결측값은 무엇인가
말 그대로 측정되지 않은 값이다.
어떠한 값도 가지지 않으니 당연히 0도 아니다.
보통 null 혹은 NaN으로 표현된다.
( bigquery에서는 ieee_divide함수를 보면 null과 NaN을 구분하는 것으로 보이는데.. 그건 더 알아봐야 함 )
자연스럽게 발생할 수 있는 결측값도 있다.
예를 들면, 체크카드 결제 데이터에서 결제 시도 로그 데이터 테이블이 있다고 상상했을 때 결제 시도 금액과 실제 결제 금액 컬럼이 있을 것이다.
그리고 잔액이 부족했다면 실제 결제는 되지 않았을터이니 null값으로 잡히도록 셋팅할 수 있다.
어떻게 처리 할 것인가
null값으로 무언가를 분석할 수 없다.
따라서 그 null값을 가진 row는 다 날리고 온전히 관측된 데이터셋만 가지고서 분석을 진행하는 것이 가장 간단할 수 있지만... 다음의 경우에는 그러한 결정을 쉽게 하기 어려울 수 있다.
1. 하나하나 데이터 날리는 것이 아쉬울 경우. 즉 관측된 데이터 셋 규모 자체가 적을 경우
2. seasonality를 가진 데이터의 경우, 어느 특정 계절성을 지닌 시기의 데이터가 날라간다면 분석 결과에도 영향이 있을 것이다. 이는 데이터셋 규모가 더 적을수록 영향이 클 것이다.
아쉬운대로 null을 대신할 값을 찾아 넣자.
방법 1. 특정 값으로 넣기
방법 2. 평균( 대표 ) 값으로 넣기
방법 3. 직전/직후 값으로 넣기
방법 4. 보간 값으로 넣기
먼저 데이터셋을 찾아보니, bigquery-public-data셋에 날씨 테이블이 있었다.
select
date,
sum(case when postal_code = '10054' then avg_temperature_air_2m_f end) avg_10054,
sum(case when postal_code = '10056' then avg_temperature_air_2m_f end) avg_10056,
sum(case when postal_code = '12014' then avg_temperature_air_2m_f end) avg_12014,
sum(case when postal_code = '22014' then avg_temperature_air_2m_f end) avg_22014,
sum(case when postal_code = '23025' then avg_temperature_air_2m_f end) avg_23025,
sum(case when postal_code = '24123' then avg_temperature_air_2m_f end) avg_24123,
from
`bigquery-public-data.covid19_weathersource_com.postal_code_day_history`
where 1=1
and country = 'IT' # 국가 코드 IT는 이탈리아라 함. 출처: [국가코드조회](https://eminwon.qia.go.kr/common/CountrySP.jsp)
and date between date( '2021-04-13' ) and date( '2021-04-17' ) # null값 주변의 날짜들도 같이 가져오기 위해
and postal_code in ( '10054', '10056', '12014', '22014', '23025', '24123' ) # 예시를 위해 지정한 임의의 우편번호
group by date
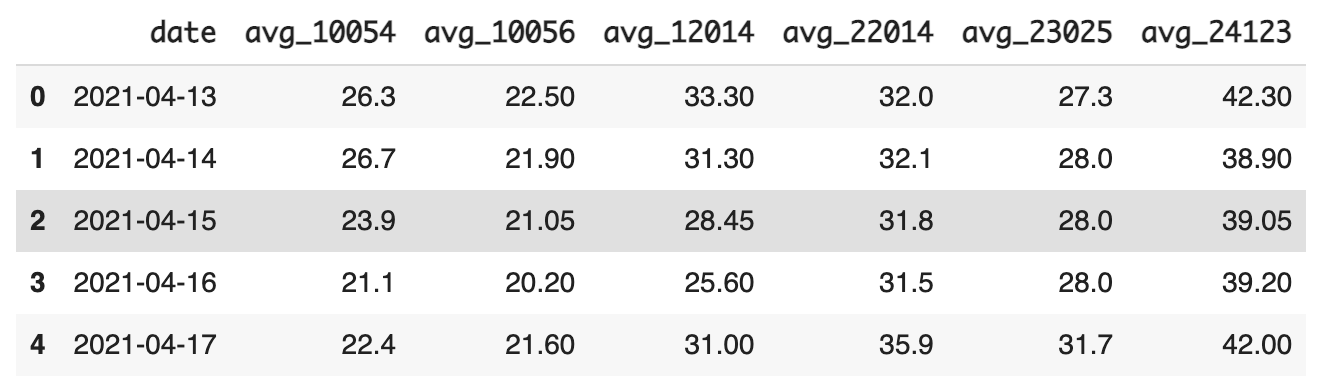
order by date- 위 쿼리 조회 결과

4월 15일 해당하는 평균기온값이 null값임을 확인할 수 있다.
방법 1. 특정 값으로 넣기
df_specific_value.fillna(0) # 0으로 채워넣기- 0으로 채운 결과
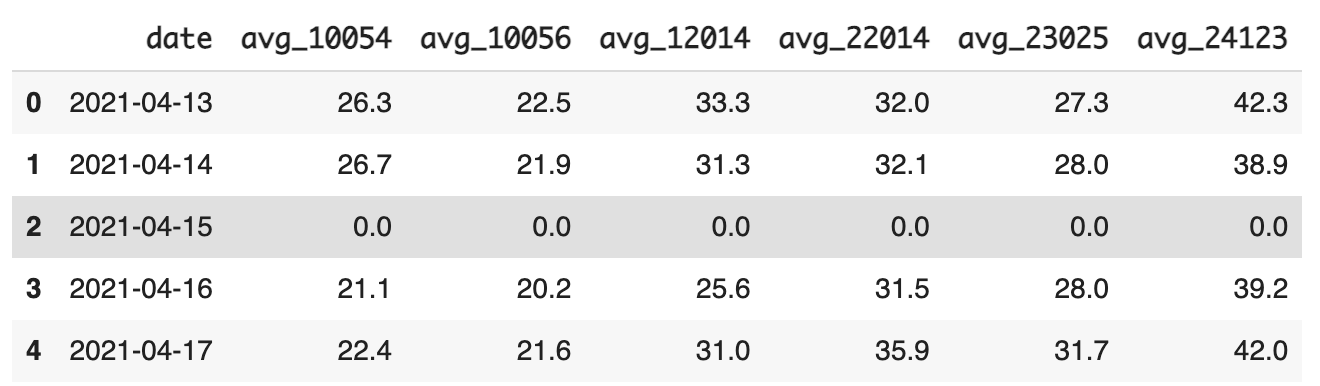
채워지긴 했는데 유용하지는 않을 것 같다. 0으로 채우면 좋은 경우가 있을지는 생각을 더 해봐야 할 듯.
방법 2. 평균( 대표 )값으로 넣기
꼭 평균값이 아니라 mode(최빈치) 혹은 median(중위수)등 적절한 대표값이 있다면 사용할 수 있는 방법.
# 각 지역(우편번호)마다의 평균값을 준비 하기
mean_10054 = df[ 'avg_10054' ].mean()
mean_10056 = df[ 'avg_10056' ].mean()
mean_12014 = df[ 'avg_12014' ].mean()
mean_22014 = df[ 'avg_22014' ].mean()
mean_23025 = df[ 'avg_23025' ].mean()
mean_24123 = df[ 'avg_24123' ].mean()# 준비한 평균값을으로 결측치를 대신하기
df_mean['avg_10054'].fillna(mean_10054, inplace = True)
df_mean['avg_10056'].fillna(mean_10056, inplace = True)
df_mean['avg_12014'].fillna(mean_12014, inplace = True)
df_mean['avg_22014'].fillna(mean_22014, inplace = True)
df_mean['avg_23025'].fillna(mean_23025, inplace = True)
df_mean['avg_24123'].fillna(mean_24123, inplace = True)
df_mean- 평균(대표)값으로 채운 결과
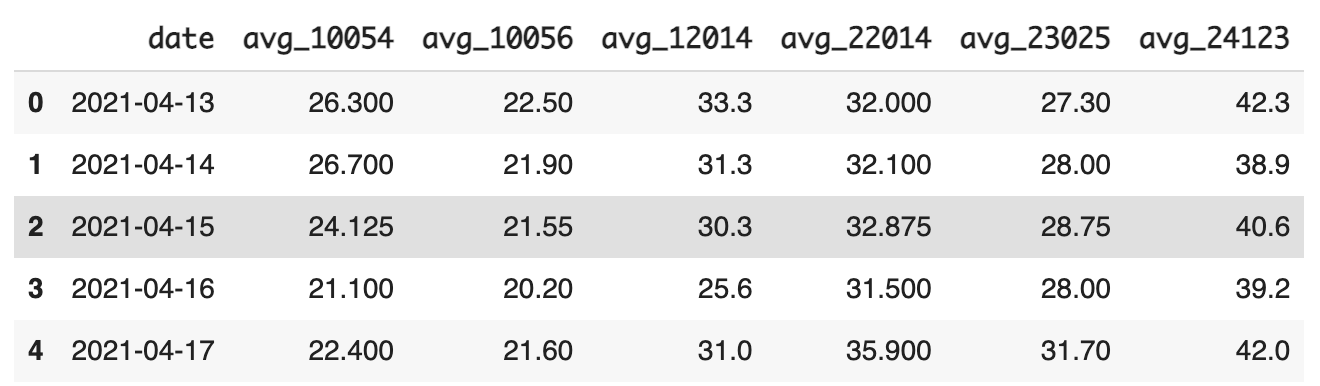
0으로 채운 것 보다는 훨씬 더 자연스러워 보인다.
다만 이 경우에는 앞 뒤 날짜 2일씩만 가져왔지만 혹 1년의 기간이라면? 위 데이터는 이탈리아 기온인데, 이탈리아는 우리나라처럼 4계절이 잘 나타난다고 함.
그러면 대표값으로 결측치를 넣는다는 것이 데이터를 왜곡시키는 경우가 충분히 발생할 수 있음.
( 예를 들면 한 여름의 기온 데이터가 결측일 때 연 중 평균 기온이 기입되면 안될 듯 )
방법 3. 직전 혹은 직후 값으로 넣기
seasonality 특징이 있다면 고려할 수 있는 방법이다.
다만 null이 가장 처음으로 나오거나 가장 끝에 나온다면 사용할 수 없다는 단점이 있다.
# 직전 값으로 넣기
df_forward.fillna(method = 'pad', inplace = True)- 직전 값으로 넣은 결과
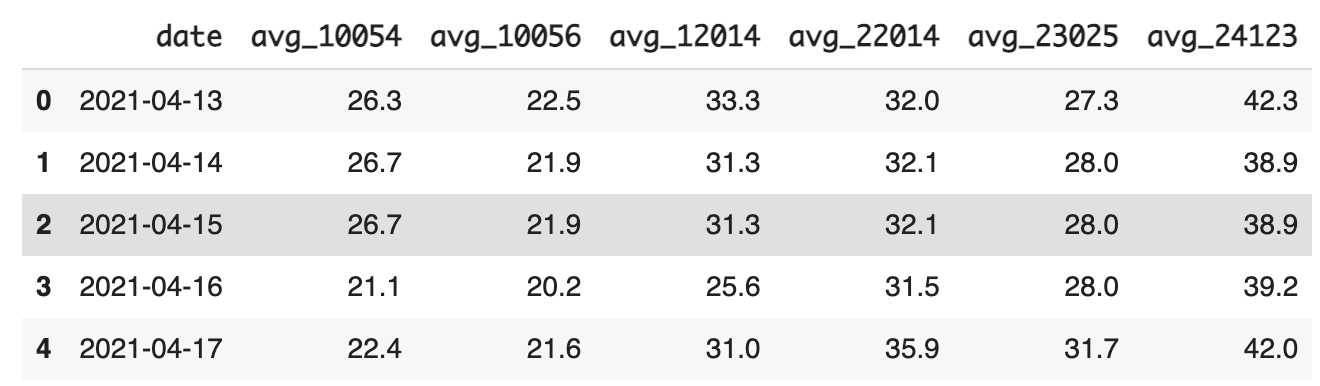
# 직후 값으로 넣기
df_backward.fillna(method = 'bfill', inplace = True)- 직후 값으로 넣은 결과
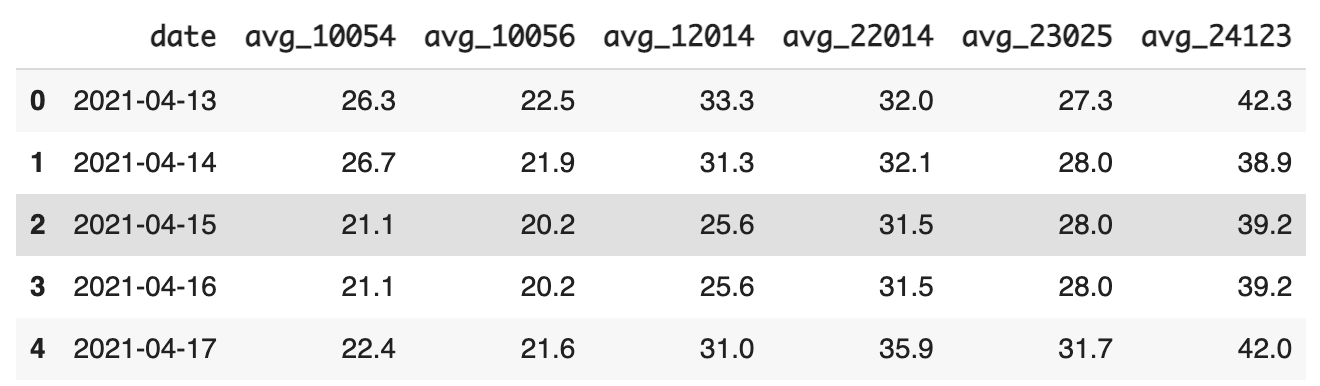
해당 시기의 계절성은 잘 반영되었지만 앞뒤로 매끄러운 느낌은 아니다.
방법 5. 보간 값으로 넣기
선형보간을 이용한 방법으로, null값이 비어있는 위치마다 선형보간법으로 결측치를 대신하는 방법이다.
df_interpolate.interpolate( method = 'linear', inplace = True)- 보간 값으로 넣은 결과
만약 null값이 2개 이상이라도 적용할 수 있다.
예를들어
0
1.25
null
null
2
위의 데이터를 보간값으로 결측치를 대신한다면
0
1.25
1.5
1.75
2
위와 같이 결과가 나온다.
시계열 데이터의 null값을 날리지 않고 대신할 값을 찾는다면,
시기의 흐름을 보여주면서 매끄럽게 null값을 메우는 것이 중요하기에 이를 감안하고 방법을 적용하면 좋을 것 같다.
시계열이 아닌 횡단면은 대표값을 넣어도 괜찮을 것 같다.
( 데이터 분석의 성지인 타이타닉 생존분석에서도 요금지불 null값인 경우 평균 데이터로 결측치를 갈아 끼워넣고 분석한 노트도 본 기억이.. )
