위키북스의 파이썬 머신러닝 완벽 가이드 책을 토대로 공부한 내용입니다.
1. Introduction
사이킷런을 통해 첫 번째로 만들어볼 머신러닝 모델은 붓꽃 데이터를 활용해 품종을 분류하는 classification model이다.
2. Classification model
분류(classification)는 대표적인 지도 학습 (superviesed learning) 방법 중 하나이다. 지도 학습은 정답이 주어진 학습 데이터를 먼저 학습한 뒤 학습되지 않은 데이터로 부터 정답을 예측하는 방식이다.
3. sklearn
우선 사이킷런을 사용하기 위해서는 sklearn 패키지에서 사용할 모듈을 import 해야 한다.
sklearn.dataset
: 사이킷런에서 자체적으로 제공하는 데이터 세트를 생성하는 모듈sklearn.tree
: 트리 기반 ML 알고리즘을 구현한 클래스의 모임sklearn.model_selection
: 학습 데이터롸 검증 데이터, 예측 데이터로 데이터를 분리하거나 최적의 하이퍼 파라미터로 평가하기 위한 다양한 모듈의 모임하이퍼 파라미터 (hyper parameter)
: 머신러닝 알고리즘별로 최적의 학습을 위해 직접 입력하는 파라미터들을 통칭한다.붓꽃 dataset을 생성하기 위해 load_iris()를 사용하며, ML 알고리즘으로는 의사 결정 트리(Decision Tree) 알고리즘으로 DecisionTreeClassifier를 사용한다. 그리고 학습 데이터와 테스트 데이터로 분리하기 위해 train_test_split() 함수를 사용한다.
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split
4. iris dataset
load_iris() 함수를 사용해 붓꽃 dataset을 불러온 뒤, 데이터가 어떻게 구성되어 있는지 확인하기 위해 DataFrame으로 변환한다.
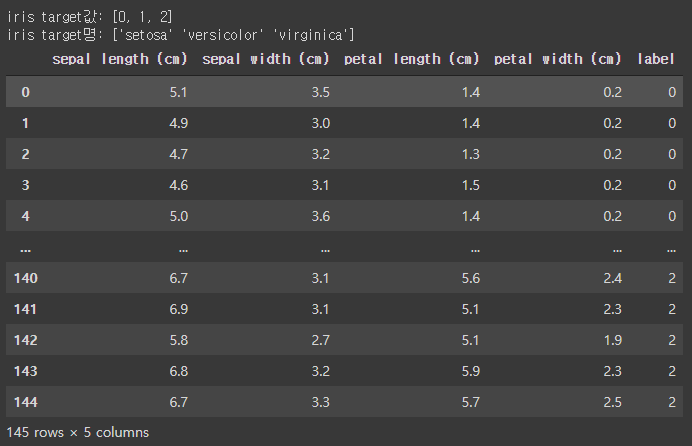
import pandas as pd # 붓꽃 데이터 세트를 로딩합니다. iris = load_iris() # iris.data는 Iris 데이터 세트에서 피처(feature)만으로 된 데이터를 numpy로 가지고 있습니다. iris_data = iris.data # iris.target은 붓꽃 데이터 세트에서 레이블(결정 값) 데이터를 numpy로 가지고 있습니다. iris_label = iris.target print('iris target값:', list(set(iris_label))) print('iris target명:', iris.target_names) # 붓꽃 데이터 세트를 자세히 보기 위해 DataFrame으로 변환합니다. iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names) iris_df['label'] = iris.target iris_df.head(-5)[output]
붓꽃의 특징들은 sepal length, sepal width, petal length, petal width로 4종류가 있고, label은 setosa, versicolor, virginica로 3종류가 있다.
5. train/test dataset
우선 학습용 데이터와 테스트용 데이터로 분리해야한다. 학습 데이터로 모들을 학습한 후, 얼마나 좋은 성능을 보이는지 알기 위해서는 테스트용 데이터가 필요하기 때문이다. 사이킷런은 train_test_split() 함수를 제공하여 학습 데이터와 테스트 데이터를 test_size로 입력된 비율로 분할시켜준다.
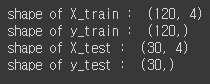
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=11)[output]
test_size가 0.2로 입력되면 전체 데이터 중 20%의 데이터가 테스트 데이터, 80%의 데이터가 학습데이터로 분할된다. 그리고 random_state는 함수를 호출할 때마다 똑같이 data를 분할하시 위한 random seed 값이다. random seed 값이 설정되어 있지 않으면 data를 항상 random하게 불러오기 때문에 매번 다른 결과가 나오게 될 수 있다. 위 코드에서는 학습용 input data를 X_train, 학습용 label data를 y_train, 테스트용 input data를 X_test, 테스트용 label data를 y_test로 반환하였다.
6. DecisionTreeClassifier
머신러닝 분류 알고리즘의 하나인 의사 결정 트리를 이용해 학습과 예측을 하려한다. 사아킷런에서 제공하는 DecisionTreeClassifier 객체를 불러온 뒤 fit() method에 학습용 데이터를 넣어주고 학습을 수행한다. 이때도 항상 같은 학습 결과를 가져오기 위해 random_state를 입력해준다. 학습을 완료하게 되면 예측을 수행하는데 이때는 predict() method에 테스트용 input 데이터를 사용하고, 모델이 예측한 결과를 반환한다. 마지막으로 모델이 예측한 결과를 토대로 성능을 확인해야 하는데, 성능 평가 방법에는 여러 가지가 있다. 그 중 사이팃런의 sklearn.metrics에서 제공하는 accuracy_score 함수로 정확도를 측정해보려고 한다.
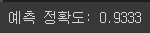
# DecisionTreeClassifier 객체 생성 dt_clf = DecisionTreeClassifier(random_state=11) # 학습 수행 dt_clf.fit(X_train, y_train) # 학습이 완료된 DecisionTreeClassifier 객체에서 테스트 데이터 세트로 예측 수행. pred = dt_clf.predict(X_test) # 정확도 측정 from sklearn.metrics import accuracy_score print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))[output]
사이킷런을 이용하여 학습한 의사 결정 트리의 알고리즘은 붓꽃 데이터에 대하여 약 93.33%의 정확도를 보였다.
7. summary
- dataset 분리 : data를 학습 데이터롸 테스트 데이터로 분리합니다.
- model 학습 : 학습 데이터를 기반으로 ML 알고리즘을 적용해 모델을 학습시킵니다.
- 예측 수행 : 학습된 ML 모델을 이용해 테스트 데이터의 분류(즉, 분꽃 종류)를 예측합니다.
- 평가 : 이렇게 예측된 결과값과 테스트 데이터의 실제 결과값을 비교해 ML 모델 성능을 평가합니다.
