현재 쇼핑몰 프로젝트 상품 도메인의 좋아요 구현 과정과 트래픽이 발생한다는 가정하에 성능을 위한 리팩토링에 대한 이야기를 담아보았습니다.
DB 모델링
가장 단순하게 생각되고 구현도 쉬운 방법입니다. 바로 상품 테이블에 likeCount 필드를 만들어 좋아요 요청을 받으면 likeCount 필드의 값을 증가시키는 것입니다.
Product 테이블
CREATE TABLE `product` (
`id` bigint NOT NULL AUTO_INCREMENT,
...
`like_count` bigint DEFAULT 0,
PRIMARY KEY (`id`)
)하지만 이 방법에는 크게 두 가지 문제점이 있습니다.
첫째로 좋아요 요청마다 update 쿼리가 계속 발생한다는 것입니다. 이러한 모델링에서 구현 방법은 디폴트 값을 0으로 주고 요청마다 현재 값에 더하는 방식입니다. MySQL 은 기본적으로 REPEATABLE READ 격리 수준을 사용하기 때문에 update 쿼리에 락이 걸리게 되고 좋아요 데이터 때문에 PRODUCT 테이블에 대한 다른 요청들이 경합을 하게 됩니다. 이 방법의 장점은 join 이나 subQuery없이 select 한 줄로 좋아요 수를 읽을 수 있다는 것이고 단점은 좋아요 요청때문에 PRODUCT 테이블의 데이터를 두고 다른 요청들이 경합해야 한다는 것입니다.
두번째로 중복 검사가 안된다는 점입니다. 현재 방법은 요청이 오면 한 개씩 증가만 시키기 때문에 같은 사용자가 여러 번 요청해도 각각의 요청을 유니크한 값으로 처리하게 됩니다. 이렇게 되면 상품 좋아요를 사용하는 비즈니스 로직이 제대로 된 사용자 데이터를 반영하지 못하고 외부 매크로 조작에 취약해집니다.
PRODUCT 와 좋아요 분리
PRODUCT 테이블에 잡히는 락을 최소화 하기 위해 likeCount 필드를 PRODUCT_LIKE 테이블로 분리합니다.
Product 테이블
like_count삭제
CREATE TABLE `product` (
`id` bigint NOT NULL AUTO_INCREMENT,
...
PRIMARY KEY (`id`)
)ProductLike 테이블
CREATE TABLE `product_like` (
`id` bigint NOT NULL AUTO_INCREMENT,
`product_id` bigint DEFAULT NULL,
`user_id` bigint DEFAULT NULL,
PRIMARY KEY (`id`)
)ProductLikeReadService
public int getProductLikeCount(final Long productId){
return productLikeRepository.countAllByProductId(productId);
}ProudctLikeWriteService
public void createOrDeleteProductLike(final User user, final Long productId){
Optional<ProductLike> findProductLike = productLikeRepository
.findByUserIdAndProductId(user.getId(), productId);
if (findProductLike.isEmpty()) {
ProductLike productLike = ProductLike.builder()
.userId(user.getId())
.productId(productId)
.build();
productLikeRepository.save(productLike);
} else {
productLikeRepository.delete(findProductLike.get());
}
} 사용자가 좋아요를 요청하면 PRODUCT_LIKE 테이블에 사용자의 id 와 상품의 id 를 저장하고 상품별로 데이터의 개수를 세는 방법입니다.
이러한 방법의 장점은 PRODUCT_LIKE 테이블을 따로 분리했기 때문에 PRODUCT 테이블을 대상으로 하는 다른 서비스들의 경합이 줄어들고 사용자마다 유니크한 값을 체크해 중복을 방지할 수 있다는 것입니다.
쓰기 성능은 좋아지지만 반대로 읽기 성능은 좋아요 개수를 세기 위해 상품 1개마다 count 쿼리가 계속 나가 이전 select 문 한 줄로 해결됐던 것에 비해 많이 안좋아집니다.
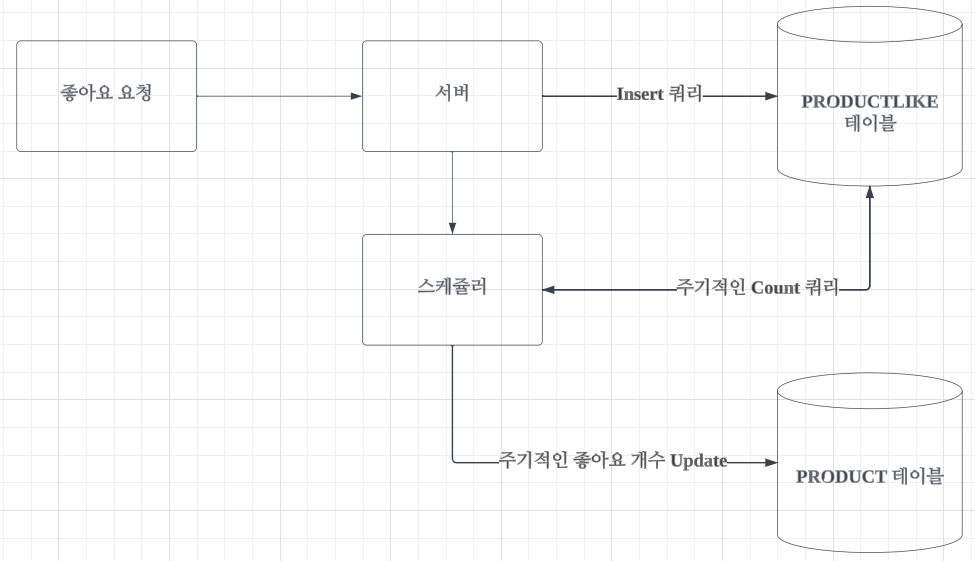
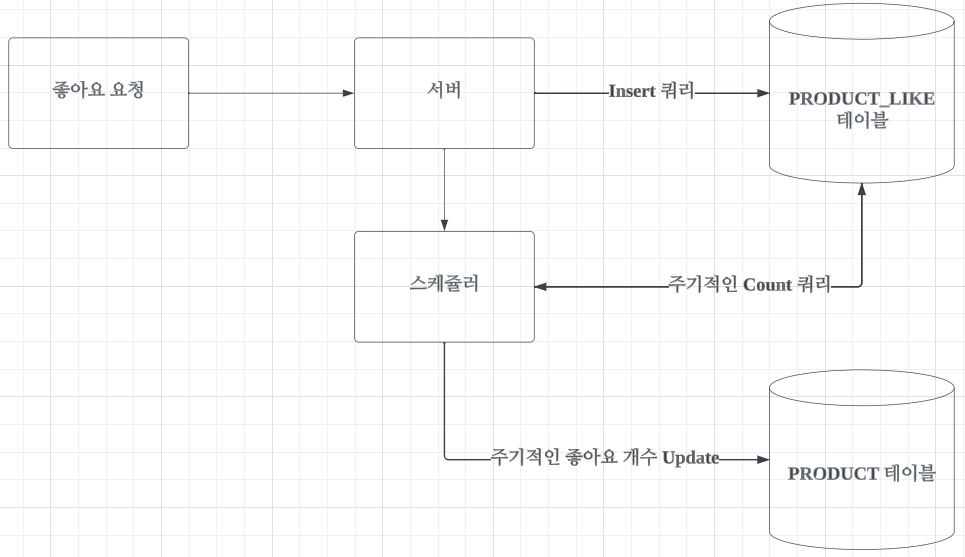
스케쥴러
PRODUCT_LIKE 테이블을 따로 분리하는 것은 PRODUCT 테이블의 서비스를 제공하는데 필요했음에는 변함이 없습니다. 하지만 이로 인해 조회 성능이 저하된 것 또한 맞습니다. 제 서비스에서 좋아요 개수라는 데이터가 사용자에게 실시간으로 오차없이 제공되어야 하는 데이터인가? 하는 고민을 했고 저는 아니라고 판단했습니다. 그래서 아래와 같은 방법을 생각했습니다.
ProductSchedulerService
@Scheduled(cron = "0 0 23 * * *", zone = "Asia/Seoul")
public void productLikeScheduler() {
List<Product> products = productRepository.findAll();
for (Product product: products) {
product.setLikeCount(productLikeReadService.getProductLikeCount(product.getId()));
}
} 1번 방법과 2번 방법의 혼합입니다. 좋아요 요청이 들어오면 서버는 PRODUCT_LIKE 테이블에 데이터를 삽입하고 스케쥴러 함수 혹은 모듈을 통해 특정 주기로 좋아요 수를 PRODUCT 테이블의 like_count 필드로 update 하는 것입니다. 사용자가 좋아요를 눌렀을 때는 클라이언트에서 현재 좋아요에 +1을 해서 증가한 것처럼 보여주고 서버는 스케쥴러를 통해 좋아요 수를 관리하는 방법입니다. 이렇게 되면 상품에 대해 조회가 몇 번이 일어나든 PRODUCT 테이블로 select 쿼리만이 발생합니다. 스케쥴러라는 관리 포인트가 늘어나긴 하지만 성능면에서 읽기와 쓰기의 밸런스를 적절히 조율했다고 생각됩니다.
후기
프로젝트를 진행할 때는 기능 구현에 급급해 보이지 않았지만 완성하고 보니 많은 생각이 들었습니다. 트래픽이 발생한다면 이런 간단한 쿼리라도 몇 백, 몇 천 실무라면 몇 만개도 발생할텐데 '쿼리를 어떻게 간단하게 만들지?' 부터 시작해 db 입출력을 줄여야겠다고 생각했고 이를 스케쥴러 메소드를 통해 별도의 포인트로 관리하는 방법을 생각했습니다.
다른 방법이 틀렸다는 것은 아닙니다. 다만 서비스 요구사항에 맞춰 변화를 줘야한다고 생각합니다. 현재 제 쇼핑몰 서비스는 좋아요 개수를 표시하지 않기 때문에 2번의 방법을 사용 중이지만 진행 중인 프로젝트에서는 좋아요 개수를 집계해야 해서 마지막 방법을 사용하고 있습니다.
