위키북스의 파이썬 머신러닝 완벽 가이드 책을 토대로 공부한 내용입니다.
1. 자전거 대여 수요 예측 데이터
자전거 대여 수요 예측 dataset에는 2011년 1월부터 2012년 12월까지 날짜/시간, 기온, 습도, 풍속 등의 정보를 기반으로 1시간 간격 동안의 자전거 대여 횟수가 기재되어 있다. dataset의 주요 column은 다음과 같고, 결정값은 가장 마지막 column인 count로 '대여 횟수'를 의미한다.
- datatime: hourly date + timestamp
- season: 1=봄, 2=여름, 3=가을, 4=겨울
- holiday: 1=토,일요일의 주말을 제외한 국경일 등의 휴일, 0=휴일이 아닌 날
- workingday: 1=토,일요일의 주말 및 휴일이 아닌 주중, 0=주말 및 휴일
- weather: 1=맑음, 약간 구름 낀 흐림, 2=안개, 안개+흐림, 3=가벼운 눈, 가벼운 비+천둥, 4=심한 눈/비, 천둥/번개
- temp: 온도(섭씨)
- atemp: 체감온도(섭씨)
- humidity: 상대습도
- windspeed: 풍속
- casual: 사전에 등록되지 않는 사용자가 대여한 횟수
- registered: 사전에 등록된 사용자가 대여한 횟수
- count: 대여 횟수
2. 데이터 클렌징 및 가공
dataset을 DataFrame으로 로드해 대략적인 확인을 해보겠다.
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline import warnings warnings.filterwarnings("ignore", category=RuntimeWarning) bike_df = pd.read_csv('./bike_train.csv') bike_df.info()[output]
datetime column을 제외하면 전부 int 혹은 float 타입이다. datetime column의 경우 년-월-일 시:분:초 문자 형식으로 되어 있어 이에 대한 처리가 필요하다. datetime을 년,월,일,시간의 4가지 속성으로 분리할텐데 pandas에서는 datetime과 같은 형태의 문자열을 편리하게 변환하려면 먼저 apply method를 이용하여 문자열을 datetime 타입으로 변경해야 한다.
# 문자열을 datetime 타입으로 변경. bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime) # datetime 타입에서 년, 월, 일, 시간 추출 bike_df['year'] = bike_df.datetime.apply(lambda x : x.year) bike_df['month'] = bike_df.datetime.apply(lambda x : x.month) bike_df['day'] = bike_df.datetime.apply(lambda x : x.day) bike_df['hour'] = bike_df.datetime.apply(lambda x: x.hour) bike_df.head(3)[output]
새로 year, month, day,hour column이 추가 되었고 기존의 datetime column은 삭제하겠다. 그리고 casual과 registered를 합하면 그 값이 count가 되므로 상관도가 너무 높아 예측을 저해할 우려가 있으므로 2개의 column도 삭제하겠다.
drop_columns = ['datetime','casual','registered'] bike_df.drop(drop_columns, axis=1,inplace=True)캐글에서 요구한 성능 평가 방법은 RMSLE(Root Mean Square Log Error)로 오류 값의 로그에 대한 RMSE이다. 사이킷런은 RMSLE를 제공하지 않아 MSE와 RMSE, RMSLE를 모두 평가하는 함수를 만들어보겠다. 로그를 사용할 때 주의할 점은 numpy의 log()나 사이킷런의 mean_square_log_error()를 이용할 수도 있지만 데이터 값의 크기에 따라 overflow나 underflow가 발생하기 쉽다. 따라서 numpy의 log1p()를 이용하는데 이 함수는 1+log() 값으로 overflow나 underflow 문제를 해결해준다. log1p()로 변환된 값은 exp1m() 함수로 복원할 수 있다.
from sklearn.metrics import mean_squared_error, mean_absolute_error # log 값 변환 시 NaN등의 이슈로 log() 가 아닌 log1p() 를 이용하여 RMSLE 계산 def rmsle(y, pred): log_y = np.log1p(y) log_pred = np.log1p(pred) squared_error = (log_y - log_pred) ** 2 rmsle = np.sqrt(np.mean(squared_error)) return rmsle # 사이킷런의 mean_square_error() 를 이용하여 RMSE 계산 def rmse(y,pred): return np.sqrt(mean_squared_error(y,pred)) # MSE, RMSE, RMSLE 를 모두 계산 def evaluate_regr(y,pred): rmsle_val = rmsle(y,pred) rmse_val = rmse(y,pred) # MAE 는 scikit learn의 mean_absolute_error() 로 계산 mae_val = mean_absolute_error(y,pred) print('RMSLE: {0:.3f}, RMSE: {1:.3F}, MAE: {2:.3F}'.format(rmsle_val, rmse_val, mae_val))
3. 로그 변환, feature 인코딩과 모델 학습/예측/평가
회귀 모델을 이용하여 자전거 대여 횟수를 예측해보기 전에 결과값이 정규 분포인지 확인하는 것과 카테고리형 회귀 모델의 경우 ont-hot 인코딩으로 feature를 인코딩해야한다. 이유를 알아보기 위해 우선 LinearRegression 객체를 이용하여 회귀 예측을 해보겠다.
from sklearn.model_selection import train_test_split , GridSearchCV from sklearn.linear_model import LinearRegression , Ridge , Lasso y_target = bike_df['count'] X_features = bike_df.drop(['count'],axis=1,inplace=False) X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.3, random_state=0) lr_reg = LinearRegression() lr_reg.fit(X_train, y_train) pred = lr_reg.predict(X_test) evaluate_regr(y_test ,pred)[output]
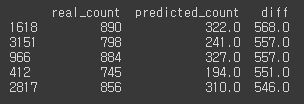
실제 대여 횟수인 count에 비하면 꽤 큰 오류값이다. 오류가 가장 큰 5개의 값만 확인해보겠다.def get_top_error_data(y_test, pred, n_tops = 5): # DataFrame에 컬럼들로 실제 대여횟수(count)와 예측 값을 서로 비교 할 수 있도록 생성. result_df = pd.DataFrame(y_test.values, columns=['real_count']) result_df['predicted_count']= np.round(pred) result_df['diff'] = np.abs(result_df['real_count'] - result_df['predicted_count']) # 예측값과 실제값이 가장 큰 데이터 순으로 출력. print(result_df.sort_values('diff', ascending=False)[:n_tops]) get_top_error_data(y_test,pred,n_tops=5)[output]
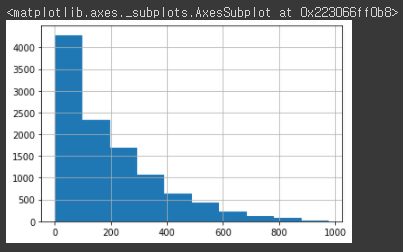
회귀에서 이렇게 큰 예측 오류가 발생할 경우 가장 먼저 살펴볼 것은 Target 값의 분포가 정규분포가 아닌 왜곡된 형태를 이루고 있는지 확인하는 것이다.y_target.hist()[output]
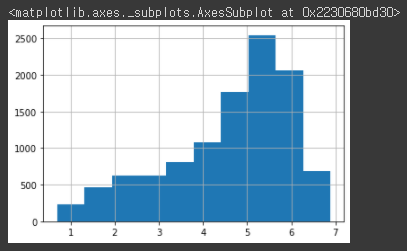
이렇게 왜곡된 값을 정규 분포 형태로 바꾸는 가장 일반적인 방법은 로그를 적용해 변환하는 것이다. 이렇게 변환된 Target 값을 기반으로 학습하고 예측한 값을 다시 exp1m() 함수로 원래 값으로 복원하면 된다. log1p()를 적용한 후 Target 값의 분포를 확인해보겠다.y_log_transform = np.log1p(y_target) y_log_transform.hist()[output]
완벽한 정규분포 형태는 아니지만 변환하기 전보다는 왜곡 정도가 많이 향상되었다. 이 Target 값으로 다시 학습을 해보겠다.# 타겟 컬럼인 count 값을 log1p 로 Log 변환 y_target_log = np.log1p(y_target) # 로그 변환된 y_target_log를 반영하여 학습/테스트 데이터 셋 분할 X_train, X_test, y_train, y_test = train_test_split(X_features, y_target_log, test_size=0.3, random_state=0) lr_reg = LinearRegression() lr_reg.fit(X_train, y_train) pred = lr_reg.predict(X_test) # 테스트 데이터 셋의 Target 값은 Log 변환되었으므로 다시 expm1를 이용하여 원래 scale로 변환 y_test_exp = np.expm1(y_test) # 예측 값 역시 Log 변환된 타겟 기반으로 학습되어 예측되었으므로 다시 exmpl으로 scale변환 pred_exp = np.expm1(pred) evaluate_regr(y_test_exp ,pred_exp)[output]
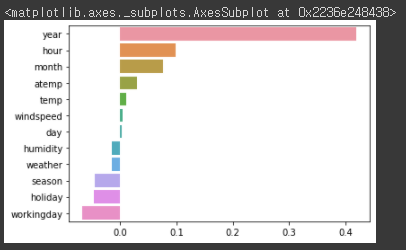
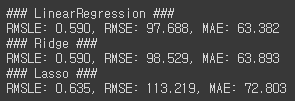
RMSLE는 줄었지만, RMSE는 더 늘어났다. 이유를 찾기 위해 각 feature의 회귀 계수 값을 시각화해보겠다.coef = pd.Series(lr_reg.coef_, index=X_features.columns) coef_sort = coef.sort_values(ascending=False) sns.barplot(x=coef_sort.values, y=coef_sort.index)[output]
Year feature의 회귀 계수가 굉장히 큰 것을 볼 수 있다. year는 2011년, 2012년으로 2개의 값을 가지고 있으며, 자전거 대여 횟수에 크게 영향을 준다고 생각하기 어렵다. year의 회귀 계수가 이렇게 큰 값을 가지는 이유는 2011, 2012와 같이 매우 큰 값을 가지고 있기 때문이다. 이러한 숫자형으로 되어 있는 카테고리형 feature를 사용하는 경우 회귀 계수를 연산할 때 큰 영향을 받을 수 있어 one-hot 인코딩을 적용하여 변환해줘야한다. 따라서 year 뿐만 아니라 month, day, hour, holiday, workingday, season, weather column도 전부 one-hot 인코딩을 해준 후 다시 학습해보겠다. 그리고 LinearRegression, Ridge, Lasso 모두 학습한 후 예측해보겠다.# 'year', month', 'day', hour'등의 피처들을 One Hot Encoding X_features_ohe = pd.get_dummies(X_features, columns=['year','month','day','hour','holiday','workingday','season','weather']) # 원-핫 인코딩이 적용된 feature 데이터 세트 기반으로 학습/예측 데이터 분할. X_train, X_test, y_train, y_test = train_test_split(X_features_ohe, y_target_log,test_size=0.3, random_state=0) # 모델과 학습/테스트 데이터 셋을 입력하면 성능 평가 수치를 반환 def get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1=False): model.fit(X_train, y_train) pred = model.predict(X_test) if is_expm1 : y_test = np.expm1(y_test) pred = np.expm1(pred) print('###',model.__class__.__name__,'###') evaluate_regr(y_test, pred) # end of function get_model_predict # model 별로 평가 수행 lr_reg = LinearRegression() ridge_reg = Ridge(alpha=10) lasso_reg = Lasso(alpha=0.01) for model in [lr_reg, ridge_reg, lasso_reg]: get_model_predict(model,X_train, X_test, y_train, y_test,is_expm1=True)[output]
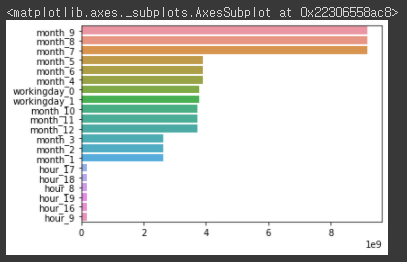
카테고리형 feature에 one-hot 인코딩을 적용한 후 선형 회귀의 예측 성능이 많이 향상되었다. 회귀 계수가 높은 상위 25개 feature를 추출하여 다시 시각화해보겠다.coef = pd.Series(lr_reg.coef_ , index=X_features_ohe.columns) coef_sort = coef.sort_values(ascending=False)[:20] sns.barplot(x=coef_sort.values , y=coef_sort.index)[output]
선형 회귀 모델 시 월 관련 feature와 workingday 관련 feature, hour 관련 feature의 회귀 계수가 높은 것을 알 수 있다. 이처럼 선형 회귀 수행 시에는 feature를 어떻게 인코딩하는 지가 성능 향상에 큰 영향을 미칠 수 있다. 그 다음으로 회귀 트리 모델들을 사용하여 회귀 예측을 수행해보겠다.from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor from xgboost import XGBRegressor from lightgbm import LGBMRegressor # 랜덤 포레스트, GBM, XGBoost, LightGBM model 별로 평가 수행 rf_reg = RandomForestRegressor(n_estimators=500) gbm_reg = GradientBoostingRegressor(n_estimators=500) xgb_reg = XGBRegressor(n_estimators=500) lgbm_reg = LGBMRegressor(n_estimators=500) for model in [rf_reg, gbm_reg, xgb_reg, lgbm_reg]: # XGBoost의 경우 DataFrame이 입력 될 경우 버전에 따라 오류 발생 가능. ndarray로 변환. get_model_predict(model,X_train.values, X_test.values, y_train.values, y_test.values,is_expm1=True)[output]
선형 회귀 모델보다 회귀 예측 성능이 개선되었다. 하지만 이 결과가 회귀 트리가 선형 회귀보다 무조건적으로 더 나은 성능을 가진다는 것은 아니다.