Quick Sort에 대해 설명해보세요.
Quick Sort의 작동 방식
-
분할 정복 알고리즘의 하나로, 분할 정복 알고리즘은 문제를 두 개의 문제로 분리하여 각각을 해결한 후 다시 결합하는 방법을 말한다.
-
하나의 기준점(피벗, pivot)을 정해서 해당 숫자를 기준으로 원래의 배열을 기준 보다 작은 수의 배열과 큰 수의 배열로 나눈다.
-
모든 배열이 하나의 원소를 가질 때까지 재귀적으로 반복하고 다시 하나의 배열로 합병하여 배열을 정렬하는 알고리즘이다.
-
배열 안에서 피벗을 정한다.
-
피벗을 기준으로 피벗보다 작으면 왼쪽으로, 크면 오른쪽으로 옮긴다.
-
왼쪽 배열과 오른쪽 배열에 대하여 원소가 하나가 될 때까지 재귀적으로 반복하여 정렬한다.
Quick Sort의 특징
-
시간 복잡도
-
최선의 경우
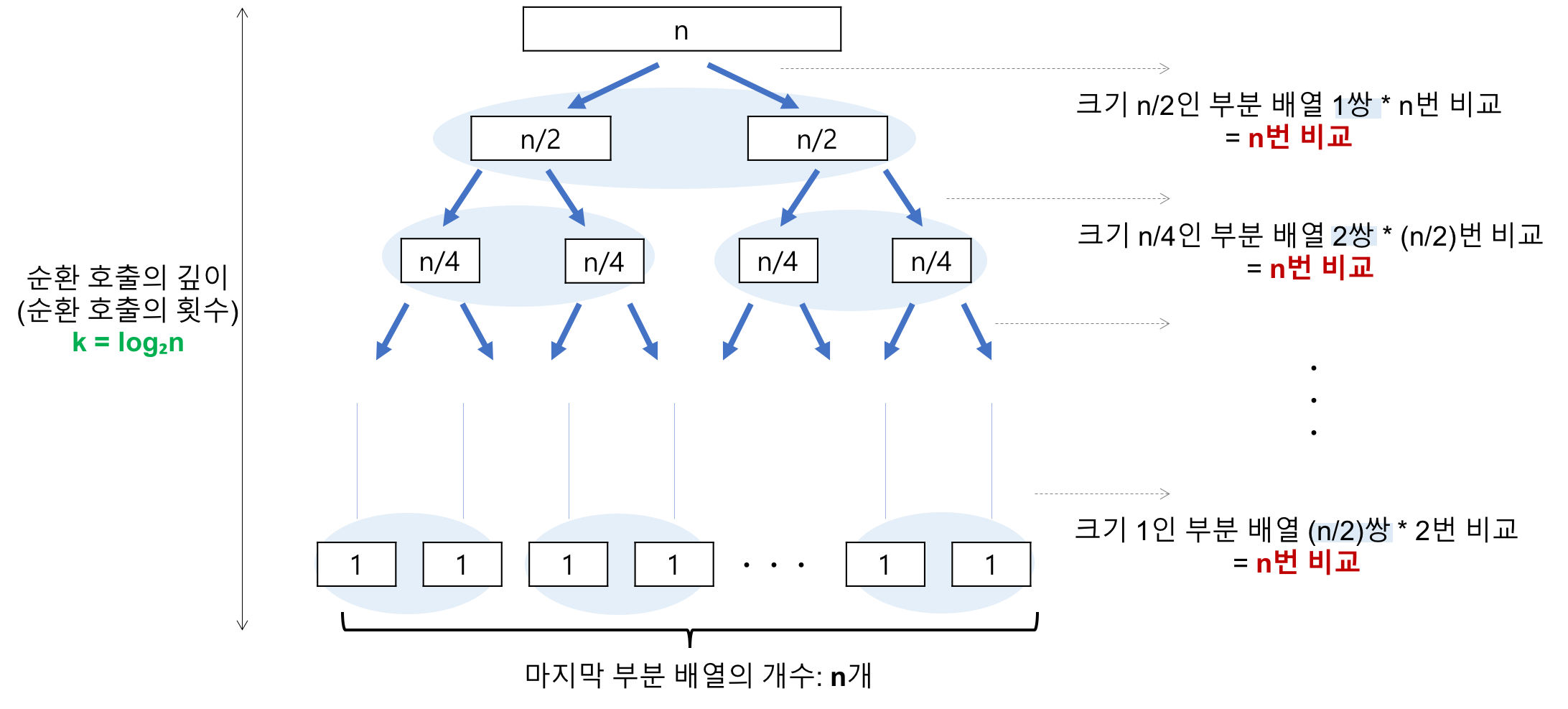
각 순환 호출 단계에서 평균 N번의 비교 연산이 발생하고, 트리의 높이는 logN이므로 순환 호출의 깊이는 logN이다. 따라서 최선의 경우 시간 복잡도는 O(NlogN)을 가진다. -
평균의 경우
평균의 경우 시간 복잡도는 O(NlogN)을 가진다. 불필요한 이동을 줄이고 한 번 정해진 피벗들은 추후 비교 연산에서 제외되므로 다른 O(NlogN)의 시간 복잡도를 가지는 정렬 알고리즘보다 빠르다. -
최악의 경우
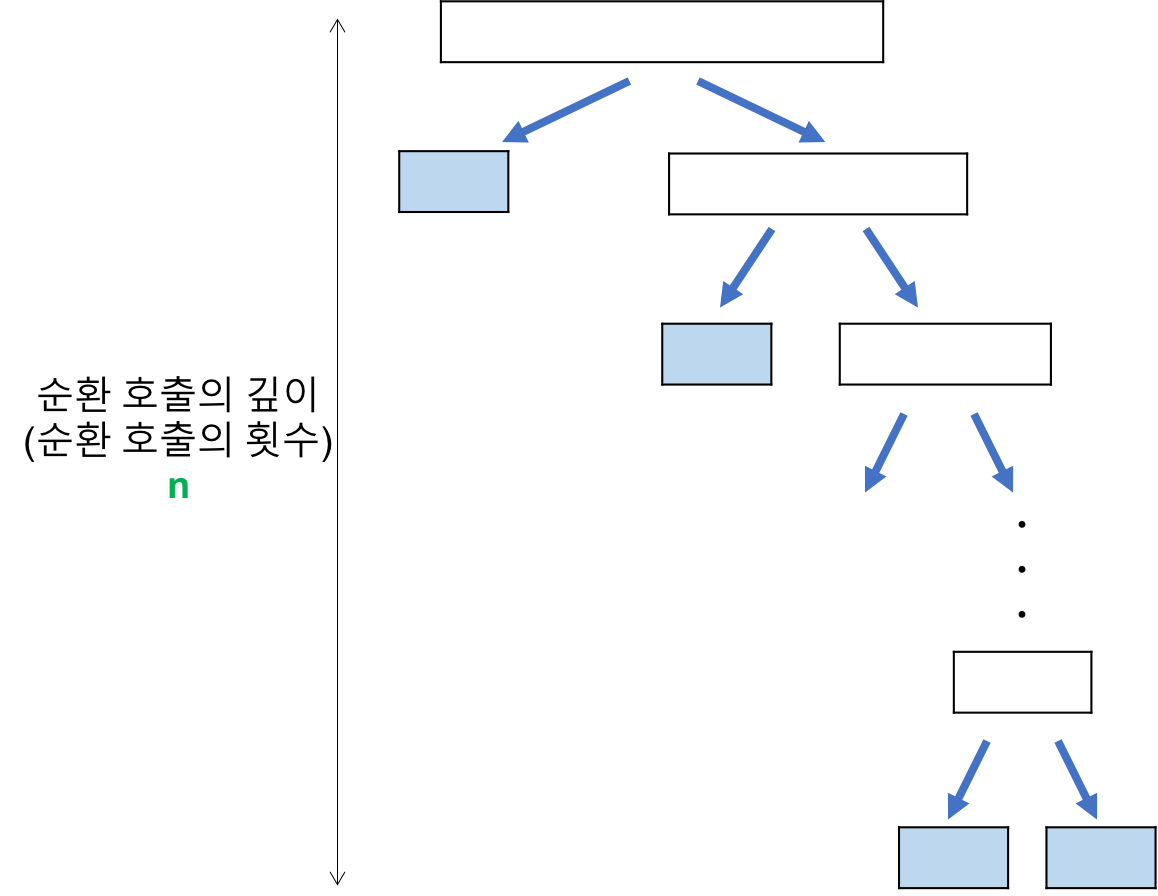
일반적으로 배열이 오름차순이나 내림차순으로 정렬되어 있는 경우이다. 분할을 하면 위의 그림과 같이 계속 불균형하게 나누어지고 순환 호출의 깊이가 N으로 깊어지게 된다. 각 순환 호출 단계에서 평균 N번의 비교 연산이 발생하므로 최악의 경우 시간 복잡도는 O(N^2)을 가진다.
-
-
공간 복잡도
: 주어진 배열 안에서 교환이 일어나면서 정렬되므로 추가 메모리 공간 필요 없이 O(N)의 공간 복잡도를 가진다. -
장점
- 대부분의 경우에 속도가 빨라 효율적이다.
- 추가 메모리 공간이 필요 없다.
-
단점
- 이미 정렬되어 있는 배열의 경우 시간이 오래 걸린다.
결론
Quick Sort는 배열 안에서 피벗을 정하여 피벗을 기준으로 피벗보다 크고 작은 두 개의 배열로 재귀적으로 분할하여 정렬하는 분할 정복 방식의 알고리즘입니다. 평균적으로 O(NlogN)의 시간 복잡도를 가지며 다른 정렬 알고리즘보다 빠른 속도로 정렬이 가능합니다. 하지만 이미 정렬되어 있는 배열의 경우 O(N^2)의 시간 복잡도를 가지면서 오히려 오래 걸리게 되는 단점이 있습니다. 공간 복잡도는 배열 안에서 정렬이 진행되므로 O(N)을 가집니다.
