
확률
확률의 정의
수학적 확률
라플라스의 확률이라고도 한다.
총 경우의 수: N
사건 A가 일어나는 경우의 수: n
이때 사건 A가 일어나는 경우의 수는 다음과 같다.
통계적 확률
콜모고로프의 확률이라고도 한다.
이때, rn 은 사건 A가 일어난 횟수이며, n은 시행 횟수를 의미한다.
즉, 시행횟수가 무한대로 수렴하면서 특정 사건이 일어날 확률이 점점 확률값에 수렴됨을 의미한다.
기하학적 확률
조건부 확률
원래의 실험으로부터 그 일부인 새로운 표본 공간으로 축소한 또 다른 실험의 확률을 의미한다.
이때 P(B)는 0이 아니어야 한다.
위 식의 의미는 사건 B가 일어났다는 조건 아래에서 사건 A가 일어날 확률을 의미한다.
독립 사건
A 사건과 B 사건이 서로 독립이면, 서로의 사건이 일어나는데 영향을 끼치지 않는다.
이를 조건부 확률을 이용하여 수식으로 표현하면 다음과 같다.
베이즈 정리
베이즈 정리는 조건부 확률을 이용한 것이지만, 의미는 조금 다르다.
조건부 확률은 말 그대로 특정 조건이 일어났을 때 다른 사건이 일어날 확률 그 교집합에 대해 구하는 것이다.
그러나 베이즈 정리는 실험자가 설정한 사전 확률 P(h)가 있을 때, 실제로 일어난 특정 사건의 확률 P(D)가 사전확률이 일어난 조건하에서 일어날 확률인 likelihood P(D|h)를 이용하여 실제로 일어난 특정 사건이 일어났다는 조건 하에, 실험자가 설정한 가정이 사실이었을 확률을 예측하는 것이다.
즉, 조건부 확률을 바로 구할 수 없을 때, 사전확률을 정해주어 실험한 것으로 구하고자 했던 확률을 예측하는 것이 베이즈 정리이다.
공분산과 상관 계수
공분산과 상관계수를 이용하여 두 변수간의 상관관계를 파악할 수 있다. 인과관계를 파악하는 것이 아니라는 점을 유의하자.
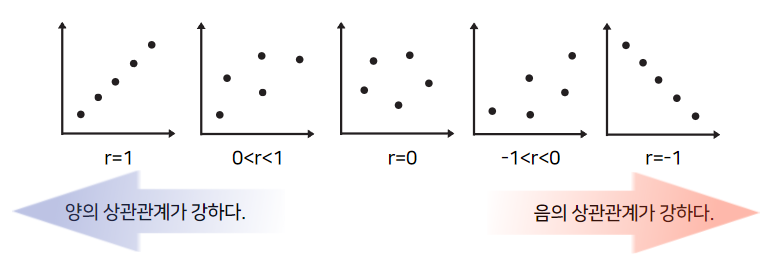
양의 상관관계가 있다는 것은 x와 y가 같은 방향으로 움직인다는 의미이다. 예를 들어, x가 증가할수록 y도 증가하는 것은 양의 상관관계를 띄는 것이다.
반대로 음의 상관관계가 있다는 것은 x와 y가 반대 방향으로 움직인다는 의미이다. 예를 들어, x가 증가할수록 y도 감소하는 것은 음의 상관관계를 띄는 것이다.
이러한 공분산과 상관계수를 구하기 위해서는 먼저, 기댓값과 분산에 대해 알아야 한다.
기댓값과 분산
확률에서의 기댓값
통계실험을 반복적으로 했을 때, 평균적으로 관측될 것으로 기대되는 값을 의미한다.
즉, 평균을 구하는 것이다.
x가 이산확률변수일 때 기댓값은 다음과 같이 구할 수 있다.
x가 연속확률변수일 때 기댓값은 다음과 같이 구할 수 있다.
분산
데이터들이 평균으로부터 얼마나 떨어져 있는지를 파악할 수 있게 하는 값이다.
x가 이산확률변수일 때 분산은 다음과 같이 구할 수 있다.
x가 연속확률변수일 때 분산은 다음과 같이 구할 수 있다.
이때 μ는 x의 기댓값을 의미한다.
이러한 분산에 루트를 씌우면 표준편차가 된다.
공분산
확률변수 X와 Y의 기댓값이 각각 μx, μy일 때, 공분산은 다음과 같이 구할 수 있다.
이 공분산이 양수이면, X와 Y가 동일한 방향으로 변한다는 것이고, 음수이면 반대방향으로 변한다는 의미이다.
상관계수
확률변수 X와 Y의 기댓값이 각각 μx, μy이고, 표준편차가 각각 σx, σy일 때 상관계수는 다음과 같이 구할 수 있다.
PXY > 0 이면 두 확률 분포는 양의 상관관계이다.
PXY < 0 이면 두 확률 분포는 음의 상관관계이다.
PXY = 0 이면 두 확률 분포는 상관관계가 없다.
PXY = 1 이면 두 확률 분포는 완전 양의 상관관계이다.
PXY = -1 이면 두 확률 분포는 완전 음의 상관관계이다.
