위키북스의 파이썬 머신러닝 완벽 가이드 책을 토대로 공부한 내용입니다.
1. 산탄데르 고객 만족 dataset
캐글의 산탄데르 고객 만족(Santander Customer Satisfaction) dataset에 대해 고객 만족 여부를 XGBoost와 LightGBM으로 예측해보겠다. 이 dataset은 370개의 feature로 이루어진 데이터를 기반으로 고객 만족 여부를 예측하는 것이고, 산탄데르 은행이 캐글에 경연을 의뢰한 데이터로서 feature 이름은 모두 익명 처리되어 어떤 속성인지는 추정할 수 없다. TARGET 속성의 값이 1이면 불만이 많은 고객, 0이면 만족한 고객이고, 모델 성능 평가는 ROC-AUC로 평가한다. 왜냐하면 대부분이 만족이고 불만족인 데이터는 일부일 것이기 때문에 정확도 수치보다는 ROC-AUC가 더 적합하다.
2. 데이터 전처리
필요한 모듈과 데이터를 로딩하고 feature의 타입과 Null 값이 있는지 알아보겠다.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib cust_df = pd.read_csv("./train_santander.csv",encoding='latin-1') cust_df.info()[output]
111개의 float 형과 260개의 int 형이 있고, Null 값은 없다. label인 Target 속성의 값의 분포를 알아보겠다.
print(cust_df['TARGET'].value_counts()) unsatisfied_cnt = cust_df[cust_df['TARGET'] == 1].TARGET.count() total_cnt = cust_df.TARGET.count() print('unsatisfied 비율은 {0:.2f}'.format((unsatisfied_cnt / total_cnt)))[output]
대부분이 만족이고 약 4%만이 불만족인 고객이다. describe() method를 이용해 각 feature의 값 분포를 간단히 확인해보겠다.
cust_df.describe( )[output]
var3 column의 경우 min 값이 -999999로 되어 있는 것을 보아 NaN이나 특정 예외 값을 -999999로 변환했을 것이다. var3의 값을 조사해 보면 -999999값이 116개가 있는 것을 알 수 있고, 다른 값에 비해 너무 편차가 싶하므로 가장 값이 많은 2로 변환하겠다. 그리고 ID feature는 단순 식별자에 불과하므로 드롭한 후 학습 dataset과 테스트 dataset을 분리하겠다.
# var3 피처 값 대체 및 ID 피처 드롭 cust_df['var3'].replace(-999999,2, inplace=True) cust_df.drop('ID',axis=1 , inplace=True) # 피처 세트와 레이블 세트분리. 레이블 컬럼은 DataFrame의 맨 마지막에 위치해 컬럼 위치 -1로 분리 X_features = cust_df.iloc[:, :-1] y_labels = cust_df.iloc[:, -1] from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X_features, y_labels, test_size=0.2, random_state=0) train_cnt = y_train.count() test_cnt = y_test.count() print('학습 세트 Shape:{0}, 테스트 세트 Shape:{1}'.format(X_train.shape , X_test.shape)) print(' 학습 세트 레이블 값 분포 비율') print(y_train.value_counts()/train_cnt) print('\n 테스트 세트 레이블 값 분포 비율') print(y_test.value_counts()/test_cnt)[output]
비대칭한 dataset으로 학습 dataset과 테스트 dataset에 label의 분포가 비슷하게 추출되었는지 확인한다.
3. XGBoost 모델 학습과 하이퍼 파라미터 튜닝
XGBoost의 학습 모델을 생성하고 예측 결과를 ROC AUC로 평가해 보겠다.
from xgboost import XGBClassifier from sklearn.metrics import roc_auc_score # n_estimators는 500으로, random state는 예제 수행 시마다 동일 예측 결과를 위해 설정. xgb_clf = XGBClassifier(n_estimators=500, random_state=156) # 성능 평가 지표를 auc로, 조기 중단 파라미터는 100으로 설정하고 학습 수행. xgb_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)]) xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:,1],average='macro') print('ROC AUC: {0:.4f}'.format(xgb_roc_score))[output]
테스트 dataset으로 예측 시 ROC AUC는 약 0.8419이다. 다음으로 XGBoost의 하이퍼 파라미터 튜닝을 해보겠다. column의 수가 많으므로 과적합 가능성을 가정하고 일차 튜닝으로 max_depth, min_child_weight, colsample_bytree 하이퍼 파라미터만 튜닝하며 8개의 경우의 수에 대해 수행해보겠다.
from sklearn.model_selection import GridSearchCV # 하이퍼 파라미터 테스트의 수행 속도를 향상시키기 위해 n_estimators를 100으로 감소 xgb_clf = XGBClassifier(n_estimators=100) params = {'max_depth':[5, 7] , 'min_child_weight':[1,3] ,'colsample_bytree':[0.5, 0.75] } # cv는 3으로 지정 gridcv = GridSearchCV(xgb_clf, param_grid=params, cv=3) gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)]) print('GridSearchCV 최적 파라미터:',gridcv.best_params_) xgb_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:,1], average='macro') print('ROC AUC: {0:.4f}'.format(xgb_roc_score))[output]
ROC-AUC가 0.8448로 조금 개선되었다. 일차 튜닝에서 구한 최적의 하이퍼 파라미터를 기반으로 다른 하이퍼 파라미터를 변경 또는 추가해서 다시 최적화를 해보겠다.
# n_estimators는 1000으로 증가시키고, learning_rate=0.02로 감소, reg_alpha=0.03으로 추가함. xgb_clf = XGBClassifier(n_estimators=1000, random_state=156, learning_rate=0.02, max_depth=7,\ min_child_weight=1, colsample_bytree=0.75, reg_alpha=0.03) # evaluation metric을 auc로, early stopping은 200 으로 설정하고 학습 수행. xgb_clf.fit(X_train, y_train, early_stopping_rounds=200, eval_metric="auc",eval_set=[(X_train, y_train), (X_test, y_test)]) xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:,1],average='macro') print('ROC AUC: {0:.4f}'.format(xgb_roc_score))[output]
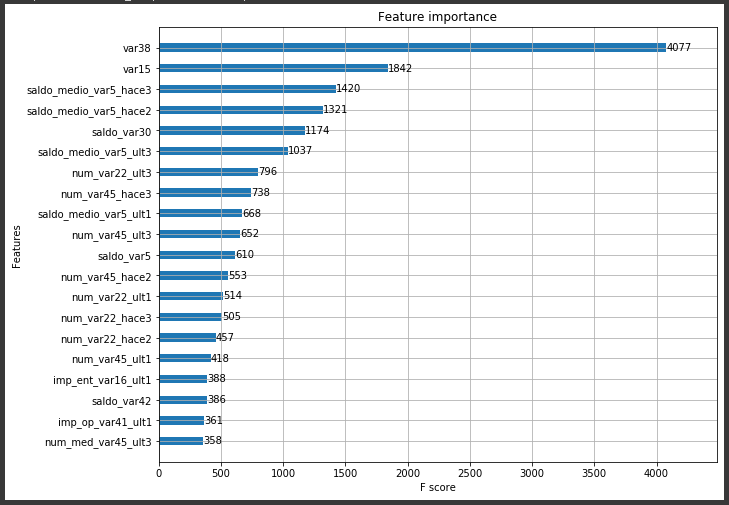
이전 보다 0.8456으로 약간 더 증가하였다. 하지만 GBM을 기반으로 하고 있기 때문에 GBM 보다 빠르지만 그래도 상당한 수행 시간이 요구된다. 튜닝된 모델에서 각 feature의 중요도를 시각화해보겠다.
from xgboost import plot_importance import matplotlib.pyplot as plt %matplotlib inline fig, ax = plt.subplots(1,1,figsize=(10,8)) plot_importance(xgb_clf, ax=ax , max_num_features=20,height=0.4)[output]
4. LightGBm 모델 학습과 하이퍼 파라미터 튜닝
같은 dataset을 기반으로 LightGBM 학습을 수행하고, ROC-AUC를 측정해 보겠다.
from lightgbm import LGBMClassifier lgbm_clf = LGBMClassifier(n_estimators=500) evals = [(X_test, y_test)] lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc", eval_set=evals, verbose=True) lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:,1],average='macro') print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))[output]
우선 XGBoost보다 학습이 더 빠르게 된다는 걸 느낄 수 있고, ROC-AUC는 약 0.8396으로 나온다. GridSearchCV로 좀 더 다양한 하이퍼 파라미터에 대한 튜닝을 수행해 보겠다.
from sklearn.model_selection import GridSearchCV # 하이퍼 파라미터 테스트의 수행 속도를 향상시키기 위해 n_estimators를 100으로 감소 lgbm_clf = LGBMClassifier(n_estimators=200) params = {'num_leaves': [32, 64 ], 'max_depth':[128, 160], 'min_child_samples':[60, 100], 'subsample':[0.8, 1]} # cv는 3으로 지정 gridcv = GridSearchCV(lgbm_clf, param_grid=params, cv=3) gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)]) print('GridSearchCV 최적 파라미터:', gridcv.best_params_) lgbm_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:,1], average='macro') print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))[output]
해당 하이퍼 파라미터를 LightGBM에 적용하고 다시 학습하여 ROC-AUC 측정 결과를 도출해 보겠다.
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=32, sumbsample=0.8, min_child_samples=100, max_depth=128) evals = [(X_test, y_test)] lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc", eval_set=evals, verbose=True) lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:,1],average='macro') print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))[output]
LightGBM의 경우 테스트 dataset에 대해 ROC-AUC가 약 0.8442로 측정되었다.
