위키북스의 파이썬 머신러닝 완벽 가이드 책을 토대로 공부한 내용입니다.
1. 스태킹 앙상블
스태킹(Stacking)은 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는 점에서 배깅(Bagging) 및 부스팅(Boosting)과 공통점을 가지고 있다. 하지만 가장 큰 차이점은 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 점이다. 즉, 개별 알고리즘의 예측 결과 dataset을 최종적인 메타 dataset으로 만들어 별도 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행하는 방식이다. 개별 모델의 예측된 dataset을 기반으로 학습하고 예측하는 방식을 메타 모델이라고 한다. 스캐팅엔 개별적인 기반 모델과 최종 메타 모델이 필요하다. 핵심은 여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해 최종 메타 모델의 학습용 feature dataset과 테스트 feature dataset을 만드는 것이다.
현실 모델에서 스태킹을 적용하는 경우는 많지 않지만, 캐글과 같은 대회에서 조금이라도 성능을 올려야 할 경우 자주 사용된다. 스태킹을 적용할 때는 2~3개가 아닌 많은 개별 모델이 필욯하고, 이렇게 적용한다고 해서 반드시 성능 향상이 된다는 보장은 없다. 일반적으로 성능이 비슷한 모델을 결합해 좀 더 나은 성능 향상을 도출하기 위해 적용된다.
M개의 row, N개의 feature(column)을 가진 dataset이 있고 스태킹 앙상블을 위해 3개의 개별 모델이 있다고 가정한다. 먼저 각 개별 모델을 학습을 시킨 뒤 예측을 수행하면 각 M개의 row를 가진 1개의 label 값을 도출할 것이다. 이렇게 각 개별 모델에서 도출된 label들을 stacking하여 M개의 row와 3개의 column을 가진 새로운 dataset으로 만들고 최종 모델에 적용하여 예측을 수행하는 것이 스태킹 앙상블 모델이다.
2. 기본 스태킹 모델
기본 스태킹 앙상블 모델로 위스콘신 암 dataset에 적용시켜 보겠다.
import numpy as np from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score cancer_data = load_breast_cancer() X_data = cancer_data.data y_label = cancer_data.target X_train , X_test , y_train , y_test = train_test_split(X_data , y_label , test_size=0.2 , random_state=0) # 개별 ML 모델을 위한 Classifier 생성. knn_clf = KNeighborsClassifier(n_neighbors=4) rf_clf = RandomForestClassifier(n_estimators=100, random_state=0) dt_clf = DecisionTreeClassifier() ada_clf = AdaBoostClassifier(n_estimators=100) # 최종 Stacking 모델을 위한 Classifier생성. lr_final = LogisticRegression(C=10) # 개별 모델들을 학습. knn_clf.fit(X_train, y_train) rf_clf.fit(X_train , y_train) dt_clf.fit(X_train , y_train) ada_clf.fit(X_train, y_train) # 학습된 개별 모델들이 각자 반환하는 예측 데이터 셋을 생성하고 개별 모델의 정확도 측정. knn_pred = knn_clf.predict(X_test) rf_pred = rf_clf.predict(X_test) dt_pred = dt_clf.predict(X_test) ada_pred = ada_clf.predict(X_test) print('KNN 정확도: {0:.4f}'.format(accuracy_score(y_test, knn_pred))) print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy_score(y_test, rf_pred))) print('결정 트리 정확도: {0:.4f}'.format(accuracy_score(y_test, dt_pred))) print('에이다부스트 정확도: {0:.4f}'.format(accuracy_score(y_test, ada_pred)))[output]
스태킹에 사용될 개별 모델은 KNN, 랜덤 포레스트, 결정 트리, 에이다부스트이며 최종 모델은 로지스틱 회귀 모델이다. 먼저 개별 알고리즘으로 부터 예측 정확도를 출력해보았다. 예측된 예측값을 column level로 옆으로 붙인 후 feature 값을 만들어 최종 모델에서 학습 데이터로 다시 사용하겠다.
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred]) # transpose를 이용해 행과 열의 위치 교환. 컬럼 레벨로 각 알고리즘의 예측 결과를 피처로 만듦. pred = np.transpose(pred) lr_final.fit(pred, y_test) final = lr_final.predict(pred) print('최종 메타 모델의 예측 정확도: {0:.4f}'.format(accuracy_score(y_test , final)))[output]
최종 메타 모델에서 학습하고 예측한 결과, 정확도가 97.37%로 개별 모델 정확도보다 향상되었다.
3. CV 세트 기반의 스태킹
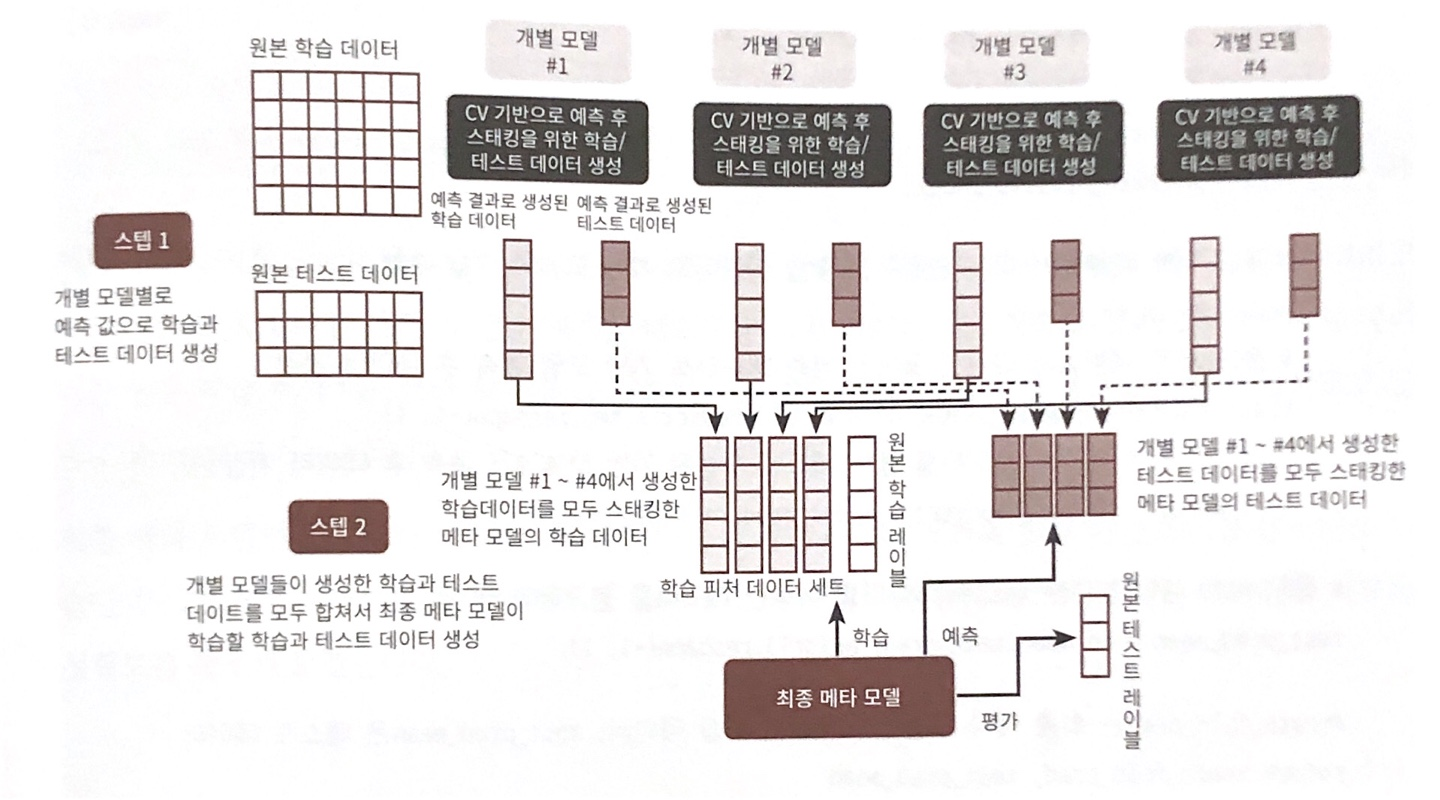
CV 세트 기반의 스태킹 모델은 과적합을 개선하기 위해 최종 메타 모델을 위한 dataset을 만들 때 교차 검증 기반으로 예측된 결과 dataset을 이용한다. 위 기본 스태킹 모델에서 최종 학습을 할 때 label dataset으로 학습 dataset이 아닌 테스트 dataset을 사용하였는데, 이는 어느 정도 예측을 이룬 dataset에 대하여 다시 추가 학습을 하게 되면 과적합이 발생할 가능성이 높아 개별 모델의 학습에 사용되지 않은 dataset으로 학습을 진행한 것이다. 이 방식을 사용하여 CV 세트 기반의 스태킹 모델은 개별 모델들이 각각 교차 검증으로 메타 모델을 위한 학습용 스태킹 데이터 생성과 예측을 위한 테스트용 스태킹 데이터를 생성한 뒤 이를 기반으로 메타 모델이 학습과 예측을 수행한다.
스텝 1: 각 모델별로 원본 학습/테스트 데이터를 예측한 결과 값을 기반으로 메타 모델을 위한 학습용/테스트용 데이터를 생성한다.
(1) 학습용 데이터를 N개의 Fold로 나누고, N-1개의 Fold는 학습을, 나머지 1개의 Fold는 검증을 위해 사용한다.
(2) N-1개의 Fold로 학습된 개별 모델은 검증용 Fold로 예측을 수행하고 그 결과를 저장한다. 이러한 로직을 N번 반복하면서 검증 Fold를 변경하여 예측 결과를 저장한다. 이렇게 만들어진 예측 결과값들을 메타 모델의 학습 데이터로 사용한다.
(3) 그리고 N번 반복할 때마다 원본 테스트 데이터를 예측하여 이 결과값도 저장하면서 N번의 반복이 끝나면 테스트 데이터의 결과값들의 평균값을 메타 모델의 테스트 데이터로 사용한다.스텝 2: 스텝 1에서 개별 모델들이 생성한 학습용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 학습할 최종 학습용 dataset를 생성한다. 마찬가지로 각 모델들이 생성한 테스트용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 예측할 최종 테스트 dataset를 생성한다. 메타 모델은 최종적으로 생성된 학습 dataset와 원본 학습 데이터의 label 데이터를 기반으로 학습한 뒤, 최종적으로 생성된 테스트 dataset을 예측하고, 원본 테스트 데이터의 label 데이터를 기반으로 평가한다.
먼저 스텝 1의 코드를 구현하여 get_stacking_base_datasets() 함수로 생성하겠다.
from sklearn.model_selection import KFold from sklearn.metrics import mean_absolute_error # 개별 기반 모델에서 최종 메타 모델이 사용할 학습 및 테스트용 데이터를 생성하기 위한 함수. def get_stacking_base_datasets(model, X_train_n, y_train_n, X_test_n, n_folds ): # 지정된 n_folds값으로 KFold 생성. kf = KFold(n_splits=n_folds, shuffle=False, random_state=0) #추후에 메타 모델이 사용할 학습 데이터 반환을 위한 넘파이 배열 초기화 train_fold_pred = np.zeros((X_train_n.shape[0] ,1 )) test_pred = np.zeros((X_test_n.shape[0],n_folds)) for folder_counter , (train_index, valid_index) in enumerate(kf.split(X_train_n)): #입력된 학습 데이터에서 기반 모델이 학습/예측할 폴드 데이터 셋 추출 X_tr = X_train_n[train_index] y_tr = y_train_n[train_index] X_te = X_train_n[valid_index] #폴드 세트 내부에서 다시 만들어진 학습 데이터로 기반 모델의 학습 수행. model.fit(X_tr , y_tr) #폴드 세트 내부에서 다시 만들어진 검증 데이터로 기반 모델 예측 후 데이터 저장. train_fold_pred[valid_index, :] = model.predict(X_te).reshape(-1,1) #입력된 원본 테스트 데이터를 폴드 세트내 학습된 기반 모델에서 예측 후 데이터 저장. test_pred[:, folder_counter] = model.predict(X_test_n) # 폴드 세트 내에서 원본 테스트 데이터를 예측한 데이터를 평균하여 테스트 데이터로 생성 test_pred_mean = np.mean(test_pred, axis=1).reshape(-1,1) #train_fold_pred는 최종 메타 모델이 사용하는 학습 데이터, test_pred_mean은 테스트 데이터 return train_fold_pred , test_pred_mean knn_train, knn_test = get_stacking_base_datasets(knn_clf, X_train, y_train, X_test, 7) rf_train, rf_test = get_stacking_base_datasets(rf_clf, X_train, y_train, X_test, 7) dt_train, dt_test = get_stacking_base_datasets(dt_clf, X_train, y_train, X_test, 7) ada_train, ada_test = get_stacking_base_datasets(ada_clf, X_train, y_train, X_test, 7) Stack_final_X_train = np.concatenate((knn_train, rf_train, dt_train, ada_train), axis=1) Stack_final_X_test = np.concatenate((knn_test, rf_test, dt_test, ada_test), axis=1) print('원본 학습 피처 데이터 Shape:',X_train.shape, '원본 테스트 피처 Shape:',X_test.shape) print('스태킹 학습 피처 데이터 Shape:', Stack_final_X_train.shape, '스태킹 테스트 피처 데이터 Shape:',Stack_final_X_test.shape)[output]
Stack_final_X_train는 메타 모델이 학습할 학습용 feature dataset이고, Stack_final_X_test은 메타 모델이 학습할 테스트용 feature dataset이다. 그 다음 스텝 2를 구현해 보고 정확도를 측정해보겠다.
lr_final.fit(Stack_final_X_train, y_train) stack_final = lr_final.predict(Stack_final_X_test) print('최종 메타 모델의 예측 정확도: {0:.4f}'.format(accuracy_score(y_test, stack_final)))[output]
최종 예측 정확도는 97.37%이다. 위 예제에서는 개별 모델의 알고리즘에서 파라미터 튜닝을 최적으로 하지 않았지만, 스태킹을 이루는 모델은 최적으로 파라미터를 튜닝한 상태에서 스태킹 모델을 만드는 것이 일반적이다. 그리고 스태킹 모델은 분류 뿐만 아니라 회귀에도 적용 가능하다.