위키북스의 파이썬 머신러닝 완벽 가이드 책을 토대로 공부한 내용입니다.
1. 학습/테스트 데이터 세트 분리 - train_test_split()
trian_test_split()은 첫번째 parameter로 feature dataset, 두번째 parameter로 label dataset을 입력받는다.
- 나머지 추가 parameter
- test_size : 전체 dataset에서 테스트 dataset의 크기를 얼마로 샘플링할 것인가를 결정한다. default는 0.25로 25%이다.
- train_size : 전체 dataset에서 학습용 dataset의 크기를 얼마도 샘플링할 것인가를 결절한다. test_size_parameter를 통상적으로 사용하기 때문에 train_size는 잘 사용되지 않는다.
- shuffle : dataset을 분리하기 전에 dataset을 미리 섞을지를 결정한다. default는 True이며, dataset을 분산시켜서 좀 더 효율적인 학습 및 테스트 dataset을 만드는 데 사용된다.
- random_state : 함수를 호출할 때마다 동일한 학습/테스트 dataset을 생성하기 위해 주어지는 난수 seed 값이다.
- train_test_split()의 반환값은 tuple 형태이다. 순차적으로 학습용 feature dataset, 테스트용 feature dataset, 학습용 label dataset, 테스트용 label dataset을 반환한다.
2. 교차 검증
학습용 dataset과 테스트용 dataset을 나누어 사용하는 방법이 필요하지만, 이 방법은 과적합(Overfitting)에 취약하다. 과적합은 모델이 학습 데이터에만 과도하게 최적화 되어, 실제 다른 데이터로 예측을 수행하는 경우에는 성능이 과도하게 떨어지는 것을 말한다. 고정된 학습용 dataset과 고정된 테스트용 dataset으로만 평가를 하다보면 테스트 dataset에만 최적의 성능을 발휘하도록 편향되게 모델을 유도하는 경향이 생긴다. 이것 또한 과적합으로 새로운 테스트 데이터에는 성능이 저하된다.
ML은 데이터에 기반한다. 그리고 데이터는 이상치, 분포도, 다양한 속성값, feature 중요도 등 여러 가지 ML에 영향을 미치는 요소를 가지고 있다. 특정 ML 알고리즘에서 최적으로 동작할 수 있도록 데이터를 선별하여 학습한다면 실제 데이터 양식과는 많은 차이가 있을 것이고, 성능이 저하될 것이다. 따라서 이러한 문제를 해결하기 위해 교차 검증을 이용한다.
교차 검증은 쉽게 말해 본 시험을 치르지 건에 모의고사를 여러 번 보는 것이라고 생각하면 되는데, 데이터의 편중을 막기 위해 여러 set로 나누어진 학습 dataset과 검증 dataset에서 학습과 평가를 수행한다. 각 set에서 수행한 평가 결과에 따라 hyper parameter 튜닝등 모델 최적화를 더욱 쉽게 할 수 있다.
대부분의 ML 모델의 성능 평가는 교차 검증 기반으로 1차 평가를 한 뒤에 최종적으로 테스트 dataset으로 평가하는 프로세스이다. ML의 dataset을 세분화하여 학습용, 검증용, 테스트용 dataset으로 나눌 수 있다.
3. K-fold 교차 검증
K-fold 교차 검증은 가장 보편적인 교차 검증 기법이다. 먼저 K개의 data fold set를 만들어 K번만큼 각 fold set에 학습과 검증 평가를 반복적으로 수행하는 방법이다.
먼저, dataset을 K등분하고, 그 중 K-1개의 dataset을 학습 dataset으로, 나머지 1개의 dataset을 검증 dataset으로 하여 학습과 평가를 수행하며 학습과 검증 dataset이 중복이 되지 않도록하여 이 과정을 K번 반복한다. 즉, K개의 dataset이 한번씩 검증 dataset으로 사용되게 된다. 그리고 K번의 반복이 끝나면 K개의 평가를 평균한 결과로 예측 성능을 평가한다.
사이킷런에서는 K-fold 교차 검증 프로세스를 구현하기 위해 KFold와 StratifiedKFold 클래스를 제공한다.
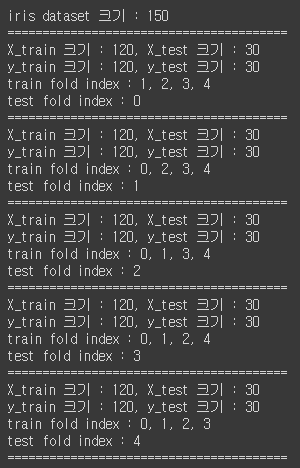
from sklearn.datasets import load_iris from sklearn.model_selection import KFold iris = load_iris() features = iris.data label = iris.target print(f"iris dataset 크기 : {features.shape[0]}") print('='*40) # 5개의 폴드 세트로 분리하는 KFold 객체와 폴드 세트별 정확도를 담을 리스트 객체 생성. kfold = KFold(n_splits=5) for train_index, test_index in kfold.split(features): # kfold.split( )으로 반환된 인덱스를 이용하여 학습용, 검증용 테스트 데이터 추출 X_train, X_test = features[train_index], features[test_index] y_train, y_test = label[train_index], label[test_index] print(f"X_train 크기 : {X_train.shape[0]}, X_test 크기 : {X_test.shape[0]}") print(f"y_train 크기 : {y_train.shape[0]}, y_test 크기 : {y_test.shape[0]}") print(f'train fold index : {train_index[0]//30}, {train_index[30]//30}, {train_index[60]//30}, {train_index[90]//30}') print(f'test fold index : {test_index[0]//30}') print('='*40)[output]
4. Stratified K-fold
Stratified K-fold는 불균형한(imbalanced) 분포도를 가진 label(결정 클래스) dataset을 위한 K-fold 방식이다. 불균형한 분포도를 가진 label dataset은 특정 label 값이 특이하게 많거나 매우 적어서 값의 분포가 한쪽으로 치우치는 것을 말한다. 따라서 Stratified K-fold는 K-fold가 label dataset이 원본 dataset의 label 분포를 학습/테스트 dataset에 제대로 분배하지 못하는 경우의 문제를 해결해 주는데, 원본 dataset의 label 분포를 먼저 고려한 뒤 이 분포와 동일하게 학습/검증 dataset을 분배하는 방식을 사용한다. 사이킷런의 StratifiedFKold 클래스를 이용한다.
import pandas as pd iris = load_iris() iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names) iris_df['label']=iris.target print('레이블 데이터 분포:\n', iris_df['label'].value_counts()) print('='*40) kfold = KFold(n_splits=3) # kfold.split(X)는 폴드 세트를 3번 반복할 때마다 달라지는 학습/테스트 용 데이터 로우 인덱스 번호 반환. n_iter =0 for train_index, test_index in kfold.split(iris_df): n_iter += 1 label_train= iris_df['label'].iloc[train_index] label_test= iris_df['label'].iloc[test_index] print('## 교차 검증: {0}'.format(n_iter)) print('학습 레이블 데이터 분포:\n', label_train.value_counts()) print('검증 레이블 데이터 분포:\n', label_test.value_counts()) print('='*40)[output]
분꽃 dataset은 label 0인 data가 50개, label 1인 data가 50개, label 2인 data가 50개로 총 3개의 label과 150개의 data를 가지고 있다. 이 dataset으로 K-fold 교차 검증을 하면 위의 결과와 같이 다른 2개의 label dataset을 학습할 때, 나머지 1개의 label dataset이 검증 dataset으로 사용되어 예측이 가능하지 않은 학습이 될 수밖에 없다.
from sklearn.model_selection import StratifiedKFold skf = StratifiedKFold(n_splits=3) n_iter=0 for train_index, test_index in skf.split(iris_df, iris_df['label']): n_iter += 1 label_train= iris_df['label'].iloc[train_index] label_test= iris_df['label'].iloc[test_index] print('## 교차 검증: {0}'.format(n_iter)) print('학습 레이블 데이터 분포:\n', label_train.value_counts()) print('검증 레이블 데이터 분포:\n', label_test.value_counts()) print('='*40)[output]
StratifiedFKold는 KFold로 분할된 label dataset이 전체 label 값의 분포도를 반영하지 못하는 문제를 해결해 준다. StratifiedFKold를 사용하는 방법은 KFold와 비슷한데, 한가지 큰 차이점은 label dataset의 분포에 따라 학습/검증 데이터를 나누기 때문에 split() method에 인자로 feature dataset 뿐만 아니라 label dataset도 반드시 필요하다. 그리고 출력 결과를 보면 학습 label과 검증 label의 분포가 동일하게 할당된 것을 알 수 있다.
5. 교차 검증을 보다 간편하게 - cross_val_score()
사이킷런의 교차 검증을 좀 더 편리하게 수행할 수 있도록 해주는 API 중 대표적인 것이 cross_val_score() 이다. K-fold 교차 검증 과정은 먼저 fold set을 나누고, 루프를 반복하여 학습/테스트 데이터의 index를 추출한 뒤, 학습과 예측을 수행하고 성능을 측정한다. cross_val_score()는 이러한 K-fold 교차 검증 과정을 한번에 수행해주는 API이다.
cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=None, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', error_score=np.nan)
- estimator : 사이킷런의 분류 알고리즘 클래스인 Classifier 혹은 회귀 알고리즘 클래스인 Regressor를 의미
- X : feature dataset
- y : label dataset
- scoring : 예측 성능 평가 지표
- cv : 교차 검증 폴드 수
- return 값은 scoring parameter로 지정된 성능 지표 측정값을 배열 형태로 반환한다. Classifier가 입력되면 Stratified K-fold 방식, Regressor가 입력되면 K-fold 방식으로 분할한다.
비슷한 API로 cross_validate()가 있다. cross_val_score는 단 하나의 평가 지표만 가능하지만 cross_validate()는 여러 개의 평가 지표를 반환할 수 있다. 또한 학습 데이터에 대한 성능 평가 지표와 수행 시간도 같이 제공한다.
6. GridSearchCV - 교차 검증과 최적 hyper parameter 튜닝을 한 번에
hyper parameter는 ML 알고리즘을 구성하는 주요 구성 요소이며, 이 값을 조정해 알고리즘의 예측 성능을 개선할 수 있다. 사이킷런은 GridSearchCV API를 이용해 Classifier나 Regressor와 같은 알고리즘에 사용되는 hyper parameter를 순차적으로 입력하면서 편리하게 최적의 parameter를 도출할 수 있는 방안을 제공한다.
### parameter 들을 dictionary 형태로 설정 parameters = {'max_depth':[1,2,3], 'min_samples_split':[2,3]}위와 같이 parameter의 집합을 만들면 총 6가지 경우의 수에 따라 학습을 진행하여 최적의 parameter와 결과를 도출할 수 있다. GridSearchCV는 교차 검증을 기반으로 이 hyper parameter의 최적 값을 찾게 해준다. 즉, dataset을 cross-validation을 위한 학습/테스트 dataset으로 자동으로 분할해준 후, hyper parameter grid에 기술된 모든 parameter를 순차적으로 적용시켜 최적의 parameter를 찾게 해준다. 하지만 편리하게 hyper parameter를 찾을 수 있게 해주지만 수행시간이 상대적으로 오래 걸리는 것에 유념해야 한다.
GridSearchCV(estimator, param_grid, scoring=None, n_jobs=None, iid='deprecated', refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score=np.nan, return_train_score=False)
- estimator : classifier, regressor, pipeline이 사용될 수 있다.
- param_grid : key+list 값을 가지는 dictionary가 주어진다. extimator의 튜닝을 위해 parameter 이름과 사용될 여러 parameter 값을 지정한다.
- scoring : 예측 성능을 측정할 평가 방법을 지정한다. 보통은 사이킷런의 성능 평가 지표를 지정하는 문자열로 지정하나 별도의 성능 평가 지표 함수도 지정할 수 있다.
- cv : 교차 검증을 위해 분할되는 학습/테스트 dataset의 개수이다.
- refit : default가 True이며 True로 생성 시 가장 최적의 hyper parameter를 찾은 뒤 입력된 estimator 객체를 해당 hyper parameter로 재학습 시킨다.
GridSearchCV 객체의 fit()을 수행하면 최고 성능을 나타댄 hyper parameter의 값과 그때의 평가 결과 값이 각각 bestparams, bestscore 속성에 기록된다.
import pandas as pd from sklearn.datasets import load_iris from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import train_test_split # 데이터를 로딩하고 학습데이타와 테스트 데이터 분리 iris_data = load_iris() X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=121) dtree = DecisionTreeClassifier() ### parameter 들을 dictionary 형태로 설정 parameters = {'max_depth':[1,2,3], 'min_samples_split':[2,3]} # param_grid의 하이퍼 파라미터들을 3개의 train, test set fold 로 나누어서 테스트 수행 설정. ### refit=True 가 default 임. True이면 가장 좋은 파라미터 설정으로 재 학습 시킴. grid_dtree = GridSearchCV(dtree, param_grid=parameters, cv=3, refit=True) # 붓꽃 Train 데이터로 param_grid의 하이퍼 파라미터들을 순차적으로 학습/평가 . grid_dtree.fit(X_train, y_train) print('GridSearchCV 최적 파라미터:', grid_dtree.best_params_) print('GridSearchCV 최고 정확도: {0:.4f}'.format(grid_dtree.best_score_)) # GridSearchCV의 refit으로 이미 학습이 된 estimator 반환 estimator = grid_dtree.best_estimator_ # GridSearchCV의 best_estimator_는 이미 최적 하이퍼 파라미터로 학습이 됨 pred = estimator.predict(X_test) print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))[output]

