위키북스의 파이썬 머신러닝 완벽 가이드 책을 토대로 공부한 내용입니다.
1. 경사 하강법
경사 하강법은 고차원 방정식에 대한 문제를 해결해 주면서 비용 함수 RSS를 최소화하는 방법을 직관적으로 제공하는 뛰어난 방식이다. 사실 경사 하강법은 '데이터를 기반으로 알고리즘이 스스로 학습한다'는 머신러닝의 개념을 가능하게 만들어준 핵심 기법의 하나이다. 사전적 의미는 '점진적 하강'이라는 뜻으로 점진적으로 반복적인 계산을 통해 w 파라미터를 업데이트하면서 오류 값이 최소가 되는 w 파라미터를 구하는 방식이다.
핵심은 오류가 작아지는 방향으로 w 값을 업데이트하는 방법이다. 위 그림과 같은 포물선 형태의 2차 함수의 최저점은 해당 2차 함수의 미분 값인 1차 함수의 기울기가 가장 최소일 때이다. 따라서 만약 비용 함수가 포물선 모양의 2차 함수라면 경사 하강법은 최초의 w에서부터 미분을 적용한 뒤 이 미분 값이 계속 감소하는 방향으로 순차적으로 w를 업데이트한다. 그리고 더 이상 미분된 1차 함수의 기울기가 감소하지 않는 지점을 비용 함수가 최소인 지점으로 간주하고 그때의 w를 반환한다.
비용 함수 에 경사하강법을 적용하여 보겠다. 이다. 이 식을 미분해서 미분 함수의 최솟값을 구해랴 하는데 파라미터가 1개가 아닌 과 을 가지고 있어 편미분을 해야 한다.
편미분의 결과값을 반복적으로 보정하면서 파라미터 값을 업데이트하면 가 최소가 되는 파라미터를 구할 수 있다. 업데이트는 편미분 결과값에 마이너스(-)를 해준 뒤 원래 파라미터 값에 더해준다. 그리고 편미분 값이 너무 클 수 있기 때문에 보정 계수 를 곱하는데, 이를 '학습률'이라고 부른다.
2. 경사 하강법 구현
간단한 회귀식인 y=4x+6을 근사하기 위한 100개의 데이터를 만들고 경사하강법을 이용해 회귀 계수를 도출해보겠다.
import numpy as np import matplotlib.pyplot as plt %matplotlib inline np.random.seed(0) # y = 4X + 6 식을 근사(w1=4, w0=6). random 값은 Noise를 위해 만듬 X = 2 * np.random.rand(100,1) y = 6 +4 * X+ np.random.randn(100,1) # X, y 데이터 셋 scatter plot으로 시각화 plt.scatter(X, y)[output]
데이터는 y=4x+6을 중심으로 무작위로 퍼져 있다. 그 다음 비용함수를 정의하고 파라미터를 업데이트하는 함수를 구현하여 경사하강법을 적용시켜 회귀 계수를 도출해보겠다.
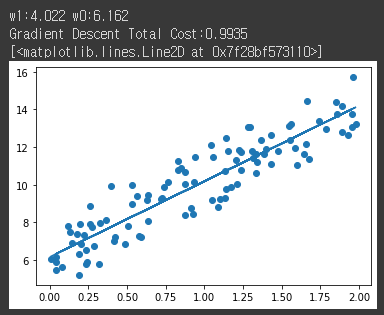
# w1 과 w0 를 업데이트 할 w1_update, w0_update를 반환. def get_weight_updates(w1, w0, X, y, learning_rate=0.01): N = len(y) # 먼저 w1_update, w0_update를 각각 w1, w0의 shape와 동일한 크기를 가진 0 값으로 초기화 w1_update = np.zeros_like(w1) w0_update = np.zeros_like(w0) # 예측 배열 계산하고 예측과 실제 값의 차이 계산 y_pred = np.dot(X, w1.T) + w0 diff = y-y_pred # w0_update를 dot 행렬 연산으로 구하기 위해 모두 1값을 가진 행렬 생성 w0_factors = np.ones((N,1)) # w1과 w0을 업데이트할 w1_update와 w0_update 계산 w1_update = -(2/N)*learning_rate*(np.dot(X.T, diff)) w0_update = -(2/N)*learning_rate*(np.dot(w0_factors.T, diff)) return w1_update, w0_update # 입력 인자 iters로 주어진 횟수만큼 반복적으로 w1과 w0를 업데이트 적용함. def gradient_descent_steps(X, y, iters=10000): # w0와 w1을 모두 0으로 초기화. w0 = np.zeros((1,1)) w1 = np.zeros((1,1)) # 인자로 주어진 iters 만큼 반복적으로 get_weight_updates() 호출하여 w1, w0 업데이트 수행. for ind in range(iters): w1_update, w0_update = get_weight_updates(w1, w0, X, y, learning_rate=0.01) w1 = w1 - w1_update w0 = w0 - w0_update return w1, w0 def get_cost(y, y_pred): N = len(y) cost = np.sum(np.square(y - y_pred))/N return cost w1, w0 = gradient_descent_steps(X, y, iters=1000) print("w1:{0:.3f} w0:{1:.3f}".format(w1[0,0], w0[0,0])) y_pred = w1[0,0] * X + w0 print('Gradient Descent Total Cost:{0:.4f}'.format(get_cost(y, y_pred))) plt.scatter(X, y) plt.plot(X,y_pred)[output]
3. 확률적 경사 하강법
일반적으로 경사 하강법은 모든 학습 데이터레 대해 반복적으로 비용함수 최소화를 위한 값을 업데이트하기 때문에 수행 시간이 매우 오래 걸린다는 단점이 있다. 그래서 실전에서는 대부분 확률적 경사 하강법(Stochastic Gradient Descent)를 이용한다. 확률적 경사 하강법은 전체 데이터에 대해 파라미터를 업데이트하는 것이 아니라 일부 데이터만 이용해 파라미터가 업데이트하기 때문에 경사 하강법에 비해 빠른 속도를 보장한다. 따라서 대용량의 학습 데이터의 경우 대부분 확률적 경사 하강법이나 미니 배치 확률적 경사 하강법을 이용해 최적 비용함수를 도출한다.
def stochastic_gradient_descent_steps(X, y, batch_size=10, iters=1000): w0 = np.zeros((1,1)) w1 = np.zeros((1,1)) prev_cost = 100000 iter_index =0 for ind in range(iters): np.random.seed(ind) # 전체 X, y 데이터에서 랜덤하게 batch_size만큼 데이터 추출하여 sample_X, sample_y로 저장 stochastic_random_index = np.random.permutation(X.shape[0]) sample_X = X[stochastic_random_index[0:batch_size]] sample_y = y[stochastic_random_index[0:batch_size]] # 랜덤하게 batch_size만큼 추출된 데이터 기반으로 w1_update, w0_update 계산 후 업데이트 w1_update, w0_update = get_weight_updates(w1, w0, sample_X, sample_y, learning_rate=0.01) w1 = w1 - w1_update w0 = w0 - w0_update return w1, w0 w1, w0 = stochastic_gradient_descent_steps(X, y, iters=1000) print("w1:",round(w1[0,0],3),"w0:",round(w0[0,0],3)) y_pred = w1[0,0] * X + w0 print('Stochastic Gradient Descent Total Cost:{0:.4f}'.format(get_cost(y, y_pred)))[output]

