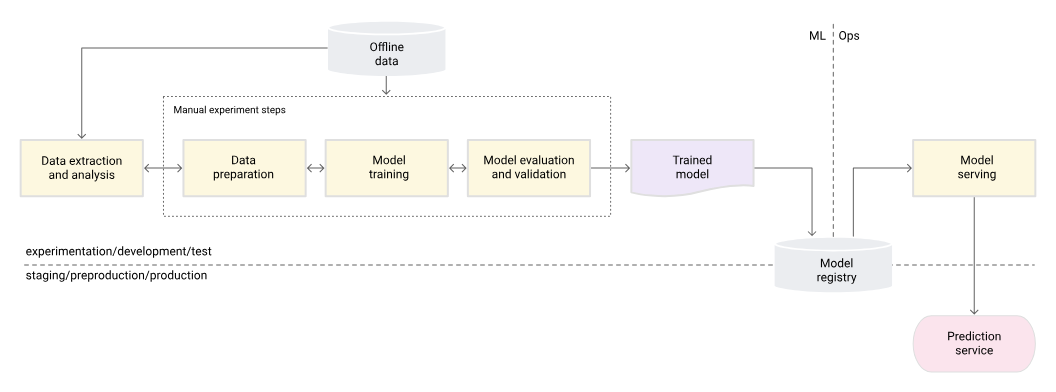
배포(deploy)는 일반적으로 '모델을 실행하고 액세스 가능하게 함'을 의미하는 포괄적인 용어 이다.
7.1 머신러닝 배포에 대한 통념
- ML 모델 배포는 전통적인 소프트웨어 프로그램을 배포하는 일과 매우 다르다.
- 따라서 배포 경험이 적거나 전혀 없는 분들에게 유용할 수 있다.
7.1.1 통념 1: 한 번에 한두 가지 머신러닝 모델만 배포합니다.
- 실제 어플리케이션에서는 한두 가지 모델만 지원하지 않고, 각 기능마다 자체 모델이 필요하다.
- 따라서 여러 모델을 한번에 학습시키거나 배포하는 과정은 필요하다.
7.1.2 통념 2: 아무것도 하지 않으면 모델 성능은 변하지 않습니다.
- software rot나 bit rot는 시간에 따라 소프트웨어 프로그램이 아무런 변화가 없어 보임에도 성능이 저하되는 현상을 의미한다.
- ML 시스템에서는 프로덕션에서 접하는 데이터 분포가 학습된 데이터 분포와 다른 data distribution shift 문제를 겪는다.
- 따라서 모델은 지속적으로 업데이트 되어야한다.
7.1.3 통념 3: 모델을 자주 업데이트할 필요 없습니다.
- 모델 성능은 시간에 따라 저하되므로 최대한 빨리 업데이트해야 합니다.
7.1.4 통념 4: 대부분의 머신러닝 엔지니어는 스케일에 신경 쓰지 않아도 됩니다.
- 스케일은 초당 수백 개의 쿼리를 처리하거나 한 달에 수백만 명의 사용자를 처리하는 것을 의미한다.
- 통계적으로 보면 ML 엔지니어도 스케일을 신경써야한다.
- Continuous batching
- 참고: TGI, vLLM
7.2 배치 예측 vs 온라인 예측
- 온라인 예측: 요청이 도착하는 즉시 예측이 생성되고 반환되는 경우 (동기 예측)
- 배치 예측: 예측이 주기적으로 혹은 트리거될 때마다 생성되는 경우 (비동기 예측)
- 배치 피처: DB나 데이터 웨어하우스의 데이터 같은 과거 데이터에서 계산된 피쳐이다.
- 스트리밍 피처: 스트리밍 데이터에서 계산된 피처, 실시간 전송 데이터
- 온라인 피처: 온라인 예측에서 사용되는 모든 피처
- 배치 예측은 배치 피처만 사용할 수 있지만 온라인 예측은 배치 피처와 스트리밍 피처를 모두 사용할 수 있다.
- 일부 기업에서는 스트리밍 피처를 사용하지 않는 온라인 예측과 구분하기 위해 스트리밍 피처를 사용하는 온라인 예측을 스트리밍 예측이라고 부른다.
7.2.1 배치 예측에서 온라인 예측으로
- 온라인 예측은 동기 예측이기 때문에 구현이 쉽다. 하지만 모델이 예측을 생성하는데 너무 오래 걸릴 수 있다는 문제가 있다.
- 배치 예측은 모델 예측을 미리 생성하고 DB에 저장해서 가져오기 때문에 레이턴시가 줄어든다. 따라서 예측 결과가 바로 필요하지 않을 때 유용하다.
- 하지만 배치 예측은 사용자의 선호도 변화에 덜 민감하다는 문제가 있다.
- 또한 생성해야하는 예측을 미리 알아야한다.
- 따라서 배치 예측은 온라인 예측이 충분히 저렴하지 않거나 충분히 빠르지 않을 때 유용합니다.
- 하드웨어와 기술이 발전함에 따라 더 빠르고 저렴한 온라인 예측이 가능해지면서 온라인 예측이 기본이 되었다.
7.2.2 배치 파이프라인과 스트리밍 파이프라인의 통합
- 배치 예측은 대부분 레거시 시스템의 산물이다. 맵리듀스나 스파크 같은 배치 시스템으로 대량의 데이터를 효율적이고 주깆거으로 처리하면서 ML에서도 기존 배치 시스템을 활용해서 예측을 수행했다. 이런 경우에 온라인 예측에 스트리밍 기능을 사용하려면 별도의 스트리밍 파이프라인을 구축해야 한다.
- 학습과 추론 파이프라인이 나눠져 있으면 한 파이프라인의 변경 사항이 다른 파이프라인에 적용되지 않아 버그가 생길 수 있다. 온라인 예측을 수행하는 ML 시스템 데이터 파이프라인에서 이러한 버그가 생기지 않으려면 스트림 처리와 배치 처리를 통합하기 위한 인프라를 구축해야한다.
7.3 모델 압축
- 추론 레이턴시를 줄이기 위해선 추론을 더 빠르게 하거나, 모델을 더 작게 만들거나, 배포된 하드웨어가 더 빠르게 실행하도록 하는 접근 방식이 있다.
- 모델 압축은 모델을 작게 만드는 과정이고, 추론 최적화는 추론을 더 빠르게 하는 과정을 말한다.
7.3.1 저차원 인수분해
- low-rank factorization은 고차원 텐서를 저차원 텐서로 대체하는 것이다.
- SqueezeNet
- 3x3 convolution filter를 1x1로 대체
- ModileNet
- Depthwise convolution을 pointwise convolution으로 분해
- Grouped query attention
7.3.2 지식 증류
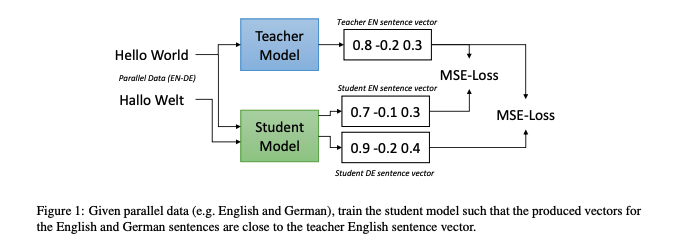
- knowledge distillation은 작은 student model이 더 큰 모델이나 앙상블 형태인 teacher model을 모방하도록 학습하는 방법
- Distilbert
- Bert 보다 매개변수가 40% 적지만 NLU 성능은 97% 유지하고 60% 더 빠르다.
- Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
7.3.3 가지치기
- pruning은 decision tree에서 중요도가 낮은 tree section을 제거하는 방법
- 신경망에서는 전체 노드를 제거하여 아케텍쳐를 변경하거나 예측에 가장 덜 유용한 매개변수를 찾아 0으로 설정하는 방식
7.3.4 양자화
- quantization은 가장 일반적이며 많이 사용되는 모델 압축 방법으로, 매개변수를 나타내는 데 더 적은 비트를 사용함으로써 모델 크기를 줄이는 방법
- 양자화는 메모리를 줄일 뿐 아니라 계산 속도도 향상시킬 수 있다.
- 배치 사이즈를 늘릴 수 있다.
- precision이 낮을수록 계산 속도가 빨라져 학습이나 추론 시간이 빨라진다.
- 단점은 비트수를 줄이면 원래 숫자와 오차가 발생하는데 이 오차가 성능에 큰 영향을 끼칠 수 있다.
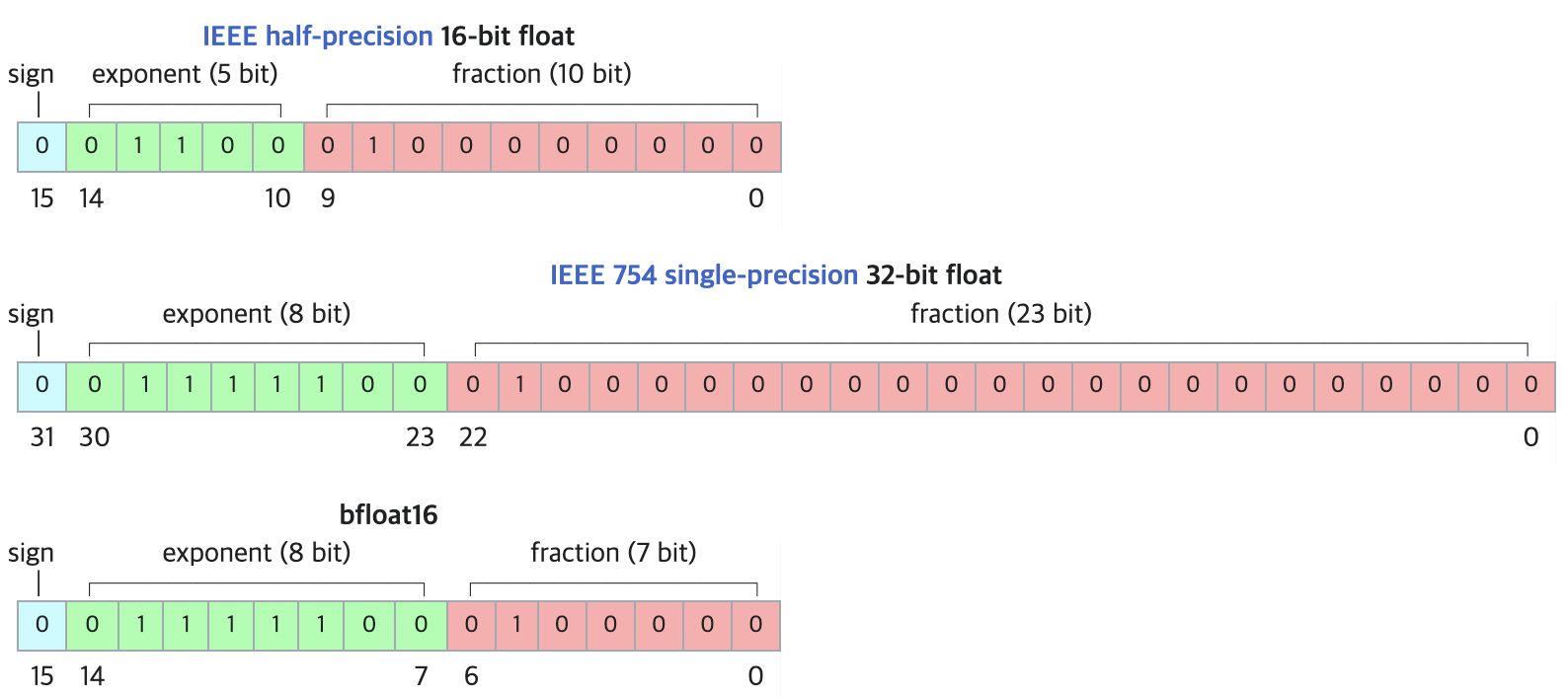
- fp16 vs bf16
- 관련 프레임워크
- Tensorflow Lite, Pytorch Mobile, TensorRT
7.4 클라우드와 에지에서의 머신러닝
- 클라우드: AWS, GCP, Azure와 같은 관리형 클라우드 서비스
- 장점: 배포가 쉽다.
- 단점: 많은 비용
- 에지 디바이스: 브라우저, 헨드폰, 노트북 등의 사용자 기기
- 장점: 적은 비용, 인터넷 연결이 불필요, 네트워크 레이턴시 우려가 없음, 민감한 사용자 데이터 처리
- 단점: 에지 디바이스가 ML 모델을 처리하기 위한 충분한 메모리, 베터리 필요
7.4.1 에지 디바이스용 모델 컴파일 및 최적화
- 하드웨어에서 프레임워크에 대한 지원을 가능하도록 엔지니어링 하는 것은 어렵고, 시간이 많이 걸린다. 따라서 IR(Intermediate Representation)을 통해 직접 개발하지 않고 프레임워크와 소프트웨어 플랫폼을 연결한다.
- 모델의 원래 코드에서 컴파일러는 하드웨어 백엔드에 네이티브 코드를 생성하기 전에 일련의 고수준 및 저수준 IR을 생성한다. 이 프로세스는 고수준의 프레임워크를 저수준의 하드웨어 네이티브 코드로 낮춘다는 의미로 lowering이라도 부른다.
- 고수준의 IR은 일반적으로 ML 모델의 계산 그래프이다.
모델 최적화
- lowering을 하게 되면 실행은 될 수 있지만 효율적으로 실행되지 않아 성능 문제가 발생할 수 있다. 따라서 많은 회사들은 하드웨어에 맞춰 최적화하기 위해 최적화 엔지니어를 고용한다.
- ML 모델을 최적화 하는 방법
- 로컬 최적화: 모델의 연산자 또는 연산자 집합을 최적화
- 벡터화(Vectorization)
- 루프나 중첩 루프가 있는 경우에 메모리에서 인접한 여러 요소를 동시에 실행해 레이턴시를 줄임
- 병렬화(Parallelization)
- 입력이 주어지면 독립적인 청크 단위로 나눠서 개별적으로 처리
- 루프 타일링(Loop tiling)
- 루프에서 데이터 액세스 순서를 바꿔 하드웨어의 메모리 레이아웃과 캐시를 활용함
- 연산자 융합(Operator fusion)
- 중복 메모리 액세스를 방지하기 위해 여러 연산자를 하나로 통하
- 벡터화(Vectorization)
- 전역 최적화: 전체 계산 그래프를 end to end로 최적화
- 수직 융합
- 수평 융합
- 로컬 최적화: 모델의 연산자 또는 연산자 집합을 최적화
머신러닝을 사용해 머신러닝 모델 최적화하기
- 최적화 엔지니어의 휴리스틱 최적화는 단점이 있다.
- Nonoptimal(비최적): 최선의 해결책이 아닐 수 있다.
- Nonadaptive(비적응): 신규 프레임워크나 하드웨어에도 적용하려면 다시 비용을 들여야한다.
- cuDNN 자동 튜닝
- 합성곱 연산자 자동 튜닝
- autoTVM
- 하드웨어에 맞춘 학습으로 어떤 유형의 하드웨어에서 실행되던 적응이 가능하다.
7.4.2 브라우저에서의 머신러닝
- 브라우저에서 실행할 경우엔 하드웨어를 신경쓰지 않아도 된다.
- WASM(WebAssembly)는 다양한 언어로 작성된 프로그램을 웹 브라우저상에서 실행하도록 해주는 개방형 표준이다.
- 모델을 빌드하고 특정 하드웨어에 맞춰 컴파일하는 대신 WASM으로 컴파일한다.
- 단점은 브라우저에서 실행되기 때문에 속도가 느리다.

NLP, AI, LLM, MLops