)
다익스트라 알고리즘은 그래프 안의 한 노드에서 다른 노드까지의 최단 경로를 구하는 알고리즘이다.매 번 최단 경로의 노드를 선택하여 탐색하므로 도착 노드 뿐 아니라 다른 노드까지 최단 경로로 이동한다.음수의 가중치 간선은 없다고 가정한다.시작 노드를 선택한다.시작 노드를
12.[알고리즘] Dynamic Programming(동적 계획법)
동적 계획법이란 복잡하고 큰 문제를 간단하고 여러 개의 작은 문제로 나누어 푸는 방법을 말한다. 분할 정복과 비슷하나, 계산한 부분 문제 결과를 저장하여 필요할 때 다시 꺼내어 사용한다는 점에서 차이가 있다. 이 결과들을 재활용하는 메모이제이션(Memoization)기
13.[알고리즘] LCS(Longest Common Substring, Longest Common Subsequence)

LCS에는 두 가지 의미가 있다. 최장 공통 문자열(Longest Common String)과 최장 공통 부분수열(Longest Common Subsequence)이다. 최장 공통 문자열은 연속된 부분 문자열이고, 최장 공통 부분수열은 연속적이지 않은 부분 문자열이다.
14.[알고리즘] LIS(Longest Increasing Subsequence, 최장 증가 부분수열)

원소가 N개인 배열의 일부 원소를 골라 만든 부분 수열 중에서 각 원소가 앞에 있는 원소보다 크고 그 길이가 최대인 부분 수열을 최장 증가 부분수열이라고 한다. 주어진 수열에서 LIS의 길이를 구하는 방법은 대표적으로 두 가지가 있다.수열의 길이와 같은 LIS 배열을
15.[알고리즘] Divide and Conquer(분할 정복)
분할 정복 알고리즘은 하나의 큰 문제를 여러 개의 충분히 작은 문제로 분할하여 해결한 후 다시 합병하여 문제를 해결하는 알고리즘 방식이다.분할 정복 알고리즘을 사용하기 위해 필요한 조건들이 있다.문제를 분할하는 과정에서, 큰 문제와 작은 문제의 구조가 같아야 한다. 즉
16.[알고리즘] Greedy Algorithm(탐욕법)
Greedy Algorithm에 대해 설명해보세요. 그리디 알고리즘
17.[알고리즘] Binary Search(이진 탐색)
이진 탐색이라고 하며, 배열 안의 데이터들이 정렬되어 있는 상태일 경우 빠른 속도로 탐색이 가능한 기법이다. 중간 원소를 기준으로 원하는 데이터와 비교하며 탐색 범위를 절반씩 좁혀가면서 탐색한다.이진 탐색은 위치를 나타내는 3개의 변수를 사용한다. 배열의 맨 앞부분(시
18.[알고리즘] Heap Sort(힙 정렬)
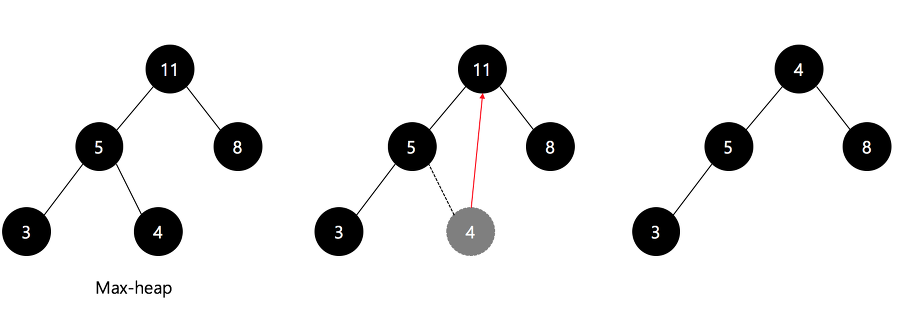
자료구조 힙(Heap)을 기반으로 정렬하는 방식으로, 배열의 요소들을 최대 힙이나 최소 힙으로 구성하여 루트 값을 마지막 요소와 바꾼 후, 마지막 요소를 삭제하고 다시 최대 힙이나 최소 힙으로 구성하는 과정을 반복하여 힙의 사이즈가 1이 될 때까지 진행한다.시간 복잡도