- 데이터는 지저분하고 복잡하며 예측 불가능하고 잠재적으로 위험하기 때문에 데이터 과학자나 ML 엔지니어는 데이터를 제대로 처리하는 방법을 배워야 한다.
- '훈련 데이터셋'이 아닌 '훈련 데이터'라는 용어를 사용하는데, 이는 실제 프로덕션 환경에서의 데이터는 데이터셋과 같이 유한하고 고정적인 집합이 아니기 때문이다.
- ML 시스템 개발 과정에서 훈련 데이터 생성은 반복 프로세스이다. 왜냐하면 프로젝트가 개선된다면 모델과 마찬가지로 훈련 데이터 또한 개선될 가능성이 높기 때문이다.
- 데이터는 수집, 샘플링, 레이블링 등의 과정에서 잠재적인 편향이 발생하기 쉽다. 따라서 데이터를 사용하되 너무 신뢰하면 안된다.
4.1 샘플링
- 샘플링은 ML 위크플로에서 핵심이다. ML 프로젝트 수명 주기 내 여러 단계에서 이뤄지기 때문이다.
- 훈련 데이터를 생성하기 위한 샘플링 방법에 초점을 둔 설명이다.
- 샘플링의 사용 사례 중 하나는 가용한 전체 데이터를 접근하기 어려운 경우이다. 이런 경우엔 모델 훈련을 위해 샘플링으로 실제 데이터의 하위 집합을 생성해 사용해야 한다.
- 또 다른 경우는 전체 데이터를 다루는데 시간과 자원이 너무 많이 소모되는 경우이고, 이 경우엔 샘플링을 통해 처리 가능한 하위 집합을 생성하여 처리한다.
- 하위 집합을 생성하여 처리하는 접근법이 소규모 데이터셋에서 잘 동작하지 않는 대형 모델에서는 해당되지 않는다고 생각할 수 있다. 이런 경우엔 하위 집합의 데이터셋을 크기에 따라 실험해봄으로써 데이터셋 크기가 모델에 미치는 영향을 파악하기 좋다.
- 샘플링의 장점은 잠재적인 샘플링 편향을 피할 수 있고, 데이터의 효율성을 향상하는 샘플링 방법을 적절히 선택할 수 있다.
4.1.1 비확률 샘플링
- 비확률 샘플링은 데이터를 확률이 아닌 기준에 의해 선택하는 방법이다.
- 확률이 아닌 기준으로 선택된 샘플은 실제 데이터를 잘 대표하지 못하고 선택 편향이 강하지만 사용이 편리하다.
편의 샘플링 (Convenience sampling)
- 가용성을 기준으로 데이터 샘플을 선택한다.
- 정보 제공 동의를 한 고객 데이터만 사용하거나 쉽게 크롤링 할 수 있는 데이터만 사용한 식의 방법이다.
눈덩이 샘플링 (Snowball sampling)
- 기본 샘플을 기반으로 미래의 샘플을 선택한다.
- 기존에 가진 데이터 표본을 사용하여 관련된 추가 데이터를 수집하는 방식이다.
- 예를 들어, 초기에 구축한 트위처 계정 데이터를 통해 해당 계정을 팔로우한 계정을 모두 수집하는 방식이다.
판단 샘플링 (Judgement sampling)
- 전문가가 어떤 샘플을 선택할지 결정한다.
할당 샘플링 (Quota sampling)
- 특정 데이터 그룹별 할당량을 기준으로 샘플을 선택한다.
4.1.2 단순 무작위 샘플링
- 가장 단순한 형태의 무작위 샘플링으로 모집단의 각 샘플이 선택될 확률이 모두 동일하다.
- 구현이 쉽지만 아주 드물게 등장하는 데이터는 포함되지 않을 수 있다는 단점이 있다.
4.1.3 계층적 샘플링 (Stratified sampling)
- 모집단을 다른 성질의 그룹으로 나누고 각 그룹에 대해 개별적으로 무작위 샘플링을 수행한다.
- 다중 레이블 작업과 같은 경우에는 활용하기 어렵다.
4.1.4 가중 샘플링 (Weighted sampling)
- 각 샘플의 가중치를 기반으로 선택한다.
- 이 방법은 도메인 전문 지식을 활용하여 모델에 더 가치있는 데이터에 높은 가중치를 부여하는 방식으로 사용될 수 있다.
- 그리고 보유하고 잇는 데이터가 실제 모집단과 다른 분포를 가지고 있다면 도움이 될 수 있다.
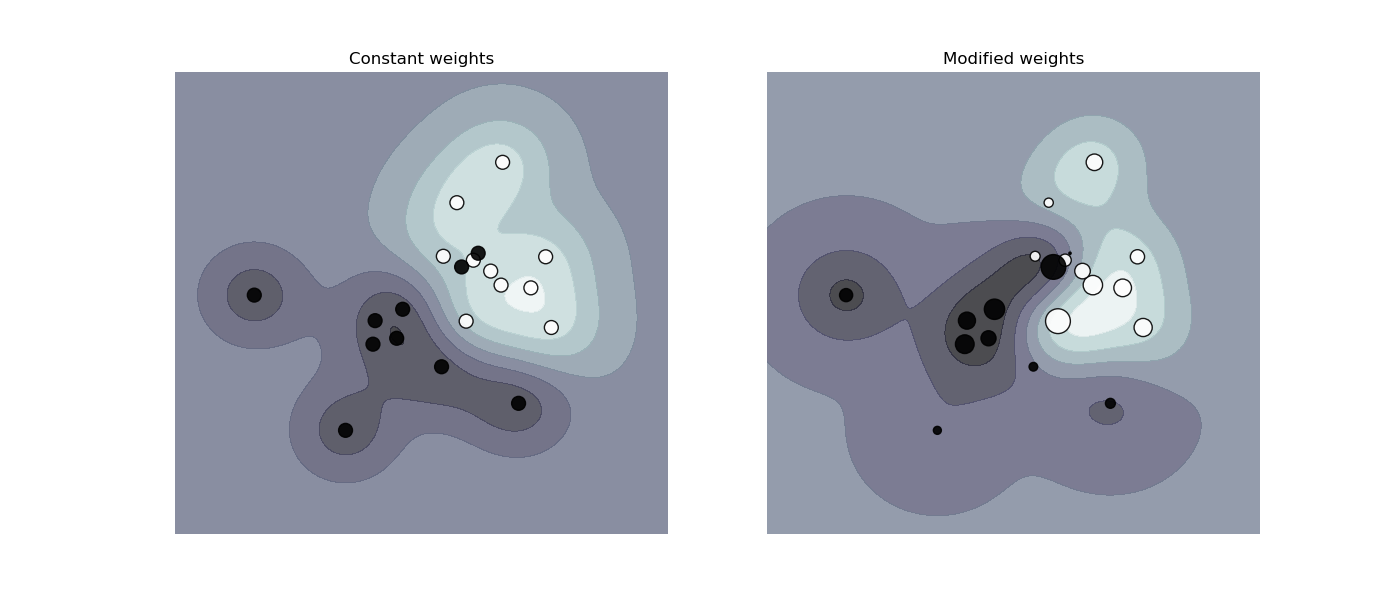
- 가중 샘플링(weighted sampling)은 샘플 가중치(sample weight)와 많이 관련되어 있다. 샘플 가중치는 특정 샘플에 높은 가중치를 부여하여 손실 함수에 더 많은 영향을 미치도록하여 학습에 더 많은 영향을 가지도록 하는 개념이다.
- 샘플 가중치는 아래 그림과 같이 결정 경계 근처의 샘플에 높은 가중치를 부여함으로써 모델의 결정 경계가 크게 변하도록 할 수 있다.
4.1.5 저수지 샘플링 (Reservoir sampling)
- 저수지 샘플링은 프로덕션 환경에서 지속적으로 수집되는 스트리밍 데이터를 처리할 때 유용하다.
- 스트리밍 데이터에서 샘플을 선택하는 요구사항은 다음과 같다.
- 각 데이터가 선택될 확률은 동일해야 한다.
- 스트리밍 데이터의 수집이 언제 멈추더라도 각 샘플은 올바른 확률(동일한 확률)로 샘플링되어야 한다.
- 위 요구사항을 만족하는 솔루션 중 하나가 저수지 샘플링이다.
- 먼저 처음 k개의 데이터를 샘플로 선택한다.
- k개 이후 n번째 데이터가 수집될 때마다 1~n 사이의 난수 i를 생성한다.
- i가 1~k 사이의 수로 생성됬다면 i번째 샘플과 n번째 데이터를 교체한다.
- 위 샘플링으로 언제든지 스트리밍 데이터의 수집이 멈추더라도 모든 샘플은 올바른 확률도 샘플링될 것이다.
4.1.6 중요도 샘플링 (Important sampling)
- 중요도 샘플링은 원하는 분포가 아닌 다른 확률 분포만 사용 가능한 상황에서도 원하는 확률 분포에서 샘플링을 수행할 수 있다,
- 원하는 확률 분포 P(x)는 샘플링 비용이 크고 느리기 때문에 활용이 어렵다.
- 반면에 확률 분포 Q(x)는 샘플링이 훨씬 쉽다.
- 그렇다면 Q(x)로 샘플링 후 각 샘플에 P(x)/Q(x)의 가중치를 부여한다.
- 여기서 Q(x)는 제안 분포(Proposal distribution) 혹은 중요도 분포(Importance distribution)이라고 부른다.
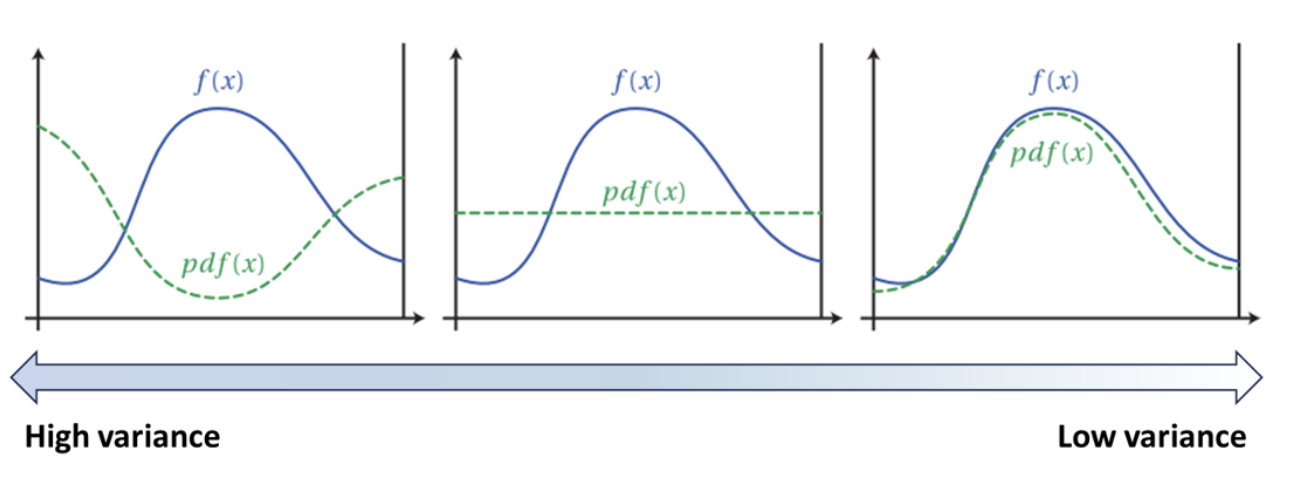
- 아래 이미지의 왼쪽 그래프와 같이 실제 분포 혹은 원하는 분포인 f(x)가 예측 분포 혹은 학습 데이터 분포인 pdf(x)와 차이가 많이 나는 경우에 높은 variance를 가지게 된다.
- 가운데 그래프는 uniform distribution에 맞춰 샘플링한 결과이다.
- 만약 실제로 가지고 있는 데이터가 오른쪽 이미지의 pdf(x)와 같아서 f(x)에 맞춰서 샘플링하는데 많은 비용이 드는 경우라면 중요도 샘플링을 통해 왼쪽과 같이 바꿔줌으로써 variance를 낮출 수 있다.
4.2 레이블링
4.2.1 수작업 레이블
- 수작업 레이블을 얻는 일은 매우 어렵다.
- 비용이 크다. 도메인 전문가가 필요한 경우는 비용이 더욱 커진다.
- 데이터 개인 정보 보호 문제를 야기한다. 온프레미스 환경에서는 더욱 그렇다.
- 느리다.
레이블 다중성
- 레이블이 지정된 데이터를 얻기 위해 여러가지 소스와 여러 어노테이터에 의존한다.
- 하지만 이는 레이블의 모호성이나 레이블 다중성 문제를 야기할 수 있다.
- 이를 해결하기 위해선 레이블 규칙, 문제를 명확하게 정의할 필요가 있다. 하지만 도메인 전문 지식 수준이 높을수록 문제 정의는 어려워진다.
데이터 계보 (Data lineage)
- 데이터 계보 기법은 잠재적 편향이 발생할 수 있는 부분에 플래그를 할당하여 모델 디버깅에 도움을 주는 방법이다.
- 자주 발생하는 문제는 추가로 수집한 데이터의 잘못된 레이블로 인해 모델 성능이 하락하는 경우이다.
4.2.2 자연 레이블
- 자연 레이블은 자연적으로 ground truth 레이블이 존재하는 경우이다.
- 이동 경로 소요 시간 예측, 주가 예측, 추천 시스템, 피드백과 같은 경우가 있다.
- 자연 레이블의 대표적인 예는 추천 시스템이고, 추천 시스템과 같이 사용자의 행동에서 얻어지는 레이블은 행동 레이블(behavioral label)이라고 부른다.
- 양성 레이블의 부재를 통해 추정으로 얻어지는 음성 레이블은 암시적 레이블(implicit label), 반대로 사용자가 명시적으로 피드백을 주어 얻어지는 레이블은 명시적 레이블(explicit label)로 부른다.
피드백 루프 길이
- 피드백 루프 길이는 예측을 수행한 시점부터 피드백을 얻는 시점까지 걸린 시간이다.
- 피드백을 포착할 window 길이는 속도와 정확도 사이의 트레이드 오프가 있기 때문에 결정하기 어렵다.
- window 길이가 짧다면,
- 레이블을 빨리 얻을 수 있고, 모델의 문제를 조기에 발견하고 빠르게 해결할 수 있다.
- 하지만 길이가 짧은 만큼 너무 이른 시점에 사용자가 어떤 행동을 취하지 않았다고 레이블을 잘못 지정해줄 수 있다.
- window 길이가 길다면,
- 몇 주 혹은 몇 달 동안 레이블을 얻지 못할 수 있어서 모델 결함을 빠르게 발견해야 하는 경우라면 문제가 될 수 있다.
- 분기별이나 연간 비즈니스 보고서를 통해 모델 성능을 보고하는 데는 도움이 된다.
4.2.3 레이블 부족 문제 해결하기
- 고품질 레이블을 얻는 것은 어렵기 때문에 이를 해결하기 위한 기술들이 개발되었다.
약한 지도 학습 (Weak supervision)
- 약한 지도 학습은 수작업 레이블을 하지 않고 도메인 전문 지식을 활용한 휴리스틱인 레이블링 함수(labeling function, LF)를 사용하여 레이블을 생성한다.
| 유형 | 설명 |
|---|---|
| 키워드 휴리스틱 | 특정 키워드의 포함 여부로 레이블을 결정한다. |
| 정규 표현식 | 특정 정규 표현식과 일치 여부로 레이블을 결정한다. |
| 데이터베이스 조회 | 사전에 구축된 DB의 정보를 통해 특정 여러 키워드를 얻은 뒤 포함 여부로 레이블을 결정한다. |
| 다른 모델의 출력 | 기존의 시스템의 출력을 레이블로 사용한다. |
- LF로 생성한 레이블은 노이즈가 수반되기 때문에 다수의 LF로 생성한 레이블 중 상충하는 레이블을 선택하기도 한다.
- 이론상 LF는 수작업 레이블이 필요하지 않지만 LF가 얼마나 정확한지 파악하려면 약간의 수작업 레이블은 필요하다.
- 개인 정보 보호 요구 사항이 엄격하게 적용될 때, 일부 데이터만 확인해서 LF를 만들고 나머지 데이터에 비공개로 적용하는 방식으로 사용하면 유용하다.
- LF를 사용하여 데이터 레이블을 생성하는 접근법을 프로그래밍 방식 레이블링이라고 한다.
| 수작업 레이블링 | 프로그래밍 방식 레이블링 |
|---|---|
| 높은 비용 | 낮은 비용 |
| 개인 정보 보호 부족 | 개인 정보 보호 |
| 느린 속도 | 빠른 속도 |
| 비적응적 | 적응적 |
- LF가 잘 동작한다고 하더라도 ML 모델이 필요한 이유는 완벽하지 못하기 때문에 약간 지도 학습으로 얻은 레이블을 실제로 적용하기엔 노이즈가 너무 많다.
준지도 학습 (Semi-supervision)
- 준지도 학습은 구조적인 가정을 활용해서 초기 수집한 소수의 레이블을 기반으로 새로운 레이블을 생성한다. 따라서 초기 수집한 레이블 집합이 필요하다.
- 대표적인 준지도 학습은 자가 훈련(self-traininig)으로, 기본 레이블 데이터로 모델을 학습한 뒤 해당 모델로 나머지 데이터의 레이블을 예측한 뒤 다시 모델을 학습한다.
- 또 다른 준지도 학습은 유사한 특성이 있는 데이터끼리는 동일한 레이블을 가진다고 가정하는 것이다. 유사성을 찾으려면 클러스터링이나 k-최근접 이웃 알고리즘과 같은 복잡한 방법을 적용한다.
- 교란(perturbation) 기반 준지도 학습 방법은 데이터에 작은 교란 신호를 더해도 레이블이 변하지 않아야한다고 가정한다. 따라서 훈련 데이터에 작은 교란 신호를 더해 새로운 훈련 대상 샘플을 얻는다.
- 준지도 학습은 훈련할 레이블 데이터 개수가 제한적일 때 가장 유용한데, 제한된 데이터 중 얼마만큼을 학습과 평가에 사용할지 고려해야 한다.
전이 학습 (Transfer learning)
- 전이 학습은 특정 작업을 위해 개발한 모델을 시작점으로 삼아 후속 작업에 재사용하는 방법론이다.
- 먼저, 일반적으로 훈련 데이터가 많고 수집 비용이 적은 기본적인 작업을 대상으로 레이블링 없이 학습한 뒤, 관심 있는 다운스트림 작업의 데이터로 이어서 학습하는 미세 조정(fine-tuninig)을 진행한다.
- 사전 훈련한 모델을 사용하면 처음부터 다운스트림 테스크로 학습한 모델보다 더 성능이 향상되기 때문에 전이 학습은 레이블링된 데이터가 많이 않은 작업에 특히 적합하다.
능동적 학습 (Active learning)
- 능동적 학습은 데이터 레이블링 작업의 효율성을 향상시킨다. ML 모델이 능동적으로 학습할 데이터를 선택함으로써 더 적은 학습 레이블로 더 높은 성능을 가져올 수 있는 방법이다.
- 모델에 가장 필요한 데이터는 무작위가 아닌 특정 지표나 휴리스틱에 근거하여 선택한다.
- 가장 간단한 지표는 불확실성이다. 결정 경계 근처에 있는 가장 불확실성이 높은 데이터를 선택하여 학습을 더 잘하도록 한다.
- 다양한 후보 모델 간의 불일치를 기반으로 데이터를 선택하기도 한다.
- 학습할 때, 그래디언트가 가장 크거나 손실을 가장 크게 줄이는 샘플을 선택하는 방법도 있다.
4.3 클래스 불균형 문제
- 클래스 불균형이란 일반적으로 분류 작업에서 나타나는 문제로, 훈련 데이터 내 클래스당 데이터 개수가 크게 차이 나는 문제를 의미한다.
- 회귀 작업에서는 추정할 값의 분포가 크게 치우쳐 있는 경우이다.
4.3.1 클래스 불균형 문제의 어려움
- 적은 수의 클래스를 선택하기 위한 학습을 하기에 충분하지 않다.
- 모델이 데이터의 패턴을 학습하지 않고 단순하게 많은 수의 데이터를 가지는 클래스를 선택하려는 경향이 강해진다.
- 비대칭적인 오차 비용 문제로 인해 모델은 적은 수의 데이터를 가지는 클래스를 선택하지 않는다.
- 일반적이진 않지만 레이블링 오류도 클래스 불균형을 야기할 수 있다. 따라서 클래스 불균형 문제에 부딪힐 경우, 데이터를 분석하여 원인을 이해하는 과정이 중요하다.
4.3.2 클래스 불균형 처리하기
- 클래스 불균형은 문제의 복잡도에 따라 증가하며, 복잡도가 낮고 선형으로 분리 가능한 문제는 불균형 정도에 상관없이 영향받지 않는다.
- 한편으로는 클래스 불균형이 데이터가 실제로 나타내는 모습일 수 있기 때문에 좋은 모델이라면 불균형을 학습해야 한다고 주장한다. 하지만 그런 모델을 개발하는 것은 어렵기 때문에 클래스 불균형을 처리할 특별한 훈련 기법에 의존할 수 밖에 없다.
올바른 평가 지표 사용하기
- 전체 정확도와 오차 비율은 ML 모델의 성능을 평가하는데 가장 자주 사용하는 지표이지만 모든 클래스를 동일하게 취급하므로 클래스 불균형이 있는 작업을 다룰 때는 적절하지 않다.
- 정밀도(Precision), 재현율(Recall), F1은 비대칭 지표로 각 클래스와 관련된 모델 성능을 측정하는 지표이다.
- 보통 0.5의 임계값(threshold)을 사용하여 클래스를 분류한다. 이 임계값을 조정하면 True Positive Rate(TPR)를 늘리거나 False Positive Rate(FPR)를 낮출 수 있고, 그 반대도 가능하다. 이렇게 임계값을 바꿔가며 그린 TPR과 FPR에 대한 곡선을 Receiver Operating Characteristic(ROC) 곡선이라고 한다.
- True Positive Rate(TPR)
- 실제 positive인 경우 중 positive로 잘 예측한 비율
- False Positive Rate(FPR)
- 실제 negative인 경우 중 positive로 잘못 예측한 비율
- 임계값이 0이면, 전부 positive로 예측하기 때문에
- TPR은 1, FPR도 1이다.
- 임계값이 1이면, 전부 negative로 예측하기 때문에
- TPR은 0, FPR도 0이다.
- True Positive Rate(TPR)
- ROC 커브는 임계값에 따라 모델의 성능이 어떻게 변하는지 보여주므로 가장 적절한 임계값을 선택하는데 도움이 된다.
- Area Under the ROC Curve(AUC)는 ROC 커브의 아래 면적을 의미한다. 성능이 좋을 수록 ROC 커브는 직선에 가까워지므로 AUC는 클수록 좋고, 최대값은 1이다.
- ROC 커브는 양성 클래스만 고려하고 있기 때문에 음성 클래스에서 얼마나 잘 동작하는지 나타내지 않는다. 그래서 ROC 커브 대신 정밀도-재현율(P-R) 곡선을 그려봐야 한다는 제안도 있다.
데이터 수준의 방법: 리샘플링
- 리샘플링은 다수 클래스에서 데이터를 제거하는 언더샘플링과 소수 클래스에 데이터를 추가하는 오버샘플링이 있다.
- 가장 간단한 언더샘플링은 무작위로 다수 클래스의 데이터를 제거하는 것이고, 가장 간단한 오버샘플링 역시 소수 클래스의 복사본을 무작위로 생성하는 것이다.
- 저차원 데이터를 언더샘플링하는 방법으로는 토멕 링크가 있다. 서로 반대되는 클래스에서 근접한 데이터 쌍을 찾아서 각 쌍에서 다수의 클래스 데이터를 제거하는 방식이다.
- 저차원 데이터를 오버샘플링하는 방법으로는 SMOTE(Synthetic Minority Over-sampling Technique)이 있다. 소수 클래스 내의 기존 데이터에 대한 볼록 조합(convex combination) 샘플링으로 새로운 데이터를 합성하는 방법이다.
- 토멕 링크나 SMOTE는 각 데이터나 데이터와 결정 경계 사이의 거리를 계산해야 해서 고차원의 데이터에서는 비용이 너무 커서 실행이 불가능하다.
- 리샘플링된 데이터로 학습을 했다면 리샘플링란 분포에 과적합되어 있을 수 있기 때문에 리샘플링된 데이터로 평가까지 진행하면 안된다.
- 언더샘플링은 중요 데이터가 손실될 위험이 있고, 오버샘플링은 학습 데이터에 과적합될 위험이 있다.
- 2단계 학습은 이러한 문제를 완화하기 위한 샘플링 기법 중 하나이다.
- 먼저, 언더샘플링한 데이터로 모델을 학습한다.
- 그런 다음 원래 데이터로 모델을 미세 조정한다.
- 다른 기법으로는 학습을 진행하면서 성능이 낮은 클래스를 오버샘플링하고, 성능이 높은 클래스는 언더샘플링하는 방식인 동적 샘플링이 있다.
알고리즘 수준의 방법
- 알고리즘 수준의 방법은 학습 데이터 분포를 그대로 유지하면서 클래스 불균형에 더 강건한 모델로 학습하는 방법으로 대부분 손실 함수(비용 함수, loss)를 조정한다.
비용 민감 학습
- 각 클래스를 다른 클래스로 잘못 예측하는 경우의 수에 따라 가중치를 조절하여 loss를 계산한다.
- 문제는 가중치를 계산하기 위한 비용 행렬을 수작업으로 정의해야 한다.
클래스 균형 손실
- 각 클래스의 가중치를 각 클래스의 데이터 수에 반비례하게 만드는 방법이다.
초점 손실 (Focal loss)
- 클래스 별 개수와는 별개로 어떤 데이터는 쉽게 분류가 가능하여 모델이 빠르게 학습하는 경우가 있다. 따라서 focal loss는 모델이 분류하기 어려운 데이터에 집중하도록 가중치를 준다.
4.4 데이터 증강
- 데이터 증강은 학습 데이터 양을 늘리는 데 사용하는 기법이다.
4.4.1 단순 레이블 보존 변환
- 가장 간단한 방법은 기존 레이블을 유지한 채 데이터를 무작위로 수정하는 방법이다.
4.4.2 교란
- 일반적으로 모델은 노이즈에 민감하다. 데이터에 노이즈를 추가하여 속임수가 있는 데이터를 사용해 모델이 잘못된 예측을 하도록 유도하는 것을 적대적 공격이라고 하며, 데이터에 노이즈를 추가하는 것은 적대적 데이터를 생성하는 일반적인 방법이다.
- 학습 데이터에 노이즈를 추가하면 결정 경계의 약점을 인식하고 성능을 개선하는데 도움이 된다.
- 노이즈는 무작위로 추가하거나 DeepFool과 같은 탐색 전략을 통해 생성 가능하고, 이러한 증강을 적대적 증강이라고 한다.
4.4.3 데이터 합성
- 데이터 수집은 느리고 비용이 크고 개인 정보 보호 문제가 있을 수 있다.
- 합성 데이터는 일부 학습 데이터를 합성해 모델 성능을 올리는 방법이다.

NLP, AI, LLM, MLops