pandas를 엑셀처럼 사용할 때 처음 막막했던 것이 함수를 적용하는 것 이었다.
엑셀은 일부 데이터가 아닌 모든 데이터를 보면서,
각 셀에서 '='로 시작하며 직접 방향키로 셀을 지정하고,
여러 컬럼을 동시에 함수에서 활용하는 것이 직관적으로 가능한,
나름 훌륭한 UI/UX를 지녔다는 느낌이 들었다.
물론 약 100여 만 개의 row를 지원 해 주지만
현실적으로 1만 개 정도의 row만 되어도 파일 자체가 무거워지며 불편해지는 현상 한 개만으로도 pandas가 더 좋게 느껴지지만..
그래서 엑셀처럼 자유롭게 다루기 위한 첫 번째 개인 기록은 함수를 적용하는 방법 이다.
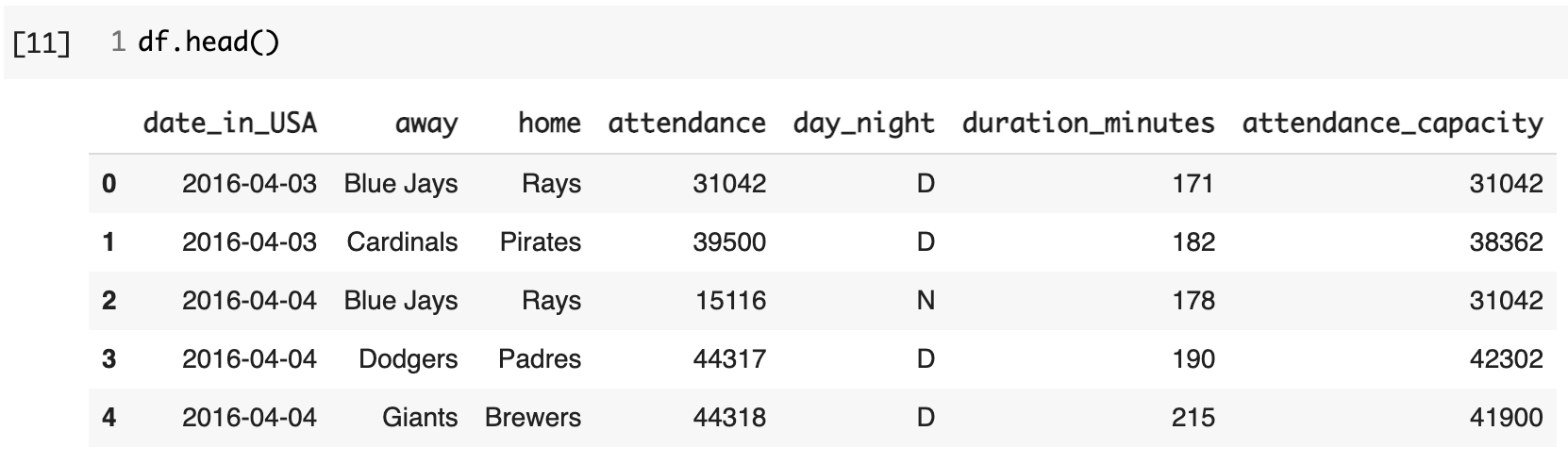
먼저, 함수를 적용할 데이터 예시를 불러오자.
이번에도 역시 google bigquery public data의 baseball data를 활용
날짜 / 홈팀 / 원정팀 / 수용 가능한 관중 수 / 관중 수 / 밤 or 낮 경기 여부 / 경기 시간위의 데이터를 가져오는 쿼리
select
date( startTime ) date_in_USA,
awayTeamName away,
homeTeamName home,
venueCapacity attendance_capacity,
attendance,
dayNight day_night,
durationMinutes duration_minutes,
from
`bigquery-public-data.baseball.games_wide`
where 1=1
group by 1,2,3,4,5,6,7
order by 1,2,3
쿼리 결과를 python DataFrame으로 가져오기
각 date 마다의 좌석 점유율 구해보기
함수 없이 원하는 값 구해보기
좌석 점유율을 occupancy 컬럼명으로 계산하여 정의
df[ 'occupancy' ] = df[ 'attendance' ] / df[ 'attendance_capacity' ]
df.head()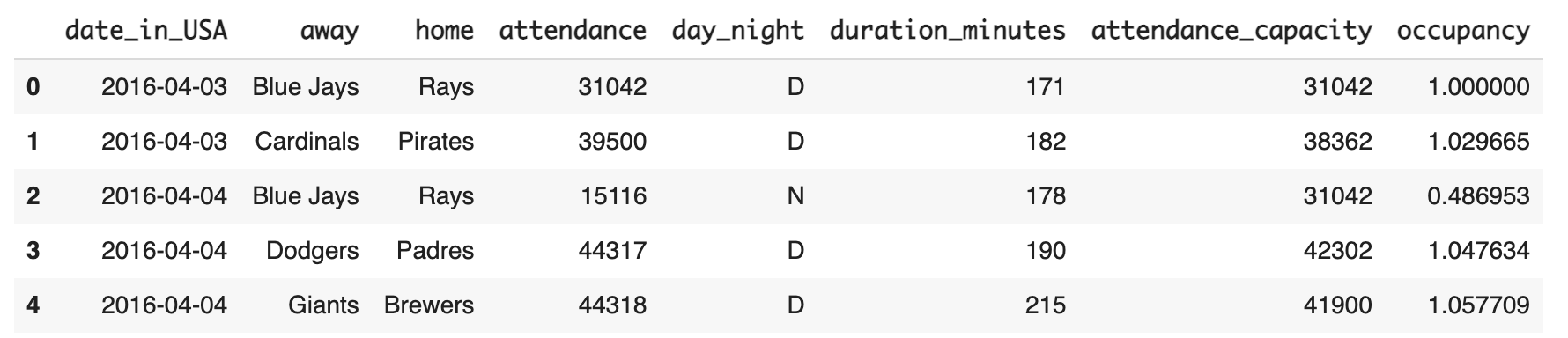
( 좌석점유율이 1이 넘은 날은 어떤 날이었을까 )
np.vectorize를 활용하기
먼저, 함수를 정의해야 한다.
def calculated_occupancy( attendance, capacity ):
occupancy = attendance / capacity
return occupancy그리고 정의된 함수를 활용한다.
df[ 'occupancy_by_apply' ] = np.vectorize( calculated_occupancy )( df[ 'attendance' ], df[ 'attendance_capacity' ] )
df[ '생성할 컬럼 명' ] = np.vectorize( 적용할 함수 이름 )( 함수 파라미터 1, 파라미터 2 )결과

결과값이 같음을 확인할 수 있다.
그리고 np.vectorize는 계산이 아닌, 여러 조건을 걸어서 새로운 컬럼을 설정할 수 있는데,
예를 들면 밤 경기이면서 좌석 점유율이 80%이상인 경우를 구분하기 위한 별도의 구분자 컬럼을 생성할 경우가 있다.
역시 함수를 정의하고
def night_over_80( day_night, occupancy ):
if day_night == 'N' and occupancy >= 0.8:
return 1
else:
return 0해당 함수를 적용한다.
df[ 'night_over_80' ] = np.vectorize( night_over_80 )( df[ 'day_night' ], df[ 'occupancy' ] )
df.sample(5)결과

숫자 계산만으로는 2개 이상의 변수를 함수 정의 없이 새로운 컬럼을 생성할 수 있으나,
계산이 아닌 특정 조건에 따른 결과값으로 새 컬럼을 생성한다면 np.vectorize를 활용하면 된다.
경기 시간을 segment로 묶어보기
apply
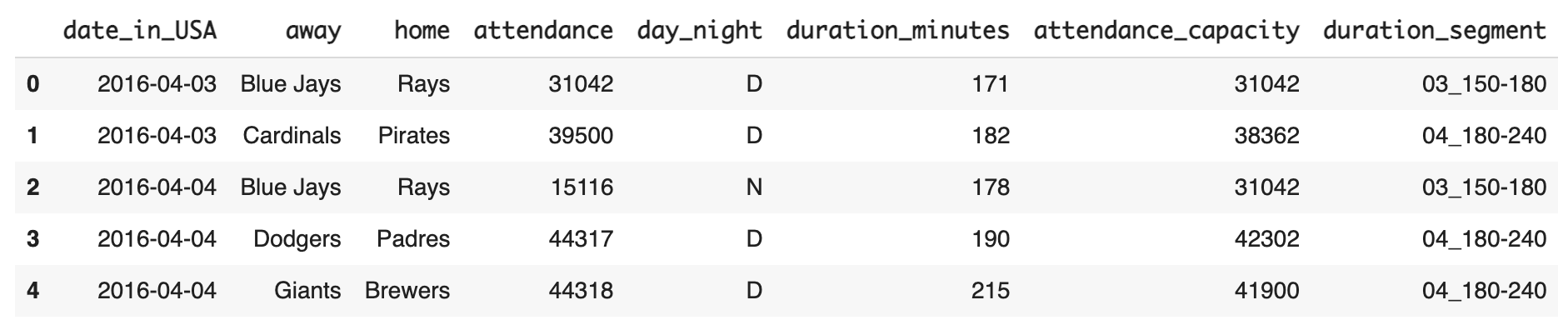
분 단위 정보로 가지고 있는 경기 시간 세그먼트를 나누는 경우
apply를 활용하기 위해서는 함수를 먼저 정의해야 한다.
def segment_duration( minutes ):
if minutes < 120:
return '01_under_120'
elif minutes < 150:
return '02_120-150'
elif minutes < 180:
return '03_150-180'
elif minutes < 240:
return '04_180-240'
else:
return '05_over_240'정의한 함수 적용
df[ 'duration_segment' ] = df[ 'duration_minutes' ].apply( segment_duration )
df[ '생성할 컬럼 명' ] = df[ '함수 파라미터로 활용될 컬럼 명' ].apply( 적용할 함수 이름 )결과
lambda
위와 동일한 결과를 별도의 함수 정의 없이 lambda 함수를 활용하여 구할 수 있다.
df[ 'duration_segment_by_lambda' ] = df[ 'duration_minutes' ].apply( lambda x: '01_under_120' if x < 120 else ( '02_120-150' if x < 150 else ( '03_150-180' if x < 180 else ( '04_180-240' if x < 240 else ( '05_over_240' )))))위의 lambda 함수를 보기 편하게 적어보면
df[ 'duration_segment_by_lambda' ] = df[ 'duration_minutes' ].apply( lambda x:
'01_under_120' if x < 120
else ( '02_120-150' if x < 150
else ( '03_150-180' if x < 180
else ( '04_180-240' if x < 240
else ( '05_over_240' )))))df[ '생성할 컬럼 명' ] = df[ 'lambda 함수에 적용할 컬럼 명' ].apply(
lambda x: # df[ 'lambda 함수에 적용할 컬럼 명' ] 각각의 row값들이 x로 적용된다고 생각
'조건 1 True일 경우 반환 값' if '조건 1'
else ( '조건 2 True일 경우 반환 값' if '조건 2'
else ( '조건 3 True일 경우 반환 값' if '조건 3'
......
else ( '앞서 설정한 조건이 모두 아닐 경우 반환할 값' ) ) )
# 괄호()를 열고 닫는 위치와 개수를 신경쓰자결과( apply를 활용한 duratio_segment 컬럼값과 lambda를 활용한 duration_segment_by_lambda의 결과값 일치 확인 )

