LLaMA: Open and Efficient Foundation Language Models
1. Introduction
- 대규모 말뭉치 텍스트로 학습된 LLM은 instuction과 few shot이 주어진 새로운 task에 대해 좋은 성능을 보여주었다.
- few shot 속성은 모델을 충분한 크기로 확장할 때 처음 등장하였기 때문에 이러한 모델을 추가로 확장하는 데 중점을 둔 작업 라인을 만들었습니다.
- scale up을 쉽게 하기 위한 작업: transformer의 encoder와 decoder를 쌓는 방식
- Scaling Laws for Neural Language Models
- Chinchilla 모델을 제안한 논문
- 위 논문에서 제안한 스케일링 법칙의 목적은 특정 training 컴퓨팅 budget(FLOPs)에 대해 데이터 세트와 모델 크기를 가장 잘 확장하는 방법을 결정하는 것입니다.
- 결과적으로 모델 크기, 데이터 및 컴퓨팅을 적절하게 확장함에 따라 언어 모델링 성능이 원활하고 예측 가능하게 향상됨을 보여준다고 함.
- 그리고 더 큰 언어 모델이 현재 모델보다 더 나은 성능을 발휘하고 샘플 효율적일 것이라고 얘기함.
- Training Compute-Optimal Large Language Models
- 하지만 위 논문의 연구에서는 주어진 컴퓨팅 예산에 대해 가장 큰 모델이 아니라 더 많은 데이터로 훈련된 더 작은 모델이 최고의 성능을 발휘할 수 있다고 한다.
- model size가 성능 향상에 제일 큰 영향을 준다는 기존의 스케일링 법칙을 따른 model들은 model size만 과도하게 키웠고, 그 결과로 현재 LLM 들은 상당히 undertrained 되었다.
- 그리고 이 모델들은 대규모 언어 모델을 제공할 때 중요해지는 inference budget을 무시한다.
- 우리가 선호하는 모델은 training보다는 inference가 가장 빠른 모델이다. 그리고 일반적으로 모델 사이즈가 작으면 inference가 더 저렴하다.
- 따라서 이 논문에서는 더 많은 데이터를 학습시켜서 (더 많은 토큰을 학습에 사용하여) inference budgets에서 가능한 최고 성능을 얻는 것이 목적이다.
- Training Compute-Optimal Large Language Models 논문에서는 200B 토큰에 대해 10B 모델을 훈련할 것을 권장하지만, llama 7B 모델의 성능은 1T 토큰 이후에도 계속 향상된다.
- LLaMA-13B는 10배 더 작음에도 불구하고 대부분의 벤치마크에서 GPT-3보다 성능이 뛰어나다.
- LLaMA-65B는 Chinchilla-70B나 PaLM-540B와 같은 대형 언어 모델과도 경쟁력이 있습니다.
2. Approach
- 학습 방식은 GPT3와 유사하며 Chinchilla 스케일링 법칙에서 영감받았다.
2.1 Pre-training Data
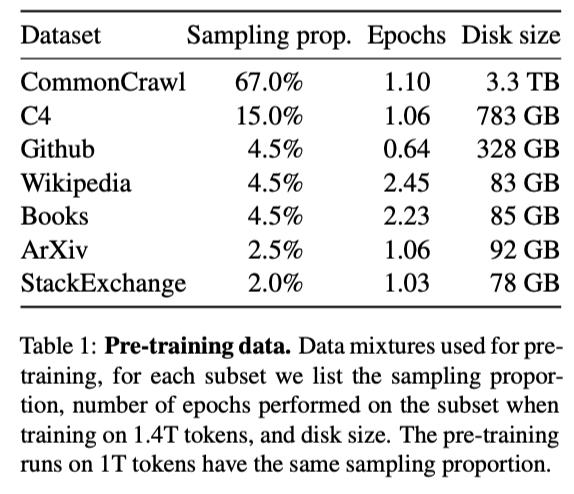
- 공개적으로 사용 가능하고 오픈 소스와 호환되는 데이터만 사용했다.
English CommonCrawl
- CCNet 파이프라인으로 전처리
- line 중복 제거
- fastText language detection 모델로 영어가 아닌 page 제거
- n-gram language model로 낮은 퀄리티의 content 제거
- classification 모델을 만들어서 references in Wikipedia를 분류
- Wikipedia와 Books domains은 대략 2 epoch, 나머지는 1 epoch 학습
C4
- 전처리된 다양한 CommonCrawl datasets이 성능을 향상시킴
- 따라서 공개된 C4 데이터셋을 추가함
- C4 datasets은 public Common Crawl web scrape에서 영어 텍스트 데이터셋
Github
- Apache, BSD, MIT licenses만 사용
- line length 나 알파벳과 숫자 조합의 비율에 기반한 휴리스틱 방법으로 낮은 퀄티티의 파일을 제거
- 정규표현식으로 반복되거나 흔하게 자주 사용되는 문구 제거
- 파일 수준에서 exact match로 제거
Wikipedia
- 20개 언어의 위키 데이터
- 하이퍼링크, 주석 및 그 외 boilerplate 제거
Gutenberg and Books3
- Gutenberg Projec과 Books3 section of ThePile
- book 수준에서 90% 이상 일치하는 중복 제거
ArXiv
- scientific arXiv latex data
- 첫 섹션 전 내용 모두 제거
- 관련 서적 목록, 참고 도서 제거
- 주석 제거
Stack Exchange
- 다양한 도메인의 높은 퀄리티를 가지는 Stack Exchange 사이트의 QA 데이터
- HTML tags 제거
- 높은 점수 순으로 답변 정렬
Tokenizer
- Sentence-Piece의 BPE 알고리즘으로 tokenization
- tokenization 후 전체 데이터는 약 1.4T 토큰
2.2 Architecture
- Transformer 기반
Pre-normalization [GPT3]
- On Layer Normalization in the Transformer Architecture
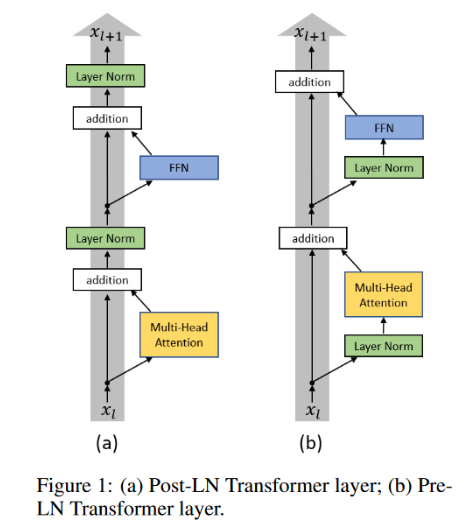
- transformer의 구조는 다양한 표현력을 가지고 있어 학습이 잘 된다면 좋은 성능을 낼 수 있지만 실제 학습에서는 learning rate에 대해 굉장히 민감하다.
- 학습 초기의 높은 learning rate가 gradient 폭발이나 0으로 수렴하는 문제를 만듬
- 이러한 현상은 post layer normalization(post-ln) 구조가 output layer의 gradient 기댓값을 매우 크게 만들기 때문이다.
- preLN에서는 normalize 후에 더하니까 layer가 쌓일수록 activation(relu)의 크기가 점점 커지고, 여기다 layer norm의 scaling이 들어가면서 PostLN에 비해서 gradient의 scale이 작아진다고 볼 수 있겠다.(?)
- 그렇기 때문에 warm up이 필수적이고, warm up이 없으면 학습이 굉장히 불안정해진다.
- 하지만 warn up은 학습을 더 느리게 만들고, 추가 하이퍼 파라미터 튜닝을 하도록 만든다.
- 따라서 mean field theory를 이용하여 LN의 위치를 바꿔서 pre-ln 구조를 사용하면 더 빠른 학습 속도를 가지면서 비슷한 성능을 낼 수 있음
- Mean Field Theory (MFT)
- fluctuation을 없애는 분석 방법
- 어떤 하나의 대상에 대한 모든 상호작용을 효과적인 또는 평균적인 하나의 상호작용으로 대체하는 방법
- 상대적으로 적은 Cost로 대상의 상호작용에 대한 어떤 통찰이 얻어 질 수 있음
- 위 논문에서는 gradient 값의 기댓값에 대한 fluctuation을 없애는 목적으로 pre-ln과 post-ln 차이 비교
- Layer Normalization
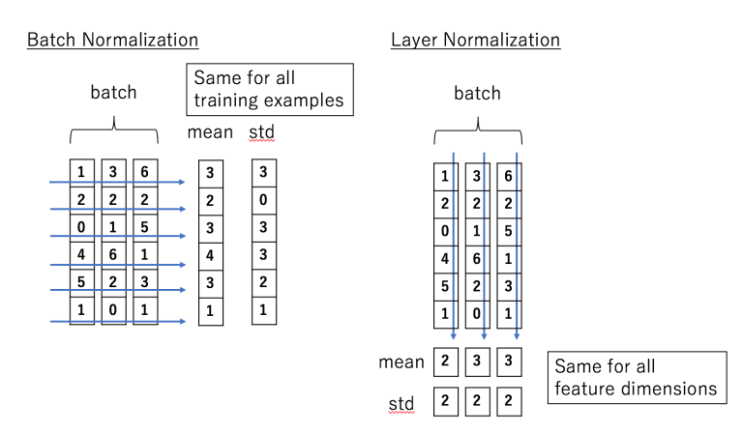
- batch size에 상관없이 모든 batch에 있는 각 feature의 평균과 분산을 구하여 normalization
- 각 hidden node의 feature별 평균과 분산이 아닌 각 hidden layer 전체의 평균과 분산으로 normalization
- Root Mean Square Layer Normalization (RMS Layer Normalization)

- RMS 정규화는 layer 내의 평균 제곱근(root mean square)을 계산하여 정규화한다.
- batch norm이나 layer norm과 같이 학습해야할 파라미터가 없다.
- input의 평균과 분산을 계산해야하는 다른 정규화 알고리즘과 달리 rms 값만 구하면 되기 때문에 효율적이다.
- 다른 정규화 알고리즘과 달리 추가 파라미터가 없어도 out of distribution의 수치에 대해 불안정하지 않다.
SwiGLU activation function [PaLM]
- Swish
Swish(x) = xσ(βx)- x: input
- σ: sigmoid function
- β: trainable parameters
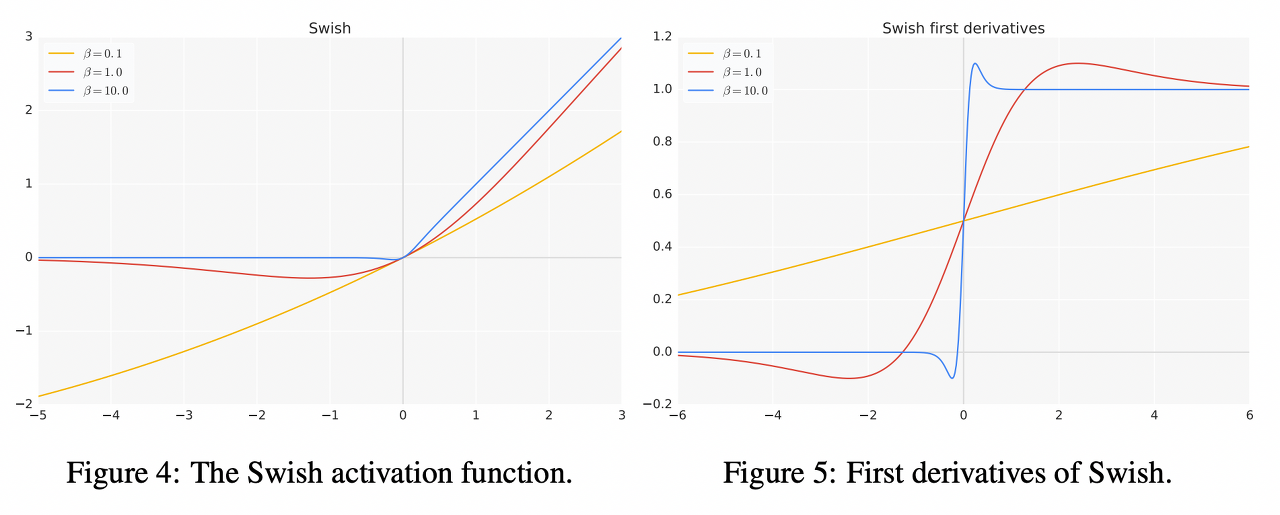
- Unbounded above for (x > 0)
- 모든 양수값을 허용함으로써 정보 유지
- Bounded below (x < 0)
- 음수에 대한 업데이트가 이루어지지 않는 것을 방지
- 매우 큰 음수라도 regularize 하는 효과가 있음
- Differentiability & Smoothness
- 기울기의 불연속 구간이 없기 때문에 빠른 수렴이 가능
- Non-monotonicity
- 모든 범위에서 미분 값이 양수가 아님
- Self-gated
- LSTM에서 사용된 방법으로 입력을 마지막에 곱함으로써 generalization을 돕고 overfitting을 방지
- Computationally expensive
- sigmoid 함수(지수 함수)가 사용되기 때문에 많은 계산량으로 인해 비효율적
- Gated Linear Units (GLU)
GLU(x, W, V, b, c) = σ(xW + b) ⊗ (xV + c)- x: input
- W, V, b, c: trainable parameters
- ⊗: element-wise multiplication (같은 position 끼리 곱합)
- torch에서는
(xV + c)이 단순히GLU(a,b)=a⊗σ(b)로 표현되어 있음
- SwiGLU
SwiGLU(x, W, V, b, c, β) = Swish(xW + b, β) ⊗ (xV + c)- 많은 계산량인 단점이 있지만 성능면에서 우수함
- Dimension
- dimension of 2/3*4d instead of 4d as in PaLM.
- PaLM에서는 feed-forward size를 model dimension의 4배로 사용했지만 LLaMA에서는 model dimension의 2/3*4배로 사용
- PaLM 논문 중 일부
Rotary Embeddings [GPTNeo]
- absolute positional embeddings 대신 각 layer에 rotary positional embeddings (RoPE) 사용
- Absolute Positional Embeddings
- 각 token 별 positional embedding을 더하는 방식
- 초기 transformer의 경우엔 Sinusoid function을 사용하였지만 bert에서는 trainable parameter로 사용
- Sinusoid function
- Absolute Positional Embeddings은 학습하지 못한 길이에 대해 확장하기 어려움
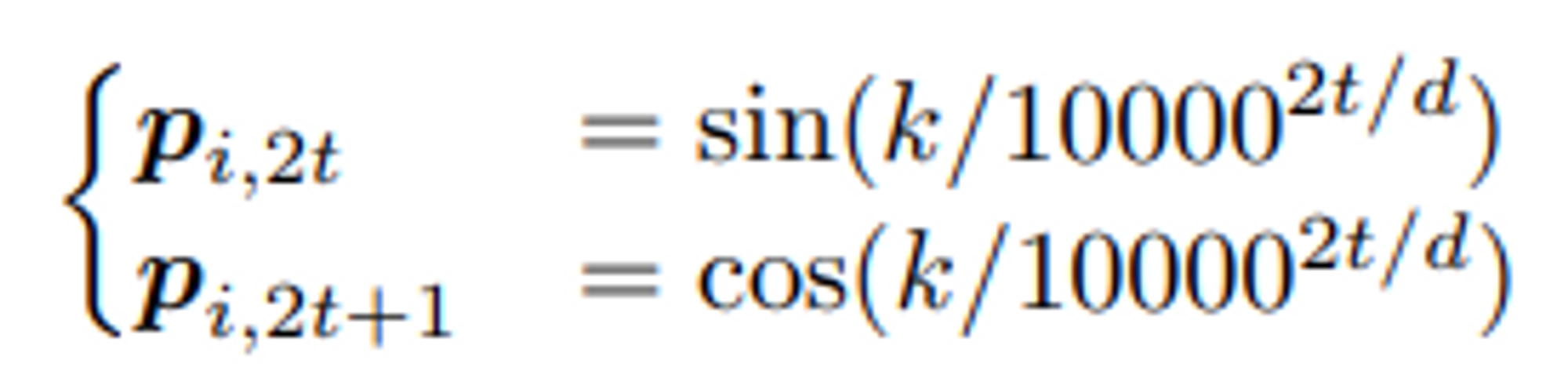
- Relative Positional Embeddings
- 특정 거리 relative distance 이상의 정보는 사용하지 않음
- Relation-aware Self-Attention
- key와 value embedding에 각 position 간의 관계 정보(edge)에 대한 embedding을 더함
- Relative Position Representations
- 각 position에 대해 다른 position에 대한 상대적 위치에 따라 clipping
- 최대 값이 k 라면, 각 position에 대해 양 방향으로 k 거리보다 큰 position을 clipping
- Rotary Positional Embeddings
2.3 Optimizer
- AdamW
- β1 = 0.9, β2 = 0.95
- Cosine Scheduler
- 마지막 learning rate는 최대 learning rate의 10%와 같도록 설정
- weight decay = 0.1, gradient clipping = 1.0
- 2,000 warmup steps
- learning rate와 batch size는 모델 사이즈에 따라 다름
2.4 Efficient implementation
- xformers library
- 메모리 사용량과 런타임을 줄이기 위해 causal multi-head attention 개선
- Self-attention Does Not Need O(n2) Memory
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- backward 동안 checkpointing을 사용하여 다시 계산되는 activation의 양을 줄임
- linear layer와 같이 계산량이 많은 경우
- GPU 간의 activations과 communication 계산도 최대한 중첩시킴
- 결과적으로 LLaMA-65B 모델 학습시 80GB 2048 A100 1개에서 초당 380 token 처리
- 1.4T token 학습에 대략 21일 정도 소요

NLP, AI, LLM, MLops