Python에서 data를 handling 하다 보면, SQL에서 할 수 있는 일을 query가 아닌 python 환경( pandas or numpy 등 )에서 처리하면 더 효율적인 경우가 생각보다 자주 발생한다.
그 중, row_number window function을 pandas로 처리할 필요가 있을 때, 구글링 혹은 과거에 작성 해 둔 코드를 찾는 시간 낭비 방지 목적으로 남겨두려고 한다.
SQL
ROW_NUBER() → 결과 table에 partition을 걸어 partition 내에서 일정 조건에 따라 번호를 부여하는 윈도우 함수
e.g., 2016년도 MLB 정규리그 경기. 월 평균 경기 시간 Top 3 경기장 추출
- 환경: Google Bigquery
- data_set: bigquery-public-data( == 빅쿼리 공개 데이터셋 )
예시 코드
WITH
result AS (
SELECT
ROW_NUMBER() OVER(PARTITION BY yyyymm ORDER BY duration, ground_name) game_duration_seq
, yyyymm
, ground_name
, duration
FROM
(
SELECT
FORMAT_DATE('%Y-%m', startTime) yyyymm
, venueName ground_name
, SAFE_CAST(TRUNC(AVG(durationMinutes)) AS BIGINT) duration
FROM
(SELECT
gameId
, startTime
, venueName
, durationMinutes
FROM
`bigquery-public-data.baseball.games_wide`
GROUP BY 1,2,3,4)
GROUP BY 1,2
)
)
SELECT
*
FROM
result
WHERE game_duration_seq <= 3
ORDER BY yyyymm, duration, ground_name결과물
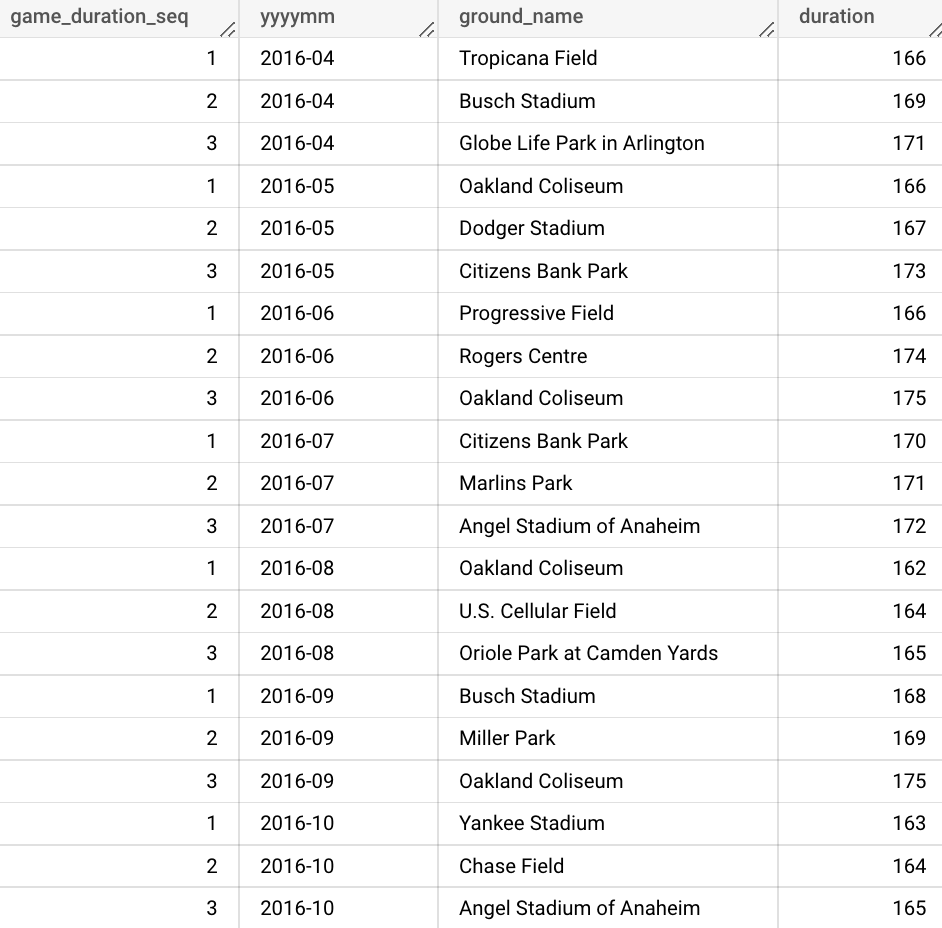
pandas
- 환경: Google Colab
- data_set: 위와 동일한 데이터( csv 파일 다운받아 colab에 업로드 )
예시 코드
## row data에서 적당한 column들을 선택하여 전처리
### → with 절 내의 FROM subquery 수준
temp_df = df_mlb_raws.groupby(['yyyymm', 'venueName'])['duration'].agg('mean').reset_index()
temp_df['duration'] = temp_df['duration'].astype(int)
## ROW_NUMBER() window 함수 컬럼 생성( `game_duration_seq` )
temp_df['game_duration_seq'] = temp_df.sort_values(by = ['yyyymm', 'duration'], ascending = True).groupby(['yyyymm']).cumcount()+1
temp_df = temp_df[temp_df.game_duration_seq <= 3]
temp_df = temp_df[['game_duration_seq', 'yyyymm', 'venueName', 'duration']]
temp_df.sort_values(by = ['yyyymm', 'game_duration_seq'], ascending = True)결과물
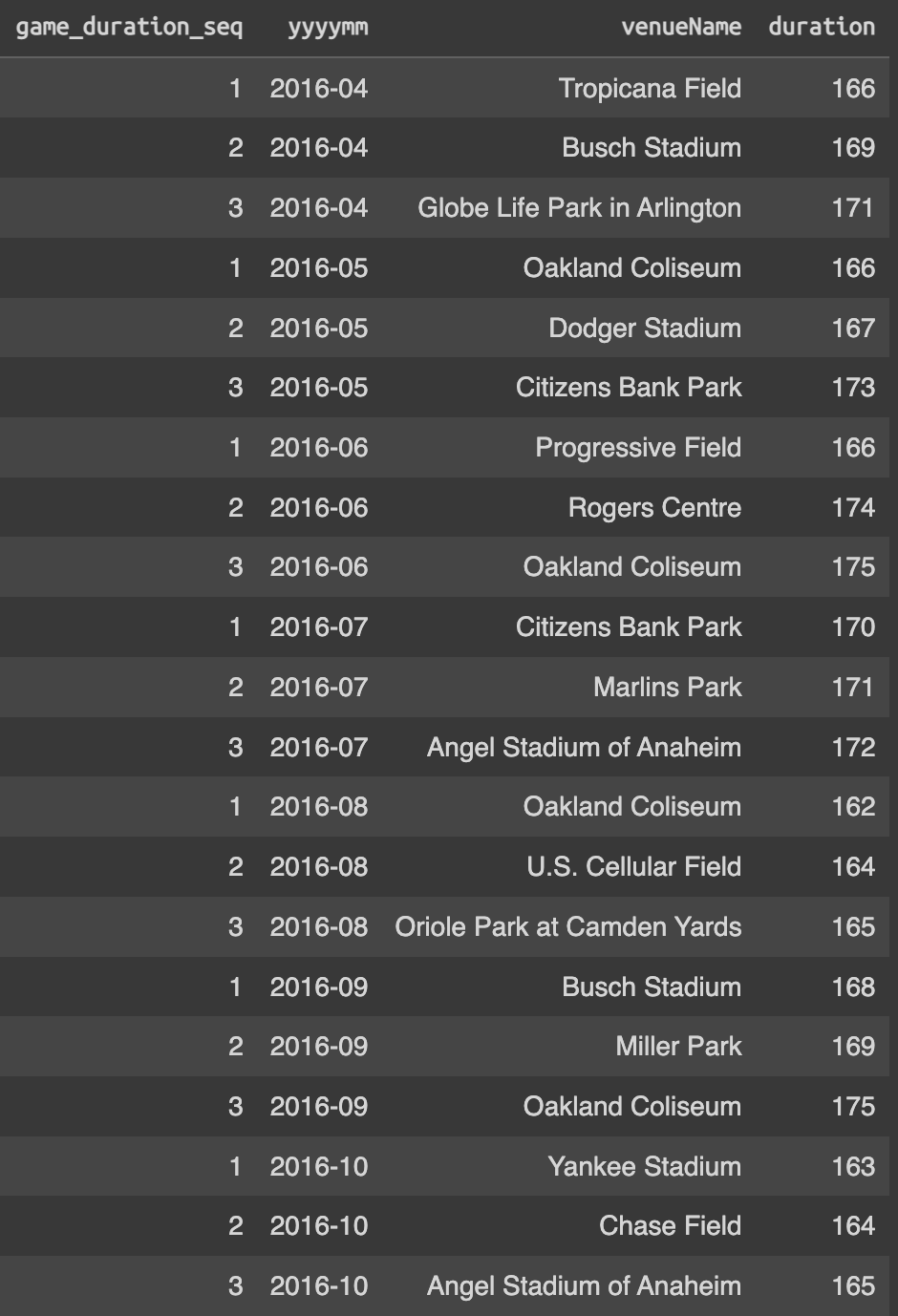

분석가