위키북스의 파이썬 머신러닝 완벽 가이드 책을 토대로 공부한 내용입니다.
1. 랜덤 포레스트의 개요 및 실습
배깅(Bagging)의 대표적인 알고리즘은 랜덤 포래스트이다. 랜덤 포레스트는 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지며, 다양한 영역에서 높은 예측 성능을 보이고 있다. 랜덤 포레스트의 기반 알고리즘은 결정 트리이며, 결정 트리의 장점인 쉽고 직관적인 점을 그대로 가지고 있다. 랜덤 포레스트는 여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링하여 개별적으로 학습을 수행한 후 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 하게 된다.
랜덤 포레스트는 각각의 개별적인 결정 트리가 학습하는 dataset이 전체 dataset에서 일부가 중첩되게 샘플링된 dataset이다. 이렇게 여러 개의 dataset을 중첩되게 분리하는 것을 부트스트래핑(bootstrapping) 분할 방식이라고 한다. bagging이 bootstrap aggregating의 줄임말이다. 원래 부트스트랩은 통계학에서 여러 개의 작은 dataset을 임의로 만들어 개별 평균의 분포도를 측정하는 목적 등을 위한 샘플링 방식을 지칭하는데 랜덤 포레스트의 Subset 데이터는 이러한 부트스트래핑으로 데이터가 임의로 만들어진다. 그리고 Subset의 데이터는 개별 데이터들의 중첩을 허용하고, 데이터 수는 전체 dataset의 수와 동일하게 만들어진다.
사이킷런은 RandomForestClassifier 클래스를 통해 랜덤 포레스트 기반의 분류를 지원한다. 사용자 행동 인식 dataset을 이용하여 예측을 수행해보겠다.
import pandas as pd def get_new_feature_name_df(old_feature_name_df): feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(), columns=['dup_cnt']) feature_dup_df = feature_dup_df.reset_index() new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer') new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1]) if x[1] > 0 else x[0], axis=1) new_feature_name_df = new_feature_name_df.drop(['index'], axis=1) return new_feature_name_df def get_human_dataset( ): # 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당. feature_name_df = pd.read_csv('/content/drive/MyDrive/pymldg-rev/4장/human_activity/features.txt',sep='\s+', header=None,names=['column_index','column_name']) # 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용, 신규 피처명 DataFrame생성. new_feature_name_df = get_new_feature_name_df(feature_name_df) # DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환 feature_name = new_feature_name_df.iloc[:, 1].values.tolist() # 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용 X_train = pd.read_csv('/content/drive/MyDrive/pymldg-rev/4장/human_activity/train/X_train.txt',sep='\s+', names=feature_name ) X_test = pd.read_csv('/content/drive/MyDrive/pymldg-rev/4장/human_activity/test/X_test.txt',sep='\s+', names=feature_name) # 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여 y_train = pd.read_csv('/content/drive/MyDrive/pymldg-rev/4장/human_activity/train/y_train.txt',sep='\s+',header=None,names=['action']) y_test = pd.read_csv('/content/drive/MyDrive/pymldg-rev/4장/human_activity/test/y_test.txt',sep='\s+',header=None,names=['action']) # 로드된 학습/테스트용 DataFrame을 모두 반환 return X_train, X_test, y_train, y_test from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import pandas as pd import warnings warnings.filterwarnings('ignore') # 결정 트리에서 사용한 get_human_dataset( )을 이용해 학습/테스트용 DataFrame 반환 X_train, X_test, y_train, y_test = get_human_dataset() # 랜덤 포레스트 학습 및 별도의 테스트 셋으로 예측 성능 평가 rf_clf = RandomForestClassifier(random_state=0) rf_clf.fit(X_train , y_train) pred = rf_clf.predict(X_test) accuracy = accuracy_score(y_test , pred) print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy))[output]
랜덤 포레스트를 이용한 결과 약 92.53%의 정확도를 보여준다.
2. 랜덤 포레스트 하이퍼 파라미터 및 튜닝
트리 기반의 앙상블 알고리즘의 단점을 굳이 뽑는다면 hyper parameter가 너무 많아 튜닝 시간이 많이 소모되는 것이고, 많은 시간을 소모하여 튜닝을 한 후에도 예측 성능은 크게 상향되지 않는다. 그나마 랜덤 포레스트가 적은 편에 속하는데 결정 트리를 사용하여 hyper parameter가 대부분 동일하기 때문이다.
- n_extimate : 랜덤 포레스트에서 결정 트리의 개수를 지정한다. default는 10개이고, 많이 설정할수록 좋은 성능을 기대할 수 있지만 계속 증가시킨다고 성능이 무조건 향상되는 것은 아니다. 또한 늘릴수록 학습 수행 시간이 오래 걸리는 것도 감안해야 한다.
- max_features : 결정 트리에 사용되는 max_features 파라미터와 동일하다. 하지만 RandomForestClassifier의 기본 max_features는 'None'이 아니라 'auto'로 성절되어 있고, 'sqrt'와 동일하다. 따라서 랜덤 포레스트의 트리를 분할하는 feature를 참조할 때 전체 feature가 아니라 sqrt(전체 feature 수)만큼 참조한다.
- max_depth나 min_samples_leaf와 같이 결정트리에서 과적합을 개선하기 위해 사용되는 parameter가 랜덤 포레스트에도 똑같이 적용된다.
GridSearchCV를 통해 parameter 튜닝을 해보겠다.
from sklearn.model_selection import GridSearchCV
>
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
>
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
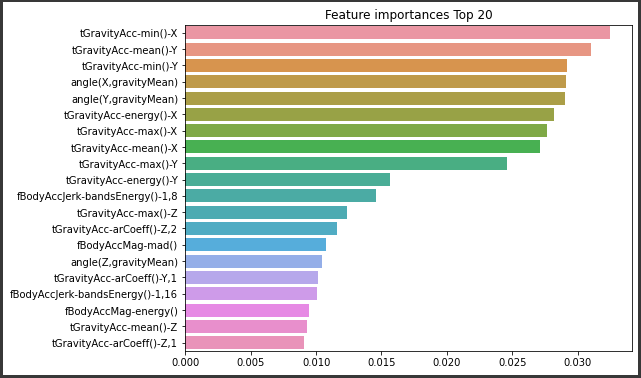
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))[output]  최적화 parameter로 약 91.80%의 정확도가 나왔다. 이 hyper parameter를 그대로 사용하고 n_estimator만 300으로 증가시키고 다시 학습한 후 예측 성능을 측정해보고 feature의 중요도를 막대그래프로 시각화해보겠다.
최적화 parameter로 약 91.80%의 정확도가 나왔다. 이 hyper parameter를 그대로 사용하고 n_estimator만 300으로 증가시키고 다시 학습한 후 예측 성능을 측정해보고 feature의 중요도를 막대그래프로 시각화해보겠다.
rf_clf1 = RandomForestClassifier(n_estimators=300, max_depth=10, min_samples_leaf=8, \
min_samples_split=8, random_state=0)
rf_clf1.fit(X_train , y_train)
pred = rf_clf1.predict(X_test)
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))[output] 
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
>
ftr_importances_values = rf_clf1.feature_importances_
ftr_importances = pd.Series(ftr_importances_values,index=X_train.columns )
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
>
plt.figure(figsize=(8,6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20 , y = ftr_top20.index)
plt.show()[output]